
强化学习是否言过其实?
可以想象一下,你正准备和朋友一起下国际象棋,但他并不是人类,而是一个不了解游戏规则的计算机程序。但这个应用程序却明白自己致力实现一个目标,就是在游戏中获胜。
因为计算机程序不知道规则,所以开始下棋的招数是随机的。其中有些招数完全没有意义,而对你来说获胜很容易。在这里假设你非常喜欢和这个朋友下国际象棋,以至于沉迷于这个游戏。
但计算机程序最终会获胜,因为它会逐渐学会击败你的方法和招数。虽然假设的这个场景看起来有些牵强,但它应该能让你对强化学习(机器学习的一个领域)的大致工作原理有一个基本的了解。
强化学习到底有多智能?
人类智力包含许多特征,包括获得知识、扩展智力能力的愿望和直觉思维。当国际象棋冠军加里·卡斯帕罗夫在输给 IBM 公司的一台名为“深蓝”(Deep Blue)的电脑时,人类的智能受到了很大的质疑。除了吸引公众的注意力之外,描绘机器人在未来统治人类的世界末日场景也占据了主流意识。
然而,“深蓝”并不是一个普通的对手。与这个计算程序下棋就像与一个千岁的老人进行比赛,而他一生一直在不停地下国际象棋。但“深蓝”擅长玩一种特定的游戏,而不是其他智力活动,如演奏乐器、撰写著作、进行科学实验、抚养子女或修理汽车。
这绝不是想贬低“深蓝”所取得的成就。与其相反,计算机在智力能力上超越人类的想法需要仔细的检验,首先要分析强化学习的工作机制。
强化学习是如何工作的
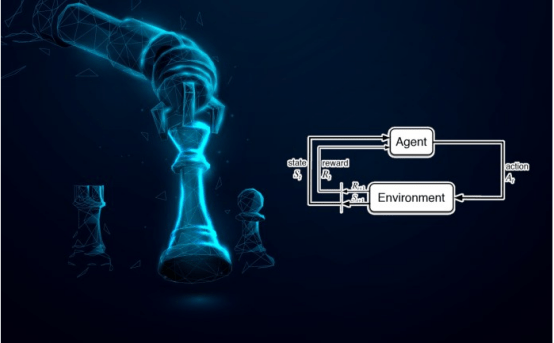
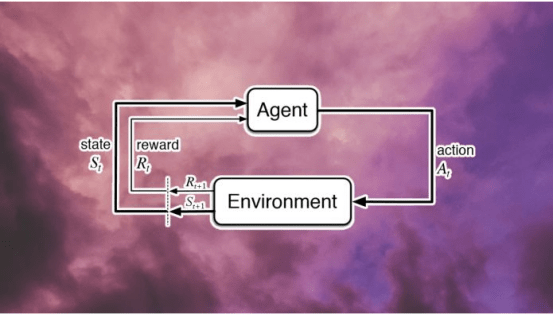
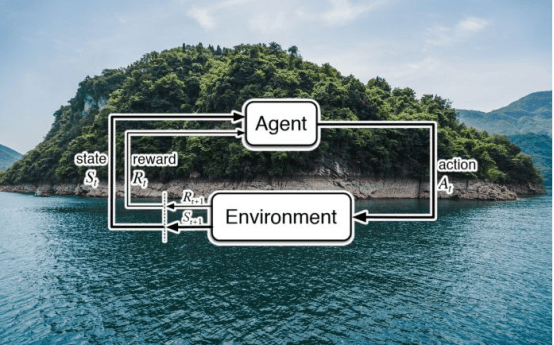
如上所述,强化学习是机器学习的一个子集,它涉及智能代理在环境中如何行动以最大化累积奖励的概念。
简单地说,强化学习机器人接受奖惩机制的训练,它们做出正确的动作会得到奖励,做出错误的动作会受到惩罚。强化学习机器人不会“思考”如何采取更好的行动,它们只是让所有的行动成为可能,以最大限度地提高成功的机会。
强化学习的缺点
强化学习的主要缺点是它需要采用大量的资源来实现它的目标。强化学习在围棋游戏中的成功就说明了这一点。这是一款流行的双人游戏,其目标是使用棋子在棋盘上占据最大区域,同时避免丢子。
AlphaGo Master 是一款在围棋比赛中击败人类棋手的计算机程序,它耗费大量的资金和人力,其中包括许多工程师,非常丰富的游戏经验以及 256 个 GPU 和 128000 个 CPU。
在学习如何在比赛获胜的过程中,需要投入大量的资源和精力。这就引出了一个问题:设计不能凭直觉思考的人工智能是否合理?人工智能研究不是应该尝试模仿人类智能吗?
支持强化学习的一个论点是,人们不应该期望人工智能系统像人类一样行动,它用于解决复杂问题需要进一步发展。另一方面,反对强化学习的观点是,人工智能研究应该专注于让机器做目前只有人类和动物才有能力做的事情。从这个角度来看,人工智能与人类智能的比较是恰当的。
量子强化学习
强化学习是一个新兴的领域,据说可以解决上述的一些问题。量子强化学习(QRL)是一种加速计算的方法。
首先,量子强化学习(QRL)应该通过优化探索(发现策略)和开发(选择最佳策略)阶段来加速学习。目前的一些应用和提出的量子计算改进了数据库搜索,将大数分解为质数,等等。
尽管量子强化学习(QRL)还没有以突破性的方式出现,但它有望解决常规强化学习的一些重大挑战。
强化学习的业务案例
正如以上提到的,强化学习研究和开发至关重要。以下是来自麦肯锡公司的一份调查报告中的有关强化学习的一些实际应用示例,强化学习可以:
优化半导体和芯片设计,优化制造工艺,提高半导体行业的产量。
提高工厂产量,优化物流以减少浪费和成本,提高农业利润。
缩短航空航天和国防工业新系统的上市时间。
优化设计流程,提高汽车行业的生产效率。
通过实时交易和定价策略增加收入,改善客户体验,并在金融服务中为客户提供先进的个性化服务。
优化矿山设计,管理发电,应用整体物流调度,优化作业,降低成本,提高产量。
通过实时监测和精确钻井提高产量,优化油轮行进路线,实现预测性维护,防止油气行业的设备故障。
促进药物发现,优化研究流程,自动化生产和优化制药行业的生物方法。
优化供应链,实施先进的库存建模,为零售部门的客户提供先进的个性化服务。
优化和管理网络,在电信行业应用客户个性化。
优化运输物流的路线、网络规划、仓库操作。
使用下一代代理从网站提取数据。
强化学习的反思
强化学习的能力可能是有限的,但它不会被高估。此外,随着强化学习研究和开发项目的增加,几乎每个经济部门的潜在用例也在增加。
大规模采用强化学习依赖于几个因素,其中包括优化算法设计、配置学习环境和计算能力的可用性。
原文标题:Is reinforcement learning overhyped?,作者:Aleksandras Šulženko
版权声明: 本文为 InfoQ 作者【高端章鱼哥】的原创文章。
原文链接:【http://xie.infoq.cn/article/d6baca0f134fa14679c6eba12】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论