
数据结构 - 堆
今天我们将学习新的数据结构-堆。
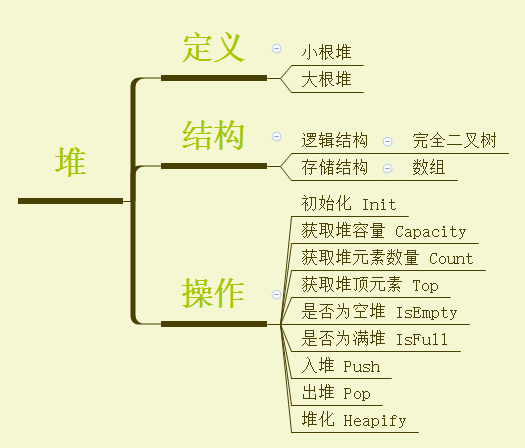
01、定义
堆是一种特殊的二叉树,并且满足以下两个特性:
(1)堆是一棵完全二叉树;
(2)堆中任意一个节点元素值都小于等于(或大于等于)左右子树中所有节点元素值;
小根堆,根节点元素永远是最小值,即堆中每个节点元素值都小于等于左右子树中所有节点元素值;
大根堆,根节点元素永远是最大值,即堆中每个节点元素值都大于等于左右子树中所有节点元素值;
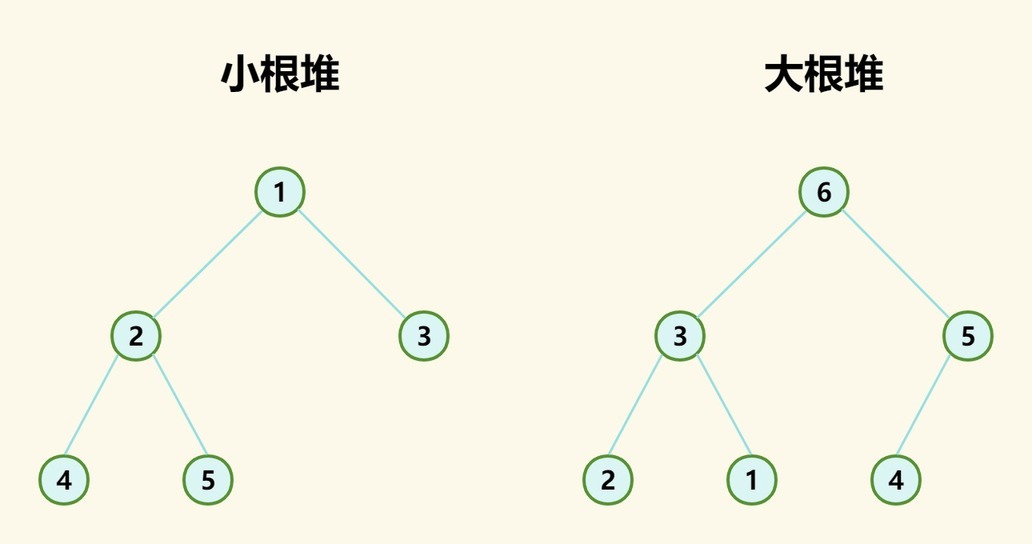
根据堆的定义我们不难发现,堆特别适合用来求集合最值,以及求最值引申的问题比如:排序、优先队列、动态排名等等
02、结构
我们指定堆是一种特殊完全二叉树,因此堆的逻辑结构是树。
我们指定树的存储结构有两种,顺序存储(数组)和链式存储(链表),那么堆的存储结构是什么呢?
既然堆是完全二叉树,那么树的存储结构当然也适用于堆。但是堆一般都选用顺序存储(数组)实现。其原因有三:
(1)位置计算简单:数组实现堆可以使用完全二叉树特性用简单的数学公式即可表示父子节点的索引关系,从而避免了链表实现使用额外的指针,即减少内存开销和实现复杂度;
(2)性能好:数组的连续内存特性使得其有高效的访问速度,而链表因为节点不一定连续访问速度相对较差;
(3)操作简单:数组实现在逻辑实现上更加简单高效,通过交换数组中的元素即可快速实现堆的性质,链表实现在插入和删除操作中需要遍历链表效率远不如数组实现;
总结一句话数组简单、内存连续、性能更好,所以一般选用数组实现堆,当然不一般的情况也可以使用链表实现。
03、实现(最小堆)
下面我们就用数组来实现一个最小堆结构,最大堆只是比较大小不同这里就不做过多赘述。
1、初始化 Init
首先我们需要定义两个私有变量,一个变量用来存放堆元素的数组,一个变量用来存放数组尾元素索引,主要用来跟踪当前堆元素个数情况。
而初始化方法就是初始化两个变量,创建指定容量数组,以及标记数组尾元素索引为-1,表示堆中还没有元素。
2、获取堆容量 Capacity
堆容量指的是数组的固定空间,即数组最多能容纳多少个元素,直接返回数组长度即可。
3、获取堆元素数量 Count
堆元素数量指当前堆中一共有多少个元素,我们可以通过私有字段数组尾元素索引值加 1 获得。
4、获取堆顶元素 Top
堆顶元素指树节点中的根节点,也就是数组中的第一个元素。同时要注意判断数组是否为空,为空报异常。
5、是否为空堆 IsEmpty
空堆即堆中还没有任何元素,当数组尾元素索引为-1 时表示空堆。
6、是否为满堆 IsFull
满堆即堆空间已满不能再添加新元素,当数组尾元素索引等于数组容量减 1 时表示满堆。
7、入堆 Push
入堆即向堆中新添加一个元素。
而入堆也涉及到一个问题,就是如何保存每次添加完新元素后,还保持着堆的特性。很显然我们也没办法做到直接把新元素直接插入到其正确的位置上,因此我们可以梳理新添加一个元素的流程,可能大致有以下几个步骤:
(1)首先把新元素添加到堆的末尾;
(2)然后调整堆使其满足堆的性质;
(3)更新堆尾元素索引;
而难点显然就在第二步,如何调整数组使其满足堆的性质?
我们先直接模拟把 7654 按顺序推入堆中,看看如何实现。
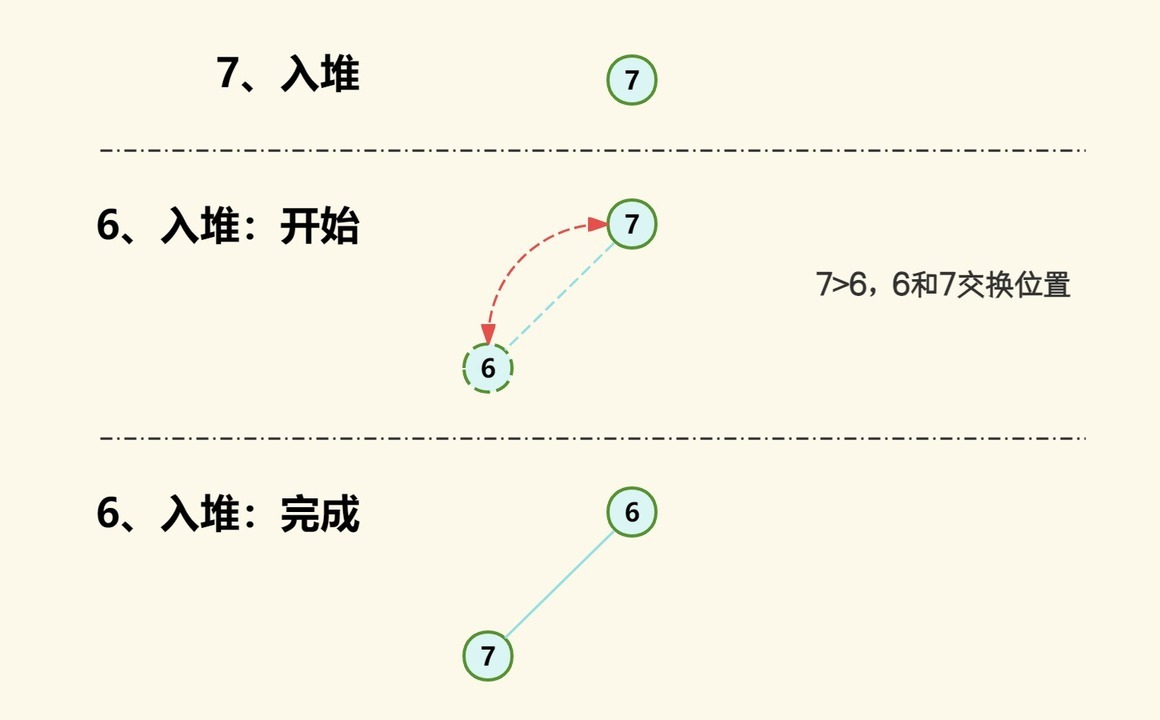
(1)首先 7 入堆,此时只有一个元素,无需做任何操作,而 7 就作为根节点;
(2)然后 6 入堆,此时已有两个元素,因此需要保持堆的两个特性:根节点永远是最小元素和堆是完全二叉树。由完全二叉树特性可得,根节点左子节点索引为 20+1=1,而右子节点索引为 20+2=2,而此时 6 的索引为 1,所以 6 为左子节点;又因 6 比 7 小,所以根节点变为 6, 7 变为根节点的左子节点;
(3)然后 5 入堆,此时已有 3 个元素,所以 5 的索引为 2,而根节点右子节点索引为 2*0+2=2,所以 5 添加为根节点的右子节点。5 比 6 小,所以 5 和 6 交互位置;
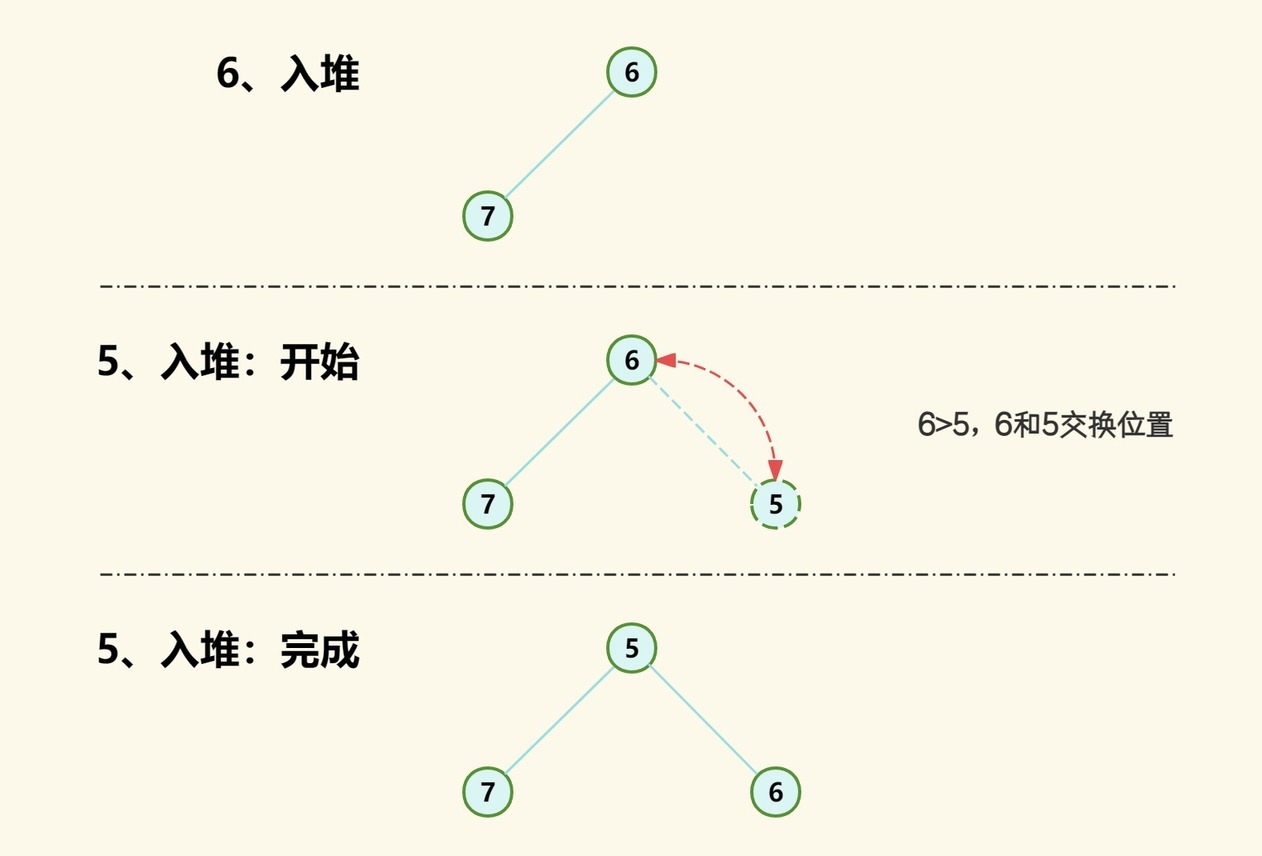
(4)然后 4 入堆,此时已有 4 个元素,所以 4 的索引为 3,而 7 节点左子节点索引为 2*1+1=3,所以 4 添加为 7 节点的左子节点。4 比 7 小,所以 4 和 7 交互位置; 再次比较 4 和 5,4 比 5 小,所以 4 和 5 交互位置;
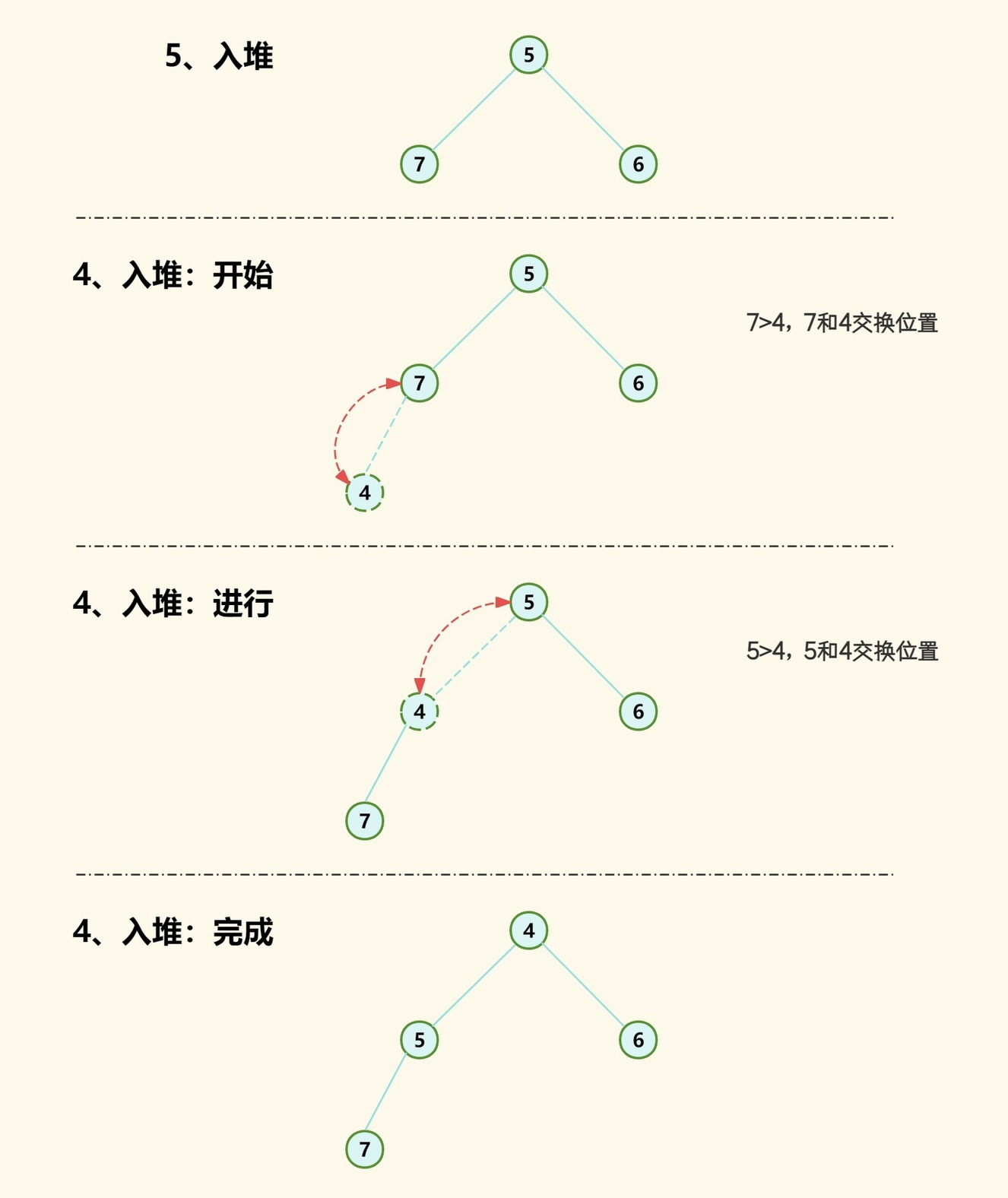
相信到这里大家已经看出一点规律了,调整整个数组元素使其满足堆的性质的整个过程大致分为以下几个步骤:
(1)从新元素开始向上比较其与父节点元素的值大小;
(2)如果新元素值小于其父节点元素值,则交互两者位置,否则结束调整;
(3)重复以上步骤直至处理到根节点。
代码实现如下:
8、出堆 Pop
出堆即删除并返回堆顶元素(堆中最小元素)。
而出堆同样也涉及到和入堆同样的问题,就是如何保存每次删除元素后,还保持着堆的特性。
显然删除和添加元素情况还不一样。添加新元素后还是一棵完全二叉树,只不过可能没有满足堆的性质,所以需要调整。而删除就不一样了,想象一下当我们把堆顶元素删除后,回怎样?根节点空了,此时还能较完全二叉树吗?显然不能。
如何处理呢?直观的想法就是根节点空了就用其子节点补充上呗,就这样从上到下一直填补,直至最后的空落在了叶子节点那一层,如果这个空位落到了叶子节点左侧,而右侧还有值,此时就表明堆不满足完全二叉树这一特性,因此还需要把这个空位移到堆的末尾,想象都头大。这显然不是一个好办法。
既然我们最后要把根节点删除后的这个空位移到堆的末尾,何不直接把这个空位和堆的尾元素直接调换个位置呢,然后再参考出堆中调整整个数组使其满足堆的性质。
我们梳理整个流程,可能大致有以下几个步骤:
(1)首先获取堆顶元素并暂存;
(2)将堆尾元素赋值给堆顶元素,并将堆尾元素置空;
(3)然后调整堆使其满足堆性质;
(4)更新数组尾元素索引,并返回暂存的堆顶元素;
而难点同样在第二步,如何调整数组使其满足堆的性质?入堆是新元素在堆尾所以是从下往上进行调整,而出堆是堆顶元素需要调整是否可以从上往下进行调整呢?
我们把 87654 按顺序推入堆中后把 4 推出堆中,看看如何实现。
首先删除根节点 4,并把堆尾元素 8 放到根节点;
为了保持堆特性,找出根节点及其子节点中最小元素并与当前根节点 8 交互位置,因为 8>6>5,所以 5 与 8 交互位置;
然后 8 节点继续与其子节点进行比较,因为 8>7,所以 7 与 8 交互位置。
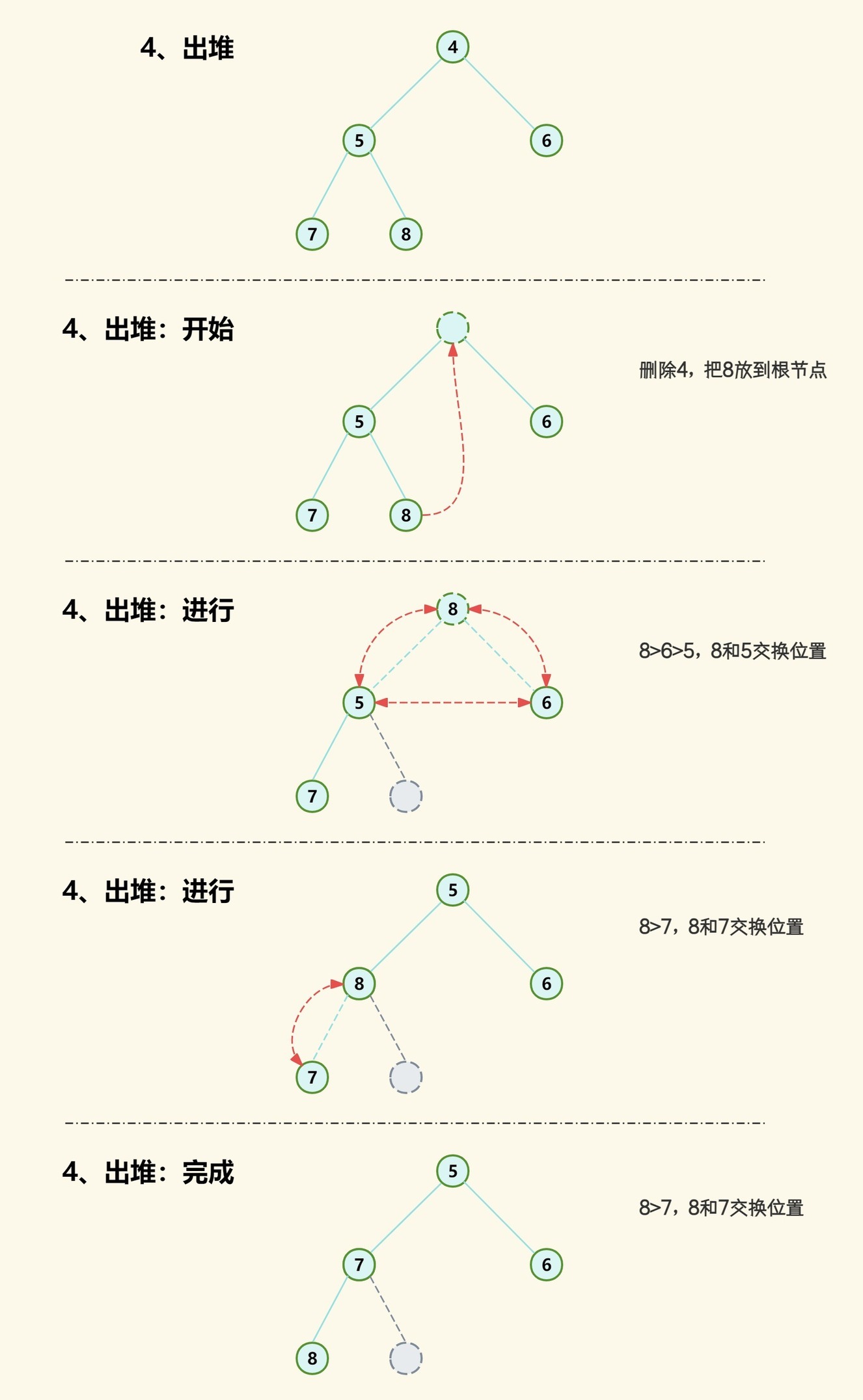
这一出堆过程我们可以总结为以下步骤:
(1)从当前节点开始,找到其子节点元素值;
(2)比较当前节点元素值与其子节点元素值大小,如果当前节点值最小则结束调整,否则取值最小的与其交互;
(3)重复以上步骤直至处理到叶子节点。
代码实现如下:
9、堆化 Heapify
堆化即把一个无序数组堆化成小根堆。
可以通过调用出堆是用到的调整方法来完成。大家可以思考一下为什么不是堆尾元素开始调整?为什么是从下往上调用向下调整方法调整?
文章转载自:IT规划师

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论