
线上 sql 执行慢,分享 3 个优化案例
本文所讲述 MySql 8.0+
代码演示地址:github.com/wayn111/new…
博主 github 地址:github.com/wayn111 欢迎大家关注,点个 star
一、or 查询条件错误
线上有一个第三方账户扫码绑定手机号登录的接口,这个接口正常逻辑如下:
使用 苹果、QQ、微信获取扫描客户端登录二维码,获取用户第三方账户唯一 ID 后。
判断第三方账户 ID 是否存在用户表中,存在且已绑定手机号则直接返回用户 token 进行登录操作。
不存在则提示用户进行绑定手机号操作。
用户填写手机号及短信验证码后,进行第三方账户唯一 ID 与手机号的绑定,成功则返回用户 token 进行登录操作。
博主记得这个接口是在 21 年 10 月上线的,到现在经历了一年多,接口执行时间是越来越慢,初步分析是用户数量持续增长,用户表记录越来越多,导致 sql 查询执行效率越来越低导致。这里用 vc_member_bak 进行举例,表结构以及数据展示,其中 apple_id、weixn_id、qq_id 有建立索引
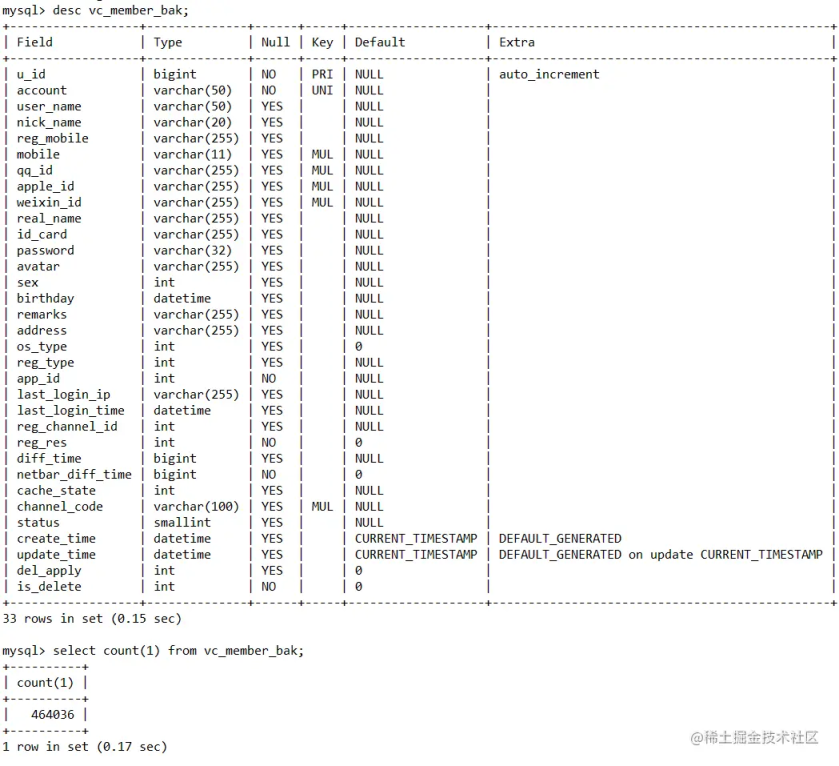
vc_member_bak 表数据量在 46 万左右,开启日志分析后,发现是下面这条 sql 执行太慢导致
执行结果:
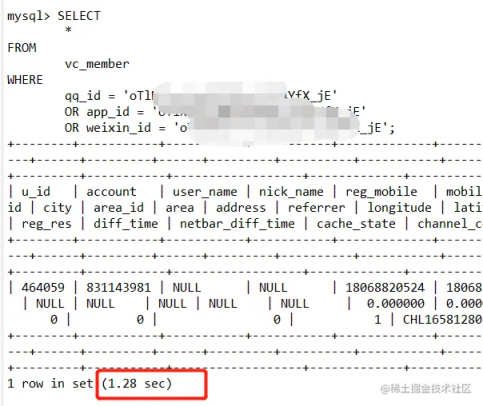
需要 1.3 秒左右,这是在我本地模拟的数据,线上用户在百万级别,耗时已经达到 2、3 秒,于是博主开始上 explain,分析 sql 执行
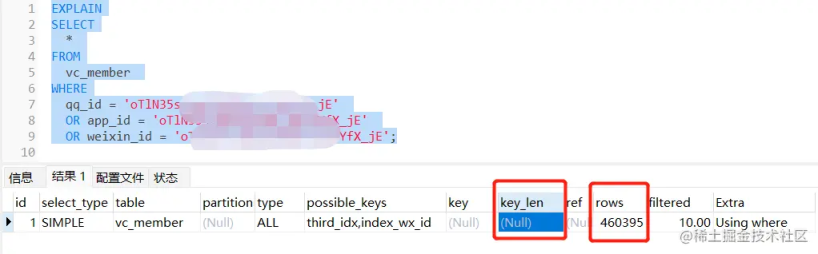
由于 explain 结果中 key 列为空,明显可知虽然 possible_keys 列有值,但是执行过程中,没有使用索引导致全表查询,从 rows 列为 46 万可以看出已经基本接近于全表查询。
那么问题出在哪里?我们不是已经给 apple_id、weixn_id、qq_id 三个字段都添加索引了吗。
于是博主仔细查询 sql 语句发现里面有坑,查询的 where 条件上使用的三个条件字段是分别是 app_id、weixin_id、qq_id,而我们的索引字段是 apple_id、weixn_id、qq_id,很明显这是查询字段 apple_id 写成 app_id 了导致。app_id 没有加索引,所以在 or 条件查询下执行的就是全表扫描。
更改字段后执行结果:
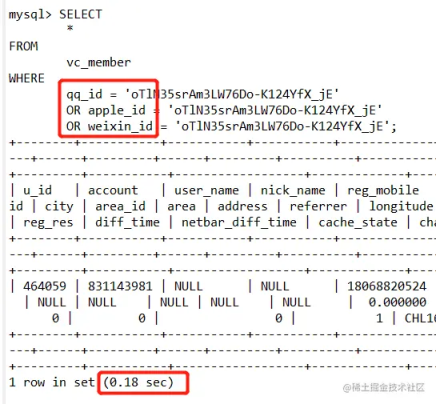
Ok,这里发现了是查询字段写错了,那么修改查询字段正确后,查询 0.18 秒就正常了。😂
二、update 批量更新优化
博主以前线上项目(Spring Boot + Mybatis)有一个接口需要批量更新库存,当时博主本着不能再代码 for 循环中执行更新逻辑的初衷,决定再 xml 文件中使用 foreach 标签执行批量更新逻辑,展示如下:
可以看出这个更新 sql 本质上就是在一条 sql 里执行了多个 update 语句。这个写法虽然不是在代码 for 循环中执行,但是这条 sql 语句执行时,MySql 任然是单条单条执行的。这里用 tb_newbee_mall_goods_info 表举例,表结构展示:
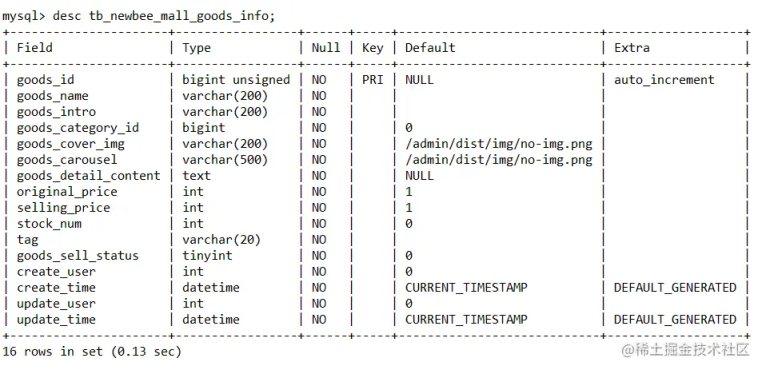
3 个 update 语句同时执行结果如下:
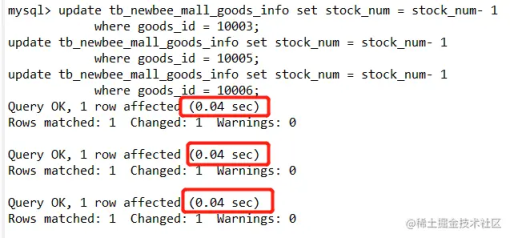
如上,假如其中一个 update 语句需要耗时 40 毫秒,那么当有 100 条 update 语句时,接口耗时就会来到 4 秒,这显然是不可接受的。
那有没有一种高级一点的写法来执行 update 批量更新嘞?
当然是有的,博主后来使用了 update + case 语句完成这个批量更新功能,
update + casesql 如下:
我们通过 SET stock_num = case goods_id when 10004 then stock_num - 1 ... ELSE stock_num END 条件,可以将对应 goods_id 的记录的库存数量设置成我们想要的结果。
PS:需要注意的就是 case when then 语句不匹配时会返回 null,那就会造成不匹配的库存更新为 null。所以 ELSE stock_num END 条件一定要带上,当不匹配 case when then 条件时,将库存数量设置成原本数量。where 条件在这里其实可以不加,它起到的作用是限制更新范围,但是建议还是要加上,避免 sql 写错时,造成脏数据范围过大。
update + case 执行结果:

可以看出我们更新了 3 条记录,耗时 50 毫秒,更新记录越多时,优化效果也就明显。
三、多线程优化大批量数据插入速度
博主线上有一个 cdk 兑换码业务,运营在后台创建一批 cdk 码时,系统会将这批码插入数据库中保存,这样可以保证用户兑换 cdk 时,码在数据库存在才能兑换,保障安全性。当运营创建十万条 cdk 记录时,线上耗时达到了十几秒。这里用 cdk_info 表举例,表结构展示:
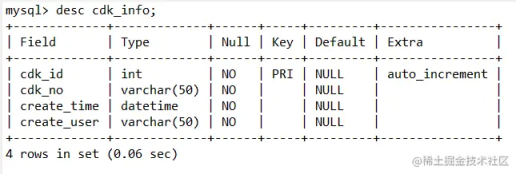
假如我们现在需要保存十万条 cdk_info 记录,分批次保存代码如下:
执行耗时:

可以看到在单一线程下,插入十万条记录差不多需要 15 秒了,这十万条数据之间没有关联,互不影响,那我们可以通过线程池提交单一批次的保存任务,配合 CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join() 方法,等所有任务执行完成拿到结果。代码如下:
执行耗时:

可以看到执行耗时 2.5 秒,执行时间缩短了 6 倍。
总结
到这里,本文所分享的 3 个优化案例就介绍完了,希望对大家日常开发有所帮助,喜欢的朋友们可以点赞加关注😘。
作者:wayn
链接:https://juejin.cn/post/7212192717395771452
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

还未添加个人签名 2023-02-14 加入
还未添加个人简介









评论