
爬虫工具(tkinter+scrapy+pyinstaller)
作者:快乐非自愿限量之名
- 2024-01-04 福建
本文字数:6526 字
阅读完需:约 21 分钟
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个 and 关系的关键字 ,则用|隔开处理:爬取访问 6 个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段(不是图片或者图例)输出:输出到 csv 文件 ui:窗口小程序,能实时地跟踪爬虫进度运行要求:不依赖于 python 环境,独立运行的 exe 文件
分析实现的主要程序
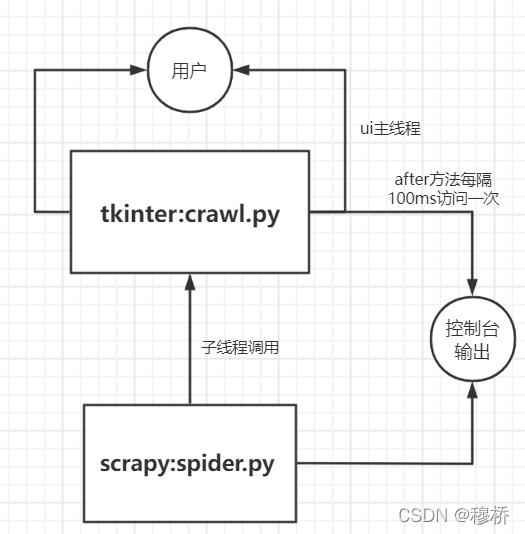
最后pyinstaller 打包 crawl.py 即可
实现
uI 中的线程控制
import tkinter as tkimport timeimport sysimport queueimport threadingdef fmtTime(timestamp): localtime=time.localtime(timestamp) datetime=time.strftime("%Y-%m-%d %H:%M:%S",localtime) return datetime
class re_Text(): def __init__(self,queue): self.q=queue def write(self,content): self.q.put(content)
class GUI(object): def __init__(self,root): self.root=root self.q=queue.Queue() self.initGUI(root)
def show_msg(self): if not self.q.empty(): self.text.insert("insert",self.q.get()) self.text.see(tk.END) self.root.after(100,self.show_msg) def initGUI(self,root): root.title("点击数据") root.geometry('400x200+700+500') bn=tk.Button(root,text="click",width=10,command=self.show) #pack 控制排版 bn.pack(side="top") scrollBar = tk.Scrollbar(root) scrollBar.pack(side="right", fill="y") self.text = tk.Text(root, height=10, width=45, yscrollcommand=scrollBar.set) self.text.pack(side="top", fill=tk.BOTH, padx=10, pady=10) #动态绑定 scrollBar.config(command=self.text.yview) #不要想着中断机制或者调用子函数机制把它视为另一个线程 # (write通信作用) sys.stdout=re_Text(self.q) root.after(100,self.show_msg) root.mainloop() def _show(self): i = 0 for i in range(4): # 顺序执行 ui的刷新线程没有抢占cpu阻塞在这 等过了3秒后才刷新到text time.sleep(1) # 重定向 调用write print(fmtTime(time.time())) def show(self): # 创建子线程 窗口程序可以不断地监听 T=threading.Thread(target=self._show) T.start() if __name__=="__main__": root=tk.Tk() GUI(root)复制代码
scrapy.py
技术细节可以参考之前的文章这里就直接写 spider 了
import scrapyfrom scrapy import Selectorfrom scrapy import Request, signalsimport pandas as pdimport refrom x93.items import csvItemimport osimport sys
class ExampleSpider(scrapy.Spider): name = 'spider'
def __init__(self, **kwargs): super(ExampleSpider, self).__init__(**kwargs) self.data = list() self.keyws=kwargs.get('keywords') #print(self.keyws) print('----------') self.sites=[ 'sh93.gov.cn', '93.gov.cn', 'shszx.gov.cn', 'tzb.ecnu.edu.cn' 'ecnu.edu.cn/info/1094', 'ecnu.edu.cn/info/1095' ] def start_requests(self): #keyw=self.keyws for keyw in self.keyws: keyw=keyw.strip() keyw=keyw.split('|') keyw="+".join(keyw) for site in self.sites: self.logger.info("site"+site) #url=f'https://cn.bing.com/search?q=site%3a{site}+allintext%3a{keyw}&first=1' url = f'https://cn.bing.com/search?q=site%3a{site}+{keyw}&first=1' yield Request(url, callback=self.parse, cb_kwargs={'first':1,'site':site,'keyw':keyw,'totallist':0}) def parse(self, response,**kwargs): #百度网页 列表内容 res=Selector(text=response.text) for a in res.xpath('//h2/a[@target="_blank"]'): title = a.xpath('./text()').get() href = a.xpath('./@href') .get() out = re.search("index",href) htm= re.search("htm",href) # 排除含index列表页 json 数据页 if out!=None or htm==None: continue kwargs['href']=href yield Request(href,callback=self.get_detail,cb_kwargs=kwargs) #翻页 # if kwargs['first']==1: # nub=res.xpath(r'//span[@class="sb_count"]/text()').get() # nub="".join(re.findall(re.compile('[\d]+'),nub)) # kwargs['totallist']=int(nub) # #self.logger.info("kwargs['totallist']" + kwargs['totallist']) # if kwargs['first']+10<kwargs['totallist']: # self.logger.info(f"kwargs['totallist']{kwargs['totallist']}") # kwargs['first'] =kwargs['first'] + 10 # url=f'https://cn.bing.com/search?q=site%3a{kwargs["site"]}+allintext%3a{kwargs["keyw"]}&first={kwargs["first"]} ' # self.logger.info(f"url{url}") # yield Request(url, callback=self.parse, cb_kwargs=kwargs)
def get_detail(self,response,**kwargs): res = Selector(response) title='' date ='' content='' source='' if kwargs['site']=='sh93.gov.cn': try: title = res.xpath('//h3[contains(@class,"article-title")]/text()').get() date = res.xpath('//div[contains(@class,"article-title-news")]/span/text()').get() date = "".join(re.findall(re.compile(r"[\d-]+"), date)) try: source=res.xpath('//span[@class="ml20"]/text()').get() except TypeError: source="九三上海市委新闻" try: content=res.xpath('//div[contains(@class,"article-content")]/p[not (@style="text-align: center;")]/' 'text()').get().strip() except : content=res.xpath('//span[contains(@style,"font-family")]/text()').get().strip() except: try: title = res.xpath('//td[@class="pix16blackl32"]/text()').get() date = res.xpath('//td[@class="pixh4_line24"]/text()').get() date = re.findall(re.compile(r"[\d-]+"), date) date = "-".join(date) source = "九三学社上海市委员会" content = res.xpath("//p/text()").get() except: self.logger.error(f"无法解析{kwargs['href']}") if kwargs['site']=='93.gov.cn': title=res.xpath('//div[contains(@class,"pageTitle")]/h2/text()').get() date=res.xpath('//div[contains(@class,"pageTitle")]//ul/li[1]/text()').get() date = "".join(re.findall(re.compile(r"[\d-]+"), date)) source=res.xpath('//div[contains(@class,"pageTitle")]//ul/li[2]/text()').get()[3:] try: content = res.xpath('//div[@class="text"]/p[not (@style="text-align: center;")]/text()').get().strip() except AttributeError: #print("url:"+kwargs['href']) content= res.xpath('//div[@class="text"]//span[contains(@style,"font-family")]/text()').get().strip() #content= res.xpath if kwargs['site']=='shszx.gov.cn': title=res.xpath('//h2[@id="ivs_title"]/text()').get() date= res.xpath('//div[@class="fc con22 lh28 grey12"]/text()').get() date="".join(re.findall(re.compile(r"[\d-]+"), date)) source="上海政协" cnt=1 while content == '': cnt=cnt+1 content=res.xpath(f'//div[@id="ivs_content"]/p[not (@align="center") and ' f'not (@style="text-align: center;")][{cnt}]/text()').get().strip() if kwargs['site']=='tzb.ecnu.edu.cn': title=res.xpath('//h1[@class="arti_title"]/text()').get() #text() 会取第一个 date=res.xpath('//span[@class="arti_update"]/text()').get() date="".join(re.findall(re.compile(r"[\d-]+"), date)) source=res.xpath('//span[@class="arti_department"]/text()').get()[4:] content=res.xapth('//div[@class="wp_articlecontent"]//p[contains(@style,"font-size")]/text()').get().strip() if 'ecnu.edu.cn' in kwargs['site']: title=res.xpath('//h2[@class="m3nTitle"]/text()').get() date=res.xpath('//span[@class="m3ntm"]/text()').get() date=re.findall(re.compile(r"[\d-]+"), date) date="-".join(date) if "1094" in kwargs['site']: source="华东师范大学新闻热点" else: source = "华东师范大学媒体关注" content=res.xpath('//p/span[contains(@style,"font-family")]//text()|' '//p[contains(@style,"text-align:justify")]/text()').get().strip() item=csvItem() item['keyword']=kwargs['keyw'] item['title']=title item['date']=date item['source']=source item['content']=content item['url']=kwargs['href'] print(title, date, content) yield item复制代码
ui 脚本中运行 scrapyscrapy 脚本运行有三种方式,实现细节可以参考官方文档cmdline.execute 方式只能运行一个爬虫,而其他两种方式可以同时运行多个(异步+异步)。
scrapy 爬虫比较耗时,需要放在子线程工作,因此选用 crawlRunner(crawlProcess 要求运行在主线程就不行),但是不清楚为什么刚开始正常运行后来又是报错提示,signal run in main thread.可以尝试的解决方法,参考博客
# !/user/bin/env Python3# -*- coding:utf-8 -*-
from scrapy import *import scrapyfrom scrapy import Selectorfrom scrapy import Request, signalsimport pandas as pdimport reimport timeimport tkinter as tkfrom tkinter import filedialog, dialogimport osimport threadingimport loggingimport sysfrom scrapy.crawler import CrawlerProcessfrom scrapy.utils.project import get_project_settingsfrom scrapy.cmdline import executefrom twisted.internet import reactorfrom scrapy.crawler import CrawlerRunnerfrom scrapy.utils.log import configure_loggingfrom x93.spiders.spider import ExampleSpiderfrom scrapy.utils.project import get_project_settings
logger = logging.getLogger(__name__)file_path = ''file_text = ''class re_Text(): def __init__(self,text): self.text=text def write(self,content): self.text.insert("insert",content ) self.text.see(tk.END)class GUI(): def __init__(self): self.root=tk.Tk() self.root.title("ecnu数据爬取工具") self.root.geometry("400x400+200+200") def initGUI(self): # self.root.title('窗口标题') # 标题 # self.root.geometry('500x500') # 窗口尺寸 self.scrollBar = tk.Scrollbar(self.root) self.scrollBar.pack(side="right", fill="y") self.text = tk.Text(self.root, height=10, width=45, yscrollcommand=self.scrollBar.set) self.text.pack(side="top", fill=tk.BOTH, padx=10, pady=10) #self.scrollBar.config(command=self.text.yview) # 动态绑定 滚动条随着鼠标移动 bt1 = tk.Button(self.root, text='打开文件', width=15, height=2, command=self.open_file) bt1.pack() bt2 = tk.Button(self.root, text='爬取数据', width=15, height=2, command=self._app) bt2.pack() #bt3 = tk.Button(self.root, text='保存文件', width=15, height=2, command=save_file) #bt3.pack()
def open_file(self): ''' 打开文件 :return: ''' global file_path global file_text file_path = filedialog.askopenfilename(title=u'选择文件', initialdir=(os.path.expanduser('H:/'))) print('打开文件:', file_path) if file_path is not None: with open(file=file_path, mode='r+', encoding='utf-8') as file: file_text = file.readlines() print(file_text)
def thread_it(func, *args): '''将函数打包进线程''' # 创建 t = threading.Thread(target=func, args=args) # 守护 !!! t.setDaemon(True) # 启动 t.start() # 阻塞--卡死界面! #t.join() def _app(self): t=threading.Thread(target=self.app,args=()) t.start() def app(self): global file_text
logger.info(f"type(file_text){type(file_text)}") runner = CrawlerRunner(get_project_settings()) d = runner.crawl(ExampleSpider,keywords=file_text) d.addBoth(lambda _: reactor.stop()) reactor.run() self.text.insert('insert', "爬取成功") # process = CrawlerProcess(get_project_settings()) # process.crawl(ExampleSpider,keywords=file_text) # process.start() # cmd=f'scrapy crawl spider -a kw={file_text}'.split() # execute(cmd) # cmd = 'python Run.py' # print(os.system(cmd)) g=GUI()g.initGUI()sys.stdout=re_Text(g.text)g.root.mainloop() # 显示复制代码
pyinstaller 打包因为看到很多博客都说用 pyinstaller 打包 scrapy 需要引入较多依赖,修改配置文件等多余的操作,一直没敢下手尝试直接用 pyinstaller 打包主程序,转向成功案例较多的单线程运行爬虫方式,后来还是败给的 scrapy 框架,返回失败的 retry 机制以及代理更换的便捷,毕竟批量输入无可避免的有无法访问目标计算机问题。
打包后的程序(调试问题后就上传占个位)
文章转载自:mingruqi
划线
评论
复制
发布于: 刚刚阅读数: 3

快乐非自愿限量之名
关注
还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论