
Sinh 算子 kernel 直调实现
这次的 CANN 训练营讲述的是 AscendC 语言开发算子,先来简单的介绍下 Ascend C 语言:
面向算子开发场景的编程语言 Ascend C,原生支持 C 和 C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力 AI 开发者低成本完成算子开发和模型调优部署。
使用 Ascend C 进行自定义算子开发的突出优势有:
C/C++原语编程
编程模型屏蔽硬件差异,编程范式提高开发效率
类库 API 封装,从简单到灵活,兼顾易用与高效
孪生调试,CPU 侧模拟 NPU 侧的行为,可优先在 CPU 侧调试
在开发一个算子之前,首先要分析一个算子的逻辑,以下就用 sinh 算子为例:
y = (e^x + e^(-x)) / 2
上面是 sinh 的算子公式,通过公式我们可以看出总共有一个输入,一个输出,为了方便计算还引用了两个 tembuf 临时变量。需要调用到的计算接口为幂函数 Exp、取倒数 Reciprocal、加法 Add、标量乘法接口 Muls;除此之外,还有数据搬运接口 Datacopy,内存管理接口 AllocTensor、FreeTensor,队列管理接口 Enque 和 Deque。对于输入和输出数据的类型和 shape,在这里我们先使用固定 shape,类型的话是 fp16,后面我们会不断的优化这个算子,并且也会尝试其他的算子实现,尽情期待吧。
核函数实现
核函数创建:
extern "C" global aicore void sinh_custom(GM_ADDR x, GM_ADDR y)
{
}
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端 AI Core 上执行。指针入参变量需要增加变量类型限定符__gm__,表明该指针变量指向 Global Memory 上某处内存地址。为了统一表达,使用 GM_ADDR 宏来修饰入参,GM_ADDR 宏定义如下:
#define GM_ADDR gm uint8_t*
Kernel 算子类的实现概览如下:
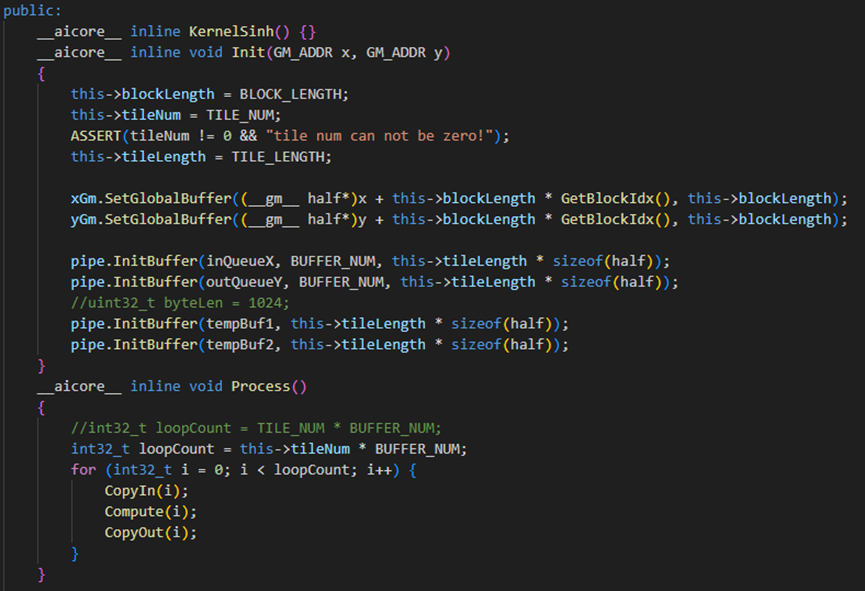
其中包含了有关的通道,需要用到的各种的变量,队列等要在这里声明。
基于矢量编程范式,将核函数的实现分为 3 个基本任务:CopyIn,Compute,CopyOut。Process 函数中通过如下方式调用这三个函数。
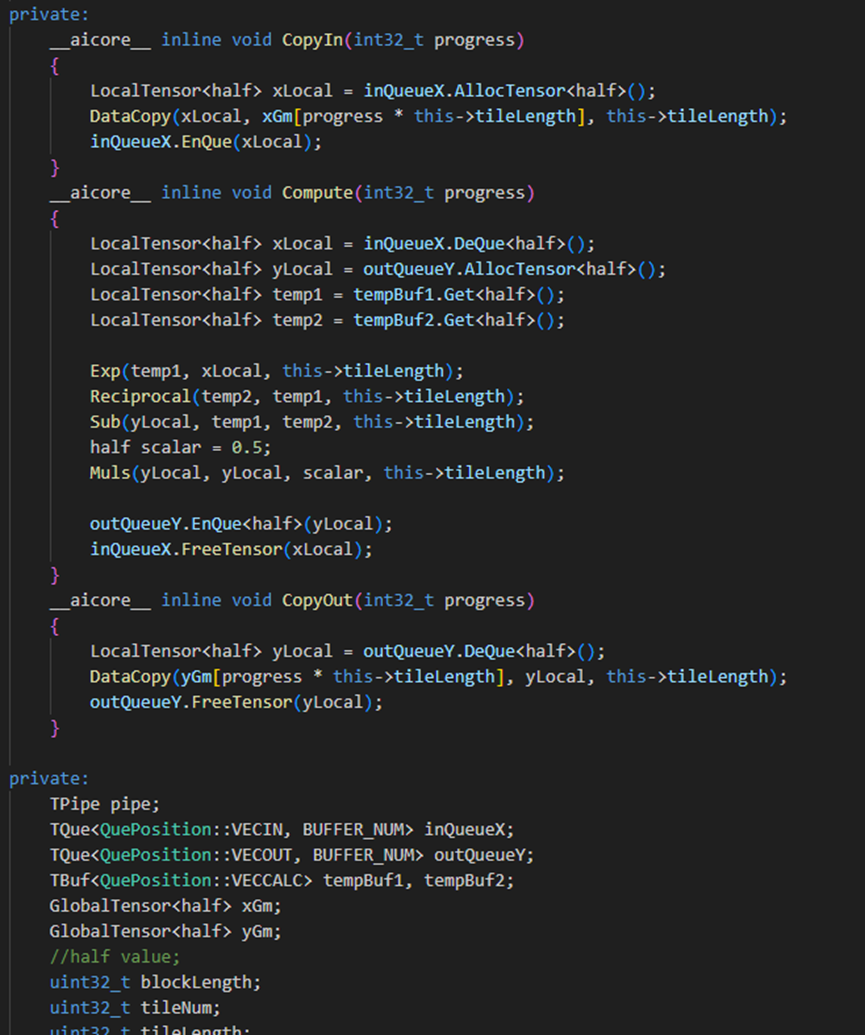
CopyIn 函数实现。
使用 DataCopy 接口将 GlobalTensor 数据拷贝到 LocalTensor。
使用 EnQue 将 LocalTensor 放入 VecIn 的 Queue 中。
Compute 函数实现。
使用 DeQue 从 VecIn 中取出 LocalTensor。
使用 Ascend C 接口 Add 完成矢量计算。
使用 EnQue 将计算结果 LocalTensor 放入到 VecOut 的 Queue 中。
使用 FreeTensor 将释放不再使用的 LocalTensor。
核函数运行验证
异构计算架构中,NPU(kernel 侧)与 CPU(host 侧)是协同工作的,完成了 kernel 侧核函数开发后,即可编写 host 侧的核函数调用程序,实现从 host 侧的 APP 程序调用算子,执行计算过程。
除了上文核函数实现文件 sinh_custom.cpp 外,核函数的调用与验证还需要准备以下文件:
调用算子的应用程序:main.cpp。
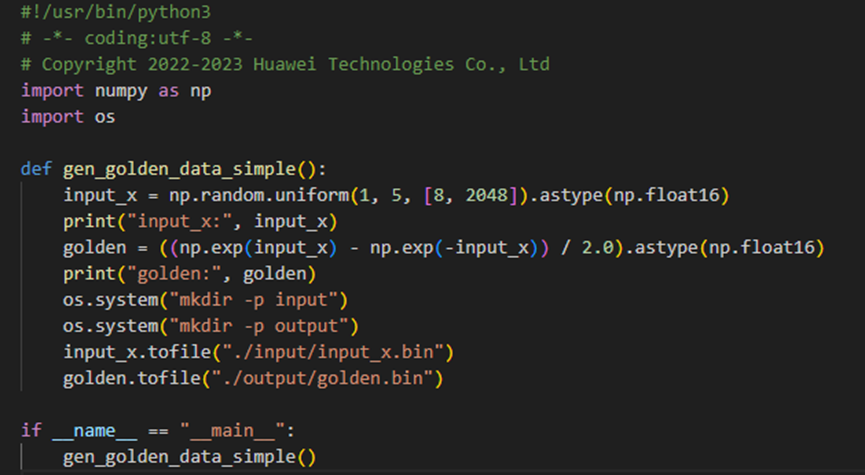
输入数据和真值数据生成脚本文件:gen_data.py;验证输出数据和真值数据是否一致的验证脚本:verify_result.py。
编译 cpu 侧或 npu 侧运行的算子的编译工程文件:CMakeLists.txt。
编译运行算子的脚本:run.sh。
核心代码如下:
CPU 侧:
NPU 侧:
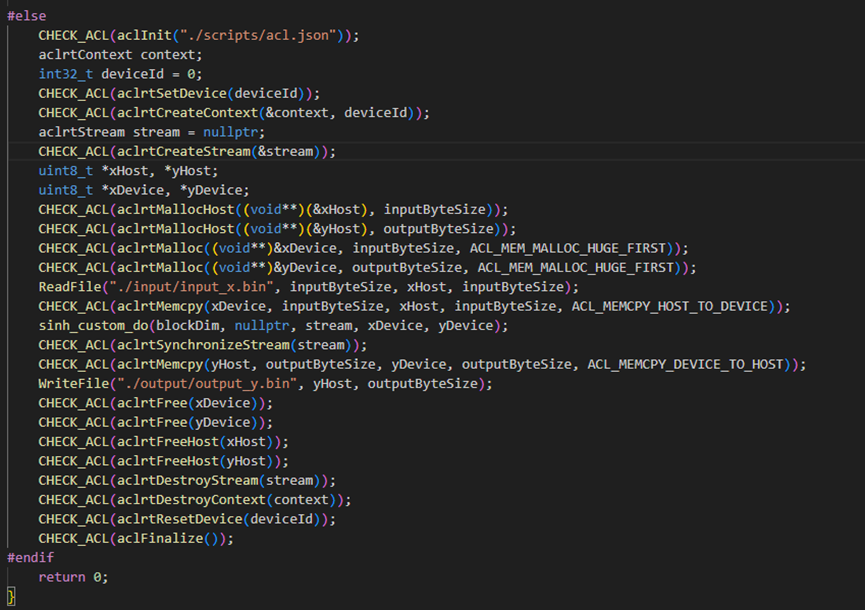
其他的代码需要修改的是:
还需要修改的是 run.sh 文件

修改完成后,就可以执行看看了。各位开发者可以参考上面的编写自己的代码。

还未添加个人签名 2020-03-27 加入
还未添加个人简介






评论