
PostgreSQL 技术内幕 (二) Greenplum-AO 表

序言
Greenplum(以下简称 GP)是一种基于开源 PostgreSQL 基础上采用 MPP 架构的关系型分布式数据库,具有强大的大规模数据分析处理能力。
GP 有两种存储格式:Heap 表和 AO 表。其中,AO 表是 Greenplum 所特有的,主要面向 OLAP 场景,支持行存和列存,批量的数据写入,有利于高吞吐数据量的加载,同时支持对数据进行压缩,AOCO 不仅支持表级别的压缩,同时也支持列级别的压缩。
GP-AO 表的分析速度快,对于 OLAP 场景,每次分析涉及的字段较少,可以保证行级严格事务。这种设计对大批量数据的访问和统计需求而言,能够有效提升分析速度。
在近期的直播中,HashData 内核研发工程师介绍了 GP-AO 表的设计和特点。以下内容根据直播文字整理。
存储引擎概要
Heap 表是从 PostgreSQL 继承而来的,目前是 GP 默认的表存储格式,只支持行存储,不支持列存和压缩。
Heap 页面存储的数据称为元组(Tuple),在物理文件上不按照某种顺序进行排序。当读取 Heap 文件页面时,也不会对元组的排序做任何假设。Heap 的存储格式对于 OLTP 和 OLAP 两个访问模式都是比较有效的,但更适合 OLTP 的场景,比如插入新的元组不需要考虑元组间的相互顺序,而且删除和更新元组也非常简单。
在 OLAP 的场景下,查询更多的是全表扫描。通常情况下,查询语句并不会读取所有列的数据,而会筛选出感兴趣的列。由于元组是将所有列都存放在一块,这样会增加额外的 IO 开销。此外,Heap 由于采用跨页存储,检索非常复杂,对数据的压缩也不如 AO 和 AOCS,对存储的开销较大。
总体来讲,Heap 表的设计理念注重平衡性,对于元组增删查改的应用场景支持比较均衡。
存储引擎的 AO 表设计
在 OLAP 的场景下,数据大多是一些历史数据或日志数据,一般不会修改或者仅少量修改,元组更多以追加而非修改的方式存放。
另外,从数据访问方式来看,OLAP 需要读取大量记录,记录多以扫描的方式进行读取。同时,由于每个页面存在空洞或者已经被删除的无效数据,扫描访问方式对于 Heap 来说并不高效。
基于此,Greenplum 引入了 AO 表,用来专门存储以追加方式插入的元组。最开始设计时,AO 表被称为 Append Only 表,只支持追加新元组。在后来的演进中,也支持了删除和更新元组操作,因此现在 AO 表指的是 Append Optimized。
与 Heap 表相比,AO 表存储更紧凑,记录之间没有空余空间,在 AO 表上进行分析通常效率更高。此外,AO 表可以支持列式存储,在处理大批量数据时具有显著优势,非常适合向量计算和 JIT 架构。
对于 AO 表的每个文件,元组总是添加到文件末尾,所以文件的结尾地址(EOF)就可以作为数据可见性判断的依据。只有当事务成功提交后,从原来 EOF 之后新追加的元组才对外可见,否则对外只能看到文件原来的 EOF。
对此,Greenplum 中提供了两个系统表记录相应的信息:pg_appendonly 和 pg_aoseg.pg_aoseg_。其中,pg_appendonly 表中 segrelid 记录了 AO 表所对应 pg_aoseg.pg_aoseg_表的 OID。
pg_aoseg.pg_aoseg_为 Heap 表,记录了 AO 表每个数据文件的 EOF。这样可以通过 MVCC 来管理 pg_aoseg.pg_aoseg_表中的 EOF 信息。
pg_aoseg.pg_aoseg_中的 OID 指的是 AO 表的 OID。
另外,Heap 的元组存储了太多可见性相关的信息,由于 EOF 已经可以作为可见性判断的依据,所以 AO 表中存储的元组不需要存储这些额外的信息。
二者对比而言,AO 表存储的元组结构是 MemTuple,Heap 假设的访问场景是随机和顺序访问,AO 表假设的访问场景多是顺序扫描;Heap 表的块必须要大小一致,便于随机寻址,AO 表的块并不需要定长存储,可以进行变长压缩,以节省空间。
Heap 表的块多个进程间需要共享,通过共享缓冲区进行管理。AO 表由于是变长块,而且多是顺序扫描,所以不经过共享缓冲区。
为了支持删除操作,AO 表引入了 VisibilityMap。如果元组被删除,将会在 VisibilityMap 中标记。该 VisibilityMap 信息由系统表 pg_aovisimap_保存。AO 表的更新操作的实现也就转换为删除操作+插入操作。
由于 AO 表采用的是变长块,无法通过文件内的逻辑块号或行号直接定位到物理位置,但是为了支持在 AO 表上建立索引,需要通过行号快速定位到物理位置以便进行元组读取。当 AO 表上建有索引时,Greenplum 中会创建系统表 pg_aoblkdir_来存储行号到物理位置的映射信息,来减少额外的存储开销。
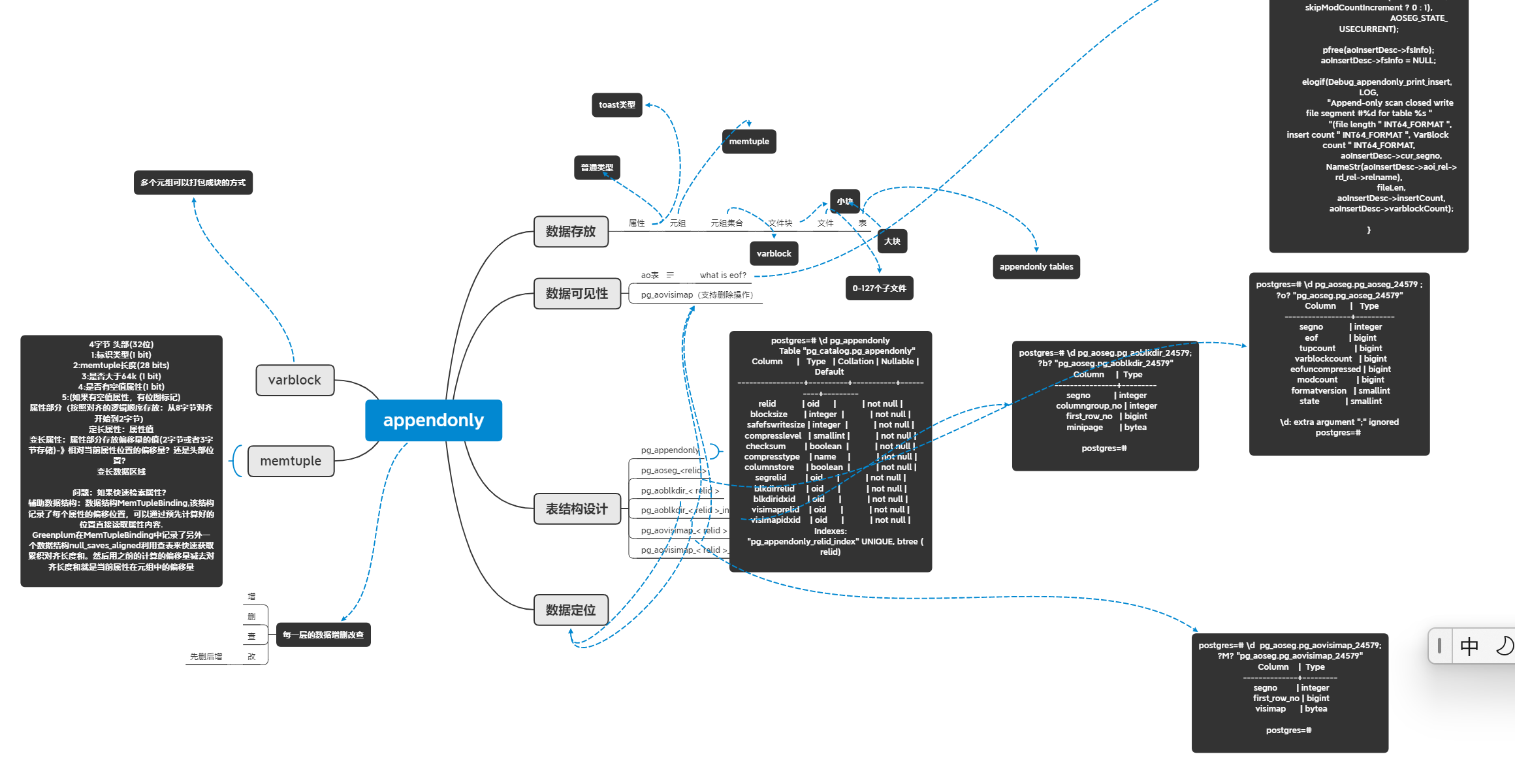
AO 表设计框架结构总体概略
数据设计
AO 表的数据设计实现面对的主要问题是数据的增删改查,这就需要解决四个问题:数据存放、数据可见性、数据表结构设计以及数据如何定位的实现。
其中,对于变长记录在数据库系统中的出现有几个原因。最常见的原因是变长域的出现,比如字符串。实现变长记录可以采用不同的技术,但都必须解决两个问题:
如何表示单条记录,使得此记录的单个属性能够被轻松地提取,即使这些属性是变长的;
如何在一个块中存储变长的记录,使得一个块中的记录能够被轻松地提取。
具有变长属性的记录表示通常包含两个部分:首先是带有定长信息的初始部分,其结构对于相同关系的所有记录都是一样的。紧接着是变长属性的内容,诸如数字值、日期或定长字符串等固定长度的属性,被分配存储它们的值所需的字节数。对于可变长字符串类型这类的变长属性,在记录的初始部分中被表示为一个(偏移量,长度)。
对于块中变长记录的存储问题,比如分槽的页结构,一般用于在块中组织记录,每个块开始有块头,包含如下信息:块头的记录项的数量、块中的自由空间的末尾处、一个包含每条记录的位置和大小的项组成的数组。
数据存放设计
AO 表通过 EOF 来控制可见性,相比于 HeapTuple,元组中不再需要存储可见性相关信息。MemTuple 除了可用在 AO 表存储格式之外,还会用在执行器中,因为当元组从磁盘读取出到执行器后,不再需要保留可见性相关信息。
数据检索设计
对于 AO 表,每个事务会写不同的分片文件,所以 AO 表中元组的位置不再像 Heap 表中的线性结构,而是由分片文件编号(7 位,范围 0~127)和文件内行号(40 位)确定。AO 表通过 AOTupleId 数据结构来表示 AO 表中元组的地址,由于元组地址会用到多个地方,比如索引、索引扫描等,所以 AOTupleId 采用了和 ItemPointerData 同样的大小和对齐方式。AOTupleId 一共 48 位 6 字节,以 16 位对齐。
AO 表采用的是变长块,和 ItemPointerData 不同的是,并不能简单的从 AOTupleId 对应到元组的物理位置。在 Greenplum 中,引入了块目录(BlockDirectory)的表和数据结构,来方便查找从分片文件号以及块内行号来获得在文件中的物理位置。只有当 AO 表上创建有索引时,块目录才会创建。
块目录表维护了从分片文件号、列组编号(columngroup_no,AO 表始终为 0,AOCS 会用到)、起始行号三者到 minipage 的映射。minipage 是由 MinipageEntry 组成的数组,每个 MinipageEntry 记录了一个或多个块的起始位置,包含如下信息:表 MinipageEntry 重要成员、firstRowNum 起始行号、fileOffset 文件内偏移位置、rowCount 行数。
索引扫描或者位图扫描时,会通过 AOTupleId 读取单个元组,其扫描过程如下:
1、通过 AOTupleId 计算得到目标分片文件号 segmentFileNum 和行号 rowNum。
2、如果当前打开分片文件不是 segmentFileNum,则关闭当前文件,重新打开第 segmentFileNum 号文件。
3、判断 AOTupleId 在块目录表中是否存在,如果不存在,说明 AOTupleId 是旧的被回收的元组,或者之前异常终止事务插入的元组,这种情况下,返回读取失败。
4、通过 VisibilityMap 进行可见性检查,如果不可见,返回失败。
5、将文件的读取起止范围设置为块目录表项中的起止范围。由于块目录表项可能对应一个或者多个块,所以表项中记录的起始位置可能比实际的文件块大。
6、调用函数 scanToFetchTuple 在起止范围内逐个读取文件块,直到找到某个块满足:currentBlock.firstRowNum <= rowNum <= currentBlock.lastRowNum。如果没找到,则返回失败。
7、在块内查找查找行号为 rowNum 的元组并返回。
8、保存当前分片文件号,当前块起止行号,当前块目录信息,下次再次读取单个元组时,如果:
a、AOTupleId 在当前起止行号之前,直接在当前块内查找元组,否则直接跳转到 b。
b、在当前块目录范围内,跳转到第 4 步开始执行。
数据可见性设计
AO 表引入了另外一个辅助的 Heap 表 pg_aoseg.pg_aovisimap_,称为 VisibilityMap。该表记录了删除元组的信息,并且通过 MVCC 控制可见效。如果删除成功,通过该表就能查询到删除元组,从而判断元组不可见。如果每个删除的元组占用一行,显然不经济并且低效。大部分情况下,AO 表中元组的访问都是顺序扫描,VisibilityMap 借鉴了块目录表的思路,将多个相邻元组可见性信息放在一起存储。
Greenplumn 中用位图来表示每个分片文件中元组的可见性,如果元组被删除,对应位图的比特位置 1。每 32768(APPENDONLY_VISIMAP_MAX_RANGE)个元组的可见性比特位作为一个位图存储在表 pg_aoseg.pg_aovisimap_的 visimap 属性中。
Greenplum 中在位图表上建立了索引,方便快速查找。每个位图 4096 个字节,包含 32768 位,可以表示 32768 个元组的可见性。VisibilityMap 通过函数 AppendOnlyVisimapDelete_Init 开始位图的修改,通过函数 AppendOnlyVisimapDelete_Finish 结束位图的修改。当某个行被删除时,需要判断该行对应的位图是否以及已经在 VisibilityMap 表中已记录,如果是则读入内存中,否则初始化一个全零的位图。
AOCS 列存的设计
AO 表整个行一起存储,当需要读取属性内容时,首先需要读取变长块,解压缩,然后再获取其中一个属性的值。这样做有时代价非常高,即使查询只涉及其中一个属性,也需要将所有内容读出来。在 OLAP 分析领域,列式存储是应对这种查询场景、提高性能的常见优化方式。Greenplum 中也提供列式存储:AOCS
AOCS 将不同的属性分成不同的文件存储。查询时,只需要读取需要的属性所对应的文件,其它属性不需要读入,节省了磁盘 IO 开销。
同 AO 表一样,AOCS 的访问也不需要通过共享缓冲区管理器,直接从磁盘进行读写。另外,AOCS 对数据的压缩做了特殊的处理,能够获得更好的表现。
AOCS 表的存储类似 AO 表的存储,但是将每个列存储在单独的分片文件中,其中,第 0 到 127 号分片文件存储第一个属性,第 128 到 255 号分片文件存储第二个属性,依次类推。其中,第 0,128,256 等文件逻辑上属于第 0 个分片文件,分配给 Utility 模式使用,第 1,129,257 等文件逻辑上属于第 1 个分片文件,依次类推。
对于 MPP 模式,一个可以支持 127 个分配文件并发写。通过这种物理文件映射到逻辑分片文件的方法,AOCS 表可以复用与 AO 表相同的逻辑,比如 AOTupleId、索引、VisibilityMap。
结语
HashData 内核基于开源的 PostgreSQL 和 Greenplum Database 构建,元数据采用开源的 KV 数据库 FoundationDB 提供持久化,通过 ORC、Parquet 等开放文件格式与其它大数据系统实现互通互联。
传统的 Greenplum、Teradata 等 MPP 架构的数据库,存储、计算是紧耦合的,数据存储在本地系统,存储能力的扩展通过增加集群节点实现,这样会导致计算资源严重浪费,无法满足业务的发展。
作为一款企业级数据仓库产品,HashData 在 PostgreSQL 和 Greenplum Database 等平台丰富的分析功能的基础上,针对云平台特性进行了大量改进和优化,实现了存算分离、湖仓一体化,满足企业对海量数据的分析与处理需求,加速企业数字化转型。

HashData 研发、行业销售、工程服务等岗位正在火热招聘中,欢迎扫描上图二维码获取职位详细信息,和我们随时联系!
版权声明: 本文为 InfoQ 作者【HashData】的原创文章。
原文链接:【http://xie.infoq.cn/article/ce8f13e802915aea21cba3ffb】。文章转载请联系作者。

还未添加个人签名 2021-03-10 加入
云原生企业级数据仓库








评论