
《深入理解 Mybatis 原理》Mybatis 中的缓存实现原理
一级缓存实现
什么是一级缓存? 为什么使用一级缓存?
每当我们使用 MyBatis 开启一次和数据库的会话,MyBatis 会创建出一个 SqlSession 对象表示一次数据库会话。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis 会在表示会话的 SqlSession 对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis 一次会话: 一个 SqlSession 对象中创建一个本地缓存(local cache),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。
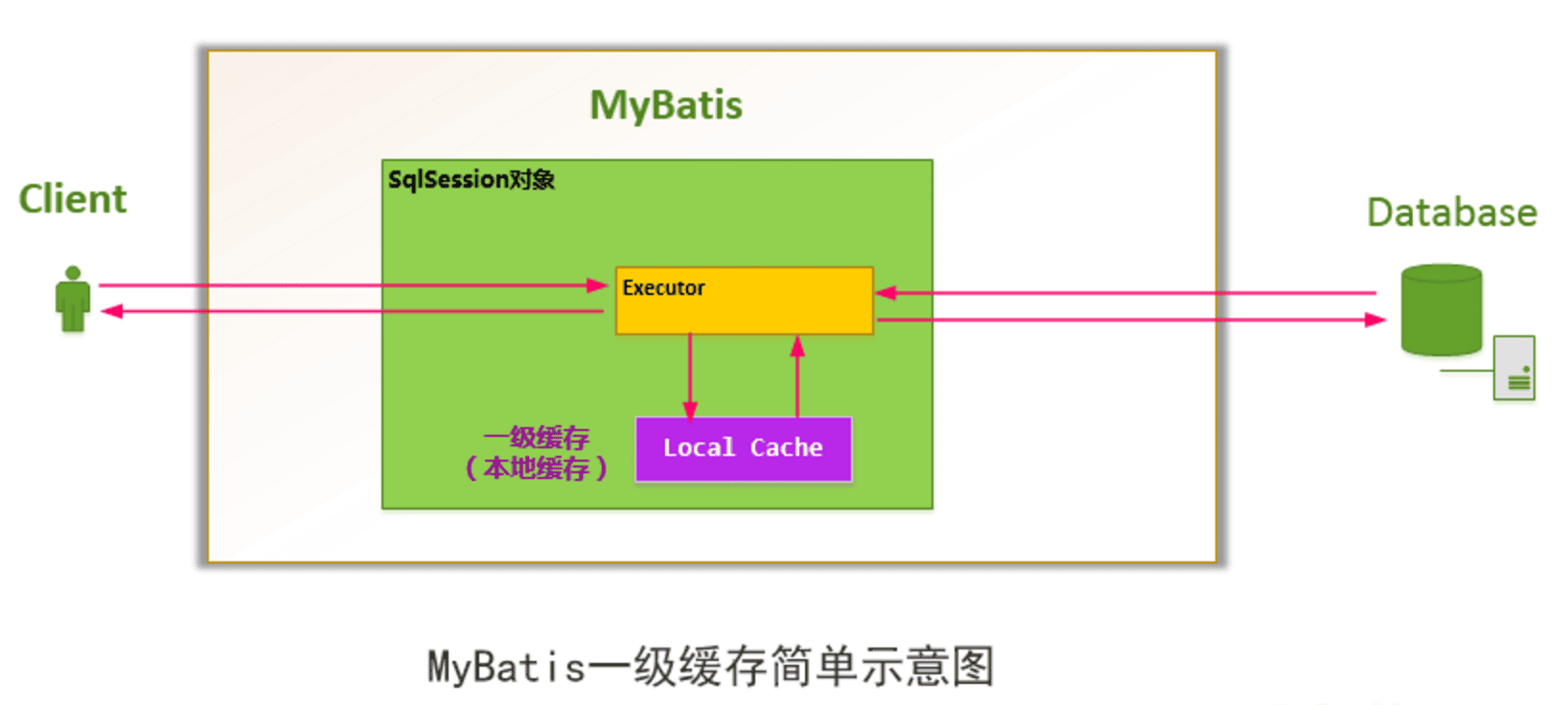
对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
MyBatis 中的一级缓存是怎样组织的?
即 SqlSession 中的缓存是怎样组织的?由于 MyBatis 使用 SqlSession 对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在 SqlSession 中控制的。
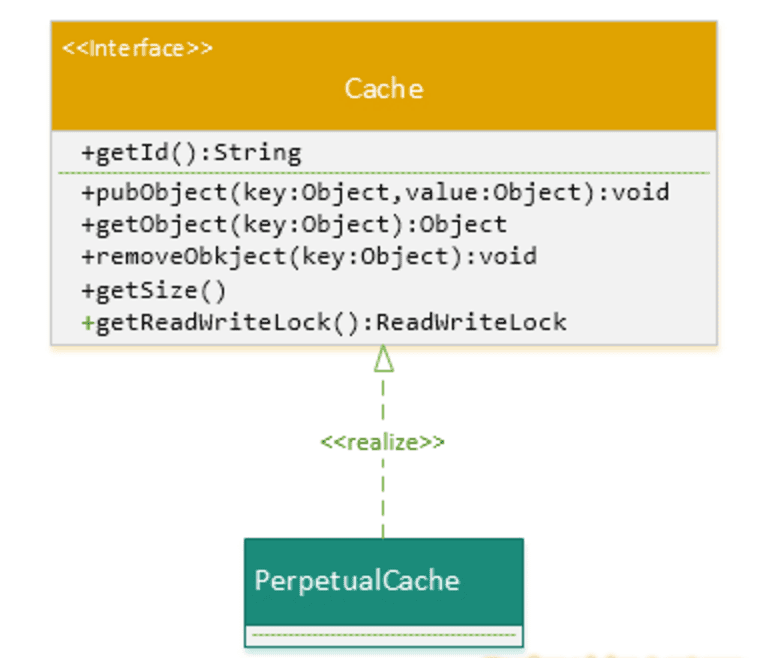
实际上, MyBatis 只是一个 MyBatis 对外的接口,SqlSession 将它的工作交给了 Executor 执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个 SqlSession 对象时,MyBatis 会为这个 SqlSession 对象创建一个新的 Executor 执行器,而缓存信息就被维护在这个 Executor 执行器中,MyBatis 将缓存和对缓存相关的操作封装成了 Cache 接口中。SqlSession、Executor、Cache 之间的关系如下列类图所示:
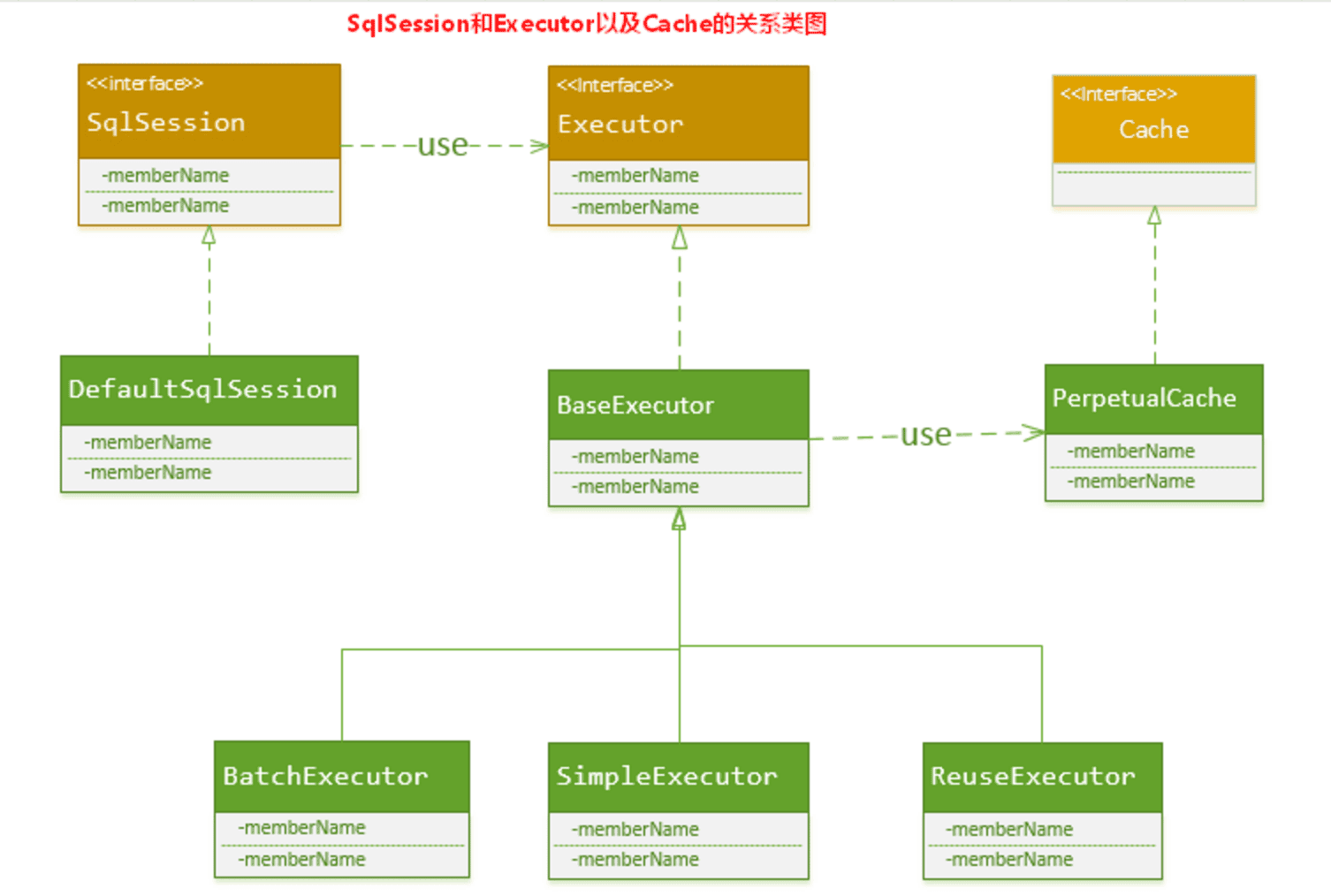
如上述的类图所示,Executor 接口的实现类 BaseExecutor 中拥有一个 Cache 接口的实现类 PerpetualCache,则对于 BaseExecutor 对象而言,它将使用 PerpetualCache 对象维护缓存。
综上,SqlSession 对象、Executor 对象、Cache 对象之间的关系如下图所示:
由于 Session 级别的一级缓存实际上就是使用 PerpetualCache 维护的,那么 PerpetualCache 是怎样实现的呢?
PerpetualCache 实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v> 来实现的,没有其他的任何限制。如下是 PerpetualCache 的实现代码:
一级缓存的生命周期有多长?
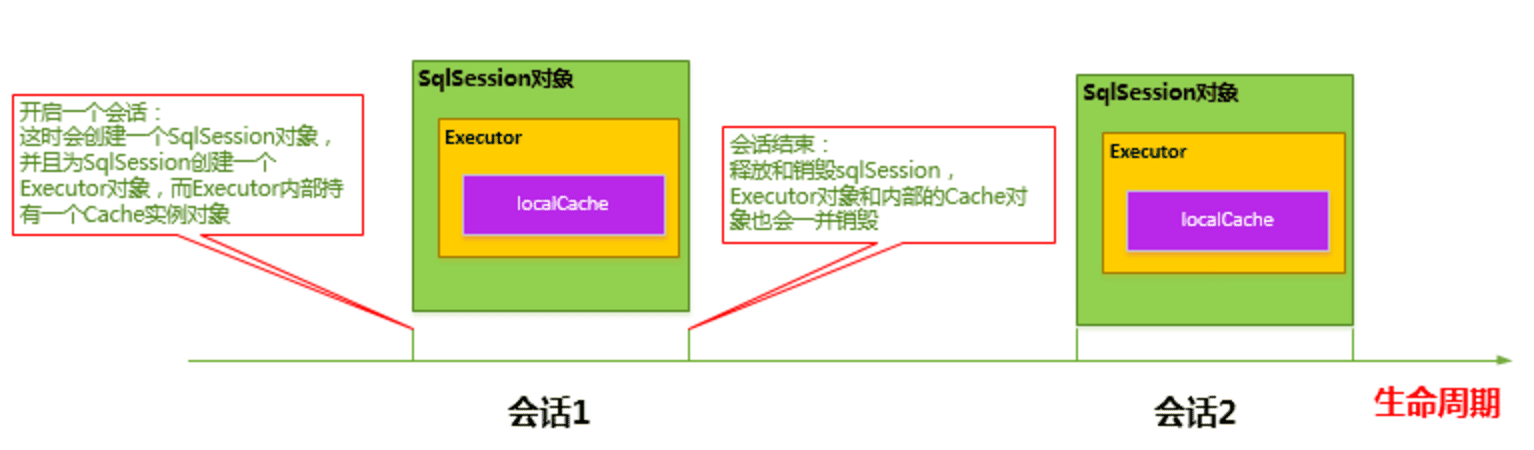
MyBatis 在开启一个数据库会话时,会创建一个新的 SqlSession 对象,SqlSession 对象中会有一个新的 Executor 对象,Executor 对象中持有一个新的 PerpetualCache 对象;当会话结束时,SqlSession 对象及其内部的 Executor 对象还有 PerpetualCache 对象也一并释放掉。
如果 SqlSession 调用了 close()方法,会释放掉一级缓存 PerpetualCache 对象,一级缓存将不可用;
如果 SqlSession 调用了 clearCache(),会清空 PerpetualCache 对象中的数据,但是该对象仍可使用;
SqlSession 中执行了任何一个 update 操作(update()、delete()、insert()) ,都会清空 PerpetualCache 对象的数据,但是该对象可以继续使用;
SqlSession 一级缓存的工作流程
对于某个查询,根据 statementId,params,rowBounds 来构建一个 key 值,根据这个 key 值去缓存 Cache 中取出对应的 key 值存储的缓存结果;
判断从 Cache 中根据特定的 key 值取的数据数据是否为空,即是否命中;
如果命中,则直接将缓存结果返回;
如果没命中:去数据库中查询数据,得到查询结果;将 key 和查询到的结果分别作为 key,value 对存储到 Cache 中;将查询结果返回;
结束。

Cache 接口的设计以及 CacheKey 的定义
如下图所示,MyBatis 定义了一个 org.apache.ibatis.cache.Cache 接口作为其 Cache 提供者的 SPI(Service Provider Interface) ,所有的 MyBatis 内部的 Cache 缓存,都应该实现这一接口。MyBatis 定义了一个 PerpetualCache 实现类实现了 Cache 接口,实际上,在 SqlSession 对象里的 Executor 对象内维护的 Cache 类型实例对象,就是 PerpetualCache 子类创建的。
(MyBatis 内部还有很多 Cache 接口的实现,一级缓存只会涉及到这一个 PerpetualCache 子类,Cache 的其他实现将会放到二级缓存中介绍)。
我们知道,Cache 最核心的实现其实就是一个 Map,将本次查询使用的特征值作为 key,将查询结果作为 value 存储到 Map 中。现在最核心的问题出现了:怎样来确定一次查询的特征值?换句话说就是:怎样判断某两次查询是完全相同的查询?也可以这样说:如何确定 Cache 中的 key 值?
MyBatis 认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
传入的 statementId
查询时要求的结果集中的结果范围 (结果的范围通过 rowBounds.offset 和 rowBounds.limit 表示)
这次查询所产生的最终要传递给 JDBC java.sql.Preparedstatement 的 Sql 语句字符串(boundSql.getSql() )
传递给 java.sql.Statement 要设置的参数值
现在分别解释上述四个条件:
传入的 statementId,对于 MyBatis 而言,你要使用它,必须需要一个 statementId,它代表着你将执行什么样的 Sql;
MyBatis 自身提供的分页功能是通过 RowBounds 来实现的,它通过 rowBounds.offset 和 rowBounds.limit 来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
由于 MyBatis 底层还是依赖于 JDBC 实现的,那么,对于两次完全一模一样的查询,MyBatis 要保证对于底层 JDBC 而言,也是完全一致的查询才行。而对于 JDBC 而言,两次查询,只要传入给 JDBC 的 SQL 语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
上述的第 3 个条件正是要求保证传递给 JDBC 的 SQL 语句完全一致;第 4 条则是保证传递给 JDBC 的参数也完全一致;即 3、4 两条 MyBatis 最本质的要求就是:调用 JDBC 的时候,传入的 SQL 语句要完全相同,传递给 JDBC 的参数值也要完全相同。
综上所述,CacheKey 由以下条件决定:statementId + rowBounds + 传递给 JDBC 的 SQL + 传递给 JDBC 的参数值;
CacheKey 的创建
对于每次的查询请求,Executor 都会根据传递的参数信息以及动态生成的 SQL 语句,将上面的条件根据一定的计算规则,创建一个对应的 CacheKey 对象。
我们知道创建 CacheKey 的目的,就两个:
根据 CacheKey 作为 key,去 Cache 缓存中查找缓存结果;
如果查找缓存命中失败,则通过此 CacheKey 作为 key,将从数据库查询到的结果作为 value,组成 key,value 对存储到 Cache 缓存中;
CacheKey 的构建被放置到了 Executor 接口的实现类 BaseExecutor 中,定义如下:
CacheKey 的 hashcode 生成算法
刚才已经提到,Cache 接口的实现,本质上是使用的HashMap<k,v>,而构建 CacheKey 的目的就是为了作为HashMap<k,v>中的 key 值。而 HashMap 是通过 key 值的 hashcode 来组织和存储的,那么,构建 CacheKey 的过程实际上就是构造其 hashCode 的过程。下面的代码就是 CacheKey 的核心 hashcode 生成算法,感兴趣的话可以看一下:
MyBatis 认为的完全相同的查询,不是指使用 sqlSession 查询时传递给算起来 Session 的所有参数值完完全全相同,你只要保证 statementId,rowBounds,最后生成的 SQL 语句,以及这个 SQL 语句所需要的参数完全一致就可以了。
一级缓存的性能分析
MyBatis 对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了 HashMap 来维护,并没有对 HashMap 的容量和大小进行限制
读者有可能就觉得不妥了:如果我一直使用某一个 SqlSession 对象查询数据,这样会不会导致 HashMap 太大,而导致 java.lang.OutOfMemoryError 错误啊? 读者这么考虑也不无道理,不过 MyBatis 的确是这样设计的。
MyBatis 这样设计也有它自己的理由:
一般而言 SqlSession 的生存时间很短。一般情况下使用一个 SqlSession 对象执行的操作不会太多,执行完就会消亡;
对于某一个 SqlSession 对象而言,只要执行 update 操作(update、insert、delete),都会将这个 SqlSession 对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响 JVM 内存空间的问题;
可以手动地释放掉 SqlSession 对象中的缓存。
一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念
MyBatis 的一级缓存就是使用了简单的 HashMap,MyBatis 只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
根据一级缓存的特性,在使用的过程中,我认为应该注意:
对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用 SqlSession 查询的时候,要控制好 SqlSession 的生存时间, SqlSession 的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空 SqlSession 中的缓存;
对于只执行、并且频繁执行大范围的 select 操作的 SqlSession 对象,SqlSession 对象的生存时间不应过长。
二级缓存实现
MyBatis 的二级缓存是 Application 级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
MyBatis 的缓存机制整体设计以及二级缓存的工作模式
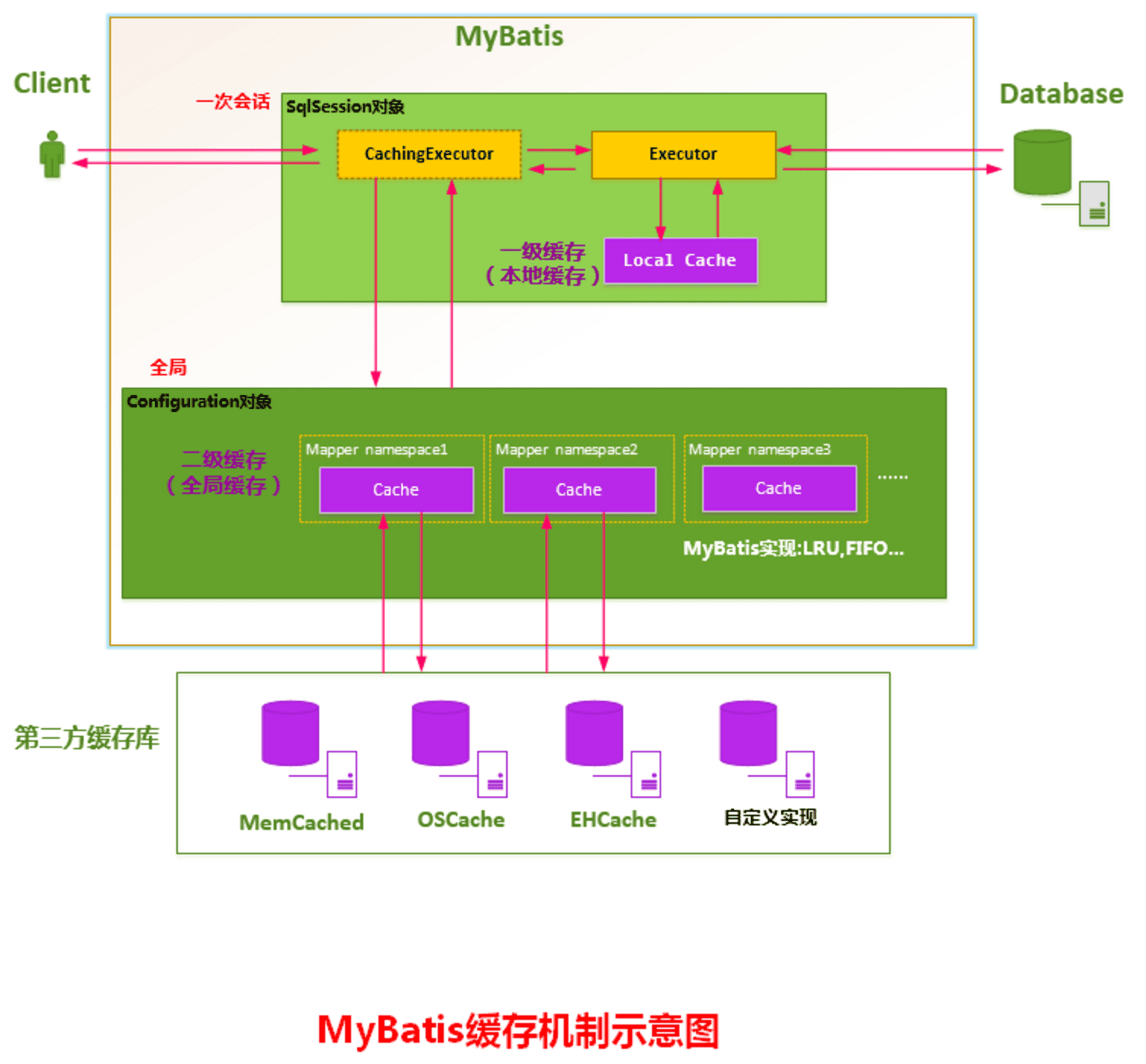
如图所示,当开一个会话时,一个 SqlSession 对象会使用一个 Executor 对象来完成会话操作,MyBatis 的二级缓存机制的关键就是对这个 Executor 对象做文章。如果用户配置了"cacheEnabled=true",那么 MyBatis 在为 SqlSession 对象创建 Executor 对象时,会对 Executor 对象加上一个装饰者:CachingExecutor,这时 SqlSession 使用 CachingExecutor 对象来完成操作请求。CachingExecutor 对于查询请求,会先判断该查询请求在 Application 级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的 Executor 对象来完成查询操作,之后 CachingExecutor 会将真正 Executor 返回的查询结果放置到缓存中,然后在返回给用户。
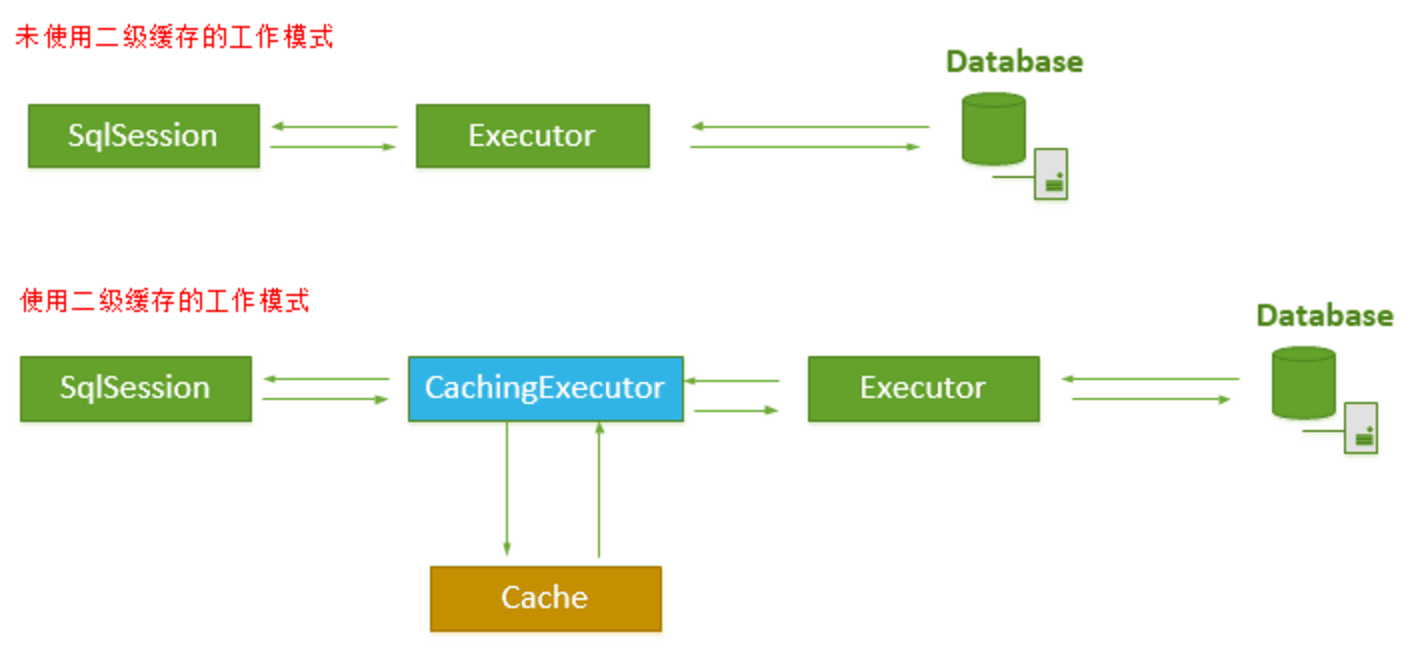
CachingExecutor 是 Executor 的装饰者,以增强 Executor 的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式,CachingExecutor 和 Executor 的接口的关系如下类图所示:
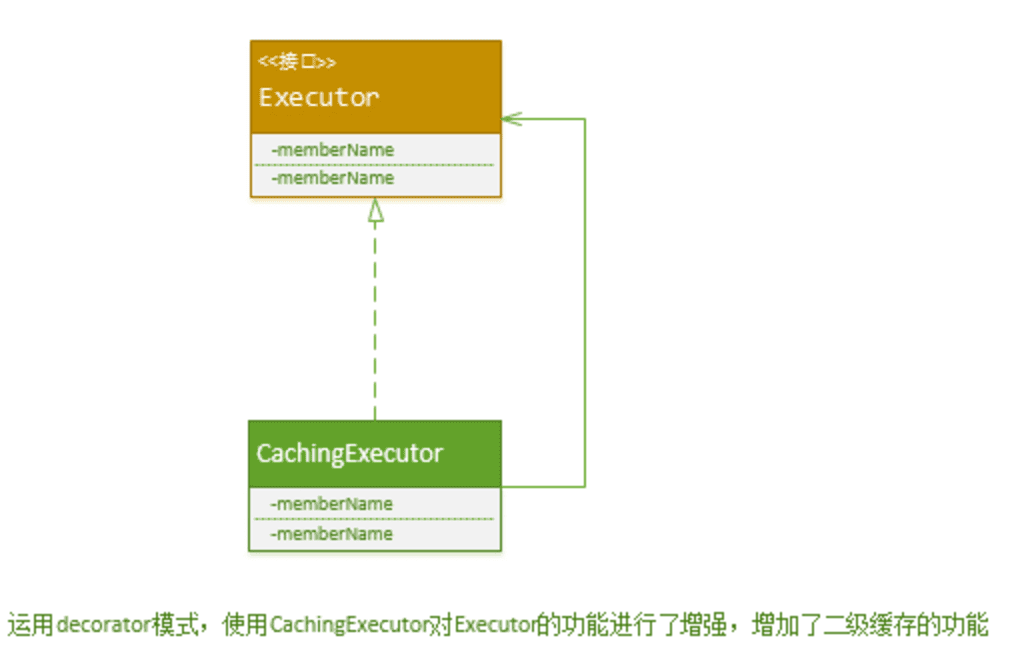
MyBatis 二级缓存的划分
MyBatis 并不是简单地对整个 Application 就只有一个 Cache 缓存对象,它将缓存划分的更细,即是 Mapper 级别的,即每一个 Mapper 都可以拥有一个 Cache 对象,具体如下:
为每一个 Mapper 分配一个 Cache 缓存对象(使用
<cache>节点配置)
MyBatis 将 Application 级别的二级缓存细分到 Mapper 级别,即对于每一个 Mapper.xml,如果在其中使用了<cache> 节点,则 MyBatis 会为这个 Mapper 创建一个 Cache 缓存对象,如下图所示:
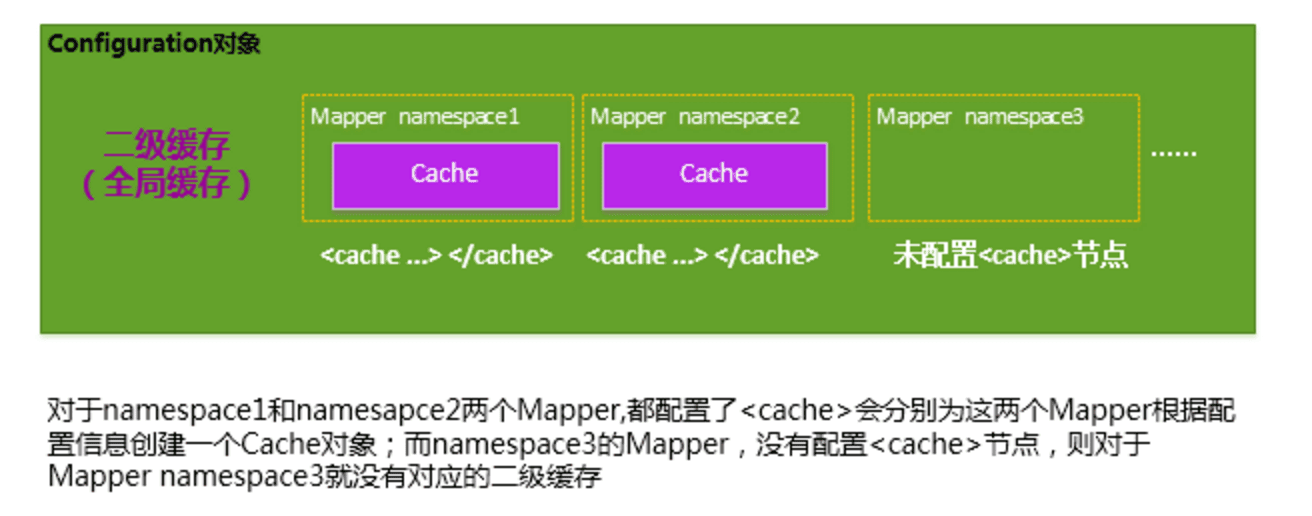
注:上述的每一个 Cache 对象,都会有一个自己所属的 namespace 命名空间,并且会将 Mapper 的 namespace 作为它们的 ID;
多个 Mapper 共用一个 Cache 缓存对象(使用
<cache-ref>节点配置)
如果你想让多个 Mapper 公用一个 Cache 的话,你可以使用<cache-ref namespace="">节点,来指定你的这个 Mapper 使用到了哪一个 Mapper 的 Cache 缓存。
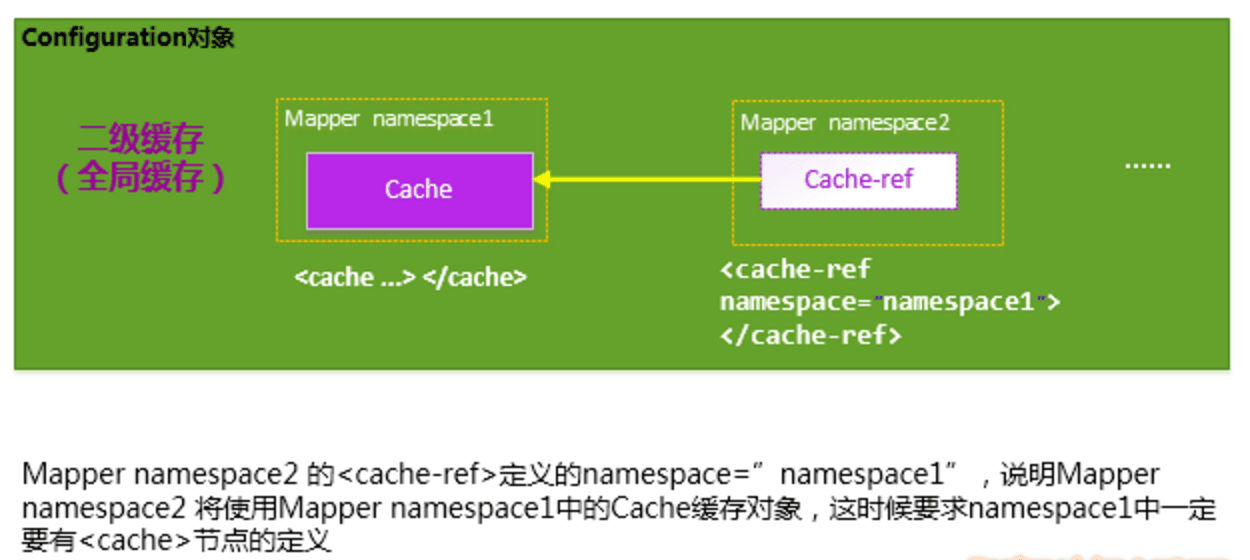
使用二级缓存,必须要具备的条件
MyBatis 对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在 Mapper 中配置了<cache>,并且为此 Mapper 分配了 Cache 对象,这并不表示我们使用 Mapper 中定义的查询语句查到的结果都会放置到 Cache 对象之中,我们必须指定 Mapper 中的某条选择语句是否支持缓存,即如下所示,在<select> 节点中配置 useCache="true",Mapper 才会对此 Select 的查询支持缓存特性,否则,不会对此 Select 查询,不会经过 Cache 缓存。如下所示,Select 语句配置了 useCache="true",则表明这条 Select 语句的查询会使用二级缓存。
总之,要想使某条 Select 查询支持二级缓存,你需要保证:
MyBatis 支持二级缓存的总开关:全局配置变量参数 cacheEnabled=true
该 select 语句所在的 Mapper,配置了
<cache>或<cached-ref>节点,并且有效该 select 语句的参数 useCache=true
一级缓存和二级缓存的使用顺序
请注意,如果你的 MyBatis 使用了二级缓存,并且你的 Mapper 和 select 语句也配置使用了二级缓存,那么在执行 select 查询的时候,MyBatis 会先从二级缓存中取输入,其次才是一级缓存,即 MyBatis 查询数据的顺序是:二级缓存 ———> 一级缓存 ——> 数据库。
二级缓存实现的选择
MyBatis 对二级缓存的设计非常灵活,它自己内部实现了一系列的 Cache 缓存实现类,并提供了各种缓存刷新策略如 LRU,FIFO 等等;另外,MyBatis 还允许用户自定义 Cache 接口实现,用户是需要实现 org.apache.ibatis.cache.Cache 接口,然后将 Cache 实现类配置在<cache type="">节点的 type 属性上即可;除此之外,MyBatis 还支持跟第三方内存缓存库如 Memecached 的集成,总之,使用 MyBatis 的二级缓存有三个选择:
MyBatis 自身提供的缓存实现;
用户自定义的 Cache 接口实现;
跟第三方内存缓存库的集成;
MyBatis 自身提供的二级缓存的实现
MyBatis 自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的 Cache 接口装饰者,可以满足各种对缓存操作和更新的策略。
MyBatis 定义了大量的 Cache 的装饰器来增强 Cache 缓存的功能,如下类图所示。
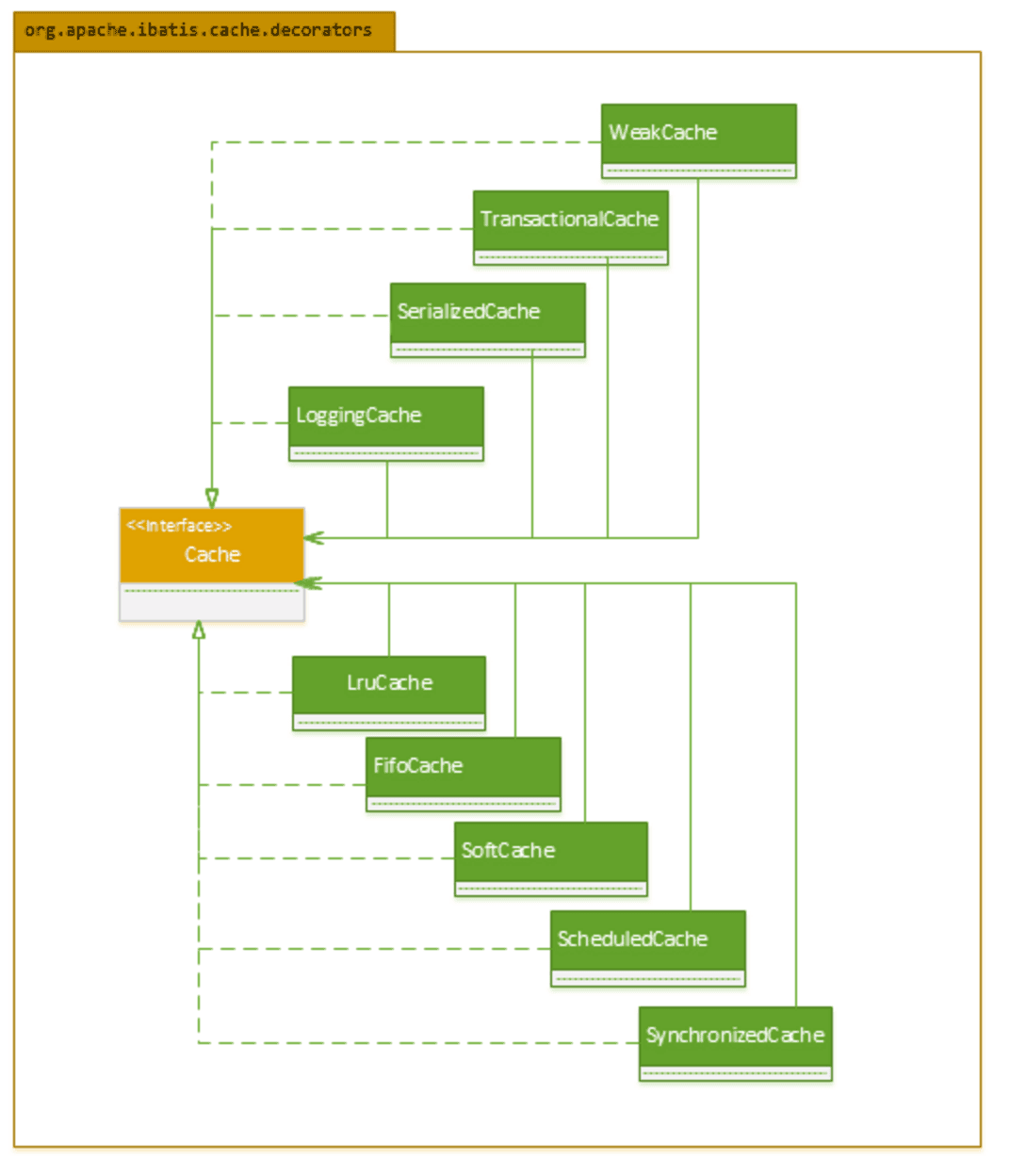
对于每个 Cache 而言,都有一个容量限制,MyBatis 各供了各种策略来对 Cache 缓存的容量进行控制,以及对 Cache 中的数据进行刷新和置换。MyBatis 主要提供了以下几个刷新和置换策略:
LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近最少被使用的缓存记录清除掉,然后添加新的记录;
FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
Scheduled:指定时间间隔清空算法,该算法会以指定的某一个时间间隔将 Cache 缓存中的数据清空;
如何细粒度地控制二级缓存
关于 MyBatis 的二级缓存的实际问题
现有 AMapper.xml 中定义了对数据库表 ATable 的 CRUD 操作,BMapper 定义了对数据库表 BTable 的 CRUD 操作;
假设 MyBatis 的二级缓存开启,并且 AMapper 中使用了二级缓存,AMapper 对应的二级缓存为 ACache;
除此之外,AMapper 中还定义了一个跟 BTable 有关的查询语句,类似如下所述:
执行以下操作:
执行 AMapper 中的"selectATableWithJoin" 操作,此时会将查询到的结果放置到 AMapper 对应的二级缓存 ACache 中;
执行 BMapper 中对 BTable 的更新操作(update、delete、insert)后,BTable 的数据更新;
再执行 1 完全相同的查询,这时候会直接从 AMapper 二级缓存 ACache 中取值,将 ACache 中的值直接返回;
好,问题就出现在第 3 步上:
由于 AMapper 的“selectATableWithJoin” 对应的 SQL 语句需要和 BTable 进行 join 查找,而在第 2 步 BTable 的数据已经更新了,但是第 3 步查询的值是第 1 步的缓存值,已经极有可能跟真实数据库结果不一样,即 ACache 中缓存数据过期了!
总结来看,就是:
对于某些使用了 join 连接的查询,如果其关联的表数据发生了更新,join 连接的查询由于先前缓存的原因,导致查询结果和真实数据不同步;
从 MyBatis 的角度来看,这个问题可以这样表述:
对于某些表执行了更新(update、delete、insert)操作后,如何去清空跟这些表有关联的查询语句所造成的缓存
当前 MyBatis 二级缓存的工作机制
MyBatis 二级缓存的一个重要特点:即松散的 Cache 缓存管理和维护
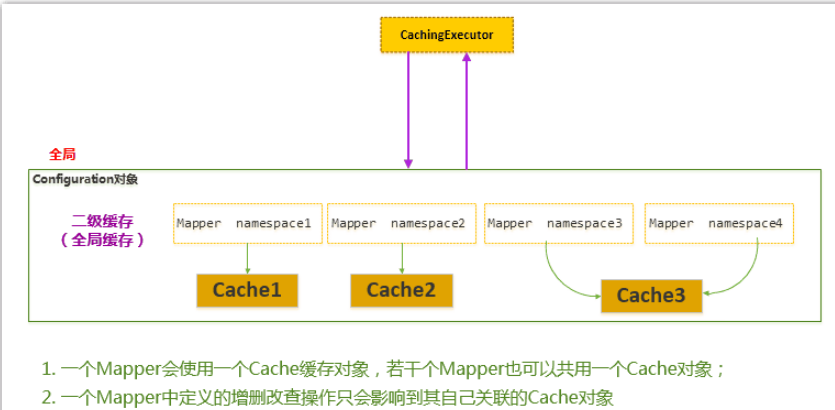
一个 Mapper 中定义的增删改查操作只能影响到自己关联的 Cache 对象。如上图所示的 Mapper namespace1 中定义的若干 CRUD 语句,产生的缓存只会被放置到相应关联的 Cache1 中,即 Mapper namespace2,namespace3,namespace4 中的 CRUD 的语句不会影响到 Cache1。
可以看出,Mapper 之间的缓存关系比较松散,相互关联的程度比较弱。
现在再回到上面描述的问题,如果我们将 AMapper 和 BMapper 共用一个 Cache 对象,那么,当 BMapper 执行更新操作时,可以清空对应 Cache 中的所有的缓存数据,这样的话,数据不是也可以保持最新吗?
确实这个也是一种解决方案,不过,它会使缓存的使用效率变的很低!AMapper 和 BMapper 的任意的更新操作都会将共用的 Cache 清空,会频繁地清空 Cache,导致 Cache 实际的命中率和使用率就变得很低了,所以这种策略实际情况下是不可取的。
最理想的解决方案就是:
对于某些表执行了更新(update、delete、insert)操作后,去清空跟这些指定的表有关联的查询语句所造成的缓存; 这样,就是以很细的粒度管理 MyBatis 内部的缓存,使得缓存的使用率和准确率都能大大地提升。
文章转载自:seven97_top

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论