
2023-06-21:redis 中什么是 BigKey?该如何解决?
2023-06-21:redis 中什么是 BigKey?该如何解决?
答案 2023-06-21:
什么是 bigkey
bigkey 是指存储在 Key-Value 数据库中的键对应的值所占用的内存空间较大。举个例子,如果值是字符串类型,它可以达到最大 512MB 的存储空间;如果值是列表类型,最多可以存储 2^32 - 1 个元素,即 4294967295 个元素。
根据数据结构的不同,我们可以将 bigkey 进一步分为字符串类型的 bigkey 和非字符串类型的 bigkey。
字符串类型的 bigkey:这种 bigkey 指的是在 Key-Value 数据库中,键对应的字符串值所占用的内存空间较大。一般来说,当一个值超过 10KB 时,就可以被认为是字符串类型的 bigkey。但需要注意的是,这个阈值可以根据具体的业务需求和系统的 OPS(每秒操作次数)进行调整,不同的环境可能会有不同的定义。
非字符串类型的 bigkey:这种 bigkey 指的是键对应的值是其他非字符串类型(例如哈希、列表、集合、有序集合等),而这些数据结构中的元素数量多到足以被认为是 bigkey。例如,当一个哈希表、列表、集合或有序集合中的元素数量超过较大的阈值时,可以被视为非字符串类型的 bigkey。
bigkey 在 Redis 中具有不友好的空间复杂度和时间复杂度,以下是它的危害。
bigkey 的危害
bigkey 的危害体现在三个方面:
1、内存空间不均匀(平衡):特别是在 Redis Cluster 中,bigkey 可能导致节点的内存空间使用不均匀。当某个节点存储了大量的 bigkey 时,该节点的内存占用会增加,并且可能超出其他节点的内存使用量。这样就破坏了集群的负载均衡,导致一些节点承受了过多的负载,而其他节点却相对空闲。
2、超时阻塞:由于 Redis 的单线程特性,操作 bigkey 可能会耗费较长的时间,这也意味着 Redis 被阻塞的可能性增大。
3、网络拥塞:获取 bigkey 时产生的网络流量较大,可能引起网络拥塞问题。
假设一个 bigkey 的大小为 1MB,每秒访问量为 1000 个请求,那么每秒产生的流量将达到 1000MB。对于普通的千兆网卡(以字节计算约为 128MB/s)的服务器来说,这将带来巨大的网络负载,甚至可能导致灾难性的影响。尤其是在采用单机多实例的方式部署服务器时,一个大型 bigkey 的影响最终会波及到其他实例上,后果不堪设想。
bigkey 的存在并非完全致命:
如果一个 bigkey 存在但几乎不被频繁访问,那么主要的问题可能是内存空间的不均衡分布,相对于其他问题来说,这个问题的重要性和紧急性可能较低。然而,如果这个 bigkey 是一个热点 key(频繁被访问),那么它所带来的危害就不容忽视。当一个热点 bigkey 的访问量特别大时,它可能会对 Redis 服务器和其他实例产生严重的性能影响。
因此,在实际的开发和运维过程中,密切关注 bigkey 的存在是非常重要的。特别是对于热点 bigkey,需要采取相应的策略来应对,例如数据分片、缓存或其他优化措施,以确保系统的高性能和稳定运行。及时监控和处理 bigkey 问题,有助于维护整体的系统性能和用户体验。
发现 bigkey
使用命令 redis-cli --bigkeys 可以统计和查看 bigkey 的分布情况。

在生产环境中,开发和运维人员通常希望能够自定义 bigkey 的大小,并且找到真正的 bigkey,以便能够定位、解决和优化相关问题。
为了判断一个 key 是否为 bigkey,可以执行 DEBUG OBJECT key 命令并查看 serializedlength 属性,它表示 key 对应的 value 序列化后的字节数。通过检查这个属性,我们可以确定一个 key 是否为 bigkey。

当需要遍历多个 key 时,应避免使用 keys 命令,而是采用 SCAN 命令来减轻 Redis 服务器的压力。
scan
自 Redis 2.8 版本以后,引入了SCAN命令来高效地解决KEYS命令存在的问题。不同于KEYS命令一次性遍历所有键的方式,SCAN采用渐进式遍历的方式,以解决可能引起阻塞的问题。要完全实现KEYS命令的功能,需要执行多次SCAN命令。可以将其想象为逐步扫描字典中的一部分键,直到所有键都遍历完成。
SCAN命令使用方法如下:
cursor是必需的参数,实际上是一个游标。第一次遍历时,游标值为 0,每次执行完SCAN命令后,会返回当前游标的值,直到游标值为 0,表示遍历已结束。MATCH pattern是可选参数,用于指定键名的模式匹配,类似于KEYS命令的模式匹配功能。COUNT number是可选参数,用于指定每次要遍历的键的数量,其默认值为 10,如果需要可以适当增大此参数。
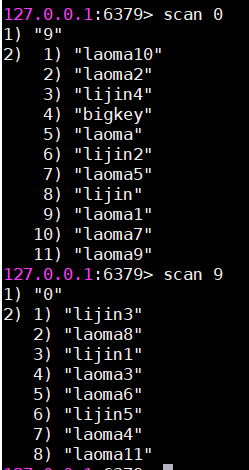
可以观察到,使用SCAN 0命令的第一次执行结果包含两部分:
第一部分是下一次执行SCAN命令所需的游标值(通常是一个整数)。
第二部分是返回的 10 个键。
接下来可以继续执行SCAN命令,并使用上一次返回的游标值作为参数,直到游标值变为 0,表示所有键都已经遍历完毕。
除了SCAN命令,Redis 还提供了针对哈希类型、集合类型和有序集合类型的扫描遍历命令,分别是HSCAN、SSCAN和ZSCAN。它们的作用是解决类似于HGETALL、SMEMBERS、ZRANGE等可能导致阻塞的操作。这些命令的用法类似于SCAN命令,请参考 Redis 官方文档获取更多信息。
渐进式遍历确实可以有效解决 KEYS 命令可能产生的阻塞问题,但并非完美无瑕。在使用 SCAN 命令进行遍历过程中,如果键空间有变化(增加、删除、修改),可能会遇到以下问题:新增的键可能没有被遍历到,或者遍历结果中可能包含重复的键。因此,在开发过程中需要考虑这些潜在的情况。
当键值个数较多时,使用 SCAN 命令结合 DEBUG OBJECT 执行速度可能较慢,此时可以考虑利用 Redis 的 Pipeline 机制来提高性能。对于元素个数较多的数据结构,DEBUG OBJECT 命令执行速度较慢,并且可能导致 Redis 阻塞。因此,如果存在从节点,可以考虑在从节点上执行这些操作。
解决 bigkey
解决大键(bigkey)的主要思路是拆分,将存储在大键中的数据(大值)进行拆分,分成多个小的值(value1,value2...valueN)进行存储。
例如,如果大值是一个大的 JSON 对象,可以通过使用MSET命令将该键的内容拆分存储到各个实例中,或者使用哈希表(hash),其中每个字段代表一个具体属性。可以使用HGET、HMGET命令来获取部分值,使用HSET、HMSET命令来更新部分属性。
同样地,如果大值是一个大的列表(list),可以将其拆分为多个小的列表(list_1,list_2,list_3...list_N)进行存储。
对于其他数据类型也可以采用类似的拆分策略。
通过拆分大键,可以将大的值分割为小的部分,这样可以更好地利用 Redis 的内存和性能。这种拆分策略可以根据实际情况进行调整,以满足存储和访问的需求。
版权声明: 本文为 InfoQ 作者【福大大架构师每日一题】的原创文章。
原文链接:【http://xie.infoq.cn/article/d2bc45a882b96ca1d04e7b2ce】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

公众号:福大大架构师每日一题 2021-02-15 加入
公众号:福大大架构师每日一题









评论