
手把手带你搭建企业低成本万能架构
企业软件应用架构层出不穷(这里的应用架构是指偏后端服务的软件架构)每个企业由各自业务形态,技术栈,技术路线,技术实力不同,各自架构方案,技术选型各有各的不同,千姿百态,正所谓:“百花齐放,尽吐芬芳”。
没有最好架构,只有当前最适合的架构方案,也没有完美架构,只有持续迭代演进的架构。
有没有一种万能通用应用服务软件架构呢?今天我们来聊聊我眼中的“万能”架构。免费获取:http://www.jnpfsoft.com/?from=infoq
所谓万能,也不是真正的万能!
这里提两个指标:
适用于大多数企业的大多数业务场景(70%以上);
在满足业务条件下企业投入成本要求最小化,包括:软硬件成本+人员学习成本+实施成本+运维成本。
1、极简之万能架构
MySQL+Redis+ES(三件套)
这是极简的架构搭配基本上可以满足 70~80%的企业应用业务场景,应用服务开发语言不限,企业根据自己团队善长技术方向就行,例如:PHP,C#,JAVA,go,python,ruby 等。
MYSQL 开源免费、稳定、可靠、安装简单,只要搞过 web 开发的人都熟悉,接入成本极低、运维成本较低(相比其他关系型数据库);
Redis 开源免费、高性能、稳定、可靠,基本搞过软件开发的人都会,接入成本、运维成本极低;
ElasticSearch 开源免费、高性能、稳定、可靠,大多数开发人员都会使用,接入成本低,运维成本有那么点高。
MYSQL+Redis+ElasticSearch 这三者组合,可以满足大多数业务应用场景,一般企业都可以考虑这种架构方式,简单高效。真的没有必要追求复杂的架构。
Redis 除了高性能之处,还经常可以用来做分布式锁,缓存一些少量热点的数据,比如数据字典。
ES 安装稍微复杂一点,但也没有多复杂,机器性能要求高一些,要求稍微高配一点的机器,内存大和高速 SSD 硬盘。它在查询分页数据列表,查询亿级数据量毫秒级(当然是要求正确建立分片和有效索引前提下)。
如下图所示:

以上架构可以号称最简单的万能架构,一般在万级以内 QPS 可以顶得住的,而绝大多数企业应用实际上也没有那么大的并发量级;
但万一有些特殊的业务场景并发远不止是万级的,特别面向互联网消费者用户量级就要高得多了,如:10 万级、百万级、千万级怎么办?
存在问题:
应用怎么实现水平扩展?
三大件单点风险比较高,怎么做高可用?
既然存在问题,那么我们对以上架构需要进一步扩展,使它更高可用,承载更高的并发量。
2、极简万能架构之二
MySQL+Redis+ES+Nginx (四个组件配置群集版)
这个架构增加了 Nginx 代理,从而可以实现应用服务水平扩展的能力,而 nginx 本身是开源免费,高性能、稳定,安装配置简单特点,非常适合在高并场景中做反向代理应用。
而 Nginx 本身也可配置多节点,通过虚拟 IP 即 VIP 配置集群,实现高可用。
同时 ES 和 Redis 都可以配置部署多个节点,从而实现集群版本,这两个组件本身单机性能非常强悍。加上集群配置,几乎可以高枕无忧一段时间了。
另外 MySQL 可以配置集群版本,1 主多从,为什么要用 1 主呢?因为单一主节点简单:程序实现简单、写入简单、配置部署也简单、运维也简单。高并发场景一般都是查多写少。
推荐:MySQL+Redis+ES+Nginx 四件套加集群版本,简单高效!
这种架构也能满足绝大多数企业应用的高并发场景。所以读多的情况下 10 万级以下 QPS 可以顶住的。
一般企业应用如果日常业务能达到 10 万级 QPS,访问量算已经非常大的了,能达到这个量级,业务量够大,也不必在意这点投入。
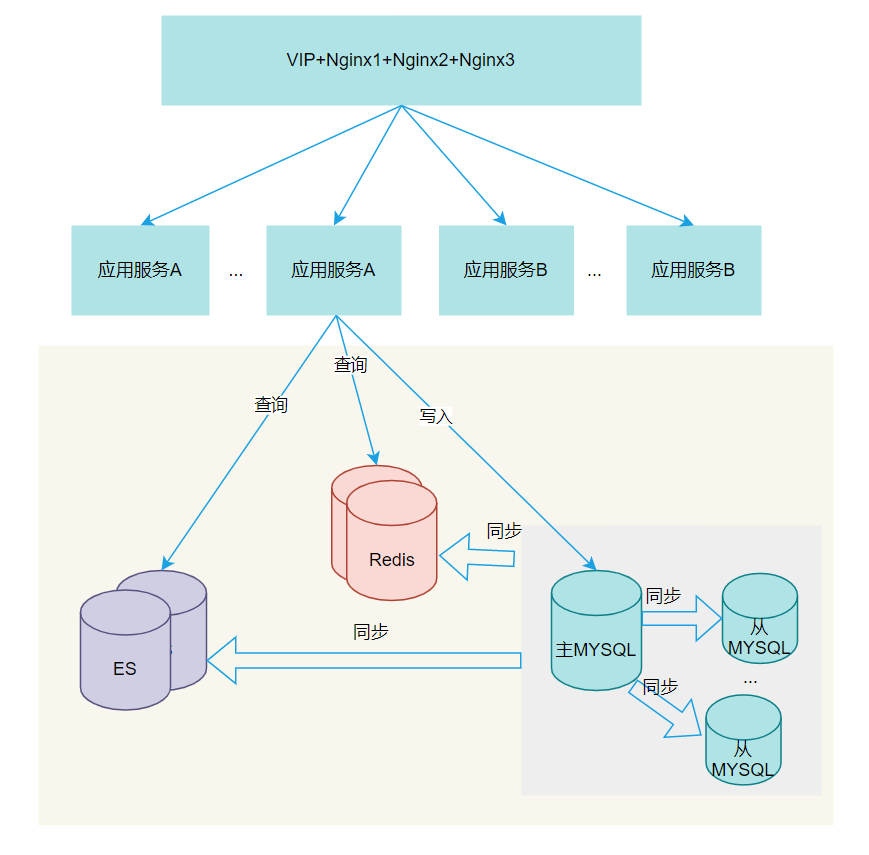
但是凡事有万一,万一真的是写多了怎么办,主库一个节点根本扛不住怎么办?
存在问题:
一个主库写入是不够的?在高并发写入的时候肯定扛不住。
3、多读多写方案一
MySQL 部署多主多从
经过以上分析读多的情况问题不大;那如果写多呢?写多的方案也有很多,可以使用 MySQL 多主架构部署,但是运维和部署复杂度也会高很多。若没有那么大的实际业务量的要求,建议谨慎考虑清楚。
应用程序不用太多改动,相当于主库多一层代理,对上层调用透明。
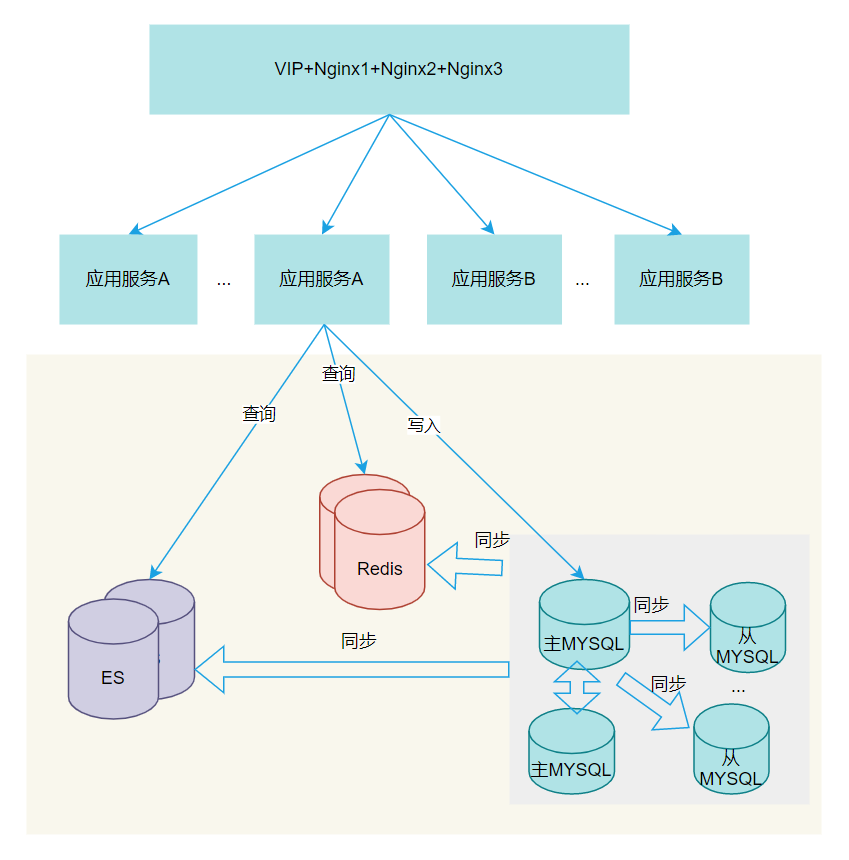
多主其实带来系统部署复杂度的提升,运维、升级维护等增加复杂度。
多主存在的问题:
主与主双向同步复制问题;
主从复制同步问题
我们先从 MySQL 主从复制,主主复制流程原理上进一步深入分析具体问题和原因。
主从复制基本工作流程
MySQL 主从复制工作流程
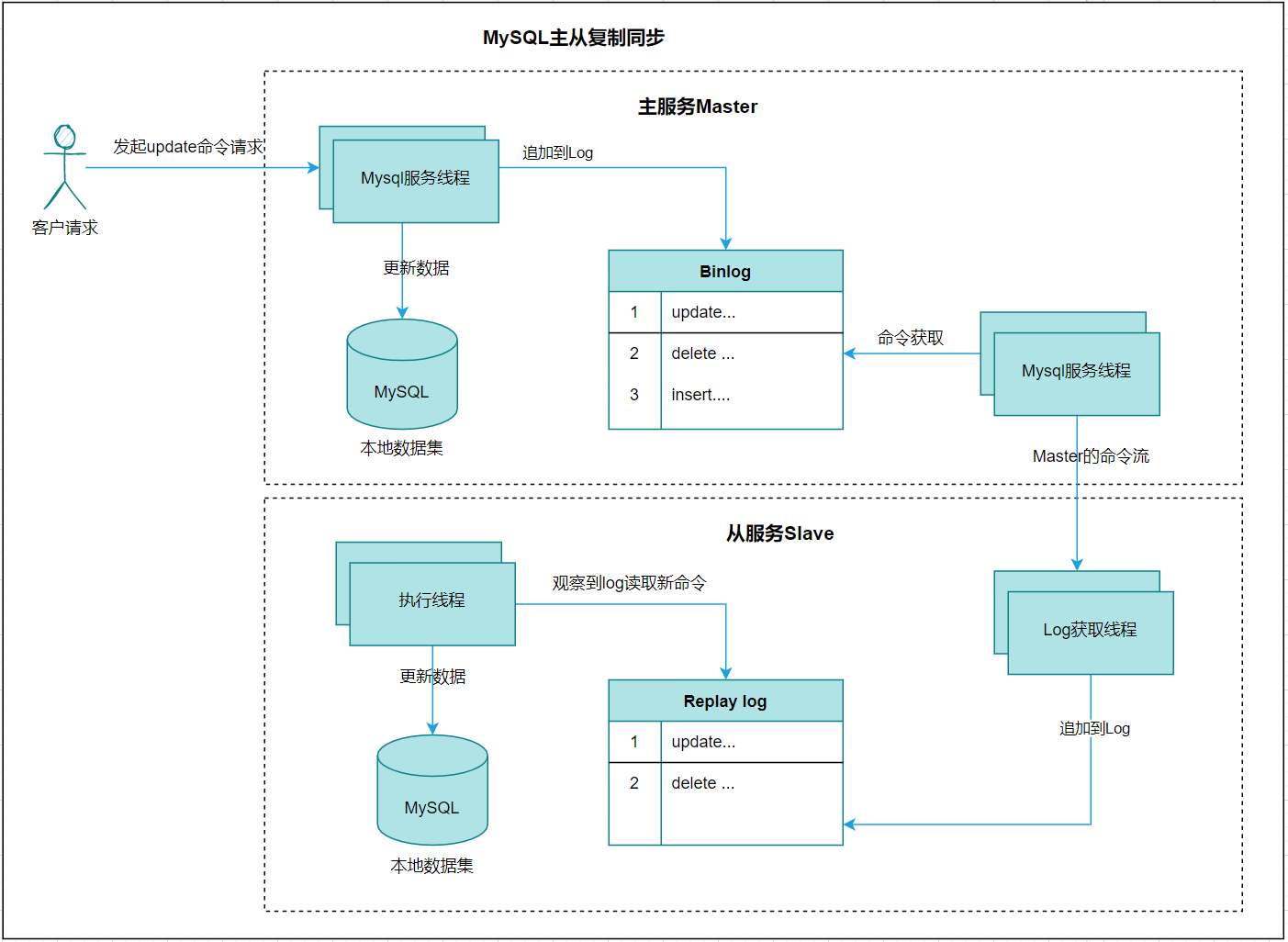
主从复制主要目的是实现数据库读写分离,写操作访问主数据库,读操作访问从数据库,从而使数据库具有更强⼤的访问负载能力,⽀撑更多的用户访问。
它的主要的复制原理是:当应⽤程序客户端发送⼀条更新命令到数据库的时候,数据库会把这条更新命令同步记录到 Binlog 中,然后由另外⼀个线程从 Binlog 中读取这条日志,然后通过远程通讯的方式将它复制到从服务器上面去,从服务器获得这条更新日志后,将其加入到自己的 Relay log 中,然后由另外⼀个 SQL 执⾏线程从 Relay log 中读取这条新的日志,并把它在本地的数据库中重新执行一遍。这样当客⼾端应⽤程序执⾏⼀个 update 命令的时候,这个命令会在主数据库和从数据库上同步执行,从而实现了主数据库向从数据库的复制,让从数据库和主数据库保持⼀样的数据。
主主复制工作流程
主主复制⽅案是指两台服务器都当 作主服务器,任何⼀台服务器上收到的写操作都会复制到另⼀台服务器上。
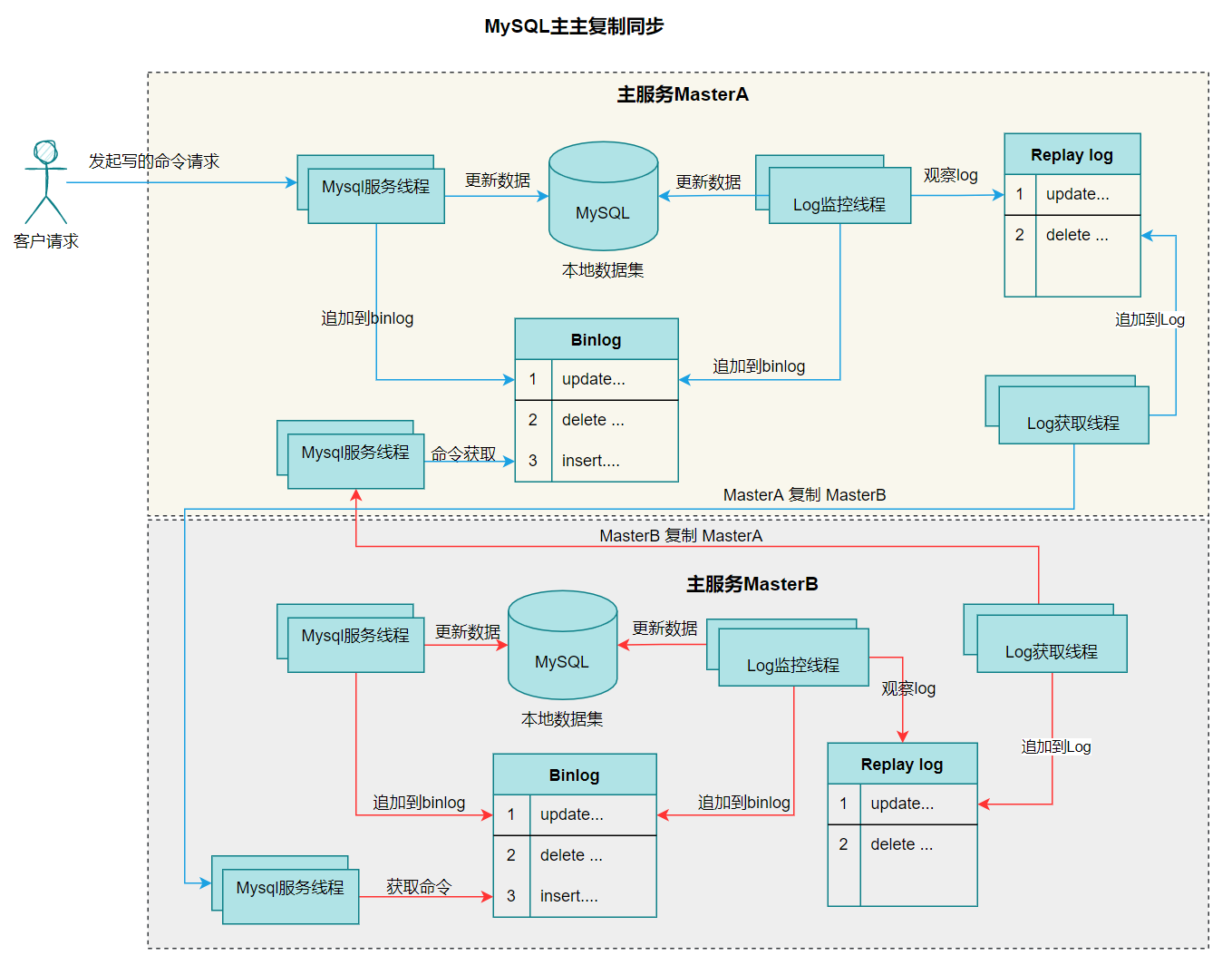
如上图所示,当客⼾端程序对主服务器 A 进⾏数据更新操作的时候,主服务器 A 会把更新操作写⼊到 Binlog 日志中。然后 Binlog 会将数据日志同步到主服务器 B,写入到主服务器的 Relay log 中,然后执 Relay log,获得 Relay log 中的更新日志,执⾏SQL 操作写⼊到数据库服务器 B 的本地数据库中。
B 服务器上的更新也同样通过 Binlog 复制到了服务器 A 的 Relay log 中,然后通过 Relay log 将数据更新到服务器 A 中。
通过这种方式,服务器 A 或者 B 任何⼀台服务器收到了数据的写的操作都会同步更新到另⼀台服务器,实现了数据库主主复制。主主复制可以提⾼系统的写高可⽤。但处理逻辑、部署、运维会复杂很多。
主主复制存在问题:
不要对两个数据库同时进⾏数据写操作,因为这种情况会导致数据冲突。
复制只是增加了数据的读并发处理能力,并没有增加写并发的能⼒和系统存储能力。
更新数据表的结构会导致巨大的同步延迟。
4、多读多写方案二
MySQL 分库分表
MySQL 分库分表也是相当成熟的方案,可以用一些开源的中间件如:MyCat,ShardingJdbc 等进行代理。查询和写入都实现分库分表,写入和查询性能能够实现较大的提升。
因为数据都散列到各个分片,数据规模打散,数据服务器处理数据能力会有较大的提升。
利用 MyCat 和 ShardingJdbc 组件作代理,相当中间有一层路由分发,对应用程序相对友好,原有程序代码不用太大的改动,进行基本规则配置即可实现。
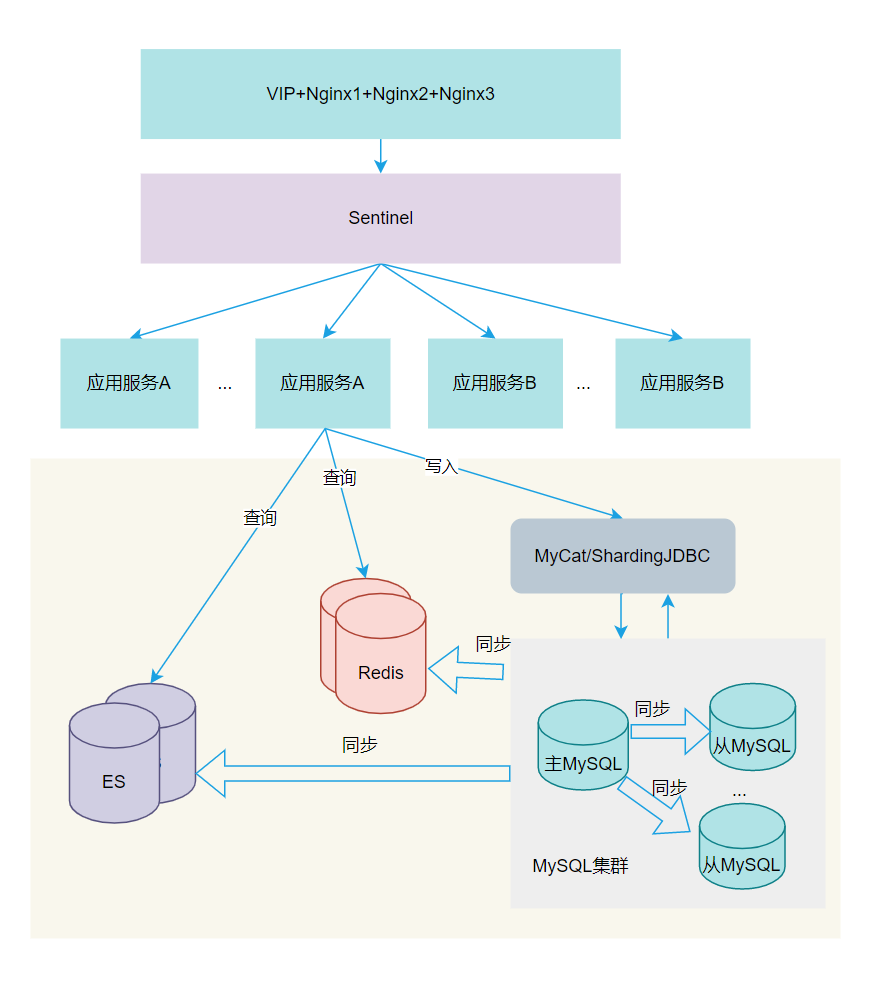
相应带的问题是:
应用程序处理逻辑会变得比较复杂;
数据打散之后,读写性能是提高了,但对数据运营和运维会带来很多的不方面(例如:发现数据有一些问题,想上去查询分析一下数据,这就比较麻烦了,得从程序逻辑解析打散的算法,然后聚合起来再去查询)。
5、多读多写方案三
增加其他中间件缓冲
在写入多的情况,如果不想拆分数据库,可以增加一些中间来做缓解。
如增加消息中间件 MQ,它可以进行错峰填谷,使用程序异步化,排队慢慢处理;同时也可增加熔断限制的组件,比如 Sentinel 组件。Sentinel 免费开源、配置使用简单、学习成本低。
Sentinel 以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应过载保护、热点流量防护等多个维度保护服务的稳定性。上面提到其他方案也可以增加 Sentinel 组件,可根据业务场景需要选择是否使用,并不会冲突。
增加 MQ 组件(可以选择 RabbitMQ 或 RocketMQ 都是免费开源的),一方面可以解耦服务间的依赖,另一方面起到限流缓冲作用,让写入队列慢慢排队操作,不至于冲跨数据库。
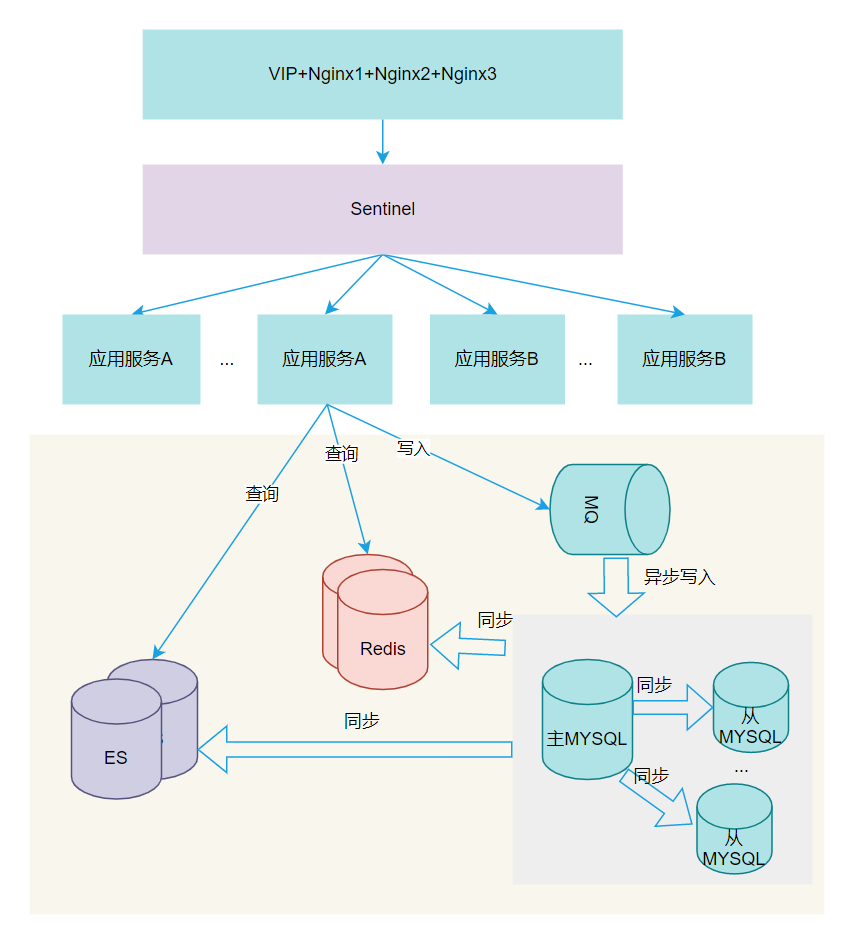
增加 MQ+Sentinel 组件是起到限流熔断降级作用,可保持在高并发条件下不至于服务被冲跨,但本质上只是保持服务高可用,并没有整个体上提高系统的并发量。
如果在百万级别以上并发量下,虽然系统可以实现高可用,但是大部分用户限流了阻挡在外面,用户体验并不友好!
6、多读多写方案四
使用 NOSQL 数据库替换
NOSQL 数据库也有很多可选方案,这里推荐使用 TIDB,不是广告!我们在实际生产业务使用验证过,按官方最低配置(一个集群最小要求 7 台高配服务器);
TIDB 为大处理大规模数据而设计的,查询性能非常优秀(比 MySQL 高效得多了),我们写入并发 TPS 可以去到 2 万左右,这个已经是一个相当大的并发量。如果并发再提升也可以随时扩展。
TIDB 是国产数据库,免费开源,使用 KV 底层实现上层关系型数据库,设计理念非常先进。TIDB 本身就是定位为分布式数据库,可以根据自己业务量实现水平扩展,这是个相当了不起的产品。
使用 TIDB 的好处有哪些?
1、最大好处是原来的业务端代码基本不用改,切换数据源就可以了,100%兼容 Mysql 语法,当然如果你使用了 Mysql 一些特殊语法,如存储过程,特殊函数是不支持的。
2、可以承载高并发业务场景数据库水平扩展,多写多读都可以。

这种架构呢,基本在百万级并发量也是能扛得住的。因为应用可以实现水平扩展,数据库也可以实现水平扩展,可以说是解决了两大核心关键问题。
我们现有的业务场景中有一块,设计应用 BOM 数据记录,每天增量产生大约 40 亿条记录数据,24 小时访问量并不是均摊的,高峰时并发量 QPS 也接近 70 多万。最开始是使用 MySQL 方案,一主多从,多主多从,分库分表各方案都试过根本顶不住,线上经常出现假死、满载等问题,搞得焦头烂额的。最后没有办法试用 TIDB,也类似上图架构方案。跑了近 2 年没有啥问题,从而验证证明这种方案的可靠性。
所以一般业务并发访问量在百万级别的体量,都推荐使用这种架构省心省事,总体算下来成本也不高。
还是那个三原则:简单、高效、低成本。
当然坏处也有的,就是需要增加一笔不少的服务器资源费用,对团队技术成员学习有一定成本、运维也有一定成本。
不过话说回来,如果说系统真有那么大流量说明公司业务大,说明业绩很好,这些投入不值一提。
假设并发量、访问量进一步提升,达到千万级访问量,应该是怎么办呢?这种巨量并发访问量是互联网头部那几家公司才会有的,一般普通企业大概率没有机会到达这个量级。
千万级别并发方案是有的,先偷个懒,下回补上!这里权当学习研究,因为我们公司的访问量也没有达到量级,不好证实方案有效性和可行性。
7、微服务体系下极简之万能架构
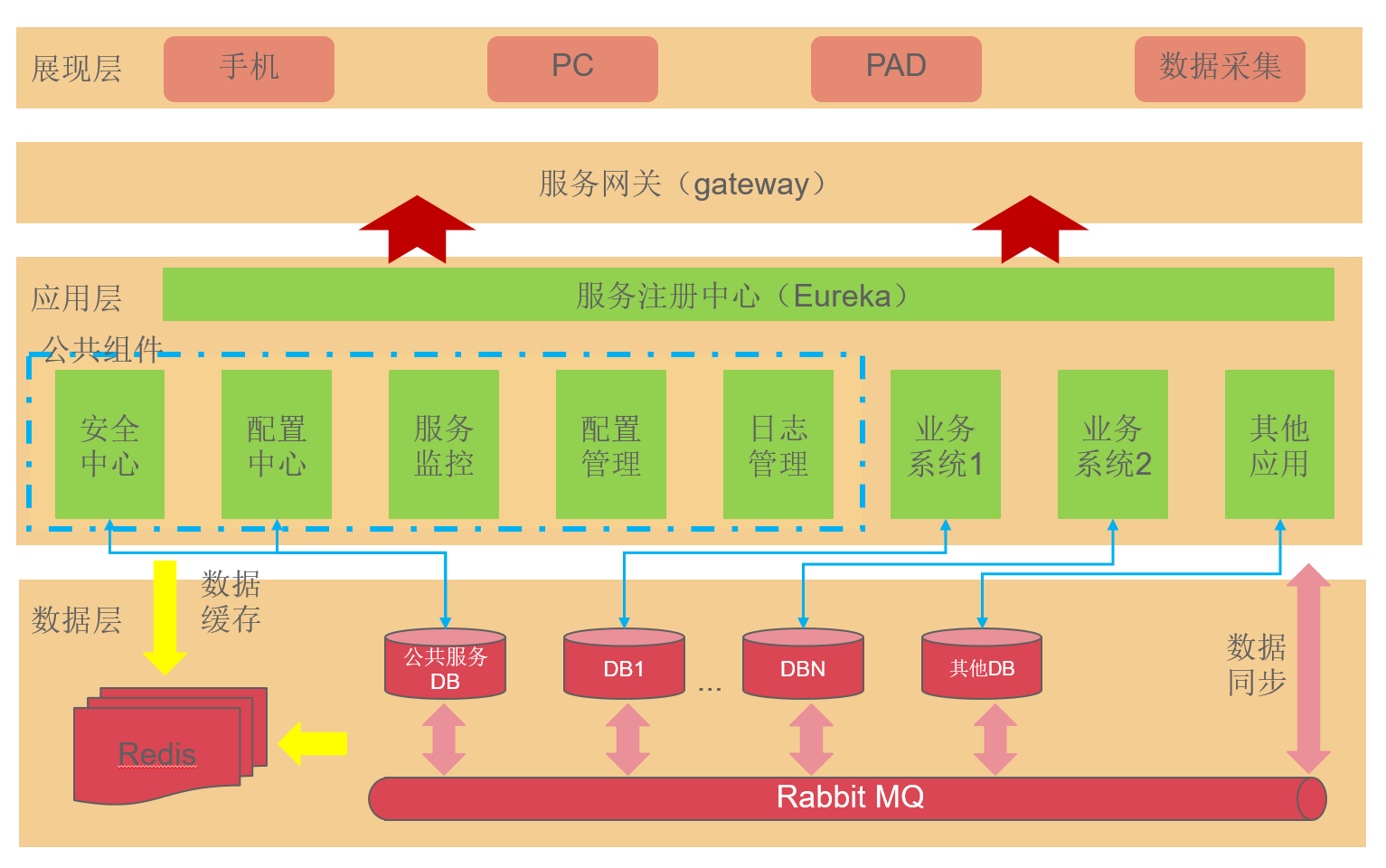
在 SpringCloud 体系下组件非常多,采用最简基本组件注册中心、配置中心和网关,其最简组合:Eureka+Gateway+Redis+Mysql+MQ
当然注册中心推荐 nacos 来代替。nacos 是阿里团队免费开源、稳定、也同时支持多种协议(http、dubbo 等);nacos 除了注册中心作用之外自带配置中心,这样好个好处是减少额外部署一个配置中心。
(1)最简版 SpringCloud 微服务分层示意
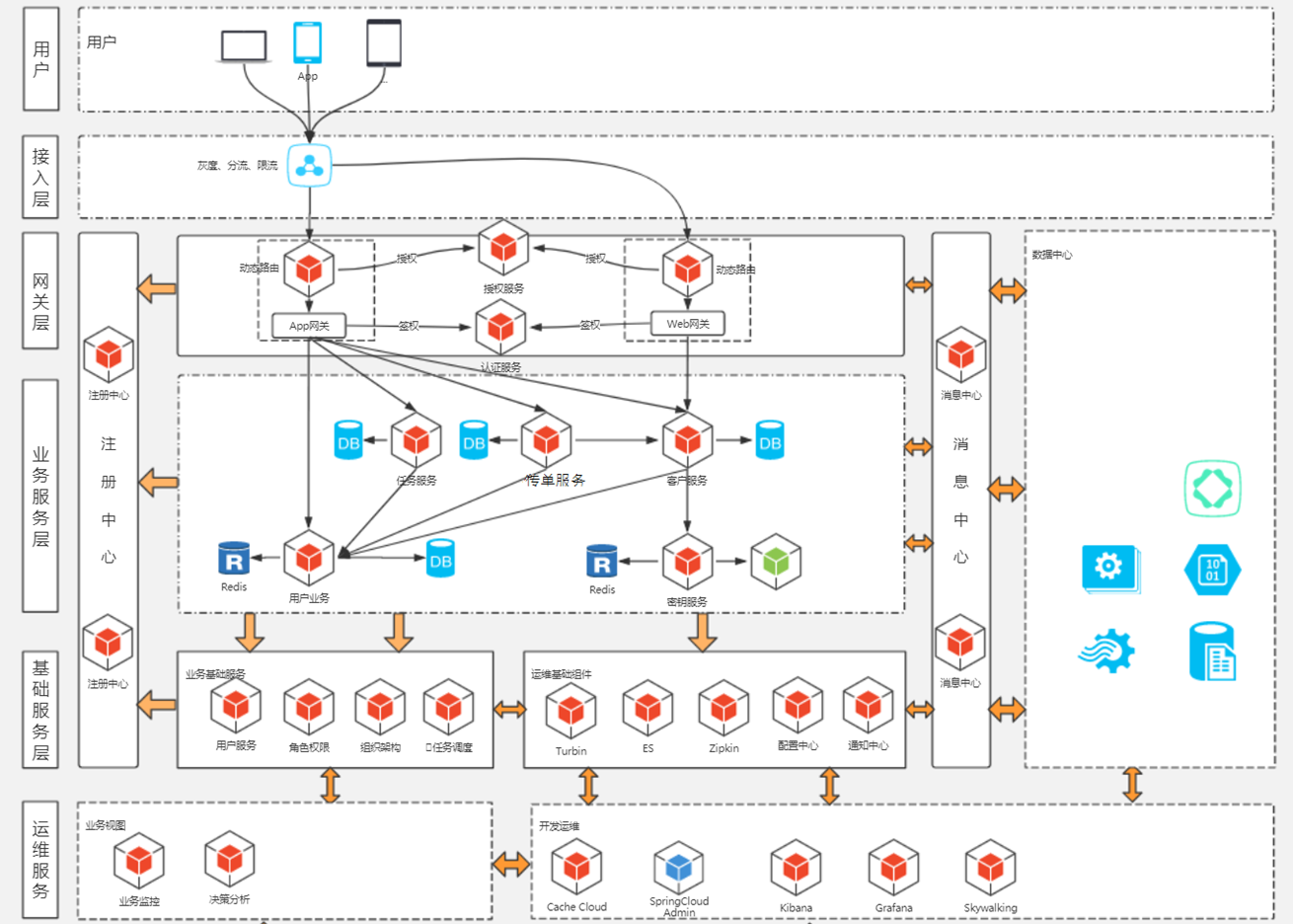
(2)我们公司微服务架构
这是几年前我们公司搭的微服务架构,这几年来没有什么太大改变。跑了几年下来也说明架构是稳定可靠的。
不过近期在搞云原生,是有较大改变,因还没有上线,没有验证生产实际情况下,所以新的架构还等一段时间再来分享。
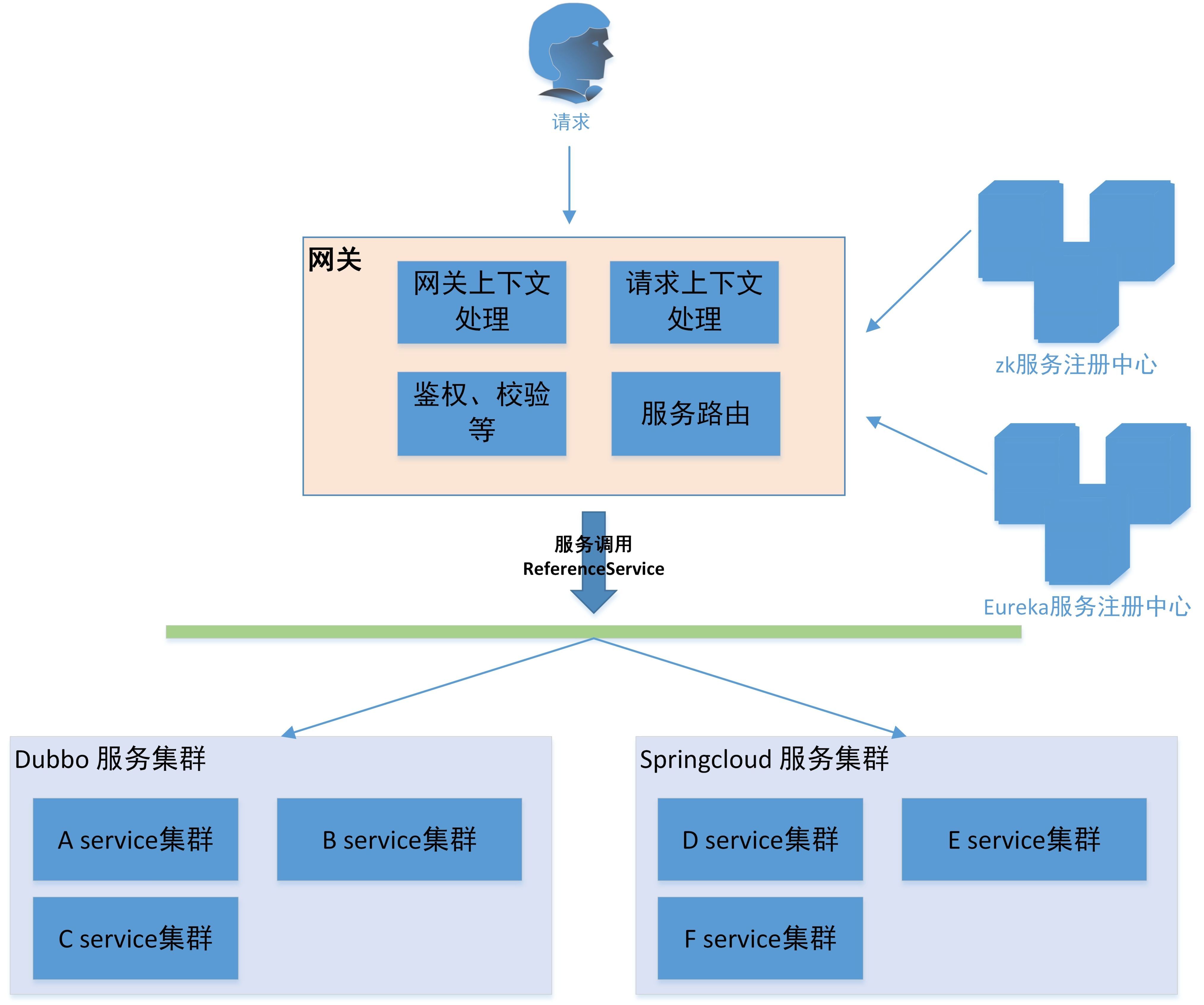
(3)微服务混合体架构
这个架构是混合 Springcloud 和 dubbo 两种微服务架构并存。这种曾经在我们的系统架构中存活过一段时间,为什么要设计这样的架构?其实有一定的历史原因,平台一开始使用了 dubbo 体系,后面改用 SpringCloud 体系。
原因如下:
早些年 SpringCloud 并不成熟,多少存一些问题,当时部署更多是出于试验考虑,核心业务并不敢往生产上放;
Dubbo 有一段时间停更状态(最后版本是 2.5.3),隔了几年之后再重启更新的;
两个体系架构中间存在切换周期,两个注册中心两种架构共存了近一年。
其实一直保持两种微服务架构存在也是可以的。只不过是调用者可能会混乱,当时我们为保持团队统一认识,减少误用的情况下,最后决定全切了 SpringCloud 体系。
建议各位在实际业务使用当中,也可以根据自己的业务实际情况需要,选择合适的微服务架构。
8、总结
1、软件世界里没有“万金油”,选择低成本最适合于业务场景的应用软件架构就达到目的了;
2、所谓万能架构也是带有条件的,就是根据自己业务量规模大小、技术条件选择最低成本架构方案;
3、微服务架构还有很多其他方案选择,目前来说 Springcloud 是相对比较低成本的架构设计方案。
文章转载自:陈国利

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论