
文件系统崩溃一致性、方法、原理与局限
前言
先提几个问题:什么是文件系统崩溃一致性?为什么会出现文件系统崩溃一致性问题?有哪些方法可以解这个问题?它们各自又有哪些局限性?
window 系统电脑异常后会蓝屏、手机死机卡顿后我们会手动给它重启,大部分设备的系统在遇到不可修复的严重异常后都会尝试通过重启来恢复,因为系统重启之后,系统整体比较"干净"。
其中有一例外,就是我们希望磁盘存储的数据无论在系统出现何种异常的情况下,都能够保存好原来的数据,系统恢复后可以再找到异常前的所有数据。
文件系统崩溃一致性(Crash Consistency)是指在文件系统发生崩溃、断电或其它不可预见的故障后,文件系统能够保证数据的一致性和完整性,并能够恢复到一个合法且可操作的状态,确保系统重新启动或恢复之后,数据不会出现损坏、丢失或不一致的情况。
(一)一致性的复杂性
以 ext4 文件系统举例,当我们创建一个文件系统的时候,有下面 4 个步骤:
查找空闲 inode:通过检查 inode bitmap 找到一个空闲的 inode,并在 inode bitmap 中标记为已使用。
分配数据块:通过检查 block bitmap 找到空闲的数据块,并在 block bitmap 中标记为已使用。
更新 inode:将新文件的元数据写入 inode table 中的相应位置。
更新目录项:在目标目录的 inode 数据块中添加一个新的目录项,包含文件名和对应的 inode 号。
因为磁盘是以扇区为最小单位,所以上面 4 个步骤不可能一次全部写入到磁盘中去,在 1 到 4 步骤中间的任意一个时间点系统突然崩溃,都会导致文件系统不一致。比如在 2~3 步骤中间断电,就会造成 inode bitmap、block bitmap 中标记已经使用,但是没有实际的文件与之对应,如果不回收,那么这几个块就可能永远不会被使用。
在实际使用的时候,情况会更加地复杂,因为系统为了提升文件系统的读写检索性能,在挂载文件系统的时候,系统会将文件系统的元数据缓存到内存上。如下图《图 1.1 内存与存储结构》
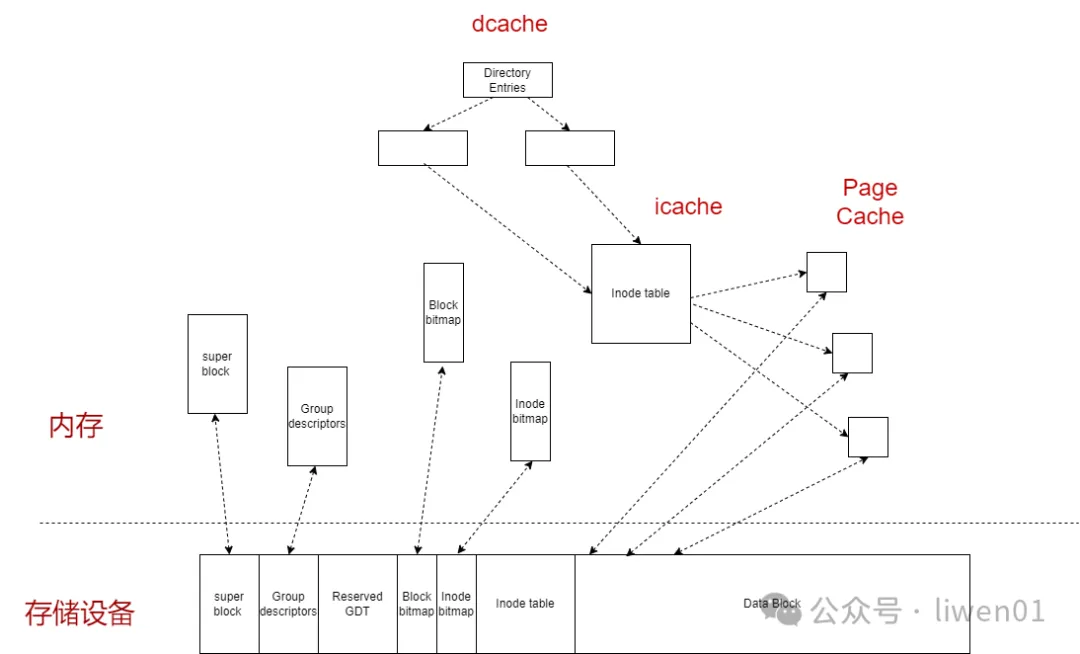
图 1.1 内存与存储结构
在有缓存的情况下,数据一般是定时写入磁盘,或者是手动保存才会写入磁盘,一次完成批量数据的写入。如果在这个过程中突然异常,丢失的数据可能会更加多。
有多少人经历过电脑突然断电,辛辛苦苦写的内容全部被丢失。系统崩了,内心也崩了。
关于 ext4 文件系统的详细介绍,可以查看文章《文件系统(六):一文看懂linux ext4文件系统工作原理》
解决文件系统一致性的问题,常用的方法有:日志、写时复制、Soft Update、日志文件系统,它们各有优缺点,目前并没有哪种方案可以适用所有场景。
(二)文件系统日志
(1)日志工作原理
在 ext4 文件系统中,有一个独立的日志数据区,它的基本思想是:先将一组操作记录到日志区(日志提交完成),然后再去实现这些操作(应用事务完成),实现结束之后再把日志擦除(日志清理完成)。
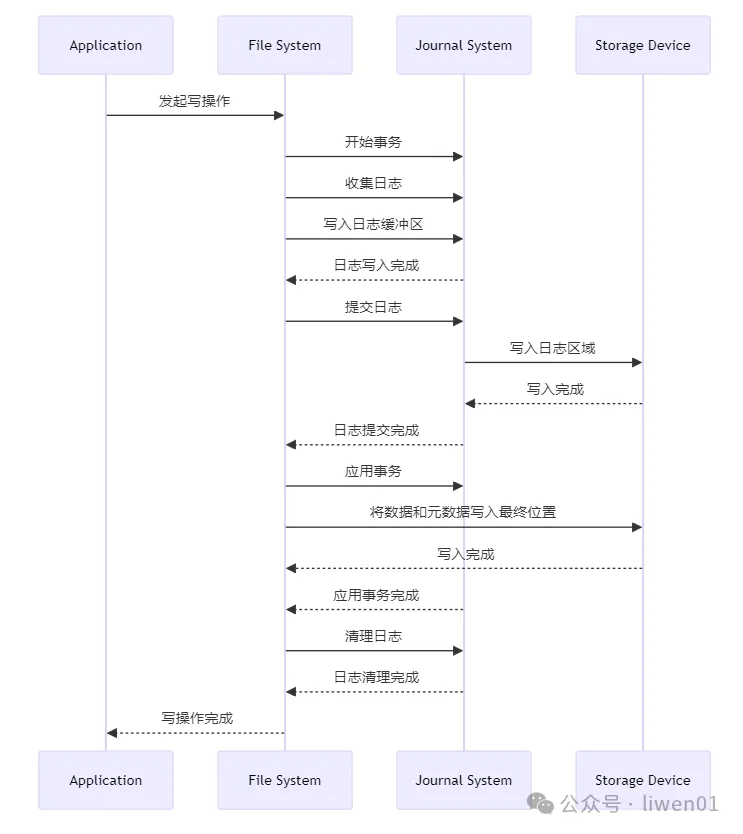
日志处理时序流程图
事务开始:文件系统开始一组更新操作,并开启一个新的事务
收集日志:收集所有即将修改的数据(以及在 Journal 模式下的数据)
提交日志:更新日志头,标记该事务已经提交(commit)
应用事务:将日志中的修改应用到文件系统,将数据和元数据写入最终位置
清理日志:事务完成后,日志系统清理已提交的日志记录
(2)通过日志进行恢复
文件系统有了日志功能之后,在文件系统崩溃或是突然断电后就可以通过日志保持文件系统的一致性。基本的流程是,文件系统挂载后,系统会去扫描日志区域,看是否有未完成的事务,如果有,则判断该事件是否有提交:
如果未提交,本次修改操作就直接丢弃
如果有提交,根据日志记录的信息,重新执行修改操作
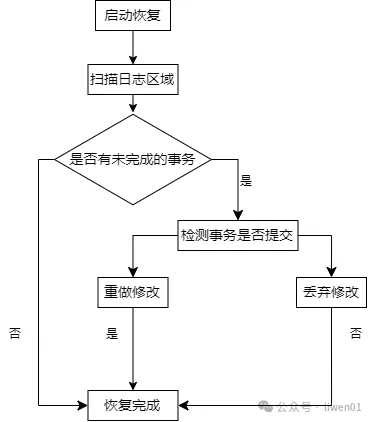
日志恢复流程
(3)优缺点
文件系统的日志功能,它的主要优点有两个:
可以保持一致性: 不会因为某些异常导致整个文件系统异常
可以减少文件系统检查时间: 传统使用 fsck 去扫描整个磁盘进行检查,非常耗时,有了日志功能后,直接扫描日志信息就可以了。
文件系统引入日志之后,明显的缺点有:
影响性能: 所有的操作都需要先写日志,再执行具体的操作,在高负载的情况下会导致 IO 压力增加,从而降低系统的整体性能。
写热点: 因为日志区会频繁的写入和擦除,对于有擦写次数限制的 flash 来说,比较容易把日志区域写穿。
(4)ext4 的日志模式
ext4 文件系统用 JBD2 实现的日志有三种模式:Writeback、Ordered、Journal
Writeback 模式:
在这种模式下,元数据变更会被记录到日志中,但数据的变更不会被记录。数据写入磁盘的顺序不受元数据更新的顺序影响。
优点:性能较高,因为减少了日志记录的数据量。
缺点:数据一致性较差,在崩溃后,文件可能会包含新元数据指向的旧数据。
Ordered 模式:
这是 ext4 文件系统的默认日志模式。元数据变更会被记录到日志中,数据的变更虽然不记录,但数据写入磁盘的顺序必须在相应的元数据更新之前。
优点:在性能和数据一致性之间提供了平衡。崩溃后,文件不会包含新元数据指向的旧数据,因为数据写入总是在元数据更新之前完成。
缺点:性能比 writeback 模式略低,因为需要保证数据先于元数据写入。
Journal 模式:
在这种模式下,所有数据和元数据的变更都会被记录到日志中。数据和元数据都被完整地写入日志,然后再写入主文件系统。
优点:提供最高的数据一致性保障。在崩溃恢复时,所有已提交的数据和元数据变更都可以被恢复。
缺点:性能较低,因为所有数据都需要写两次,一次写入日志,一次写入主文件系统
(三)写时复制(Copy on Write)
Copy-on-Write(COW,写时复制)在在计算机中应用非常多,比较常见的是在内存中的写时复制。文件系统中的写时复制与内存中的写时复制有些不一样。在文件系统崩溃一致性中,COW 它的基本原理是,在需要修改数据时,不直接在原数据位置进行修改,而是将数据复制到新位置进行修改,只有在修改完成后,才更新指针或元数据指向新的数据位置。
(1)基本原理
COW 技术的核心思想是推迟实际数据写入的时间,直到必须进行修改为止。具体步骤如下:
读取数据:当需要读取数据时,直接从现有的数据块读取。
写入数据:当需要写入数据时,不直接修改现有的数据块,而是复制一份数据块到新位置。
修改数据:在新的数据块上进行修改操作。
更新元数据:在确保新数据块写入成功后,更新指向数据块的元数据,使其指向新的数据位置。
释放旧数据:如果旧的数据块不再被引用,则可以将其标记为可用空间。
(2)工作流程
以 Btrfs 为例,COW 的工作流程如下:
当用户修改文件时,Btrfs 首先在新位置分配一个新的数据块。
将旧数据块中的内容复制到新数据块。
在新数据块上应用用户的修改。
修改完成后,更新 Btrfs 的元数据,将指针从旧数据块指向新数据块。
在确保所有元数据更新都完成后,旧数据块可以被标记为可用空间。
(3)应用实例
Btrfs 和 ZFS:Btrfs(B-tree 文件系统)和 ZFS(Zettabyte 文件系统)是两种广泛使用的支持 COW 的文件系统。它们利用 COW 技术来提高数据一致性和完整性。
快照和克隆:COW 允许高效地创建数据快照和克隆。例如,在 Btrfs 中,可以通过 COW 技术快速创建文件系统的快照,而无需复制实际数据。
事务性操作:通过 COW,文件系统中的修改可以被视为事务性操作。只有当所有修改都成功完成后,才会更新元数据指针,这确保了在崩溃发生时,文件系统处于一致的状态。
(4)优势
数据一致性:由于数据修改是在新位置进行的,系统崩溃时旧数据仍然保持不变,确保数据一致性。
崩溃恢复:在崩溃恢复过程中,通过检查元数据,可以快速确定哪些数据块是有效的,哪些是未完成的修改。
高效快照:COW 技术允许文件系统高效地创建和管理快照,因为快照只需复制元数据指针,而不需要复制实际数据。
(5)缺点
性能开销
写放大效应:COW 会导致写放大效应,因为每次写入操作都需要分配新的数据块,并将数据复制到新位置。这可能会增加写操作的延迟,尤其在写入频繁的场景下
额外的元数据更新:由于每次写入都需要更新元数据指针,这会增加文件系统的元数据操作负担,影响整体性能。
磁盘空间利用效率
磁盘空间碎片化:COW 技术会导致磁盘空间碎片化,因为每次写入都会创建新的数据块。这可能会导致文件系统中的空闲空间变得不连续,从而降低磁盘空间利用效率。
空间消耗:由于每次写入需要新的数据块,因此在频繁的写操作下,磁盘空间的消耗速度会加快,尤其是在快照和克隆操作频繁的情况下。
数据恢复和修复复杂性
数据恢复时间:在发生系统崩溃或其他故障时,尽管 COW 能确保数据一致性,但恢复过程可能会较为复杂,需要检查和重建元数据。
修复工具的复杂性:文件系统需要复杂的修复工具来处理和修复 COW 带来的元数据和数据问题,这增加了系统维护的复杂性。
硬件依赖性
对存储硬件的要求:COW 技术对存储硬件的性能有较高要求,尤其是在频繁写操作或快照操作的情况下。使用慢速存储设备可能会显著降低系统性能。
(四)Soft Updates
Soft Updates 是通过有序地更新元数据以确保文件系统的一致性,同时尽可能减少性能开销。与日志和 Copy-on-Write(COW)技术相比,Soft Updates 提供了一种不同的路径来实现崩溃一致性。
(1)基本原理
Soft Updates 的核心思想是控制文件系统元数据更新的顺序,以确保即使在系统崩溃时,文件系统仍然保持一致性。具体方法包括以下几个步骤:
依赖关系跟踪:记录元数据更新之间的依赖关系,确保更新顺序满足一致性要求。
延迟写入:延迟写入元数据的某些更新,直到所有相关依赖关系得到满足为止。
批量处理:将多个相关的元数据更新批量处理,以减少磁盘 I/O 操作次数。
(2)工作流程
创建和删除文件:
在创建文件时,首先更新目录条目,然后更新文件的 inode。
在删除文件时,先更新文件的 inode,再更新目录条目。这确保了即使系统崩溃,仍然不会出现目录指向已删除文件的情况。
分配和释放数据块:
分配数据块时,先更新 inode 中的指针,再标记数据块为已使用。
释放数据块时,先标记数据块为未使用,再更新 inode 中的指针。这防止系统崩溃后出现数据块被多次分配的情况。
更新元数据:
所有元数据更新操作都在内存中进行排序,确保在写入磁盘时满足依赖关系。
在写入磁盘之前,检查所有依赖关系,确保更新顺序正确。
(3)优势
提高性能:由于不需要像日志功能那样记录每次操作的日志,Soft Updates 在一定程度上减少了磁盘 I/O 操作,从而提高了性能。
一致性保证:通过有序的元数据更新,确保文件系统即使在崩溃后也能保持一致性。
减少写放大效应:相比 COW,Soft Updates 通过批量处理和延迟写入减少了写放大效应,节省了磁盘空间和 I/O 操作。
(4)缺点
实现复杂性:Soft Updates 的实现需要精确跟踪和管理元数据更新之间的依赖关系,增加了文件系统的复杂性。
内存消耗:为了管理依赖关系和批量处理更新,Soft Updates 需要在内存中维护大量的状态信息,可能增加内存消耗。
有限的应用范围:Soft Updates 主要适用于元数据更新频繁的场景,对于数据更新频繁的场景,其优势不明显。
(五)日志文件系统(Log-structured File System)
这里介绍的日志文件系统(Log-structured File System,LFS),与上面介绍的 ext4 的日志功能不是同一个东西,LFS 采用了完全不同的方法来管理数据和元数据,以提高性能和崩溃一致性。
(1)基本原理
日志文件系统(LFS)的核心思想是将所有数据和元数据的更新操作记录到一个连续的日志结构中,而不是直接在原数据块上进行写操作。其基本原理如下:
日志结构:LFS 将所有写操作都追加(append)到一个称为日志(log)的连续区域中,而不是覆盖现有的数据块。
数据和元数据更新:当有写操作时,LFS 将更新操作追加到日志中,并在日志中记录新的数据块或更新的元数据。
后台回收:为了保持文件系统性能,LFS 周期性地执行后台任务,将日志中的更新整理并合并成新的数据块,然后释放不再使用的旧数据块。
崩溃一致性:由于所有的更新都是追加到日志中,而不是直接在原始数据位置上修改,当系统崩溃时,可以通过重放日志来恢复文件系统状态,从而确保数据的一致性。
(2)工作流程
写操作:
当文件系统执行写操作时,LFS 将新的数据或更新的元数据追加到日志中。
日志中的写入是顺序的,因此可以通过顺序写入优化性能。
后台合并:
定期或在需要时,LFS 执行后台任务,将日志中的更新合并成新的数据块。
合并过程中可以优化数据的排列顺序,并释放不再需要的旧数据块。
崩溃恢复:
在系统崩溃或重新启动时,LFS 通过重放日志中的操作来恢复文件系统的状态。
因为所有更新都是追加的,可以确保文件系统在崩溃后仍然保持一致性,避免数据损坏或丢失。
(3)优势
崩溃一致性:通过日志追加和重放机制,确保系统崩溃后可以快速恢复到一致状态。
写性能:顺序写入日志结构可以显著提高写入性能,特别是在高负载和随机写入场景下。
数据恢复:由于数据和元数据的更新都是追加到日志中的,即使发生意外的系统崩溃,也可以通过重放日志来恢复数据,而不会丢失已经提交的更新。
(4)缺点
读操作性能:由于数据的读取可能分散在不同的日志块中,可能导致随机读取性能下降,尤其是在较大的文件系统上。
空间利用率:由于数据是追加到日志中的,可能会产生碎片化的数据存储,从而影响磁盘空间的有效利用。
实现复杂性:设计和实现一个高效的日志文件系统需要处理复杂的数据结构和算法,这可能增加系统的开发和维护成本。
(5)应用
在嵌入式设备中, 经常使用 jffs2 文件系统进行参数保存,虽然 jffs2 是专门为闪存设计的文件系统,但它的设计也是 LFS 的原理来设计的。
结尾
上面介绍了日志、写时复制、Soft Update、日志文件系统的方法来解决文件系统的一致性问题,这里还有一个问题,我们经常使用的 U 盘或是 SD 卡,它并没有使用上面的任何一种机制,为什么我们在实际使用的时候,很少能感觉到丢数据呢?甚至还经常直接热拔插它们。这个问题我们在下一篇中解释。
文章转载自:liwen01

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论