
Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力 Few-Shot 和 Zero-Shot 任务”

Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力 Few-Shot 和 Zero-Shot 任务”
通过设计提示(prompt)模板,实现使用更少量的数据在预训练模型(Pretrained Model)上得到更好的效果,多用于:Few-Shot,Zero-Shot 等任务。
1.背景介绍
prompt 是当前 NLP 中研究小样本学习方向上非常重要的一个方向。举例来讲,今天如果有这样两句评论:
什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
这破笔记本速度太慢了,卡的不要不要的。
现在我们需要根据他们描述的商品类型进行一个分类任务,
即,第一句需要被分类到「水果」类别中;第二句则需要分类到「电脑」类别中。
一种直觉的方式是将该问题建模成一个传统文本分类的任务,通过人工标注,为每一个类别设置一个 id,例如:
这样一来,标注数据集就长这样:
这种方法是可行的,但是需要「较多的标注数据」才能取得不错的效果。
由于大多数预训练模型(如 BRET)在 pretrain 的时候都使用了 [MASK] token 做 MLM 任务,而我们在真实下游任务中往往是不会使用到 [MASK] 这个 token,这就意味着今天我们在训练下游任务时需要较多的数据集去抹平上下游任务不一致的 gap。
那,如果我们没有足够多的训练数据怎么办呢?
prompt learning 的出现就是为了解决这一问题,它将 [MASK] 的 token 引入到了下游任务中,将下游任务构造成和 MLM 类似的任务。
举例来讲,我们可以将上述评论改写为:
然后让模型去预测两个 [MASK] token 的真实值是什么,那模型根据上下文能推测出被掩码住的词应该为「电脑」。
由于下游任务中也使用了和预训练任务中同样的 MLM 任务,这样我们就可以使用更少的训练数据来进行微调了。
但,这还不是 P-tuning。
通过上面的例子我们可以观察到,构建句子最关键的部分是在于 prompt 的生成,即:
被括号括起来的前缀(prompt)的生成是非常重要的,不同 prompt 会极大影响模型对 [MASK] 预测的正确率。
那么这个 prompt 怎么生成呢?
我们当然可以通过人工去设计很多不同类型的前缀 prompt,我们把他们称为 prompt pattern,例如:
但是人工列这种 prompt pattern 非常的麻烦,不同的数据集所需要的 prompt pattern 也不同,可复用性很低。
那么,我们能不能通过机器自己去学习 prompt pattern 呢?
这,就是 P-Tuning。
1.1 P-Tuning
人工构建的模板对人类来讲是合理的,但是在机器眼中,prompt pattern 长成什么样真的关键吗?
机器对自然语言的理解和人类对自然语言的理解很有可能不尽相同,我们曾经有做一个 model attention 和人类对语言重要性的理解的对比实验,发现机器对语言的理解和人类是存在一定的偏差的。
那么,我们是不是也不用特意为模型去设定一堆我们觉得「合理」的 prompt pattern,而是让模型自己去找它们认为「合理」的 prompt pattern 就可以了呢?
因此,P-Tuning 的训练一共分为:prompt token(s) 生成、mask label 生成、mlm loss 计算 三个步骤。
1.1.1 prompt token(s) 生成
既然现在我们不用人工去构建 prompt 模板,我们也不清楚机器究竟喜欢什么样的模板……
那不如我们就随便凑一个模板丢给模型吧。
听起来很草率,但确实就是这么做的。
我们选用中文 BERT 作为 backbon 模型,选用 vocab.txt 中的 [unused] token 作为构成 prompt 模板的元素。
[unused] 是 BERT 词表里预留出来的未使用的 token,其本身没有什么含义,随意组合也不会产生很大的语义影响,这也是我们使用它来构建 prompt 模板的原因。
那么,构建出来的 prompt pattern 就长这样:
1.1.2 mask label 生成
完成 prompt 模板的构建后,我们还需要把 mask label 给加到句子中,好让模型帮我们完成标签预测任务。
我们设定 label 的长度为 2('水果'、'电脑',都是 2 个字的长度),并将 label 塞到句子的开头位置:
其中 [MASK] token 就是我们需要模型帮我们预测的标签 token,现在我们把两个部分拼起来:
这就是我们最终输入给模型的样本。
1.1.3 mlm loss 计算
下面就要开始进行模型微调了,我们喂给模型这样的数据:
并获得模型预测 [MASK] token 的预测结果,并计算和真实标签之间的 CrossEntropy Loss。
P-Tuning 中标签数据长这样:
也就是说,我们需要计算的是模型对 [MASK] token 的输出与「电脑」这两个标签 token 之间的 CrossEntropy Loss,以教会模型在这样的上下文中,被 [MASK] 住的标签应该被还原成「物品类别」。
1.1.4 实验
我们选用 63 条评论(8 个类别)的评论作为训练数据,在 417 条评论上作分类测试,模型 F1 能收敛在 76%。通过实验结果我们可以看到,基于 prompt 的方式即使在训练样本数较小的情况下模型也能取得较为不错的效果。相比于传统的分类方式,P-Tuning 能够更好的缓解模型在小样本数据下的过拟合,从而拥有更好的鲁棒性。
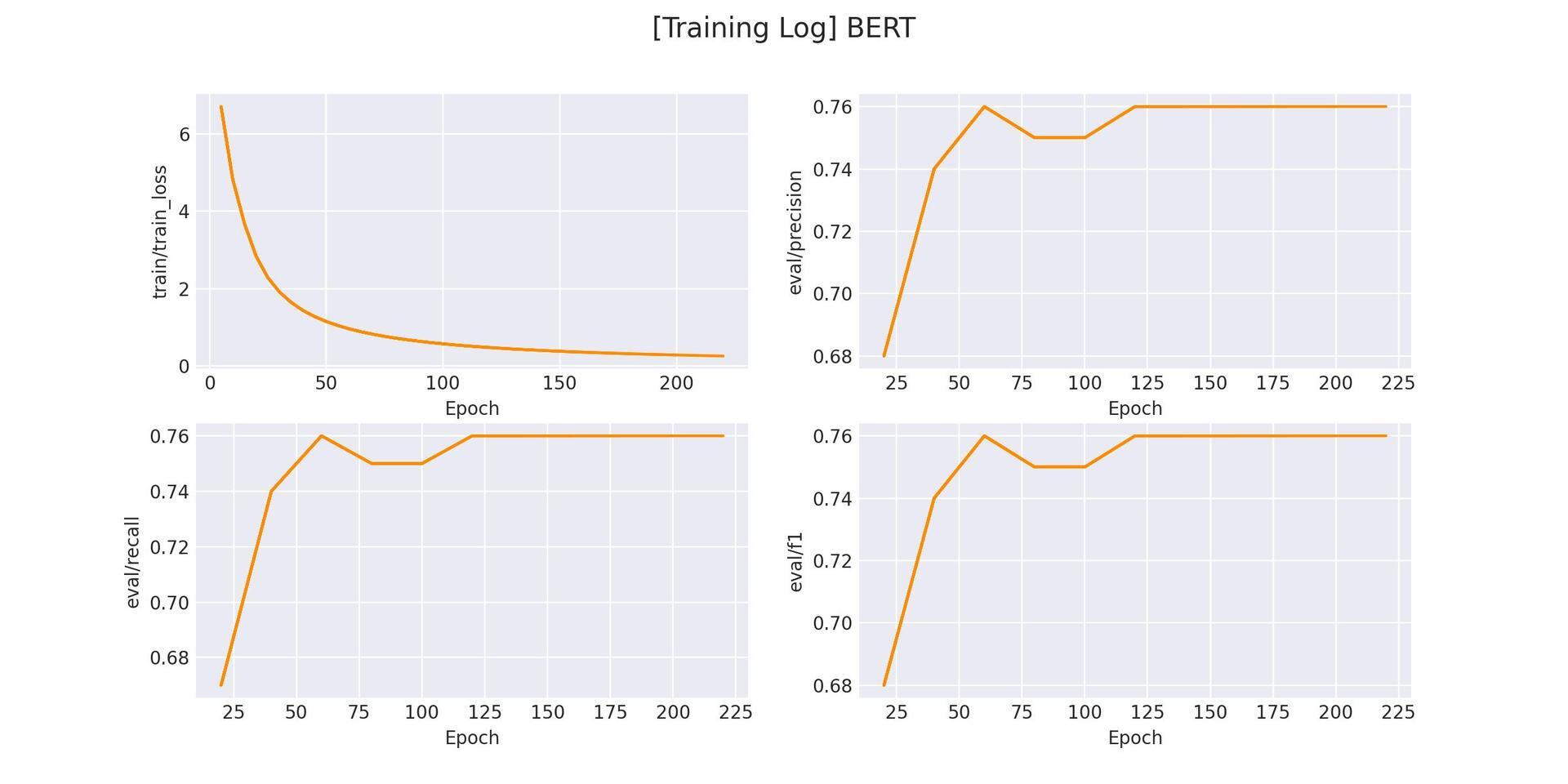
论文链接:https://arxiv.org/pdf/2103.10385.pdf
2.PET (PatternExploiting Training)
环境安装本项目基于
pytorch+transformers实现,运行前请安装相关依赖包:
2.1 数据集准备
2.1.1 标签数据准备
项目中提供了一部分示例数据,根据用户评论预测用户评论的物品类别(分类任务),数据在 data/comment_classify 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
每一行用 \t 分隔符分开,前半部分为标签(label),后半部分为原始输入。
2.1.2 Verbalizer 准备
Verbalizer 用于定义「真实标签」到「标签预测词」之间的映射。
在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
项目中提供了一部分示例数据在 data/comment_classify/verbalizer.txt 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
在例子中我们使用 1 对 1 的 verbalizer,若想定义一对多的映射,只需要在后面用 ',' 分隔即可, e.g.:
2.1.3 Prompt 设定
promot 是人工构建的模板,项目中提供了一部分示例数据在 data/comment_classify/prompt.txt 。
其中,用大括号括起来的部分为「自定义参数」,可以自定义设置大括号内的值。
示例中 {MASK} 代表 [MASK] token 的位置,{textA} 代表评论数据的位置。
你可以改为自己想要的模板,例如想新增一个 {textB} 参数:
此时,除了修改 prompt 文件外,还需要在 utils.py 文件中 convert_example() 函数中修改 inputs_dict 用于给对应的给每一个「自定义参数」赋值:
2.2. 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
正确开启训练后,终端会打印以下信息:
在 logs/sentiment_classification 文件下将会保存训练曲线图:

2.3. 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
运行推理程序:
得到以下推理结果:
3.P-tuning:Auto Learning prompt pattern
环境安装本项目基于
pytorch+transformers实现,运行前请安装相关依赖包:
3.1 数据集准备
3.1.1 标签数据准备
项目中提供了一部分示例数据,根据用户评论预测用户评论的物品类别(分类任务),数据在 data/comment_classify 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
每一行用 \t 分隔符分开,前半部分为标签(label),后半部分为原始输入。
3.1.2 Verbalizer 准备
Verbalizer 用于定义「真实标签」到「标签预测词」之间的映射。
在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
项目中提供了一部分示例数据在 data/comment_classify/verbalizer.txt 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
在例子中我们使用 1 对 1 的 verbalizer,若想定义一对多的映射,只需要在后面用 ',' 分隔即可, e.g.:
3.2 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
正确开启训练后,终端会打印以下信息:
在 logs/sentiment_classification 文件下将会保存训练曲线图:
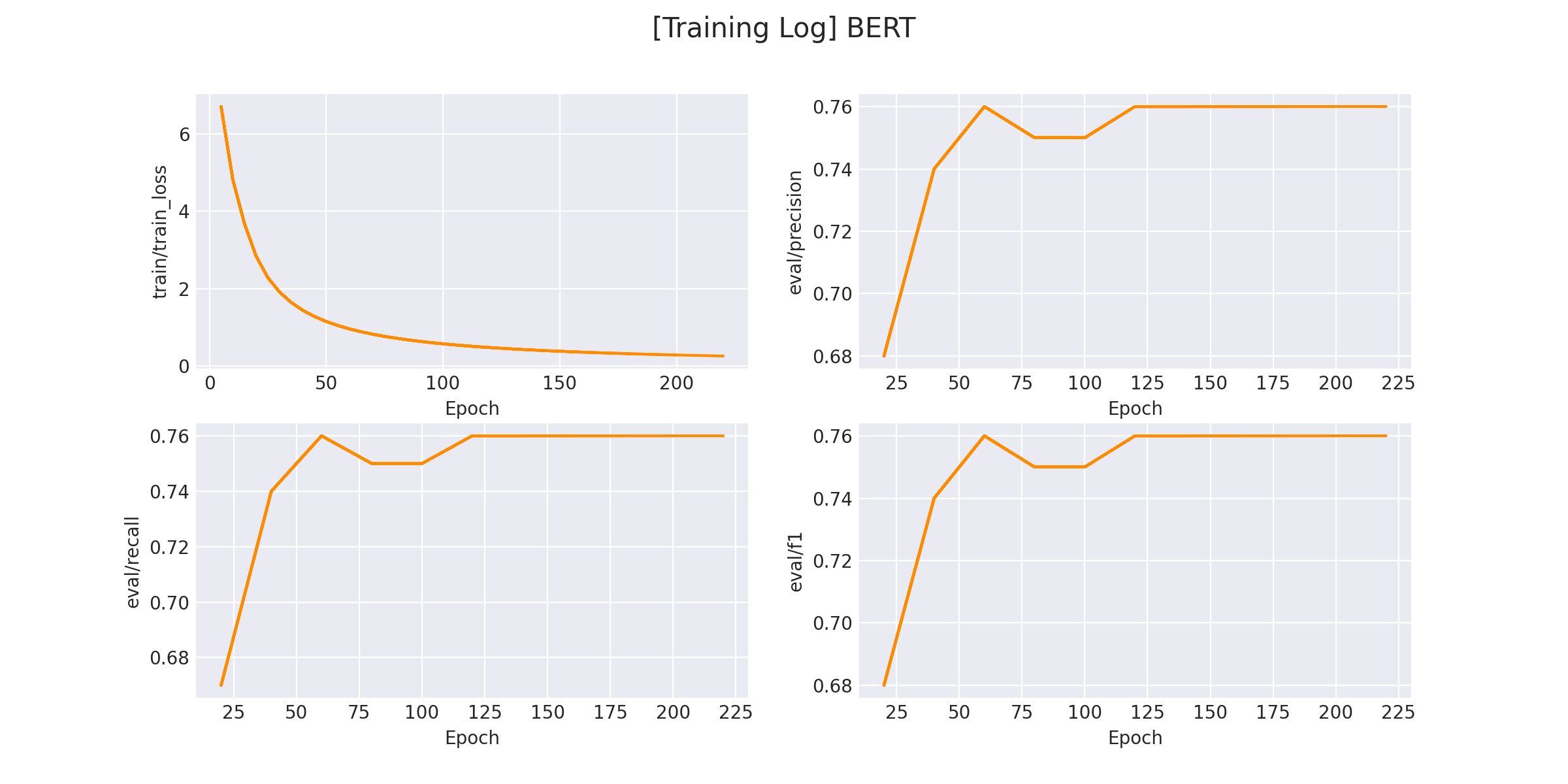
3.3 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
运行推理程序:
得到以下推理结果:
参考链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/prompt_tasks/p-tuning
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


版权声明: 本文为 InfoQ 作者【汀丶人工智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/e01bdec96d4540ec15c61cd55】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

本博客将不定期更新关于NLP等领域相关知识 2022-01-06 加入
本博客将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识,以及分享自己学习到的知识技能,感谢大家关注!








评论