
数据库的连接、创建会话与模型
SQLAlchemy 是一个强大的 Python 库,它让你可以用一种面向对象的方式来操作数据库(ORM 技术)。
在学习 SQLAlchemy 的过程中,需要一些基础知识的沉淀:Python 基础、Python 面向对象、MySQL 数据库的诸多知识点……
在此之前,你可能需要了解传统执行 SQL 语句和使用 ORM 的一些区别以及他们的概念。
什么是传统执行 SQL?
传统执行 SQL 是指直接使用 SQL 语句与数据库进行交互。这通常包括连接数据库、编写 SQL 查询、执行查询以及处理结果。
特点
直接编写 SQL 语句:你需要手动编写 SQL 查询来操作数据库。
灵活性高:可以使用所有的 SQL 功能,精确控制查询和操作。
低级别控制:你需要管理数据库连接、事务处理等。
示例
什么是 ORM(对象关系映射)?
ORM 是一种通过面向对象的方式来操作数据库的技术。ORM 将数据库表映射为类,将表中的记录映射为类的实例,使得你可以用面向对象的方式来进行数据库操作。
特点
面向对象:使用类和对象来表示数据库表和记录。
自动生成 SQL:ORM 框架会根据你的操作自动生成相应的 SQL 语句。
简化代码:简化了数据库操作的代码,使得代码更易读、更易维护。
示例
比较

适用场景
传统执行 SQL:适用于需要精细控制 SQL 查询的场景,或者需要使用复杂的 SQL 特性的场景。
ORM:适用于需要快速开发、代码可读性和维护性要求高的场景。ORM 可以大大简化常见的数据库操作。
接下来进入 SQLAlchemy 的快速学习
1. 创建数据库驱动引擎
首先,我们需要创建一个数据库驱动引擎。当你连接数据库时,需要提前创建这个数据库。
这个引擎就是你和数据库之间的桥梁。
2. 创建数据库会话
有了引擎之后,我们需要创建一个会话,这样才能和数据库进行交互。会话就像是你和数据库之间的对话窗口。
另一种创建会话的方式
3. 定义模型基类
在 SQLAlchemy 中,模型是与数据库表对应的类。我们需要定义一个基类,所有的模型都将继承这个基类。
另一种创建基类的方式
该方式也是来源于目前官方文档的示例。
4. 创建模型
现在我们基于上方的模型基类,创建一个学生模型,这个模型对应数据库中的 tb_student 表。
每个模型类对应的其实就是数据库中的表,其中表名、字段都对应了类属性的设置,而每个类的实例对象也就是一条记录。
附表:常用 Column 字段
下面是一个详细的 SQLAlchemy Column 类型及其参数的表格,包括字段的用途、存储到数据库的类型、Python 中表示的数据类型等信息。
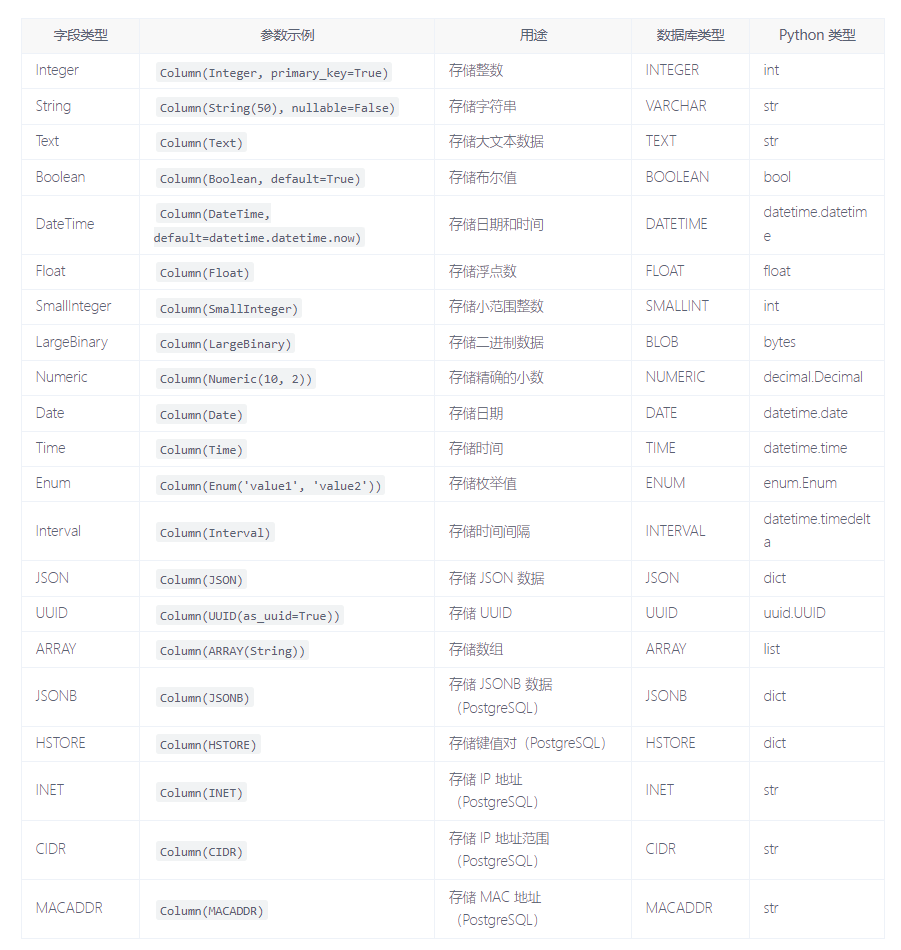
常用 Column 参数
primary_key:是否为主键。类型:
bool默认值:False示例:Column(Integer, primary_key=True)nullable:是否允许为空。类型:
bool默认值:True示例:Column(String, nullable=False)default:默认值。类型:
any默认值:None示例:Column(Boolean, default=True)unique:是否唯一。类型:
bool默认值:False示例:Column(String, unique=True)index:是否创建索引。类型:
bool默认值:False示例:Column(String, index=True)comment:字段注释。类型:
str默认值:None示例:Column(String, comment='用户名')autoincrement:是否自动递增(通常用于主键)。类型:
bool或str(好像是auto表示自增吧,忘记了,可查文档)默认值:True(在主键列上)示例:Column(Integer, primary_key=True, autoincrement=True)server_default:数据库服务器端的默认值。类型:
DefaultClause或str默认值:None示例:Column(String, server_default='default_value')server_onupdate:数据库服务器端的更新值。类型:
DefaultClause或str默认值:None示例:Column(DateTime, server_onupdate=func.now())onupdate:更新时的默认值。类型:
any默认值:None示例:Column(DateTime, onupdate=datetime.datetime.now)foreign_key:外键约束。类型:
ForeignKey默认值:None示例:Column(Integer, ForeignKey('other_table.id'))
文章转载自:顾平安

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论