
阿里云云边一体容器架构创新论文被云计算顶会 ACM SoCC 录用
近日,由阿里云撰写的关于 KOLE 创新论文被 ACM SoCC 国际会议长文录用。

ACM Symposium on Cloud Computing(以下简称 SoCC)是由美国计算机协会主办、聚焦云计算技术的一项学术会议,是云计算的首要会议。它汇集了对云计算感兴趣的研究人员、开发人员、用户和实践者,是唯一由 SIGMOD(数据管理特别兴趣组)和 SIGOPS(操作系统特别兴趣组)联合主办的会议, 这个会议在近些年蓬勃发展,旨在聚集数据库和计算机系统两大领域的学者,共同推进云计算技术在工业界的研究与发展。
此次被录用的论文为《KOLE: Breaking the Scalability Barrier for Managing Far Edge Nodes in Cloud》。此论文灵感诞生于阿里云边缘容器产品 ACK@Edge ,ACK@Edge 是阿里云容器服务针对边缘计算场景推出的云边一体化协同托管方案,采用非侵入方式增强,提供边缘自治、边缘单元、边缘流量管理、原生运维 API 支持等能力,以原生方式支持边缘计算场景下的应用统一生命周期管理和统一资源调度,现阶段已经覆盖了 CDN、音视频直播、物联网、物流、工业大脑、城市大脑、地产、票务、新零售、能源、交通等实际业务场景,并服务于阿里云 LinkEdge、盒马、优酷、视频云、大麦、CDN 等多个业务或项目中。
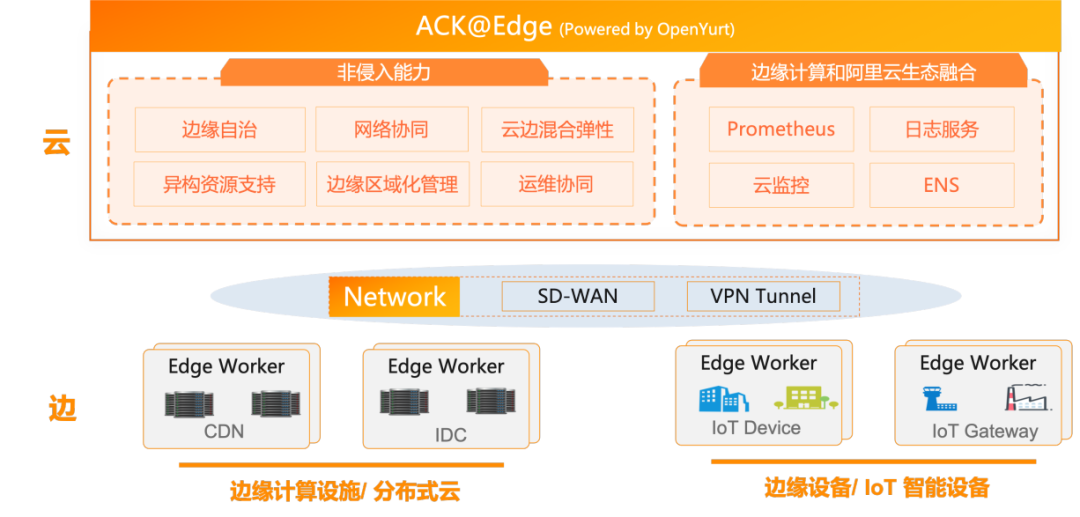
KOLE 全称:A framework built on top of Kubernetes to Orchestrate Limitless (far) Edge nodes。KOLE 针对 Kubernetes 在云边一体,大规模边缘节点管理方面的挑战,创新性的提出了基于 Kubernetes 的新的云边架构,通过利用新的云边通信协议以及缓存快照的方式,使 Kubernetes 能够轻松管理数百万节点。为了突破 Kubernetes 管理大量边缘节点的可扩展性限制,KOLE 的设计遵循三个标准:
避免创建大量对象来持久化边缘节点的状态;
避免在节点与 APIServer 中保持大量的 HTTP 连接;
使用 Kubernetes CRD 支持对边缘节点及其运行的应用程序进行所需的管理操作。
基于以上原则,KOLE 创新性的使用了 MQTT 协议作为云边通信机制,MQTT 被设计用于轻量级的发布/订阅式消息传输,旨在为低带宽和不稳定的网络环境中的物联网设备提供可靠的网络服务,是专门针对物联网开发的轻量级传输协议,并且适合百万级设备连接, MQTT 协议针对低带宽网络,低计算能力的设 备,做了特殊的优化,MQTT 的传输格式非常精小,最小的数据包只有 2 个比特,相对于 HTTP 协议具有更低的能耗。
经过我们大量的实验测试评估,KOLE 可以支持多达 100 万个节点,而不会给 Kubernetes 的核心组件(如 Apiserver 和 etcd)带来显著的开销。我们能够使用 KOLE 在约 73 秒内将工作负载规范分发到 100 万个节点,在 5 分钟内处理 100 万个节点注册,并在约 20 秒内使用快照中的 100 万个节点重建云状态缓存。具体特点如下:
更强的处理节点心跳的性能
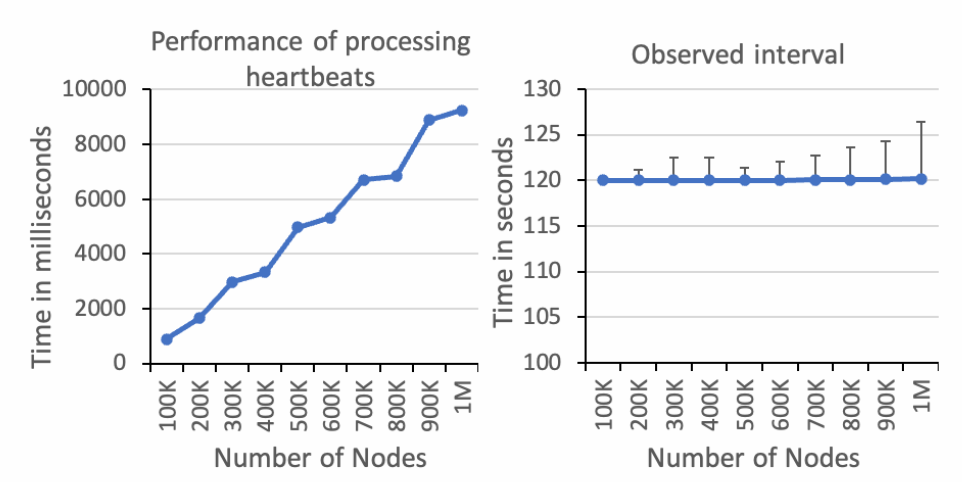
实验数据表明 KOLE 处理所有心跳的时间几乎随着节点数量的增加呈线性增加。处理一百万个注册心跳需要 ∼9.2 秒。
更低的云端控制器组件的消耗
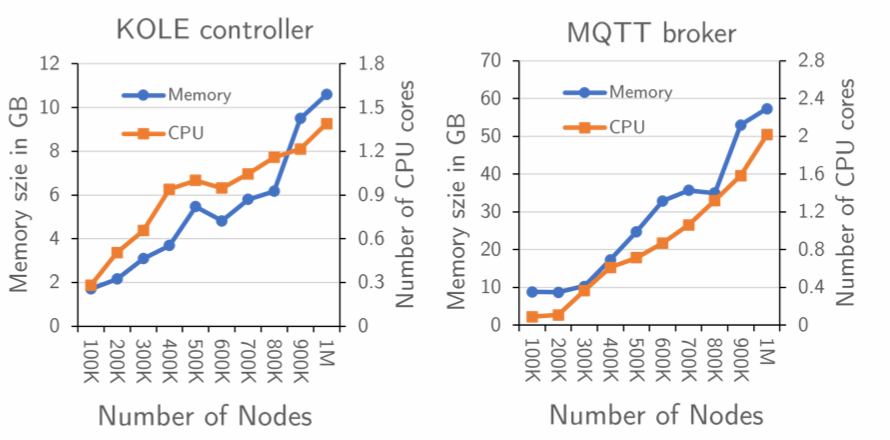
对于 100 万个节点,KOLE 控制器和 MQTT Broker 的内存消耗分别为 10.6GB 和 57.3GB,CPU 使用率适中,KOLE 控制器消耗~1.4 个核心,MQTT Broker 消耗~2 个核心。
更快的工作负载分发
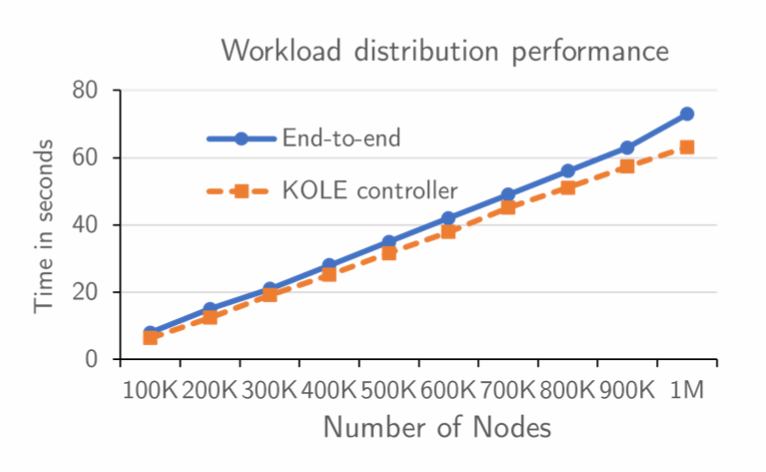
KOLE 通过 MQTT Topic 发送到单个节点时提供了线性可扩展性。将工作负载分别分发到一百万个节点需要 73 秒。线性来自 KOLE 控制器按顺序发布所有 MQTT Topic 的事实。
更高效的云状态缓存快照
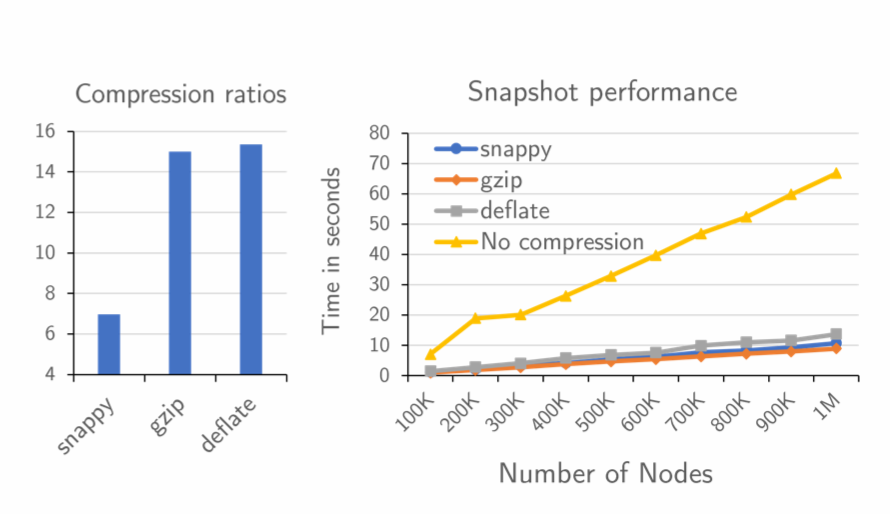
由于 Kubernetes 对 CRD 的限制为 1MB 大小,因此 KOLE 将云状态缓存的序列化字节流设置为为 500MB,对于一百万个节点,这意味着需要 ∼500 个快照用于保存一张快照的 CR 实例。另外为了对数据进一步压缩,KOLE 对常见的压缩算法进行了测试,最终在 KOLE 中,我们选择 gzip 作为默认压缩算法,因为它提供了高压缩比和快速压缩时间,将快照 CR 的数量从 503 个减少到 33 个(减少 93%)。
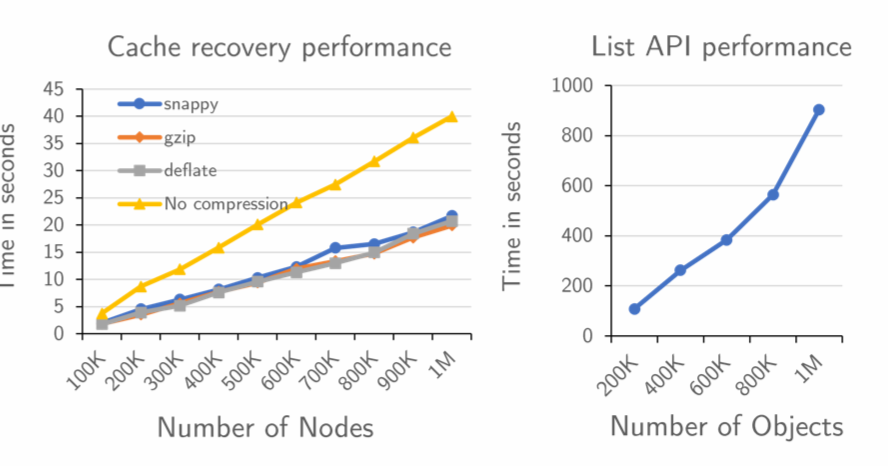
在极端情况下, 我们需要从快照中恢复最原始的数据,上图展示了从快照构建云状态缓存所需要时间,其中包括从 APIServer 加载所有快照 CR 的时间以及运行解压缩算法以恢复数据结构的时间。使用 gzip 算法构建具有 100 万个节点的缓存需要 ∼20 秒。为了突出 KOLE 中快速状态恢复的优势,我们通过列出来自 APIServer 的大量单个节点对象来检查 Kubernetes List API 的性能。结果如上图所示。正如预期的那样,从 APIServer 列出大量对象是低效的。列出一百万个节点对象需要 900 秒。很多 Kubernetes 控制器如 kube-scheduler,kube-controller-manager 需要在启动过程中列出所有节点, List API 性能是他们支持大量节点的瓶颈之一。
更迅速的批量节点注册
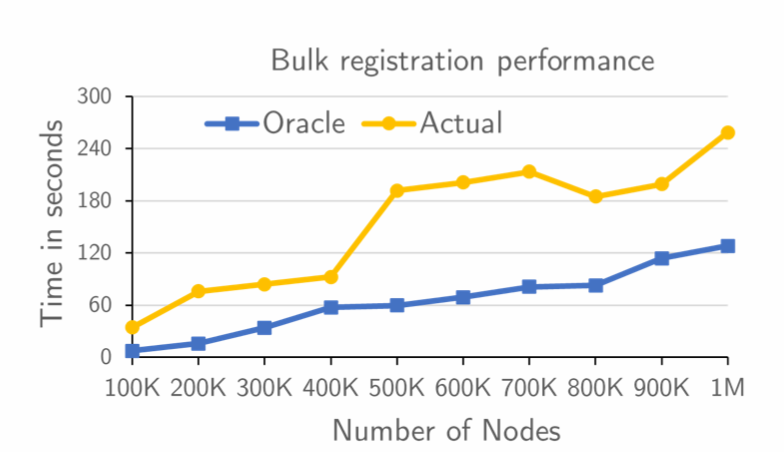
实验结果表明,在拥有 100 万个节点情况下,同时批量注册成功需要 260 秒左右。
此次论文入选 ACM SoCC,是阿里云在云原生容器技术领域,拓展服务边界,实现云边协同的又一次创新。
附论文信息
录用论文题目:
KOLE: Breaking the Scalability Barrier for Managing Far Edge Nodes in Cloud
作者:张杰,晋晨,黄玉奇,易立,叔同,郭飞
论文概述:在边缘计算领域,越来越多的趋势是利用容器化和 Kubernetes 等云原生技术和平台来管理边缘应用程序以提高运营效率。不幸的是,Kubernetes 中每个集群支持的节点数量只有几千个,这远远少于在典型边缘计算场景中所能管理的设备节点数量。在本文中,我们提出了 KOLE 方案,这是一个扩展上游 Kubernetes 以支持大量边缘节点的框架。它用 MQTT 消息系统代替了 Kubernetes 中现有的 Apiserver 与节点的通信机制。MQTT 代理完全卸载了为 Apiserver 中的节点保持大量 HTTP 连接的开销。在 KOLE 中,我们通过在云状态缓存中维护它们来避免在 Apiserver 中创建大量单独的对象。缓存会定期生成快照以进行灾难恢复。总体而言,KOLE 通过牺牲拥有单个对象的可管理性实现了出色的可扩展性。实验结果表明,KOLE 具有可扩展性,可支持百万级别的节点。
点击此处,了解边缘容器服务 ACK@Edge 更多详情!
版权声明: 本文为 InfoQ 作者【阿里巴巴云原生】的原创文章。
原文链接:【http://xie.infoq.cn/article/d9dea56116f4eabc72ab46937】。文章转载请联系作者。

阿里云云原生 2019-05-21 加入
还未添加个人简介









评论