
亿级大表毫秒关联, 荔枝微课基于腾讯云数据仓库 Doris 的统一实时数仓建设实践
腾讯云数据仓库 Doris 助力荔枝微课构建了规范的、计算统一的实时数仓平台。目前腾讯云数据仓库 Doris 已经支撑了荔枝微课内部 90% 以上的业务场景,整体可达到毫秒级的查询响应,数据时效性完成 T+1 到分钟级的提升,开发效率更是实现了 50% 的增长,满足了各业务场景需求、实现降本提效,深得十方融海各数据部门高度认可。
作者|荔枝微课数据中台组组长 陈城
深圳十方融海科技有限公司成立于 2016 年,是一家数字职业在线教育头部企业,业务涵盖“数字职业技能课程、知识分享平台「荔枝微课」、智慧教育解决方案「女娲云教室」”,推出了多类数字素养与数字技能课程服务,助力用户在数字时代实现技能进阶与职业进阶。2016 年上线的荔枝微课,已发展成为国内头部知识分享平台。2021 年上线女娲云教室,实现了“教学练”一体化模式,填补了国内在线教学与实操脱轨的空白。
一、业务介绍
荔枝微课隶属于深圳十方融海科技有限公司,是一个免费使用的在线教育平台。荔枝微课拥有海量的知识内容,包括直播视频、录播视频、音频等多种形式。通过技术和数据的赋能,推进荔枝微课持续创新,也为微课平台方和合作伙伴在视频的创新和销售方面提供了更强劲的支持。在业务运营过程中我们需要对用户进行全方位分析,高效为业务赋能。数据平台旨在集成各种数据源的数据,整合形成数据资产,为业务提供用户全链路生命周期、实时指标分析、标签圈选等分析服务。
二、早期架构及痛点
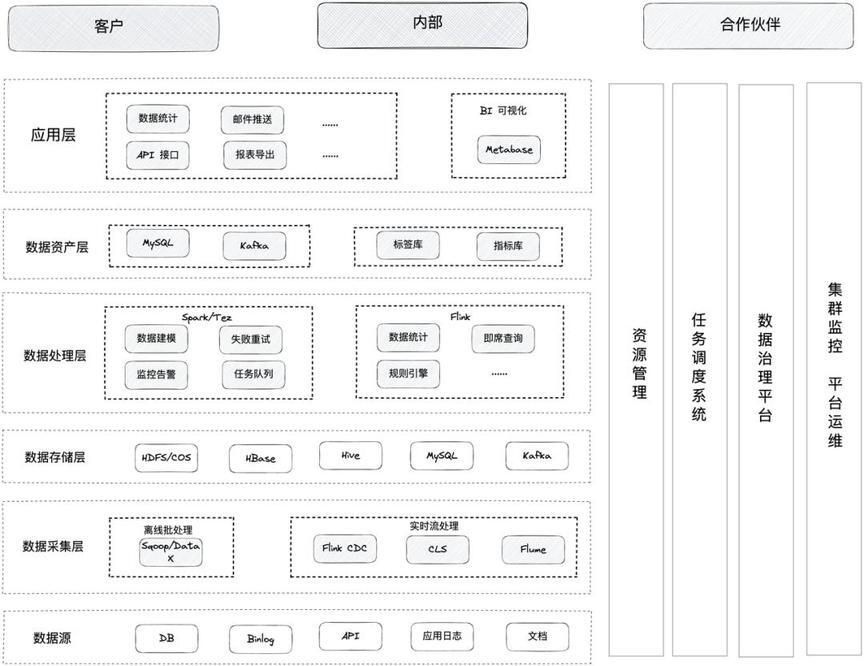
早期架构选用的是 Hadoop 生态圈组件,以 Spark 批计算引擎为核心构建了最初的离线数仓架构,基于 Flink 计算引擎进行实时处理。从源端采集到的业务数据和日志数据将分为实时和离线两条链路:在实时部分,业务库数据通过 Binlog 的方式接入,日志数据使用 Flume-Kafka-Sink 进行实时采集,利用 Flink 将数据计算写入到 Kafka 和 MySQL 中。在实时数仓的内部,遵守数据分层的理论以实现最大程度的数据复用。
在离线部分,利用 Sqoop 和 DataX 对全量和增量业务库中的数据进行定时同步,日志数据通过 Flume 和日志服务进行采集。当不同数据源进入到离线数仓后,首先使用 Hive on Spark/Tez 进行定时调度处理,接着根据维度建模经过 ODS、DWD、DWS、ADS 层数据,这些数据存储在 HDFS 和对象存储 COS 上,最终利用 Presto 进行数据查询展示,并通过 Metabase 提供交互式分析服务。同时为了保障数据的一致性,我们会通过离线数据对实时数据进行定期覆盖。
问题与挑战:基于 Hadoop 的早期架构可以满足我们的初步需求,而面对较为复杂的分析诉求则显得心有余而力不足,再加上近年来,荔枝微课用户体量不断上升,数据量呈指数级上升,为了更好地为业务赋能,提高用户使用体验,业务侧对数据的实时性、可用性、响应速度也提出了更高的要求。在这样的背景下,早期架构暴露的问题也越发明显:
·组件繁多,维护复杂,运维难度非常高
·数据处理链路过长,导致查询延迟变高
·当有新的数据需求时,牵一发而动全身,所需开发周期比较长
·数据时效性低,只可满足 T+1 的数据需求,从而也导致数据分析效率低下
三、技术选型
通过对数据规模及早期架构存在的问题进行评估,我们决定引入一款实时数仓来搭建新的数据平台,同时希望新的 OLAP 引擎可以具备以下能力:
·支持 Join 操作,可满足不同业务用户灵活多变的分析需求
·支持高并发查询,可满足日常业务的报表分析需求
·性能强悍,可以在海量数据场景下实现快速响应
·运维简单,缩减运维人力的投入和成本的支出,实现降本提效
·统一数仓构建,简化繁琐的大数据软件栈
·社区活跃,在使用过程中遇到问题,可迅速与社区取得联系
基于以上要求,我们快速定位了 Apache Doris 和 ClickHouse 这两款开源 OLAP 引擎 ,这两款引擎都是当下使用较为广泛、口碑不错的产品。在调研中发现,ClickHouse 在宽表查询时有着非常出色的性能表现,写入速度快,对于大量的数据更新非常实用;但对于 join 场景,通常需要额外的调优才能有较好的表现。而我们在大多数业务场景中都需要基于明细数据进行大数据量的 Join,相比而言,Apache Doris 多表 Join 能力强悍,高并发能力优异,完全可以满足我们日常的业务报表分析需求。除此之外,Apache Doris 可以同时支持实时数据服务、交互数据分析和离线数据处理多种场景,并且支持 Multi Catalog ,可以实现统一的数据门户,这几个特点都是我们核心考虑的几个能力。
同时,我们也了解到腾讯云数据仓库 Doris 这款产品。作为一款支持在线业务和多维分析的实时数仓产品,腾讯云数据仓库 Doris 100% 兼容开源 Apache Doris,整体架构简洁易用,极简运维,弹性伸缩,功能完备,一站式的分析解决方案,满足各种业务数据分析场景,能够助力企业快速构建云上数据分析平台。
在多源数据加工方面, Flink 有着优秀的表现满足我们的实时数据加工诉求,我们选择了腾讯云大数据 EMR-Flink。腾讯云 EMR 是一款基于云原生技术和泛 Hadoop 生态开源技术的安全、低成本、高可靠的开源大数据平台,提供了非常丰富的组件选项。而作为云原生大数据产品,腾讯云数据仓库 Doris 与 EMR 这两款产品之间能够无缝集成与联动。
基于以上优势,我们最终选择与腾讯云大数据合作,采用腾讯云数据仓库 Doris + EMR 来搭建新的实时数仓架构体系。
四、新的架构及方案
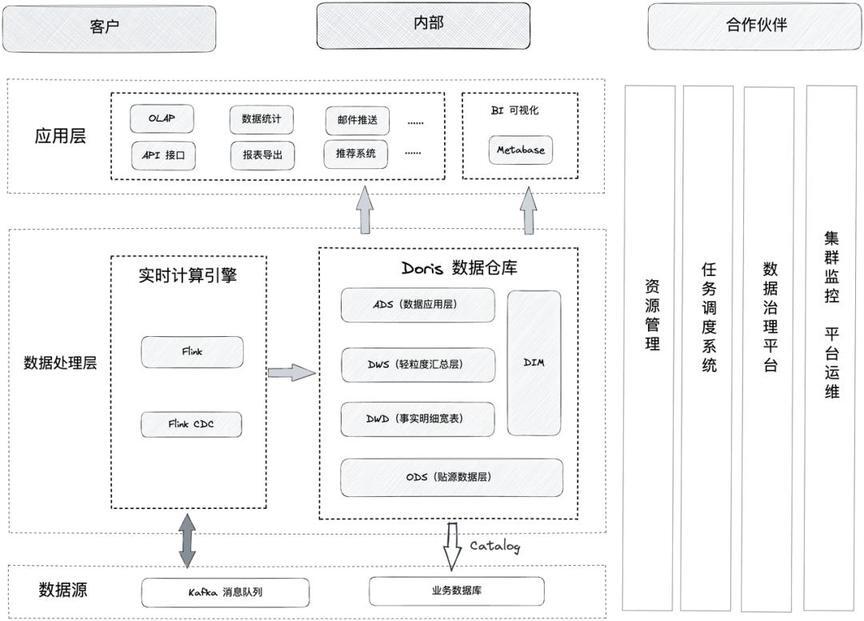
在新的架构中我们采取 腾讯云数据仓库 Doris 和 腾讯云 EMR-Flink 来构建实时数仓,多种数据源的数据经过 Flink CDC 或 Flink 加工处理后,入库到 Kafka 和 Doris 中,最终由 Doris 提供统一的查询服务。在数据同步上,一般通过 Flink CDC 将 RDS 数据实时同步到 Doris,通过 Flink 将 Kafka 的日志数据加工处理到 Doris,重要的指标数据一般由 Flink 计算,再经过 Kafka 分层处理写入到 Doris 中。
·在存储媒介上,主要使用 腾讯云数据仓库 Doris 进行流批数据的统一存储。
·架构收益:成功构建了规范的、计算统一的实时数仓平台,腾讯云数据仓库 Doris 的 Multi Catalog 功能助力我们统一了不同数据源出口,实现联邦查询。同时利用外部表插入的方式进行快速数据同步和修复,真正实现了统一数据门户。
·数据实时性有效提升,通过 Flink + Doris 架构,实时性从早期 T+1 缩短为的分钟级延迟。并发能力强,可以覆盖更多的业务场景。
·极大地减少了运维成本,Doris 架构简单,只有 FE 和 BE 两个进程,不依赖其他系统;另外,集群扩缩容非常简单,可实现用户无感知扩容。
·开发周期从周级别降至天级别,开发周期大幅缩短,开发效率较之前提升了 50 %。
五、搭建经验
数据建模
结合腾讯云数据仓库 Doris 的特性,我们对数据仓库进行了建模,建模方式与传统数仓类似:
1、ODS 层:ODS 层日志数据选择 Duplicate 模型的分区表,分区表方便进行数据修复,Duplicate 模型还可以减少非必要的 Compaction。ODS 层业务库数据采用 Unique 数据模型(业务库 MySQL 单表数据通过 Flink CDC 实时同步到 Doris,Kafka 日志数据经 Flink 清洗,通过 Doris 的 Routine Load 写入 Doris 作为 ODS 层),DISTRIBUTED BY HASH KEY 根据具体的业务场景进行选择:
如果考虑机器资源,可选择均匀分布的 KEY,让 Tablet 数据能够均匀分布,使得查询时各 BE 资源能够充分利用,避免出现木桶效应;
如果考虑大表 Join 性能,可以依据 Colocate Join 特性进行创建,让 Join 查询更高效;
Doris 1.2 版本中 Unqiue 模型开始支持写时合并 Merge On Write,进一步提升了 Unique 模型的查询性能;
2、DWD 层:对于通过 Flink 将数据进行 Join 打宽处理分别写入 Doris 和 Kafka 中的场景,选择使用 Unique 数据模型;
对于高频查询的宽表选择 Doris 的 Aggregate 模型,使用 REPLACE_IF_NOT_NULL 字段类型,将多个事实单表进行插入,通过 Doris 的 Compaction 机制可以有效减少 Flink 状态 TTL 导致历史数据没有及时更新的问题。
3、DWS 层和 ADS 层:主要采用 Unique 数据模型,DWS 层根据数据量大小按天、月进行分区。除此之外,我们还会利用 INSERT INTO 语句进行 5 分钟的任务调度和 T+1 的任务修复来进行数仓分层,便于需求的快速开发和实时数据修复。对于 Duplicate 模型的数据表,我们会创建 Rollup 的物化视图,通过击中物化视图查询能够加快上层表查询效率。
数据开发
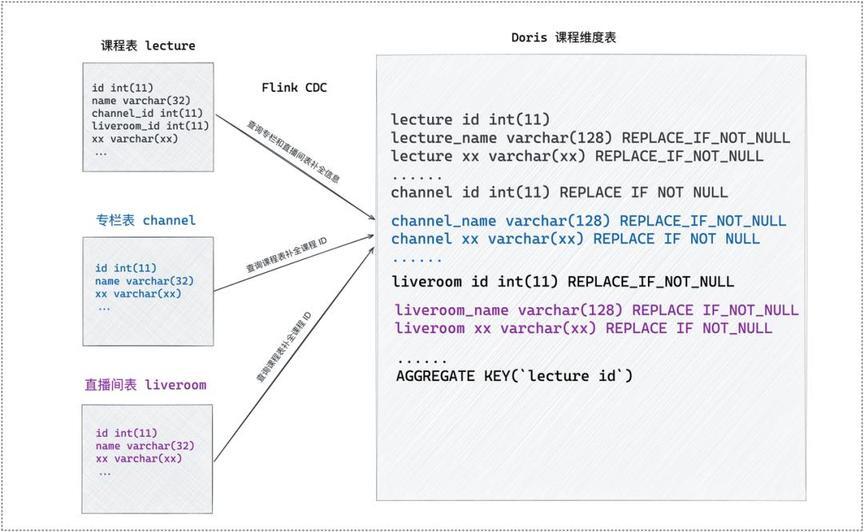
在荔枝微课业务中,运营人员经常会有调整直播课程信息、修改专栏名称等操作,针对维度快速变化但宽表中维度列没有及时更新的场景,为了能更好地满足业务需求,我们利用 Doris Aggregate 模型 的 REPLACE_IF_NOT_NULL 字段特性,通过 Flink CDC 多表分别写入 Doris 维度表的部分列。当课程维度表数据发生变化时,需要查询上层维度(专栏和直播间),对维度表补全,再将数据插入到 Doris 中;当上层维度(专栏和直播间)发生变化时,需要下钻查询课程表,补全对应的课程 ID ,再将数据插入到 Doris 中。通过该方式可以保证维度表中所有字段的实时性,数据查询时再通过宽表来关联维表补全维度字段展示数据。
库表设计
在初期设计阶段,为了更好地利用腾讯云数据仓库 Doris 提供的 Colocation Join 功能,我们特别设计了事实表的主键,如下图示例:
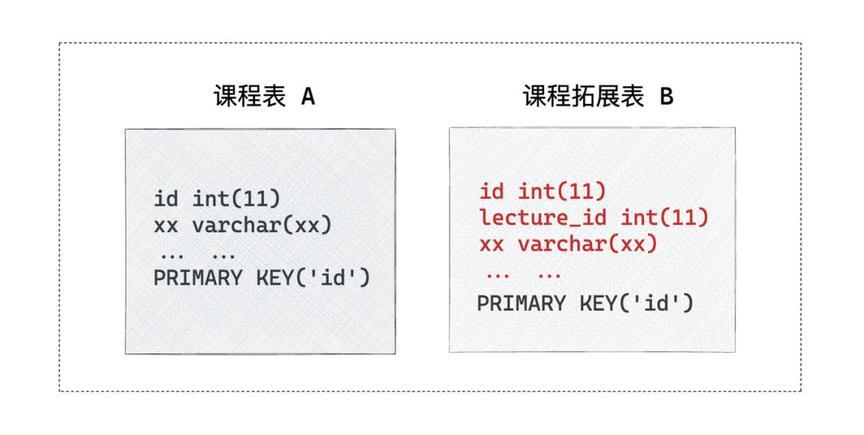
在业务库中课程表 A 和课程表 B 的关系是 A.id=B.lecture_id,为了实现 Colocation Join,我们将 B 的 distributed by hash key 设置为 lecture_id。当面对多事实表时,先进行 Colocation Join ,再进行维度 Bucket Shuffle Join ,以实现快速查询响应。而使用这个方式可能导致以下问题:当选取的 lecture_id 进行 DISTRIBUTED BY 时,数据库主键 ID 并不是均匀分布的,在数据量很大的情况下可能会导致数据倾斜,而各个机器的 Tablet 大小不一致,在高并发查询时可能出现 BE 机器资源使用不均衡,从而影响查询稳定性,造成资源浪费。
基于以上问题,我们尝试进行调整,并对查询效率和机器资源的占用这两方面进行了评估权衡,最终决定在尽量不影响查询效率的前提下,尽可能提高资源利用率。在资源利用上,我们在建表时利用 colocate_with 属性,在不同数量和类型的 Distributed Key 创建不同的 Group,实现机器资源能得以充分利用。
在查询效率上,根据业务场景和需求对前缀索引的字段顺序进行针对性调整,对于必选或高频的查询条件,将字段放在 UNIQUE KEY 前面,根据维度按照从高到低的顺序进行设计。其次我们利用物化视图对字段顺序进行调整,尽可能使用前缀索引进行查询,以加快数据查询 。除此之外,我们对数据量进行月、天分区,对明细数据进行分桶,通过合理库表的设计减少 FE 元数据的压力。
数据管理
在数据管理方面,我们进行了以下操作:
·监控告警:对于重要的单表,我们一般通过 腾讯云数据仓库 Doris 来创建外部表,通过数据质量监控来对比业务库数据和 Doris 数据,进行数据质量稽查告警。
·数据备份与恢复:我们会将 Doris 数据定期导入到 HDFS 进行备份,避免数据误删除或丢失的情况发生。比如当因某些原因导致 Flink 同步任务失败、无法从 Checkpoint 进行启动时,我们可读取最新的数据进行同步,历史缺失数据通过外部表进行修复,使得同步任务能够快速恢复。
六、收益总结
在新架构中我们从 Hadoop 生态完全地迁移到 Flink + Doris 上,在上层构建不同的数据应用,比如自助报表、自助数据提取、数据大屏、业务预警等,Doris 通过应用层接口服务项目统一对外提供 API 查询,新架构的应用也为我们带来了许多收益:支撑了荔枝微课内部 90% 以上的业务场景,整体可达到毫秒级的查询响应。
·支持千万级甚至亿级大表关联查询,可实现秒级甚至毫秒级响应。
·Doris 统一了数据源出口,查询效率显著提升,支持多种数据的联邦查询,降低了多数据查询的复杂度以及数据链路处理成本。
·Doris 架构简单,极大简化了大数据的架构体系;并高度兼容 MySQL 的语法,极大降低开发人员接入成本。
七、未来规划
荔枝微课在引入腾讯云数据仓库 Doris 之后,在内部得到了非常广泛的应用,满足了各业务场景需求、实现降本提效,深得十方融海各数据部门高度认可。未来我们期待 腾讯云数据仓库 Doris 在实时数据处理场景的能力上有更进一步的提升,包括 Unique 模型上的部分列更新、单表物化视图上的计算增强、自动增量刷新的多表物化视图等,通过不断的迭代更新,使实时数仓的构建更加简单易用。最后,感谢腾讯云大数据和 selectDB 团队,感谢其对问题的快速响应和积极的技术支持。同时,腾讯云也将不断打磨产品,探索惠及更多行业场景的云端实践之路。

还未添加个人签名 2021-05-31 加入
还未添加个人简介









评论