
服务重启了,如何保证线程池中的数据不丢失?
1 什么是线程池?
之前没有线程池的时候,我们在代码中,创建一个线程有两种方式:
继承 Thread 类
实现 Runnable 接口
虽说通过这两种方式创建一个线程,非常方便。
但也带来了下面的问题:
1、创建和销毁一个线程,都是比较耗时,频繁的创建和销毁线程,非常影响系统的性能。
2、无限制的创建线程,会导致内存不足。
3、有新任务过来时,必须要先创建好线程才能执行,不能直接复用线程。
为了解决上面的这些问题,Java 中引入了:线程池。
它相当于一个存放线程的池子。
使用线程池带来了下面 3 个好处:
1、降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
2、提高响应速度。当任务到达时,可以直接使用已有空闲的线程,不需要的等到线程创建就能立即执行。
3、提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性。而如果我们使用线程池,可以对线程进行统一的分配、管理和监控。
2 线程池原理
先看看线程池的构造器:
corePoolSize:核心线程数,线程池维护的最少线程数。
maximumPoolSize:最大线程数,线程池允许创建的最大线程数。
keepAliveTime:线程存活时间,当线程数超过核心线程数时,多余的空闲线程的存活时间。
unit:时间单位。
workQueue:任务队列,用于保存等待执行的任务。
threadFactory:线程工厂,用于创建新线程。
handler:拒绝策略,当任务无法执行时的处理策略。
线程池的核心流程图如下:
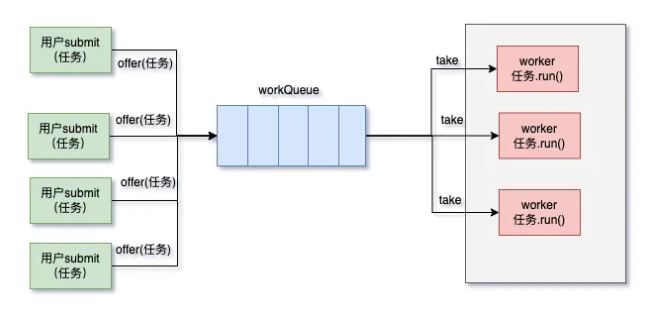
线程池的工作过程如下:
线程池初始化:根据 corePoolSize 初始化核心线程。
任务提交:当任务提交到线程池时,根据当前线程数判断:
若当前线程数小于 corePoolSize,创建新的线程执行任务。
若当前线程数大于或等于 corePoolSize,任务被加入 workQueue 队列。
任务处理:当有空闲线程时,从 workQueue 中取出任务执行。
线程扩展:若队列已满且当前线程数小于 maximumPoolSize,创建新的线程处理任务。
线程回收:当线程空闲时间超过 keepAliveTime,多余的线程会被回收,直到线程数不超过 corePoolSize。
拒绝策略:若队列已满且当前线程数达到 maximumPoolSize,则根据拒绝策略处理新任务。
说白了在线程池中,多余的任务会被放到 workQueue 任务队列中。
这个任务队列的数据保存在内存中。
这样就会出现一些问题。
接下来,看看线程池有哪些问题。
3 线程池有哪些问题?
在 JDK 中为了方便大家创建线程池,专门提供了 Executors 这个工具类。
3.1 队列过大
Executors.newFixedThreadPool,它可以创建固定线程数量的线程池,任务队列使用的是 LinkedBlockingQueue,默认最大容量是 Integer.MAX_VALUE。
如果向 newFixedThreadPool 线程池中提交的任务太多,可能会导致 LinkedBlockingQueue 非常大,从而出现 OOM 问题。
3.2 线程太多
Executors.newCachedThreadPool,它可以创建可缓冲的线程池,最大线程数量是 Integer.MAX_VALUE,任务队列使用的是 SynchronousQueue。
如果向 newCachedThreadPool 线程池中提交的任务太多,可能会导致创建大量的线程,也会出现 OOM 问题。
3.3 数据丢失
如果线程池在执行过程中,服务突然被重启了,可能会导致线程池中的数据丢失。
上面的 OOM 问题,我们在日常开发中,可以通过自定义线程池的方式解决。
比如创建这样的线程池:
自定义了一个最大线程数量和任务队列都在可控范围内线程池。
这样做基本上不会出现 OOM 问题。
但线程池的数据丢失问题,光靠自身的功能很难解决。
4 如何保证数据不丢失?
线程池中的数据,是保存到内存中的,一旦遇到服务器重启了,数据就会丢失。
之前的系统流程是这样的:
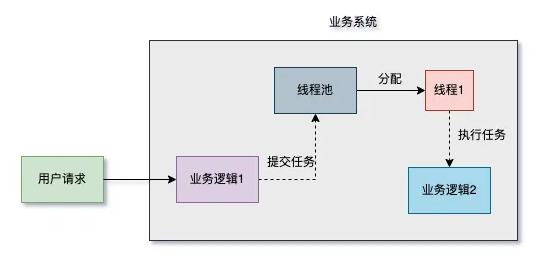
用户请求过来之后,先处理业务逻辑 1,它是系统的核心功能。
然后再将任务提交到线程池,由它处理业务逻辑 2,它是系统的非核心功能。
但如果线程池在处理的过程中,服务 down 机了,此时,业务逻辑 2 的数据就会丢失。
那么,如何保证数据不丢失呢?
答:需要提前做持久化。
我们优化的系统流程如下:
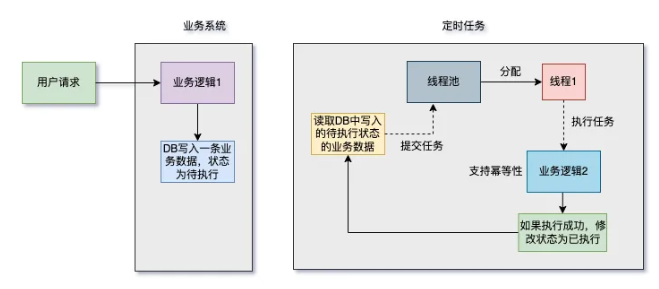
用户请求过来之后,先处理业务逻辑 1,紧接着向 DB 中写入一条任务数据,状态是:待执行。
处理业务逻辑 1 和向 DB 写任务数据,可以在同一个事务中,方便出现异常时回滚。
然后有一个专门的定时任务,每个一段时间,按添加时间升序,分页查询状态是待执行的任务。
最早的任务,最先被查出来。
然后将查出的任务提交到线程池中,由它处理业务逻辑 2。
处理成功之后,修改任务的待执行状态为:已执行。
需要注意的是:业务逻辑 2 的处理过程,要做幂等性设计,同一个请求允许被执行多次,其结果不会有影响。
如果此时,线程池在处理的过程中,服务 down 机了,业务逻辑 2 的数据会丢失。
但此时 DB 中保存了任务的数据,并且丢失那些任务的状态还是:待执行。
在下一次定时任务周期开始执行时,又会将那些任务数据重新查询出来,重新提交到线程池中。
业务逻辑 2 丢失的数据,又自动回来了。
如果要考虑失败的情况,还需要在任务表中增加一个失败次数字段。
在定时任务的线程池中执行业务逻辑 2 失败了,在下定时任务执行时可以自动重试。
但不可能无限制的一直重试下去。
当失败超过了一定的次数,可以将任务状态改成:失败。
这样后续可以人工处理。
文章转载自:苏三说技术

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论