
使用生成式 AI 和 Amazon Kendra 实现企业规模的图像字幕创建和搜索
Amazon Kendra 是一个由机器学习(ML)驱动的智能搜索服务。Amazon Kendra 重新构想了您的网站和应用程序的搜索功能,以便您的员工和客户可以轻松地找到散布在您组织内多个位置和内容存储库中的内容。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
Amazon Kendra 支持各种文档格式,例如 Microsoft Word、PDF 和来自各种数据源的文本。在本文中,我们重点介绍通过显示的内容使图像可搜索的 Amazon Kendra 文档支持的扩展。图像通常可以使用补充的元数据(例如关键词)来搜索。但是,为成千上万的图像添加详细元数据需要大量的手动工作。生成式 AI (GenAI) 可以帮助自动生成元数据。通过生成文字字幕,GenAI 字幕预测为图像提供了描述性的元数据。然后,在文档摄入过程中,可以使用生成的元数据来丰富 Amazon Kendra 索引,从而无需任何手动工作即可搜索图像。
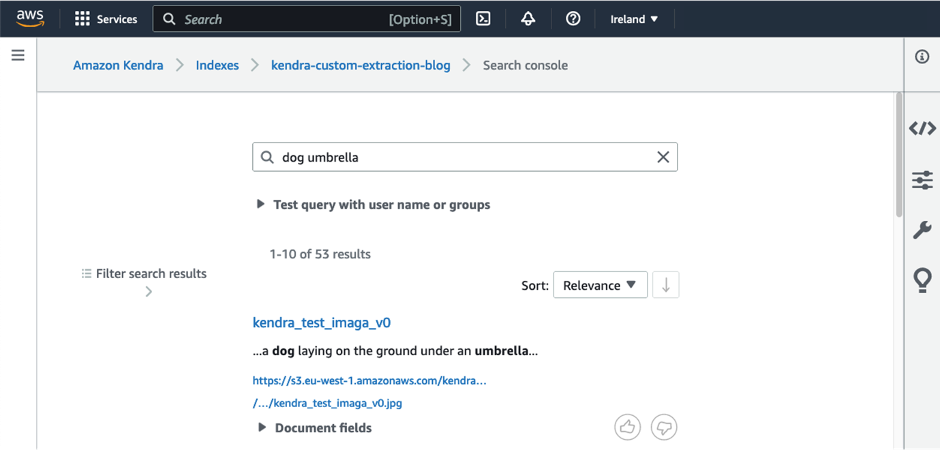
例如,在对图像进行文档摄入过程中,可以使用 GenAI 模型为以下图像生成“一只狗躺在伞下的地面上”的文本描述。

Amazon Kendra 是一个由机器学习(ML)驱动的智能搜索服务。Amazon Kendra 重新构想了您的网站和应用程序的搜索功能,以便您的员工和客户可以轻松地找到散布在您组织内多个位置和内容存储库中的内容。
Amazon Kendra 支持各种文档格式,例如 Microsoft Word、PDF 和来自各种数据源的文本。在本文中,我们重点介绍通过显示的内容使图像可搜索的 Amazon Kendra 文档支持的扩展。图像通常可以使用补充的元数据(例如关键词)来搜索。但是,为成千上万的图像添加详细元数据需要大量的手动工作。生成式 AI (GenAI) 可以帮助自动生成元数据。通过生成文字字幕,GenAI 字幕预测为图像提供了描述性的元数据。然后,在文档摄入过程中,可以使用生成的元数据来丰富 Amazon Kendra 索引,从而无需任何手动工作即可搜索图像。
例如,在对图像进行文档摄入过程中,可以使用 GenAI 模型为以下图像生成“一只狗躺在伞下的地面上”的文本描述。
在本文中,我们展示了如何在 Amazon Kendra 中使用 CDE 和在 Amazon SageMaker 上部署的 GenAI 模型。我们使用简单的示例演示 CDE,并提供分步指南,以便您可以在自己的亚马逊云科技账户中的 Amazon Kendra 索引中体验 CDE。它允许用户通过自然语言查询快速轻松地找到所需的图像,而无需手动标记或分类。该解决方案也可以根据不同应用程序和行业的需求进行定制和扩展。
使用 GenAI 进行图像字幕
使用 GenAI 对图像进行描述涉及使用 ML 算法生成图像的文本描述。该过程也称为图像字幕,它处于计算机视觉和自然语言处理(NLP)的交叉点。它在多模态数据的领域有应用,例如电子商务,其中数据包含文本形式的元数据以及图像,或者在医疗保健领域,数据可以包含 MRI 或 CT 扫描以及医生的笔记和诊断,只举几个用例。
GenAI 模型学习识别图像中的对象和特征,然后用自然语言生成对这些对象和特征的描述。最先进的模型使用编码器-解码器架构,其中图像信息被编码在神经网络的中间层,并解码为文本描述。这些可以被视为两个不同的阶段:从图像中提取特征和生成文本字幕。在特征提取阶段(编码器),GenAI 模型处理图像以提取相关的视觉特征,例如对象形状、颜色和纹理。在字幕生成阶段(解码器),模型基于提取的视觉特征生成图像的自然语言描述。
GenAI 模型通常在大量数据上进行训练,这使它们适合各种任务,而无需额外训练。通过少量学习也可以轻松地适应自定义数据集和新领域。预训练方法允许轻松地使用最先进的语言和图像模型来训练多模态应用程序。这些预训练方法还允许您根据数据选择最佳的视觉模型和语言模型作为图像字幕模型。
生成的图像描述的质量取决于训练数据的质量和数量、GenAI 模型的架构以及特征提取和字幕生成算法的质量。尽管使用 GenAI 进行图像描述是一个活跃的研究领域,但它在广泛的应用中显示出了非常好的结果,例如图像搜索、视觉叙事和视力障碍人士的辅助功能。
用例
GenAI 图像字幕在以下用例中非常有用:
电子商务 - 图像和文本同时出现的常见行业用例是零售业。特别是电子商务存储了大量的数据作为产品图像以及文本描述。文本描述或元数据对于根据搜索查询显示最佳产品非常重要。此外,随着电商网站从第三方供应商获得数据的趋势,产品描述通常不完整,需要大量的人工小时数和由于在元数据列中标记正确信息而产生的巨大开销。基于 GenAI 的图像字幕特别适合自动化这一繁琐的过程。在自定义时尚数据(如时尚图像以及描述时尚产品属性的文本)上微调模型可以生成元数据,从而改善用户的搜索体验。
营销 - 图像搜索的另一个用例是数字资产管理。营销公司存储大量需要集中化、易于搜索且可扩展的数字数据,这需要数据目录。一个中心化的数据湖具有信息丰富的数据目录,可以减少重复工作并使创意内容更广泛地共享,在团队之间保持一致性。对于广泛用于支持社交媒体内容生成的图形设计平台或企业环境中的演示文稿而言,更快的搜索可以通过呈现用户希望查找的图像来改善用户体验,并使用户能够使用自然语言查询进行搜索。
制造业 - 制造业存储大量图像数据,如组件、建筑物、硬件和设备的架构蓝图。能够搜索这些数据使产品团队能够轻松地从已经存在的起点重新创建设计,从而消除了大量设计开销,加速了设计生成过程。
医疗保健 - 医生和医学研究人员可以整理和搜索 MRI 和 CT 扫描、标本样本、疾病的图像(如皮疹和畸形)以及医生的笔记、诊断和临床试验细节。
元宇宙或增强现实 - 广告商品是关于创造一个用户可以想象和认同的故事。随着人工智能驱动的工具和分析,比以往任何时候都更容易构建不仅一个故事,而是定制的故事,以吸引每个用户独特的品味和敏感性。这是图像到文本模型可以成为游戏规则的地方。视觉叙事可以帮助创建角色、将其调整到不同的样式,并为其添加字幕。它也可以用来驱动元宇宙或增强现实以及沉浸式内容(包括视频游戏)中的刺激体验。图像搜索使开发人员、设计师和团队能够使用自然语言查询搜索他们的内容,从而在各种团队之间保持内容的一致性。
视力障碍者数字内容辅助功能 - 这主要是通过诸如屏幕阅读器、盲文系统(允许触觉阅读和书写)和特殊键盘(用于浏览网站和互联网上的应用程序)等辅助技术实现的。但是,图像需要以文本内容进行交付,然后以语音的形式进行交流。使用 GenAI 算法进行图像字幕是重新设计互联网、使其更具包容性的关键部分,为每个人提供访问、理解和交互在线内容的机会。
模型细节和用于自定义数据集的模型微调
在此解决方案中,我们利用了 vit-gpt2-image-captioning 模型,该模型可从 Hugging Face 获得,许可证为 Apache 2.0,无需进行进一步微调。Vit 是用于图像数据的基础模型,GPT-2 是用于语言的基础模型。两者的多模态组合提供了图像字幕的功能。Hugging Face 托管最先进的图像字幕模型,可以在几次点击中在亚马逊云科技中进行部署,并提供简单的部署推理端点。尽管我们可以直接使用预训练模型,但我们也可以自定义模型以适应特定领域的数据集、更多数据类型(如视频或空间数据)以及独特的用例。有几个 GenAI 模型,其中一些模型在某些数据集上表现较好,或者您的团队可能已经在使用视觉和语言模型。该解决方案提供了通过直接替换我们使用的模型来选择最佳执行视觉和语言模型作为图像字幕模型的灵活性。
对于定制到独特行业应用的模型,亚马逊云科技上的 Hugging Face 开源模型提供了几种可能性。可以对预训练模型进行测试以获得特定数据集,或对标记数据的样本进行训练以对其进行微调。新的研究方法还允许高效地组合任何视觉和语言模型,并在您的数据集上对其进行训练。然后,可以在 SageMaker 中部署这个新训练的模型进行本文介绍的图像字幕。
定制图像搜索的一个示例是企业资源计划(ERP)。在 ERP 中,从物流或供应链管理的不同阶段收集的图像数据可能包括税收收据、供应商订单、工资单等,需要自动分类以供组织内不同团队查阅。另一个示例是使用医疗扫描和医生诊断来预测新医学图像以进行自动分类。视觉模型从 MRI、CT 或 X 射线图像中提取特征,文本模型使用医疗诊断对其进行字幕。
解决方案概述
下图显示了具有 GenAI 和 Amazon Kendra 的图像搜索体系结构。
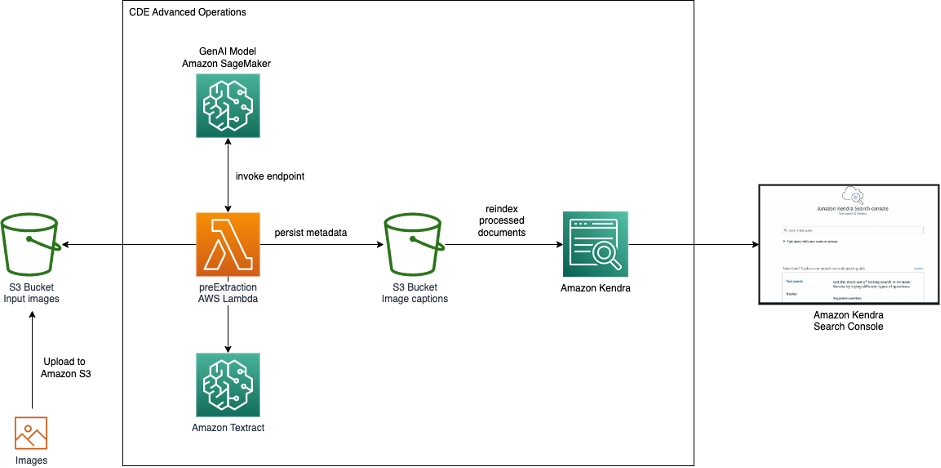
我们从 Amazon Simple Storage Service (Amazon S3) 中摄入图像到 Amazon Kendra。在摄入 Amazon Kendra 期间,调用托管在 SageMaker 上的 GenAI 模型以生成图像描述。此外,通过 Amazon Textract 提取图像中可见的文本。图像描述和提取的文本存储为元数据,可用于 Amazon Kendra 搜索索引。摄入后,可以通过 Amazon Kendra 搜索控制台、API 或 SDK 搜索图像。
我们使用 Amazon Kendra 中的 CDE 高级操作在图像摄入步骤期间调用 GenAI 模型和 Amazon Textract。但是,我们可以在更广泛的用例中使用 CDE。使用 CDE,您可以在将文档摄入 Amazon Kendra 时创建、修改或删除文档属性和内容。这意味着您可以根据需要操作和摄入数据。这可以通过在摄入期间调用摄入前后 Amazon Lambda 函数来实现,这允许进行数据丰富或修改。例如,在摄入医疗文本数据时,我们可以使用 Amazon Medical Comprehend 将 ML 生成的洞察力添加到搜索元数据中。
您可以通过以下步骤使用我们的解决方案通过 Amazon Kendra 搜索图像:
将图像上传到图像存储库,如 S3 存储桶。
然后,Amazon Kendra 会索引图像存储库,这是一个可用于搜索结构化和非结构化数据的搜索引擎。在索引过程中,将调用 GenAI 模型和 Amazon Textract 来生成图像元数据。您可以手动触发索引或按预定义的计划触发索引。
然后,您可以使用自然语言查询(例如“查找红玫瑰的图像”或“展示狗在公园里玩的图片”)通过 Amazon Kendra 控制台、SDK 或 API 搜索图像。这些查询由 Amazon Kendra 处理,Amazon Kendra 使用 ML 算法理解查询背后的含义,并从索引的存储库中检索相关图像。
搜索结果以及相应的文本描述将呈现给您,使您可以快速轻松地找到所需的图像。
前提条件
您必须具备以下先决条件:
一个亚马逊云科技账户
通过 Amazon CloudFormation 提供和调用以下服务的权限:Amazon S3、Amazon Kendra、Lambda 和 Amazon Textract。
成本估算
部署此解决方案作为概念验证的成本预计如下表所示。这就是我们使用 Amazon Kendra 开发者版的原因,不建议用于生产工作负载,但为开发人员提供了低成本选项。我们假设 Amazon Kendra 的搜索功能在 20 个工作日内每天用于 3 个小时,因此计算与 60 个月活跃小时相关的成本。
使用 Amazon CloudFormation 部署资源
CloudFormation 堆栈部署以下资源:
从 Hugging Face 中心下载图像字幕模型的 Lambda 函数,随后构建模型资产
将推理代码和压缩的模型工件填充到目标 S3 存储桶的 Lambda 函数
用于存储压缩模型工件和推理代码的 S3 存储桶
用于存储上传的图像和 Amazon Kendra 文档的 S3 存储桶
用于搜索生成的图像字幕的 Amazon Kendra 索引
SageMaker 实时推理端点,用于部署来自 Hugging Face 的图像字幕模型
在按需丰富 Amazon Kendra 索引时触发的 Lambda 函数。它调用 Amazon Textract 和 SageMaker 实时推理端点。
此外,Amazon CloudFormation 还部署了在自定义资源 Lambda 函数中运行所需的所有 Amazon Identity and Access Management(IAM) 角色和策略、VPC 以及子网、安全组和互联网网关。
请完成以下步骤以预配资源:
单击启动堆栈在
us-east-1区域启动 CloudFormation 模板:
单击下一步。
在指定堆栈详细信息页面上,将模板 URL 和参数文件 S3 URI 保留为默认值,然后单击下一步。
在后续页面上继续单击下一步。
单击创建堆栈以部署堆栈。
监控堆栈的状态。当状态显示为 CREATE_COMPLETE 时,部署完成。
摄入和搜索示例图像
请完成以下步骤以摄入和搜索图像:
在 Amazon S3 控制台上,在
us-east-1Region 的kendra-image-search-stack-imagecaptionsS3 bucket 中创建一个名为images的文件夹。上传以下图像到
images文件夹




导航到
us-east-1区域的 Amazon Kendra 控制台。在导航窗格中,选择索引,然后选择您的索引(
kendra-index)。选择数据源,然后选择
generated_image_captions。选择立即同步。
在继续下一步之前,请等待同步完成。
在导航窗格中,选择索引,然后选择
kendra-index。导航到搜索控制台。
尝试以下查询,可以单独使用也可以组合使用:“dog”、“umbrella”和“newsletter”,了解 Amazon Kendra 对哪些图像进行了高排名。
随意测试适合上传图像的自己的查询。
清理
要取消预配所有资源,请完成以下步骤:
在 Amazon CloudFormation 控制台上,选择导航窗格中的堆栈。
选择堆栈
kendra-genai-image-search并选择删除。
等待堆栈状态更改为 DELETE_COMPLETE。
结论
在本文中,我们看到了 Amazon Kendra 和 GenAI 如何结合来自动为图像创建有意义的元数据。最先进的 GenAI 模型非常适合根据图像内容生成文本字幕。这在医疗保健和生命科学、零售和电子商务、数字资产平台和媒体等行业都有广泛的用例。图像字幕对于建立更具包容性的数字世界和重新设计互联网、元宇宙和沉浸式技术以适应视力障碍人群的需求也至关重要。
通过字幕启用的图像搜索使这些应用程序的数字内容无需人工工作即可轻松搜索,并消除了重复工作。我们提供的 CloudFormation 模板使得部署此解决方案以通过 Amazon Kendra 启用图像搜索变得简单直观。将图像存储在 Amazon S3 中并使用 GenAI 创建图像的文本描述的简单体系结构可以与 Amazon Kendra 中的 CDE 一起使用以提供此解决方案。
这只是 GenAI 与 Amazon Kendra 的一个应用。要深入了解如何使用 GenAI 与 Amazon Kendra 构建应用程序,请参阅使用 Amazon Kendra、LangChain 和大型语言模型快速构建高精度的生成式 AI 企业数据应用程序。对于构建和扩展 GenAI 应用程序,我们建议查看 Amazon Bedrock。

还未添加个人签名 2019-09-17 加入
进入亚马逊云科技开发者网站,请锁定 https://dev.amazoncloud.cn 帮助开发者学习成长、交流,链接全球资源,助力开发者成功。









评论