
柏睿向量数据库 Rapids VectorDB 赋能企业级大模型构建及智能应用
ChatGPT 的问世,在为沉寂已久的人工智能重新注入活力的同时,也把长期默默无闻的向量数据库推上舞台。今年 4 月以来,全球已有 4 家知名向量数据库公司先后获得融资,更加印证了向量数据库在 AI 大模型时代的价值。
什么是向量数据库?
在认识向量数据库前,先来了解一下最常见的关系型数据库。传统关系型数据库将数据以行和列的形式存储,一组行和列组成一个表,这些表组合在一起形成数据库。通过行和列能够准确定位所需的数据。然而,当存储文本、图像和音视频等非结构化数据时,传统关系型数据库却难以对语义、颜色等属性进行相似性比较,也难以实现有效的检索。
因此,向量数据库应运而生。向量数据库可能够把这些无法直接比较的对象转化为向量形式,即统一处理成多维空间里的坐标值。通过比较这些向量在向量空间中的关系,即可以实现对复杂非结构化数据的检索。
本质上,向量数据库是一种能够存储、管理、查询和检索向量的数据库。它使得非结构化数据的处理更加灵活高效。目前常见的个性化推荐、以图搜图、哼唱搜歌、问答机器人等应用功能,其内核都是向量数据库。
为什么 LLM 需要向量数据库
大语言模型具有理解和生成自然语言文本的能力。它通过学习大量的文本数据,来预测下一个词或下一段话的可能性,从而更好地理解和生成人类语言。但是,大语言模型也存在一些缺陷,如缺乏垂直领域或私域知识,缺乏长期记忆,缺乏事实一致性等,使得用户遇到大模型回答专业度不够、理解不准确、时效性差等问题。
向量数据库与大模型的结合有助于这些问题的解决。向量数据库能够为大模型提供一个可长期记忆的外部知识库,使大模型可以根据用户的查询,在向量数据库中检索相关数据、知识,并根据数据的内容和语义来更新上下文,还能通过回忆自己过往的知识和经验,从而生成更相关和精确的文本。
向量数据库的技术原理与优势
针对传统关系型数据库难以处理的非结构化数据、大规模高并发数据检索、模糊匹配等,向量数据库通过数据向量化、相似度搜索等方式来处理,实现实时查询、快速响应,尤其适用于实时推荐系统、金融交易分析等实时应用场景。
数据向量化为语义理解与处理其他非结构化数据提供了一种有效便捷的表示方法,这一技术称为向量嵌入(Vector Embedding),其核心在于将非数值的词汇或符号转化为数值向量表示。典型的做法是利用神经网络,将文本中的词汇输入网络,获得对应的词向量输出。每个词向量是数值向量,其中的数值反映了词汇的不同特征。例如,“King”和“Queen”可以分别用不同的数值向量表示,通过计算向量间的距离,可以评估它们的相似程度。

向量数据库引入了相似度搜索,利用余弦相似度、欧氏距离等模糊匹配方式,使得在大规模数据中快速定位相关信息成为可能,实现高效检索和精准匹配;无论是图像还是文本查询,用户均能即刻找到最相似结果。
向量数据库的运行原理如下:
a.写入部分
将文本、图像、语音等非结构化数据通过嵌入模型(Embedding Model)转化为向量;
将转化好的向量与元数据通过索引技术(Indexing)储存到向量数据库中。
b.查询部分
通过元数据查询直接匹配元数据索引;
输入文本、图像或语音等非结构化数据,并通过嵌入模型转化为向量索引(Vector Index);
在嵌入空间(Embedding Space)中,通过近似最近邻搜索算法,计算查询与向量索引相似度最高的向量,即我们所需查询的向量。

柏睿向量数据库 Rapids VectorDB 是一款高性能、轻量化、可扩展的向量数据库,基于全内存分布式架构,支持对向量数据的高效存储、检索、分析。它具有以下特点优势:
a.高性能
基于 HNSW 向量相似度算法的快速查询。
b.可扩展
支持分布式扩展,可存储十亿级数据。
c.高集成
支持 Python, Java 和 Javascript API;
内置多种词嵌入模型,同时支持自定义模型来进行向量嵌入;
支持与 LangChain 框架集成,快速构建内存级 LLM 应用。
企业如何构建垂直领域的智能服务
据 Gartner 日前调查显示,在中国已经有 6%的用户部署了大语言模型、生成式 AI 相关技术,有 26%的用户已经在积极试点,还有 24%左右的用户称未来 0-6 个月会部署相关应用或技术。目前,企业构建垂直领域的 LLM 智能服务存在两种模式。
a.微调大模型参数适配企业领域
这种方法将垂直领域或私域内容加入训练集,以微调现有大模型。虽然避免了从零开始训练模型,但仍需投入较大成本且更新频率较低。这并非适用于所有行业和企业,且无法完全消除模型的“幻觉”现象,回答准确性难以保证。
b.结合大模型和向量数据库构建深度服务
这种方法结合企业自有知识资产,利用大模型和向量数据库构建垂直领域的服务。核心在于知识库的提示工程,随文档更新知识库立即更新,且输出的答案来源清晰可信。
在要求大模型时效性和准确性的业务场景中,第二种模式无疑是更优选择。
Rapids VectorDB + LLM:加速构建企业级智能应用
柏睿数据 Rapids VectorDB 与大模型结合,有助于加速企业级大模型的构建,有效拓展大模型的时空边界,助力企业实现文本图像检索、推荐系统、自然语言处理等场景应用,提供更加专业、实时且智慧的服务。

基于 Rapids VectorDB 与大模型实现知识问答应用
Rapids VectorDB 使大模型拥有“长期记忆”。通过更新数据库中的向量信息,能够保证大模型的准实时性、行业专业性与适用性。
保障私有数据接入大模型的安全性和隐私性。在本地部署或专有云上部署大模型,可在有保护的前提下访问相关隐私数据,避免隐私数据接入外网,很大程度上解决用户的 prompt 隐私泄漏问题。
同时,企业基于柏睿 LLMOps 平台和 Rapids VectorDB,能够简化大模型支持应用程序的开发、部署和维护过程,更高效地部署好用、可靠、精准的 AI 大模型,加速释放大模型在垂直应用场景中的潜力。
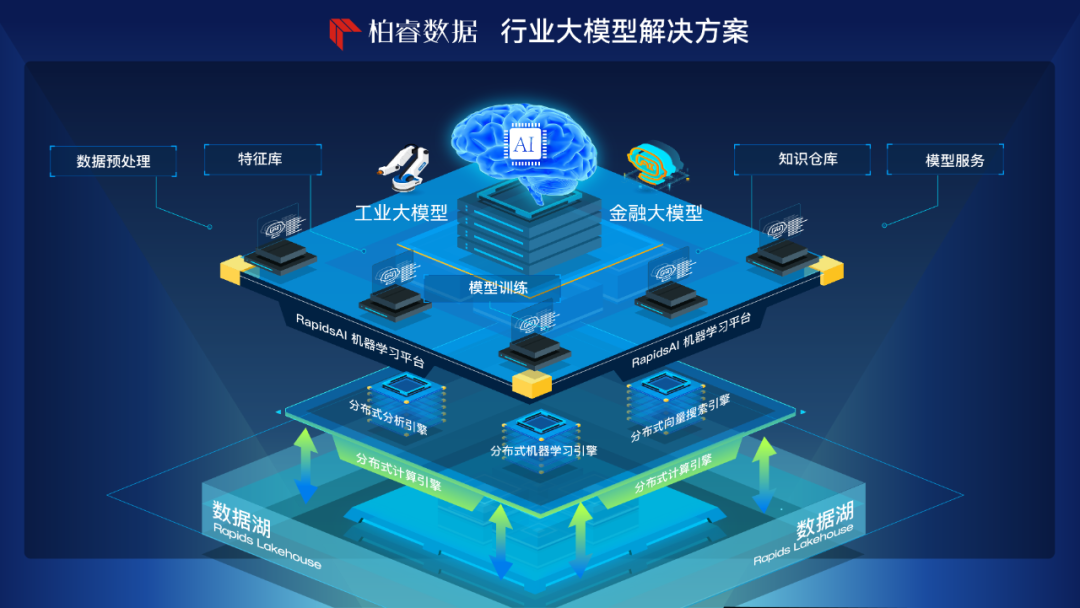
展望未来,柏睿数据也将持续深度打磨技术能力,提供更坚实的 Data+AI 基础设施,全面迎接 AI 大模型时代。

还未添加个人签名 2022-09-22 加入
还未添加个人简介









评论