
利用 Kubernetes 降本增效?EasyMR 基于 Kubernetes 部署的探索实践

Kubernetes 是用于编排容器化应用程序的云原生系统。最初由 Google 创建,如今由 Cloud Native Computing Foundation(CNCF)维护更新。
Kubernetes 是市面上最受欢迎的集群管理解决方案之一。它自动化容器化应用程序的部署、扩展和管理,允许管理和协调跨多个主机的容器集群,提供容错性和可伸缩性等服务。
简单点说,如果你的应用程序可以容器化(例如,借助 Docker),那么绝对应该使用 Kubernetes 来运行和管理这些应用程序。在 k8s 的支持下,可以大大提高本地或云托管基础架构的利用率,所有计算资源都可以在多个应用程序之间动态而合理地共享。
Kubernetes 负责在整个应用生命周期中调度并自动执行与容器相关的任务,包括部署、运维、服务发现、存储配置、负载均衡、自动扩展、自我治愈实现高可用性等等。
如今,Kubernetes 和更广泛的容器生态系统日益成熟,成为通用的计算平台和生态系统,可与作为现代云基础架构和应用基本构建块的虚拟机 (VM) 一争高下,甚至大有后来居上之势。但是 Kubernetes 本身是一个比较复杂的平台,一个运维或者开发人员如果要说快速精通 Kubernetes 是不可能的,所以这就提高了传统运维开发人员使用其的门槛。
EasyMR 作为一款提供一站式可视化组件安装部署与可观测运维管理能力的大数据计算引擎产品,我们自然也基于 Kubernetes 部署进行了实践探索。
EasyMR 基于 Kubernetes 部署的探索
之前我们讨论的 EasyMR 都是基于主机集群的模式下,需要部署服务就需要先接入主机,然后部署对应产品包服务从而完成应用集群的快速搭建。但是随着云原生相关技术栈(容器、微服务、服务网格等)和 Kubernetes 近些年的流行,传统模式也急需更新换代以适应大趋势的发展。所以我们决定在 EasyMR 原有的基于产品包部署的产品模式基础上,全新打造一个容器化部署的版本。
前面我们说过,由于 Kubernetes 自身的复杂性,一般开发运维人员使用起来是比较费力的,比如控制器(Deployment/Daemonset/Statefulset/Job/CronJob),存储(PVC/PV/StorageClass)等等,所以我们还是将复杂性交给平台去解决,暴露给用户的交互则是通俗易懂的。
在主机集群模式下,部署服务的步骤为下载包->解压缩安装包->配置下发->服务启动,EasyMR 自身的 easyagent 可以做到服务的全生命周期管理。基于 Kubernetes 的架构下,我们再去开发对应版本的 agent 也是可以做到的,但是经过对市面上一些开源服务的调研,我们发现 kubevela 正好可以弥补我们这部分能力。
kubevela 使用 OAM(Open Application Model),本质是根据软件设计的关注点分离原则对负责的 DevOps 流程的高度抽象和封装,一个以应用为中心的 Kubernetes API 分层,这种模型旨在定义云原生应用的标准。
作为 EasyMR 平台,基于 kubevela,我们只需要提供多种可扩展的组件类型,便可以对上层用户屏蔽 Kubernetes 的底层复杂实现逻辑。使用 EasyMR 部署 Kubernetes 服务的用户只需要关注服务类型以及修改应用配置,便可以实现服务的部署,关于 kubevela/OAM 更详细的部分我们会在后面的文章中介绍,本文便不多赘述。
对 EasyMR 而言,部署服务的维度始终是产品包,这点我们并没有去做更改,产品包的核心就是 schema 文件。因此,我们扩展了一些字段以适应 Kubernetes 部署的要求。

上述表格的 workload 表示服务类型,比如说平台内置主从 MySQL 的 workload,那么只需要在产品包中声明服务类型是 MySQL 以及镜像的名称,当执行部署的时候,平台会自动创建 MySQL 的有状态应用 statefulset、配置文件 configmap、服务 service、存储 pv/pvc 等等 Kubernetes 底层资源。大大节省了人力成本,提升了交付效率,后续如果需要扩展组件类型也可以在平台迭代中逐步完善。
EasyMR 云化部署架构如下图所示:
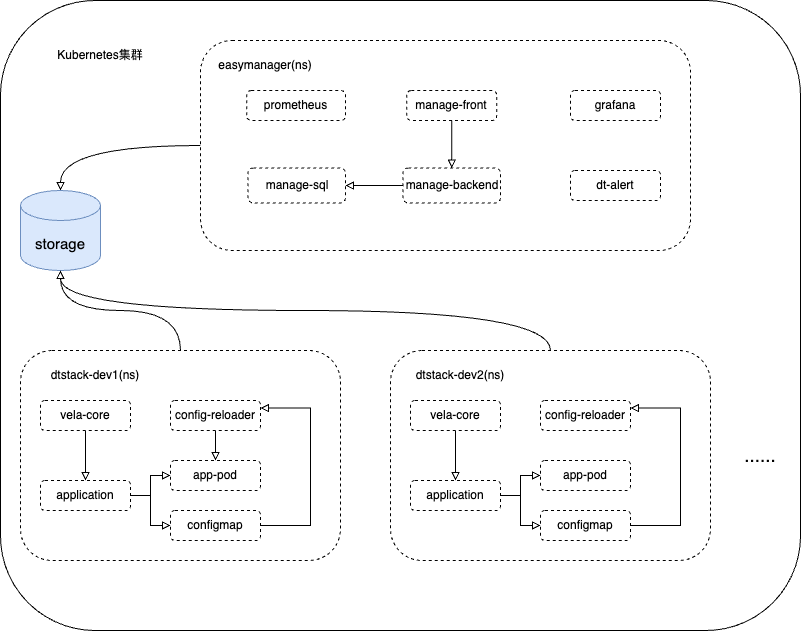
架构图中 vela-core 是核心部署组件,config-reloader 会动态监测 Pod 使用的 configmap 的更新状态从而重启应用 Pod。
EasyMR 基于 Kubernetes 的未来探索
EasyMR 作为基于云原生技术和 Hadoop、Hive、Spark、Flink、Hbase、Presto 等开源大数据组件构建的弹性计算引擎,做到能部署大数据组件只是里程碑中的第一步,未来我们的目标会投向更长远的地方——存算分离:
● 使用 Kubernetes 替代 Yarn 作为调度组件
以 Flink 和 Spark 为代表的分布式流批计算框架的下层资源管理平台逐渐从 Hadoop 生态的 YARN 转向 Kubernetes 生态的 Kubernetes 原生 scheduler 以及周边资源调度器,比如 Volcano 和 Yunikorn 等。
● 使用对象存储+缓存加速
随着云计算技术的成熟,企业存储又多了一个选项——对象存储。最早从 AWS 开始,后来所有的云厂商都在向这个方向发展,用对象存储去替换 HDFS。
但是对象存储用于支持 Hadoop 这样复杂的系统,会出现以下问题:文件 Listing 性能较弱;对象存储没有原子 Rename 从而影响任务的稳定性;对象存储数据最终一致性的机制会降低计算过程中的稳定性和正确性。所以我们还需要 Alluxio/Juicefs 这样的缓存加速层来提升我们使用对象存储的性能。
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
《数栈 V6.0 产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szinfoq
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术 qun」,交流最新开源技术信息,qun 号码:30537511,项目地址:https://github.com/DTStack
版权声明: 本文为 InfoQ 作者【袋鼠云数栈】的原创文章。
原文链接:【http://xie.infoq.cn/article/e8c8a1a30043304c1235b02f2】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2021-05-06 加入
还未添加个人简介









评论