
前端树形 Tree 数据结构使用 -🤸🏻♂️各种姿势总结
01、树形结构数据
前端开发中会经常用到树形结构数据,如多级菜单、商品的多级分类等。数据库的设计和存储都是扁平结构,就会用到各种 Tree 树结构的转换操作,本文就尝试全面总结一下。
如下示例数据,关键字段id为唯一标识,pid为父级id,用来标识父级节点,实现任意多级树形结构。"pid": 0“0”标识为根节点,orderNum属性用于控制排序。
在前端使用的时候,如树形菜单、树形列表、树形表格、下拉树形选择器等,需要把数据转换为树形结构数据,转换后的数据结效果图:
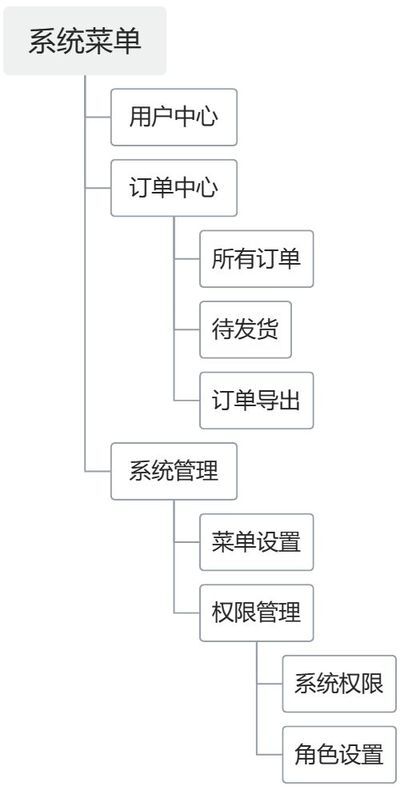
预期的树形数据结构:多了children数组存放子节点数据。
02、列表转树-list2Tree
常用的算法有 2 种:
🟢递归遍历子节点:先找出根节点,然后从根节点开始递归遍历寻找下级节点,构造出一颗树,这是比较常用也比较简单的方法,缺点是数据太多递归耗时多,效率不高。还有一个隐患就是如果数据量太,递归嵌套太多会造成 JS 调用栈溢出,参考《JavaScript函数(2)原理{深入}执行上下文》。
🟢2 次循环 Object 的 Key 值:利用数据对象的
id作为对象的key创建一个map对象,放置所有数据。通过对象的 key 快速获取数据,实现快速查找,再来一次循环遍历获取根节点、设置父节点,就搞定了,效率更高。
🟢递归遍历
从根节点递归,查找每个节点的子节点,直到叶子节点(没有子节点)。
🟢object 的 Key 遍历
简单理解就是一次性循环遍历查找所有节点的父节点,两个循环就搞定了。
第一次循环,把所有数据放入一个 Object 对象 map 中,id 作为属性 key,这样就可以快速查找指定节点了。
第二个循环获取根节点、设置父节点。
分开两个循环的原因是无法完全保障父节点数据一定在前面,若循环先遇到子节点,map 中还没有父节点的,否则一个循环也是可以的。
参数
option为数据结构的配置,就可以兼容各种命名的数据结构了。option中的parent支持函数,兼容一些复杂的数据结构,如parent: (n) => n.meta.parentName,父节点属性存在一个复合对象内部。
测试一下:
对比一下
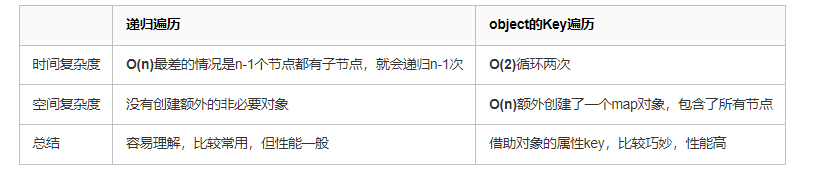
延伸一下:Map 和 Object 哪个更快?
在上面的方案 2(object 的 Key 遍历)中使用的是 Object,其实也是可以用 ES6 新增的 Map 对象。Object、Map 都可用作键值查找,速度都还是比较快的,他们内部使用了哈希表(hash table)、红黑树等算法,不过不同引擎可能实现不同。
大多数情况下 Map 的键值操作是要比 Object 更高效的,比如频繁的插入、删除操作,大量的数据集。相对而言,数据量不多,插入、删除比较少的场景也是可以用 Object 的。
03、树转列表-tree2List
树形数据结构转列表,这就简单了,广度优先,先横向再纵向,从上而下依次遍历,把所有节点都放入一个数组中即可。
04、设置节点不可用-setTreeDisable
递归设置树形结构中数据的 disabled 属性值为不可用。使用场景:在修改节点所属父级时,不可选择自己及后代。
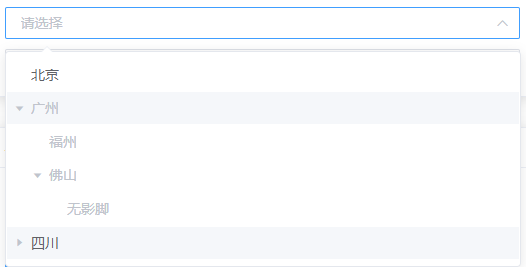
基本思路:
先重置
disabled属性,递归树所有节点,这一步可根据实际情况优化下。设置目标节点及其子节点的
disabled属性。
05、搜索过滤树-filterTree
搜索树中符合条件的节点,但要包含其所有上级节点(父节点可能并没有命中),便于友好展示。当树形结构的数据量大、结构深时,搜索功能就很有必要了。
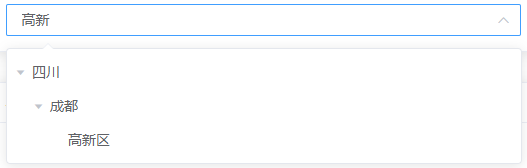
基本思路:
为避免污染原有 Tree 数据,这里的对象都使用了简单的浅拷贝
const newNode = { ...node }。递归为主的思路,子节点有命中,则会包含父节点,当然父节点的
children会被重置。
文章转载自:安木夕

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论