
【Netty】「源码解析」(二)HeapBuffer 创建过程详解:高效可靠的内存管理技巧
前言
本篇博文是《从 0 到 1 学习 Netty》中源码系列的第二篇博文,主要内容是通过源码层层剖析 Netty 中 HeapBuffer 的创建过程,了解它是如何高效的对内存进行管理,往期系列文章请访问博主的 Netty 专栏,博文中的所有代码全部收集在博主的 GitHub 仓库中;
介绍
在博文 ByteBuf 的基本使用 中,博主曾提到过 HeapBuffer,它是基于堆内存实现的,它的底层实现是一个字节数组,在创建时需要指定容量大小,并且可以自动扩展。
相比其他类型的缓冲区,如 DirectBuffer,HeapBuffer 的优点是它使用的是 Java 虚拟机的堆内存,因此创建和销毁 HeapBuffer 对资源的开销较小,而且 HeapBuffer 相对于 DirectBuffer 更易于调试和跟踪。但是,由于堆内存的分配和回收机制,HeapBuffer 的性能可能会受到垃圾回收的影响,特别是对于大型缓冲区。因此,在某些情况下,DirectBuffer 可能更适合使用。
在 Java 中,我们可以使用上面这一行代码直接创建 HeapBuffer 对象,但实际上,这个过程经历了许多复杂的操作,接下来,我们逐层深入剖析这个过程。
HeapBuffer 对象创建
heapBuffer 函数
首先要分析的函数是 heapBuffer,其主要作用是提供一个简单的 API 来创建基于 JVM 堆内存的 HeapBuffer 对象,并确保参数符合要求,源码如下所示:
在上述源码中,heapBuffer(int initialCapacity, int maxCapacity) 接受两个参数:initialCapacity 和 maxCapacity。其中,initialCapacity 是代表缓冲区初始容量的整数参数,由开发者自定义传入,而 maxCapacity 是代表缓冲区最大容量的整数参数,一般默认值为 Integer.MAX_VALUE。
如果参数 initialCapacity 和 maxCapacity 都为零,则返回一个空的 ByteBuf 对象。
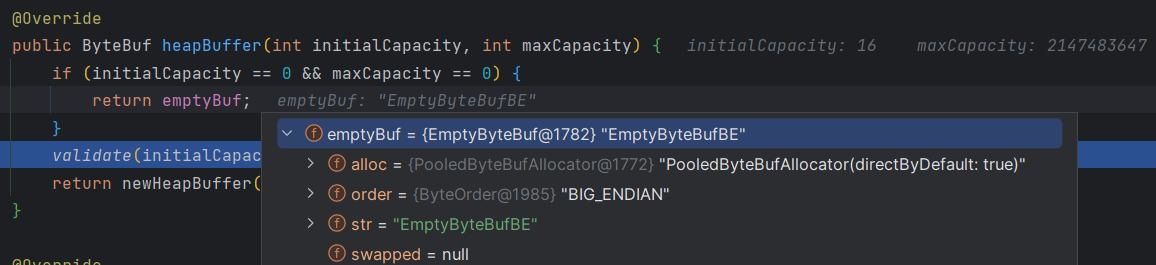
校验参数 initialCapacity 和 maxCapacity 是否为 0 之后,还需要更进一步的验证,具体来说,就是调用 validate(initialCapacity, maxCapacity) 方法对这两个参数进行验证。
validate 函数
validate 源码如下所示:
在上述源码中,validate 方法的作用是确保 initialCapacity 大于等于零并且不大于 maxCapacity,如果不满足这些条件,则会抛出异常 IllegalArgumentException 以提示错误。
参数 initialCapacity 和 maxCapacity 经过两层验证,确保符合规范后,heapBuffer 函数内部将调用 newHeapBuffer(initialCapacity, maxCapacity) 方法创建一个新的 HeapBuffer 对象。
接下来,博主将详细讲解有关 HeapBuffer 内存分配的内容;
HeapBuffer 内存分配
newHeapBuffer 函数
newHeapBuffer 源码如下所示:
在上述源码中,首先获取当前线程的缓存对象 cache,其中包含了一个或多个 PoolArena 对象,每个 PoolArena 对象对应一个内存池,用于分配不同大小的内存块,从缓存中获取一个 HeapArena 对象,该对象对应着一个基于堆的内存池。
接着,代码尝试从 HeapArena 中分配一个大小为 initialCapacity 且最大容量为 maxCapacity 的内存块。如果 HeapArena 为空,则根据操作系统是否支持 Unsafe 类来创建一个新的 UnpooledHeapByteBuf 或 UnpooledUnsafeHeapByteBuf 对象。
最后,将返回的 ByteBuf 包装成一个 LeakAwareByteBuf 对象,该对象用于检测内存泄漏并在必要时打印警告日志。
heapArena.allocate 函数
接下来分析用于分配内存的函数 allocate,源码如下所示:
在上述源码中,函数 allocate 的作用是从 ByteBuf 池中分配一个 PooledByteBuf 并返回它。这个函数有三个参数:PoolThreadCache 对象,请求分配的容量 reqCapacity 以及最大容量 maxCapacity。
首先,该函数使用 newByteBuf 方法创建一个新的 PooledByteBuf 对象,并将其赋值给 buf 变量。然后,方法调用 allocate 方法,该方法会在给定的缓存 cache 中,为 buf 对象分配所需的空间,容量大小由 reqCapacity 决定。最后,该方法返回分配好空间的 PooledByteBuf 对象 buf。

其中,newByteBuf 方法的源码如下所示:
在上述源码中,函数 newByteBuf 的主要作用是创建一个可重用的 ByteBuf 实例,并且根据是否支持 Unsafe 操作来选择相应的实现方式。如果支持 Unsafe,则创建一个 PooledUnsafeHeapByteBuf 实例;否则,创建一个 PooledHeapByteBuf 实例。
PooledUnsafeHeapByteBuf 函数
这里以 PooledUnsafeHeapByteBuf 为例进行讲解,它是一个具有内存池功能的 ByteBuf 实现,在创建实例时会通过 RECYCLER 来获取一个已经回收的对象进行重用,这样可以避免频繁地创建和销毁对象,提高性能。

RECYCLER.get() 方法的源码如下所示:
上述源码基于一个栈结构,每个线程都有自己的栈。当需要获取一个对象时,首先检查当前线程对应的栈是否为空,如果不为空,则从栈顶弹出一个对象;如果栈为空,则新建一个对象并返回给调用方。被弹出的对象会在使用完后,再次放回到栈顶,以便下一次调用时可以重复利用。
另外,NOOP_HANDLE 是一个空操作的句柄对象,当 maxCapacityPerThread 为 0 时,代表不限制每个线程池中的对象数量,并且所有对象都由 NOOP_HANDLE 管理,否则,每个线程池中最多容纳 maxCapacityPerThread 个对象。
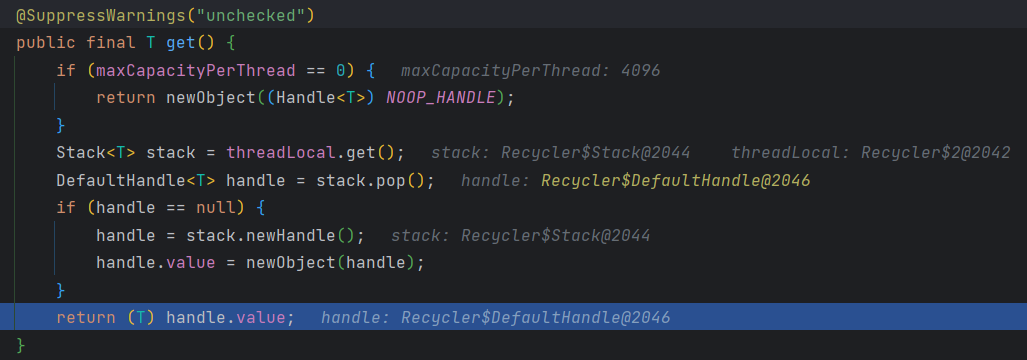
reuse 方法的源码如下所示:
在上述源码中,reuse 方法的作用应该是在重用一个对象时对其状态进行重置。该方法接收一个整数类型参数 maxCapacity,表示对象允许的最大容量。接着,调用了 resetRefCnt 方法,将对象的引用计数器重置为初始值。然后,调用 setIndex0 方法,将对象的索引位置重置为初始值。最后,调用了 discardMarks 方法,将对象的标记位清除。
值得注意的是,对象的引用计数值被初始化为 2:
PoolArena.allocate 函数
源码如下所示:
在上述源码中,allocate 实现了分配内存的逻辑,它根据请求的内存大小对内存进行分类,然后尝试从内存缓存中分配内存,如果在缓存中没有可用的内存,则需要从内存块中分配内存。内存块可以是一个普通的 JVM 堆内存块,也可以是一个直接内存块。
该方法首先将请求的内存大小规范化为合适的大小,然后分为三种情况:
内存较小(小于等于页大小):如果请求的内存大小小于等于
Tiny或Small内存块的最大容量,则从Tiny或Small内存块分配内存。如果Tiny或Small块中没有剩余空间,则需要从内存块中分配内存。内存正常大小(大于页大小,小于等于内存块大小):如果请求的内存大小小于等于当前内存块的最大容量,则从当前内存块分配内存。
内存巨大(大于内存块大小):如果请求的内存大小超过了当前内存块的最大容量,则需要分配一块
Huge内存。
在分配内存时,如果内存块中没有可用的子页面,则需要使用 allocateNormal 方法从内存块中分配内存,最后,根据分配的内存大小更新内存池的状态。
接下来就以 reqCapacity=16 为例,对 allocate 函数进行逐步讲解;
首先,normalizeCapacity 函数的作用就是将传入的内存大小标准化为符合某些规则的内存块大小,以便在内存池中使用。
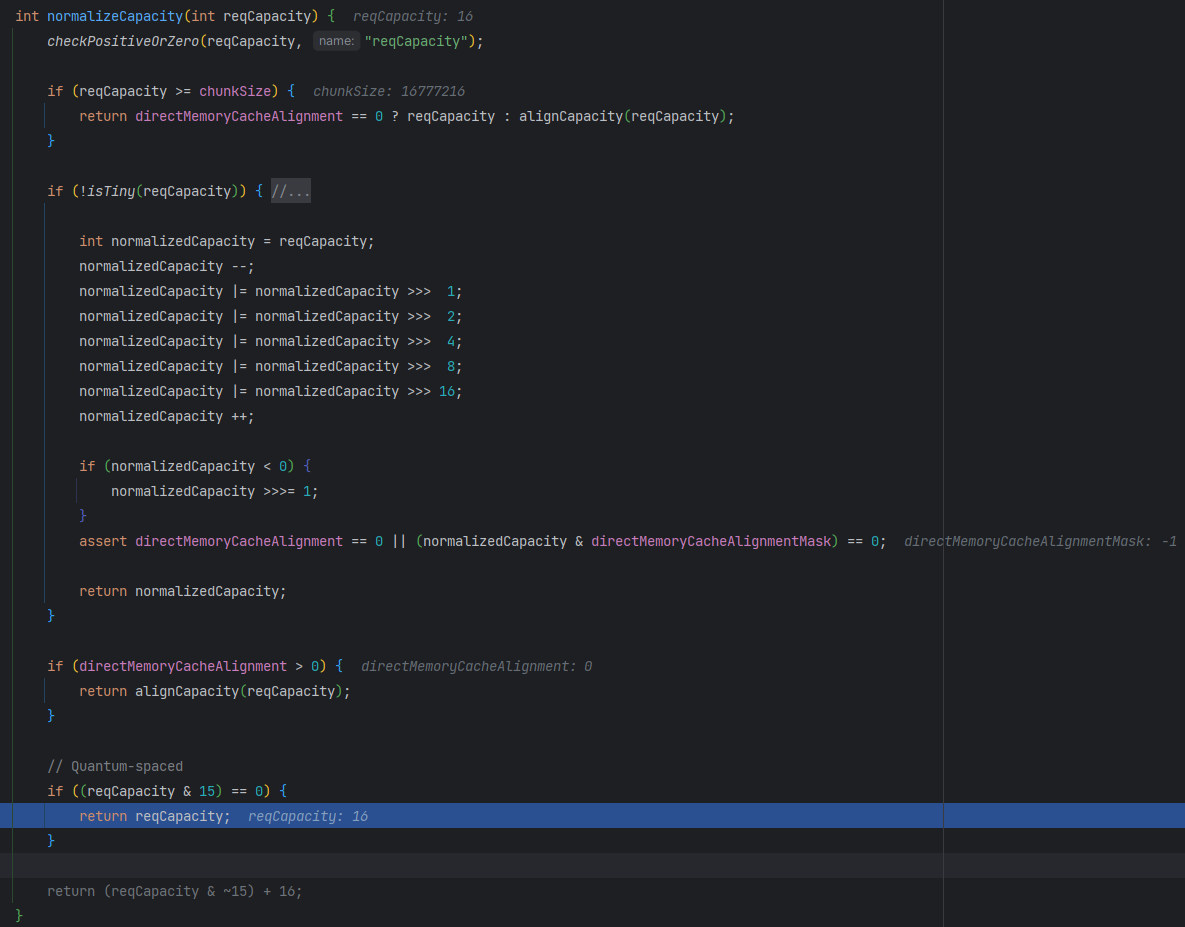
函数先通过调用 checkPositiveOrZero 方法检查传入的 reqCapacity 是否大于等于零,如果不是会抛出异常。然后函数会根据 reqCapacity 的大小分别进行不同的处理:
如果
reqCapacity大于等于一个设定阈值chunkSize,则判断是否需要对齐。如果需要对齐,则返回一个对齐后的大小;否则直接返回reqCapacity的值。如果
reqCapacity小于chunkSize且大于等于一个设定阈值 512,则将reqCapacity向上取最近的 2 的幂次方数,然后返回这个数。如果
reqCapacity小于 512,则根据设定的缓存对齐大小directMemoryCacheAlignment,对齐reqCapacity并返回对齐后的大小。如果以上情况都不符合,则将
reqCapacity向上取到最近的 16 的倍数,并返回这个数。
因为 reqCapacity=16 既小于 512,又是 16 的倍数,因此 (reqCapacity & 15) == 0,所以返回 reqCapacity=16,即 normCapacity=16;
根据刚刚得到的对齐后的容量值 normCapacity,对内存大小进行分类,因为 normCapacity=16,所以 isTinyOrSmall 和 isTiny 方法的返回值都是 true;

计算出在 Tiny Subpage 池中对应的索引 tableIdx,然后从 Tiny Subpage 池中取出与该索引对应的链表头节点 head。
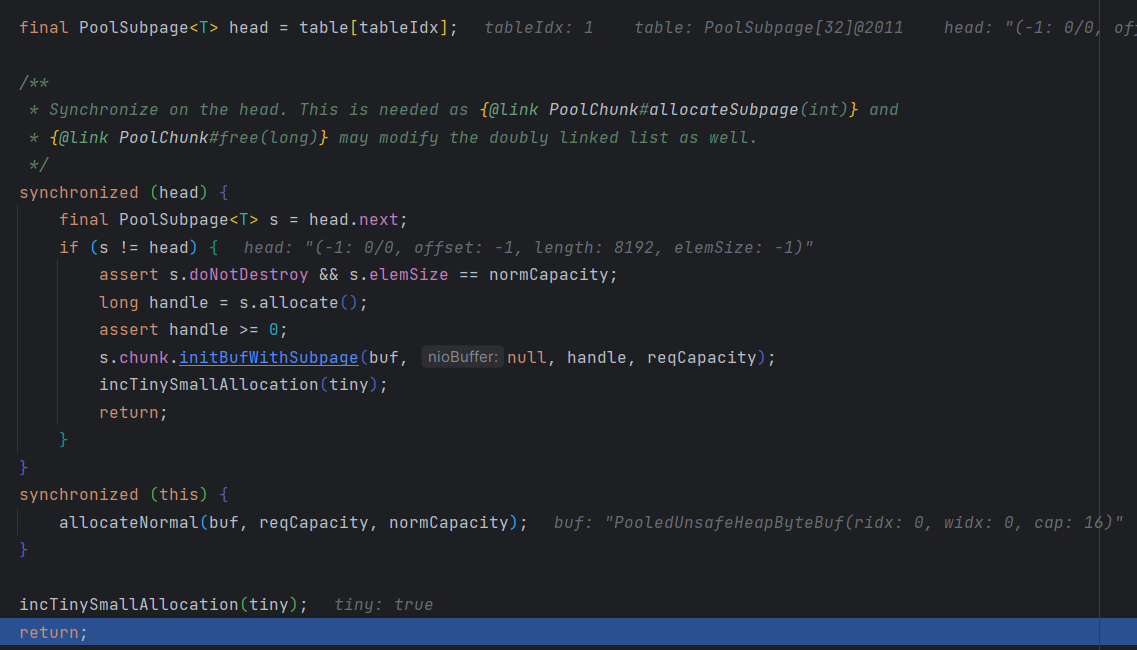
使用 synchronized 同步关键字对链表头节点 head 进行加锁,防止多个线程同时访问并修改链表结构。
在加锁区间内,检查链表头节点 head 的下一个节点 s 是否指向自身,如果不是,则取出该节点,并确认其状态符合要求:doNotDestroy 为 true 表示该节点未被销毁,elemSize 等于 normCapacity 表示该节点可用于当前请求。
然后,通过 allocate() 方法在该节点所属的内存页的内存块中分配空间,并将其初始化为 buf 对象。最后,增加 Tiny Subpage 类型的内存分配计数器,并返回分配结果。
如果 Tiny Subpage 池中没有可用的内存块,则执行第二个 synchronized 区间,使用另一种内存分配算法 allocateNormal() 从 Normal Pool 中分配内存块。最后,同样增加 Tiny Subpage 类型的内存分配计数器,并返回分配结果。
allocateNormal() 方法主要用于分配一个指定大小的 ByteBuf。具体来说,它会遍历多个内存池队列,尝试从中分配一个指定容量的内存块。如果找到了可用的内存块,则直接返回;否则将会创建一个新的一块内存区域 Chunk,然后在其中分配所需的内存块,并将该 Chunk 添加到内存池的初始化队列 qInit 中。
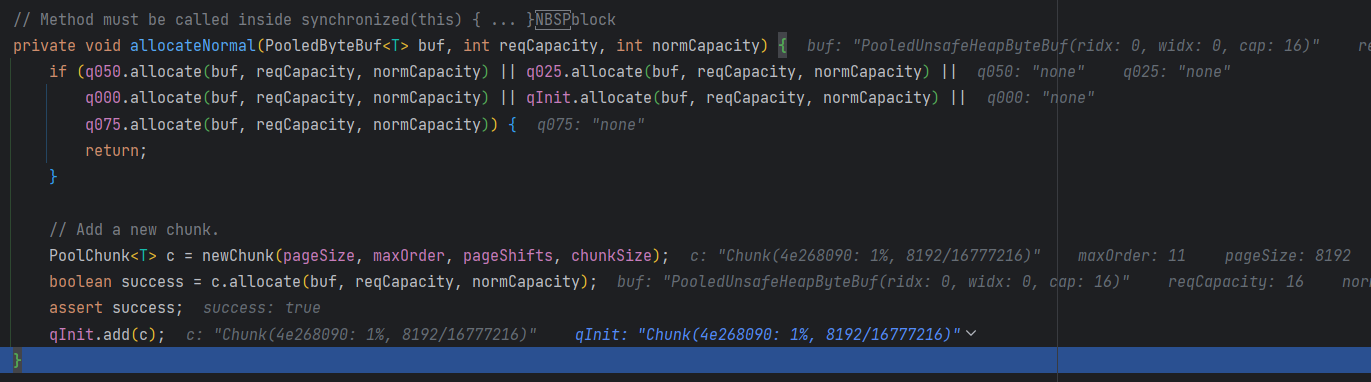
q050、q025、q000、qInit、q075 是五个不同阈值的内存池队列:
q050:内存块大小为 512KB 至 1024KB;q025:内存块大小为 256KB 至 512KB;q000:内存块大小为 64KB 至 256KB;qInit:内存块大小为 16B 至 64KB,这个队列是所有内存块大小的初始队列,也就是说,只要有空闲的内存块,都应该先从这个队列中分配;q075:内存块大小为 1024KB 至 8192KB;
同时,用于管理内存块的分配和释放 allocate 方法如下所示:
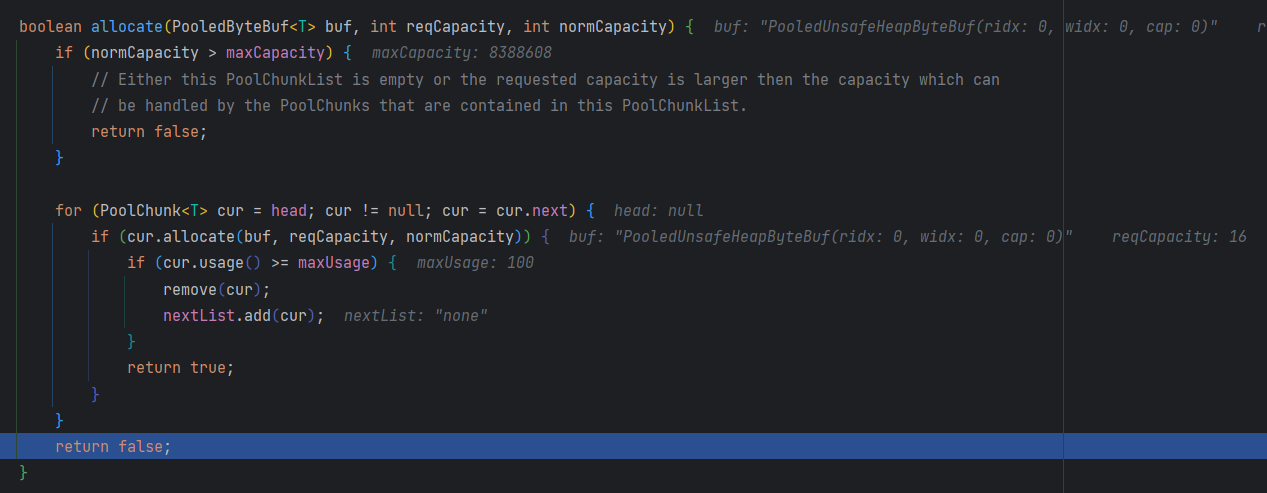
该方法的作用是尝试从当前的内存池中分配一个指定容量的内存块,并将其分配给参数中传入的 PooledByteBuf 对象。在内存块分配过程中,会首先检查请求的容量是否超出了内存池支持的最大容量 maxCapacity,如果超出则不能分配。
然后会遍历当前内存池中的所有内存块,尝试找到一个满足要求的内存块进行分配。如果找到了合适的内存块,则会调用该内存块自身的 allocate 方法进行具体的分配操作,并返回 true 表示成功分配。如果一个内存块已经被分配的使用率超过了 maxUsage,则会将其从当前内存池中移除,加入到下一级内存池中。
如果遍历完所有的内存块都没有找到可用的内存块,则返回 false 表示分配失败。
后记
通过本次对 HeapBuffer 的创建过程的详细介绍,我们可以清楚地了解到它是如何从分配内存到初始化的。在此过程中,首先需要进行内存的分配和对齐,然后进行内存的初始化和管理。这些步骤都非常重要,因为它们保证了 HeapBuffer 在使用时的高效性、稳定性和安全性。总而言之,HeapBuffer 是一种非常有用的内存管理工具,对于提高程序的性能和效率具有重要的作用。
以上就是 HeapBuffer 创建过程详解:高效可靠的内存管理技巧 的所有内容了,希望本篇博文对大家有所帮助!
参考:
版权声明: 本文为 InfoQ 作者【sidiot】的原创文章。
原文链接:【http://xie.infoq.cn/article/eb134fa261559c3ee29960adf】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2023-06-04 加入
还未添加个人简介









评论