
使用 sql 查询 excel 内容
- 2025-01-22 福建
本文字数:10477 字
阅读完需:约 34 分钟
1. 简介
我们在前面的文章中提到了 calcite 支持 csv 和 json 文件的数据源适配, 其实就是将文件解析成表然后以文件夹为 schema, 然后将生成的 schema 注册到RootSehema(RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下)下, 最终使用 calcite 的特性进行 sql 的解析查询返回.
但其实我们的数据文件一般使用 excel 进行存储,流转, 但很可惜, calcite 本身没有 excel 的适配器, 但其实我们可以模仿calcite-file, 自己搞一个calcite-file-excel, 也可以熟悉 calcite 的工作原理.
2. 实现思路
因为 excel 有 sheet 的概念, 所以可以将一个 excel 解析成 schema, 每个 sheet 解析成 table, 实现步骤如下:
实现
SchemaFactory重写 create 方法: schema 工厂 用于创建 schema继承
AbstractSchema: schema 描述类 用于解析 excel, 创建 table(解析 sheet)继承
AbstractTable, ScannableTable: table 描述类 提供字段信息和数据内容等(解析 sheet data)
3. Excel 样例
excel 有两个 sheet 页, 分别是user_info 和 role_info如下:


ok, 万事具备.
4. Maven
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>5.2.3</version></dependency>
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>5.2.3</version></dependency>
<dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-core</artifactId> <version>1.37.0</version></dependency>5. 核心代码
5.1 SchemaFactory
package com.ldx.calcite.excel;
import com.google.common.collect.Lists;import org.apache.calcite.schema.Schema;import org.apache.calcite.schema.SchemaFactory;import org.apache.calcite.schema.SchemaPlus;import org.apache.commons.lang3.ObjectUtils;import org.apache.commons.lang3.StringUtils;
import java.io.File;import java.util.List;import java.util.Map;
/** * schema factory */public class ExcelSchemaFactory implements SchemaFactory { public final static ExcelSchemaFactory INSTANCE = new ExcelSchemaFactory();
private ExcelSchemaFactory(){}
@Override public Schema create(SchemaPlus parentSchema, String name, Map<String, Object> operand) { final Object filePath = operand.get("filePath");
if (ObjectUtils.isEmpty(filePath)) { throw new NullPointerException("can not find excel file"); }
return this.create(filePath.toString()); }
public Schema create(String excelFilePath) { if (StringUtils.isBlank(excelFilePath)) { throw new NullPointerException("can not find excel file"); }
return this.create(new File(excelFilePath)); }
public Schema create(File excelFile) { if (ObjectUtils.isEmpty(excelFile) || !excelFile.exists()) { throw new NullPointerException("can not find excel file"); }
if (!excelFile.isFile() || !isExcelFile(excelFile)) { throw new RuntimeException("can not find excel file: " + excelFile.getAbsolutePath()); }
return new ExcelSchema(excelFile); }
protected List<String> supportedFileSuffix() { return Lists.newArrayList("xls", "xlsx"); }
private boolean isExcelFile(File excelFile) { if (ObjectUtils.isEmpty(excelFile)) { return false; }
final String name = excelFile.getName(); return StringUtils.endsWithAny(name, this.supportedFileSuffix().toArray(new String[0])); }}schema 中有多个重载的 create 方法用于方便的创建 schema, 最终将 excel file 交给ExcelSchema创建一个 schema 对象
5.2 Schema
package com.ldx.calcite.excel;
import org.apache.calcite.schema.Table;import org.apache.calcite.schema.impl.AbstractSchema;import org.apache.commons.lang3.ObjectUtils;import org.apache.poi.ss.usermodel.Sheet;import org.apache.poi.ss.usermodel.Workbook;import org.apache.poi.ss.usermodel.WorkbookFactory;import org.testng.collections.Maps;
import java.io.File;import java.util.Iterator;import java.util.Map;
/** * schema */public class ExcelSchema extends AbstractSchema { private final File excelFile;
private Map<String, Table> tableMap;
public ExcelSchema(File excelFile) { this.excelFile = excelFile; }
@Override protected Map<String, Table> getTableMap() { if (ObjectUtils.isEmpty(tableMap)) { tableMap = createTableMap(); }
return tableMap; }
private Map<String, Table> createTableMap() { final Map<String, Table> result = Maps.newHashMap();
try (Workbook workbook = WorkbookFactory.create(excelFile)) { final Iterator<Sheet> sheetIterator = workbook.sheetIterator();
while (sheetIterator.hasNext()) { final Sheet sheet = sheetIterator.next(); final ExcelScannableTable excelScannableTable = new ExcelScannableTable(sheet, null); result.put(sheet.getSheetName(), excelScannableTable); } } catch (Exception ignored) {}
return result; }}schema 类读取 Excel file, 并循环读取 sheet, 将每个 sheet 解析成ExcelScannableTable并存储
5.3 Table
package com.ldx.calcite.excel;
import com.google.common.collect.Lists;import com.ldx.calcite.excel.enums.JavaFileTypeEnum;import org.apache.calcite.DataContext;import org.apache.calcite.adapter.java.JavaTypeFactory;import org.apache.calcite.linq4j.Enumerable;import org.apache.calcite.linq4j.Linq4j;import org.apache.calcite.rel.type.RelDataType;import org.apache.calcite.rel.type.RelDataTypeFactory;import org.apache.calcite.rel.type.RelProtoDataType;import org.apache.calcite.schema.ScannableTable;import org.apache.calcite.schema.impl.AbstractTable;import org.apache.calcite.sql.type.SqlTypeName;import org.apache.calcite.util.Pair;import org.apache.commons.lang3.ObjectUtils;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import org.checkerframework.checker.nullness.qual.Nullable;
import java.util.List;
/** * table */public class ExcelScannableTable extends AbstractTable implements ScannableTable { private final RelProtoDataType protoRowType;
private final Sheet sheet;
private RelDataType rowType;
private List<JavaFileTypeEnum> fieldTypes;
private List<Object[]> rowDataList;
public ExcelScannableTable(Sheet sheet, RelProtoDataType protoRowType) { this.protoRowType = protoRowType; this.sheet = sheet; }
@Override public Enumerable<@Nullable Object[]> scan(DataContext root) { JavaTypeFactory typeFactory = root.getTypeFactory(); final List<JavaFileTypeEnum> fieldTypes = this.getFieldTypes(typeFactory);
if (rowDataList == null) { rowDataList = readExcelData(sheet, fieldTypes); }
return Linq4j.asEnumerable(rowDataList); }
@Override public RelDataType getRowType(RelDataTypeFactory typeFactory) { if (ObjectUtils.isNotEmpty(protoRowType)) { return protoRowType.apply(typeFactory); }
if (ObjectUtils.isEmpty(rowType)) { rowType = deduceRowType((JavaTypeFactory) typeFactory, sheet, null); }
return rowType; }
public List<JavaFileTypeEnum> getFieldTypes(RelDataTypeFactory typeFactory) { if (fieldTypes == null) { fieldTypes = Lists.newArrayList(); deduceRowType((JavaTypeFactory) typeFactory, sheet, fieldTypes); } return fieldTypes; }
private List<Object[]> readExcelData(Sheet sheet, List<JavaFileTypeEnum> fieldTypes) { List<Object[]> rowDataList = Lists.newArrayList();
for (int rowIndex = 1; rowIndex <= sheet.getLastRowNum(); rowIndex++) { Row row = sheet.getRow(rowIndex); Object[] rowData = new Object[fieldTypes.size()];
for (int i = 0; i < row.getLastCellNum(); i++) { final JavaFileTypeEnum javaFileTypeEnum = fieldTypes.get(i); Cell cell = row.getCell(i, Row.MissingCellPolicy.CREATE_NULL_AS_BLANK); final Object cellValue = javaFileTypeEnum.getCellValue(cell); rowData[i] = cellValue; }
rowDataList.add(rowData); }
return rowDataList; }
public static RelDataType deduceRowType(JavaTypeFactory typeFactory, Sheet sheet, List<JavaFileTypeEnum> fieldTypes) { final List<String> names = Lists.newArrayList(); final List<RelDataType> types = Lists.newArrayList();
if (sheet != null) { Row headerRow = sheet.getRow(0);
if (headerRow != null) { for (int i = 0; i < headerRow.getLastCellNum(); i++) { Cell cell = headerRow.getCell(i, Row.MissingCellPolicy.CREATE_NULL_AS_BLANK); String[] columnInfo = cell .getStringCellValue() .split(":"); String columnName = columnInfo[0].trim(); String columnType = null;
if (columnInfo.length == 2) { columnType = columnInfo[1].trim(); }
final JavaFileTypeEnum javaFileType = JavaFileTypeEnum .of(columnType) .orElse(JavaFileTypeEnum.UNKNOWN); final RelDataType sqlType = typeFactory.createSqlType(javaFileType.getSqlTypeName()); names.add(columnName); types.add(sqlType);
if (fieldTypes != null) { fieldTypes.add(javaFileType); } } } }
if (names.isEmpty()) { names.add("line"); types.add(typeFactory.createSqlType(SqlTypeName.VARCHAR)); }
return typeFactory.createStructType(Pair.zip(names, types)); }}
table 类中其中有两个比较关键的方法
scan: 扫描表内容, 我们这里将 sheet 页面的数据内容解析存储最后交给 calcite
getRowType: 获取字段信息, 我们这里默认使用第一条记录作为表头(row[0]) 并解析为字段信息, 字段规则跟 csv 一样 name:string, 冒号前面的是字段 key, 冒号后面的是字段类型, 如果未指定字段类型, 则解析为UNKNOWN, 后续JavaFileTypeEnum会进行类型推断, 最终在结果处理时 calcite 也会进行推断
deduceRowType: 推断字段类型, 方法中使用JavaFileTypeEnum枚举类对 java type & sql type & 字段值转化处理方法 进行管理
5.4 ColumnTypeEnum
package com.ldx.calcite.excel.enums;
import lombok.Getter;import lombok.extern.slf4j.Slf4j;import org.apache.calcite.avatica.util.DateTimeUtils;import org.apache.calcite.sql.type.SqlTypeName;import org.apache.commons.lang3.ObjectUtils;import org.apache.commons.lang3.StringUtils;import org.apache.commons.lang3.time.FastDateFormat;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.DateUtil;import org.apache.poi.ss.util.CellUtil;
import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Arrays;import java.util.Date;import java.util.Optional;import java.util.TimeZone;import java.util.function.Function;
/** * type converter */@Slf4j@Getterpublic enum JavaFileTypeEnum { STRING("string", SqlTypeName.VARCHAR, Cell::getStringCellValue), BOOLEAN("boolean", SqlTypeName.BOOLEAN, Cell::getBooleanCellValue), BYTE("byte", SqlTypeName.TINYINT, Cell::getStringCellValue), CHAR("char", SqlTypeName.CHAR, Cell::getStringCellValue), SHORT("short", SqlTypeName.SMALLINT, Cell::getNumericCellValue), INT("int", SqlTypeName.INTEGER, cell -> (Double.valueOf(cell.getNumericCellValue()).intValue())), LONG("long", SqlTypeName.BIGINT, cell -> (Double.valueOf(cell.getNumericCellValue()).longValue())), FLOAT("float", SqlTypeName.REAL, Cell::getNumericCellValue), DOUBLE("double", SqlTypeName.DOUBLE, Cell::getNumericCellValue), DATE("date", SqlTypeName.DATE, getValueWithDate()), TIMESTAMP("timestamp", SqlTypeName.TIMESTAMP, getValueWithTimestamp()), TIME("time", SqlTypeName.TIME, getValueWithTime()), UNKNOWN("unknown", SqlTypeName.UNKNOWN, getValueWithUnknown()),; // cell type private final String typeName; // sql type private final SqlTypeName sqlTypeName; // value convert func private final Function<Cell, Object> cellValueFunc;
private static final FastDateFormat TIME_FORMAT_DATE;
private static final FastDateFormat TIME_FORMAT_TIME;
private static final FastDateFormat TIME_FORMAT_TIMESTAMP;
static { final TimeZone gmt = TimeZone.getTimeZone("GMT"); TIME_FORMAT_DATE = FastDateFormat.getInstance("yyyy-MM-dd", gmt); TIME_FORMAT_TIME = FastDateFormat.getInstance("HH:mm:ss", gmt); TIME_FORMAT_TIMESTAMP = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss", gmt); }
JavaFileTypeEnum(String typeName, SqlTypeName sqlTypeName, Function<Cell, Object> cellValueFunc) { this.typeName = typeName; this.sqlTypeName = sqlTypeName; this.cellValueFunc = cellValueFunc; }
public static Optional<JavaFileTypeEnum> of(String typeName) { return Arrays .stream(values()) .filter(type -> StringUtils.equalsIgnoreCase(typeName, type.getTypeName())) .findFirst(); }
public static SqlTypeName findSqlTypeName(String typeName) { final Optional<JavaFileTypeEnum> javaFileTypeOptional = of(typeName);
if (javaFileTypeOptional.isPresent()) { return javaFileTypeOptional .get() .getSqlTypeName(); }
return SqlTypeName.UNKNOWN; }
public Object getCellValue(Cell cell) { return cellValueFunc.apply(cell); }
public static Function<Cell, Object> getValueWithUnknown() { return cell -> { if (ObjectUtils.isEmpty(cell)) { return null; }
switch (cell.getCellType()) { case STRING: return cell.getStringCellValue(); case NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { // 如果是日期类型,返回日期对象 return cell.getDateCellValue(); } else { // 否则返回数值 return cell.getNumericCellValue(); } case BOOLEAN: return cell.getBooleanCellValue(); case FORMULA: // 对于公式单元格,先计算公式结果,再获取其值 try { return cell.getNumericCellValue(); } catch (Exception e) { try { return cell.getStringCellValue(); } catch (Exception ex) { log.error("parse unknown data error, cellRowIndex:{}, cellColumnIndex:{}", cell.getRowIndex(), cell.getColumnIndex(), e); return null; } } case BLANK: return ""; default: return null; } }; }
public static Function<Cell, Object> getValueWithDate() { return cell -> { Date date = cell.getDateCellValue();
if(ObjectUtils.isEmpty(date)) { return null; }
try { final String formated = new SimpleDateFormat("yyyy-MM-dd").format(date); Date newDate = TIME_FORMAT_DATE.parse(formated); return (int) (newDate.getTime() / DateTimeUtils.MILLIS_PER_DAY); } catch (ParseException e) { log.error("parse date error, date:{}", date, e); }
return null; }; }
public static Function<Cell, Object> getValueWithTimestamp() { return cell -> { Date date = cell.getDateCellValue();
if(ObjectUtils.isEmpty(date)) { return null; }
try { final String formated = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date); Date newDate = TIME_FORMAT_TIMESTAMP.parse(formated); return (int) newDate.getTime(); } catch (ParseException e) { log.error("parse timestamp error, date:{}", date, e); }
return null; }; }
public static Function<Cell, Object> getValueWithTime() { return cell -> { Date date = cell.getDateCellValue();
if(ObjectUtils.isEmpty(date)) { return null; }
try { final String formated = new SimpleDateFormat("HH:mm:ss").format(date); Date newDate = TIME_FORMAT_TIME.parse(formated); return newDate.getTime(); } catch (ParseException e) { log.error("parse time error, date:{}", date, e); }
return null; }; }}该枚举类主要管理了java type& sql type & cell value convert func, 方便统一管理类型映射及单元格内容提取时的转换方法(这里借用了 java8 function 函数特性)
注: 这里的日期转换只能这样写, 即使用 GMT 的时区(抄的
calcite-file), 要不然输出的日期时间一直有时差...
6. 测试查询
package com.ldx.calcite;
import com.ldx.calcite.excel.ExcelSchemaFactory;import lombok.SneakyThrows;import lombok.extern.slf4j.Slf4j;import org.apache.calcite.config.CalciteConnectionProperty;import org.apache.calcite.jdbc.CalciteConnection;import org.apache.calcite.schema.Schema;import org.apache.calcite.schema.SchemaPlus;import org.apache.calcite.util.Sources;import org.junit.jupiter.api.AfterAll;import org.junit.jupiter.api.BeforeAll;import org.junit.jupiter.api.Test;import org.testng.collections.Maps;
import java.net.URL;import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.ResultSetMetaData;import java.sql.SQLException;import java.sql.Statement;import java.util.Map;import java.util.Properties;
@Slf4jpublic class CalciteExcelTest { private static Connection connection;
private static SchemaPlus rootSchema;
private static CalciteConnection calciteConnection;
@BeforeAll @SneakyThrows public static void beforeAll() { Properties info = new Properties(); // 不区分sql大小写 info.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(), "false");
// 创建Calcite连接 connection = DriverManager.getConnection("jdbc:calcite:", info); calciteConnection = connection.unwrap(CalciteConnection.class); // 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下 rootSchema = calciteConnection.getRootSchema(); }
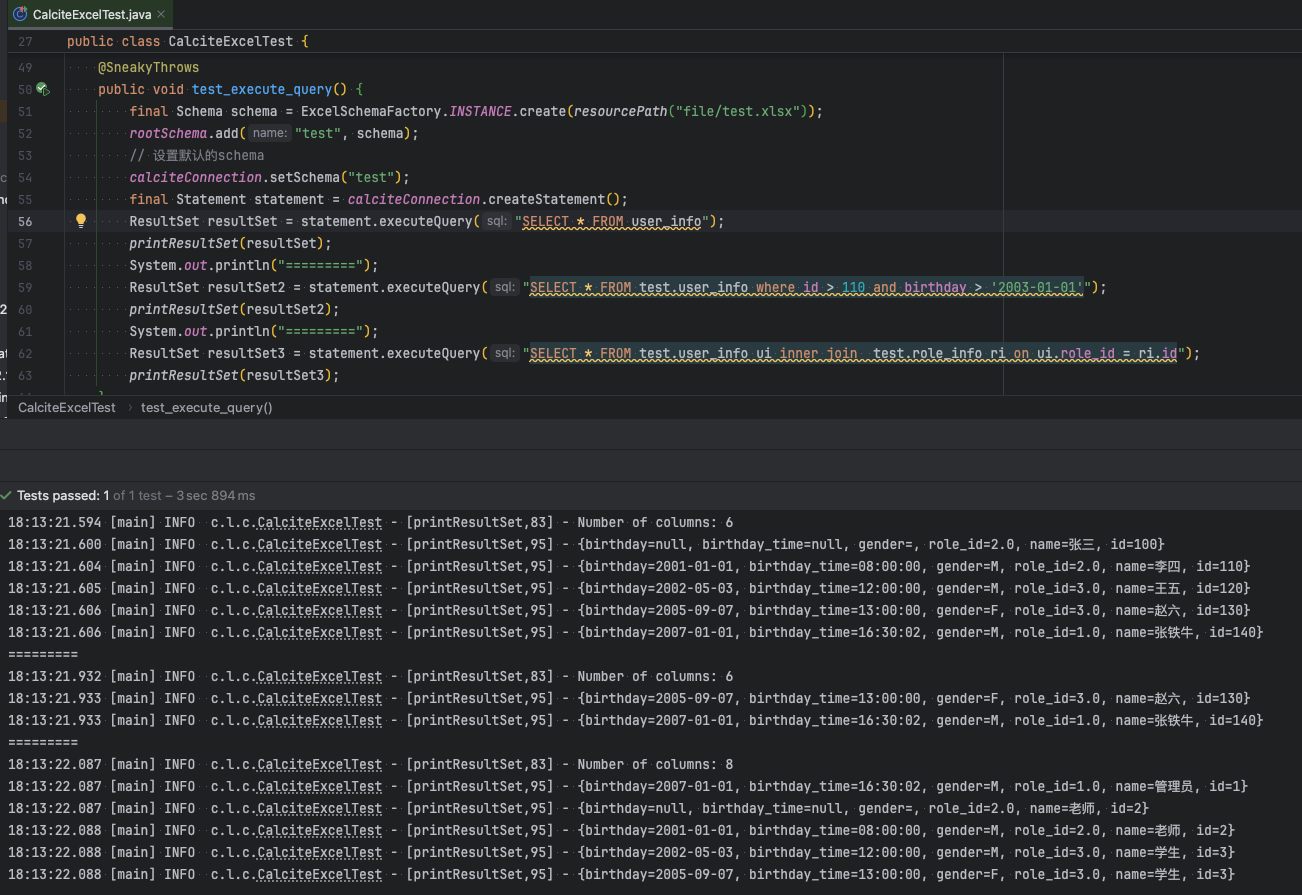
@Test @SneakyThrows public void test_execute_query() { final Schema schema = ExcelSchemaFactory.INSTANCE.create(resourcePath("file/test.xlsx")); rootSchema.add("test", schema); // 设置默认的schema calciteConnection.setSchema("test"); final Statement statement = calciteConnection.createStatement(); ResultSet resultSet = statement.executeQuery("SELECT * FROM user_info"); printResultSet(resultSet); System.out.println("========="); ResultSet resultSet2 = statement.executeQuery("SELECT * FROM test.user_info where id > 110 and birthday > '2003-01-01'"); printResultSet(resultSet2); System.out.println("========="); ResultSet resultSet3 = statement.executeQuery("SELECT * FROM test.user_info ui inner join test.role_info ri on ui.role_id = ri.id"); printResultSet(resultSet3); }
@AfterAll @SneakyThrows public static void closeResource() { connection.close(); }
private static String resourcePath(String path) { final URL url = CalciteExcelTest.class.getResource("/" + path); return Sources.of(url).file().getAbsolutePath(); }
public static void printResultSet(ResultSet resultSet) throws SQLException { // 获取 ResultSet 元数据 ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列数 int columnCount = metaData.getColumnCount(); log.info("Number of columns: {}",columnCount);
// 遍历 ResultSet 并打印结果 while (resultSet.next()) { final Map<String, String> item = Maps.newHashMap(); // 遍历每一列并打印 for (int i = 1; i <= columnCount; i++) { String columnName = metaData.getColumnName(i); String columnValue = resultSet.getString(i); item.put(columnName, columnValue); }
log.info(item.toString()); } }}测试结果如下:
文章转载自:张铁牛

EquatorCoco
还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论