
查询性能提升 10 倍!喜马拉雅广告倒排索引设计实践

—— Lucene 设计原理分析与广告业务场景下的全内存倒排索引自研实践
背景
目前,喜马拉雅广告引擎系统在广告物料召回阶段需要从候选物料集中召回大量广告物料进行后续的业务处理。在业务发展初期,我们使用了 ElasticSearch 作为广告物料召回的数据检索服务。ElasitcSearch 是一个分布式全文检索服务,使用 Lucene 作为其核心存储引擎,提供了简单易用的 RESTful API。随着业务的发展,广告物料越来越多,Lucene 的查询操作出现了较大的性能瓶颈。Lucene 为了支撑海量数据的检索、打分和排序等功能, 主要使用磁盘存储大量的数据,在查询阶段会产生大量磁盘 IO 操作,影响了查询性能。喜马拉雅的广告引擎主要是对广告物料 ID 进行召回,通过使用特定的数据结构,物料数据可以完全存储在内存中。因此,我们决定自行设计一套高性能、适配我们业务场景的内存检索系统来支撑业务未来的发展。
Lucene 设计分析
要开发这样一套更适合我们业务场景的内存检索系统,首先还是需要对 Lucene 的设计进行调研分析。ElasticSearch 主要由 Lucene 提供数据的存储与检索服务。Lucene 将数据存储在磁盘上,查询操作时通过将查询表达式解析成待查询的 Term, 再对 Term 构建文档 ID 的倒排链,使用内存与磁盘协作完成数据的召回。因此,设计一个检索系统主要解决以下问题:
数据存储:采用合适的数据结构存储 term 字典与对应文档的数据;
查询模型:设计一套检索模型支持灵活的数据查询。
Lucene 对海量数据检索能力的支持主要使用了倒排索引结构(Inverted Index)。倒排索引是实现单词-文档矩阵的一种存储形式。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两部分组成:单词词典(Lexicon)和倒排文件(Inverted File)。单词词典是由文档集中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息及指向倒排列表的指针。如图 1 所示:
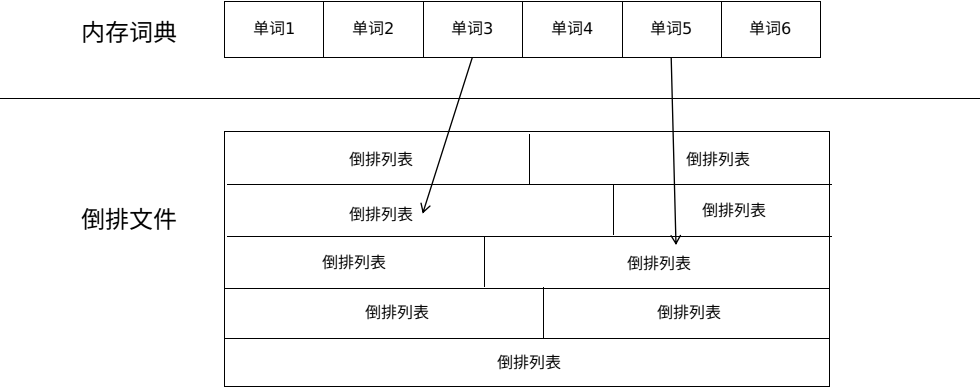
图 1
首先,Lucene 会通过分词器(Analyzer)对文档集(Docuement Collection)进行解析,分词器会将文档字段(Field)的值解析为单词词典。在 Lucene 中,这些词称为 Term。然后, Lucene 通过对每个 Term 在所有文档中出现的文档构建相应的集合,即倒排列表(Posting List)。倒排列表记录出现过某个单词的所有文档及单词在文档中出现的位置等信息。每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。Lucene 使用 FreqProxPostingsArray 类记录每个文档字段的所有 term 的相关文档信息。
Lucene 倒排索引数据是按字段(Field)进行解析与存储的。Lucene 通过扩展列表(Extent List)方式进行多字段索引的支持。扩展列表方式会为每个字段建立一个列表,这个列表记载每个文档的这个字段对应的位置信息。Lucene 中字段对象是所有文档共用的。为了支持短语查询(PhraseQuery), Lucene 需要记录单词的位置索引信息,这也导致了需要存储的数据量剧烈增长。在索引构建过程中,会先在内存中维护每个字段的倒排索引数据。字段对象使用数组进行管理,通过 Hash 算法确定字段对象在数组中的位置,与 HashMap 类似,单链表解决 Hash 冲突。
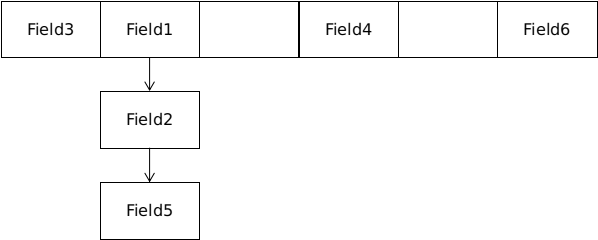
图 2
在执行文档添加操作时,首先会生成文档的字段对象,通过分词器对每个文档的字段值进行分词,得到分词后的单词 Term 集合及相关的位置、频率、偏移等信息。Lucene 会给每个单词 Term 生成一个 termId 号,使用 BytesRefHash 数据结构进行存储。BytesRefHash 相当于一个 HashMap,Key 为 termId,Value 为 term。实际的 term 值存储在一个可扩容的字节数组(ByteBlockPool)中,并使用 FreqProxPostingsArray 对象管理 term 在字节数组中的位置等信息。FreqProxPostingsArray 相当于内存中的倒排结构,它通过多个数组维护 termId 在这个字节数组中的偏移等信息。FreqProxPostingsArray 的结构如下图所示:

图 3
Lucene 通过引入 slice 将文档 Id 写入到字节数组(ByteBlockPool),slice 是操作字节数组的工具,如下图所示。 Lucene 的倒排链实际存储的是文档编号的差值(D-Gap)。在索引的构建过程中,通过为每个文档分配一个自增 ID, 保证后面出现的文档编号大于之前出现的文档编号。使用差值可以更好的对数据进行压缩存储。通过 termId 可以定位到相关文档 Id 的列表。

图 4
Lucene 在文档解析后内存中整体的倒排数据结构如下图所示:
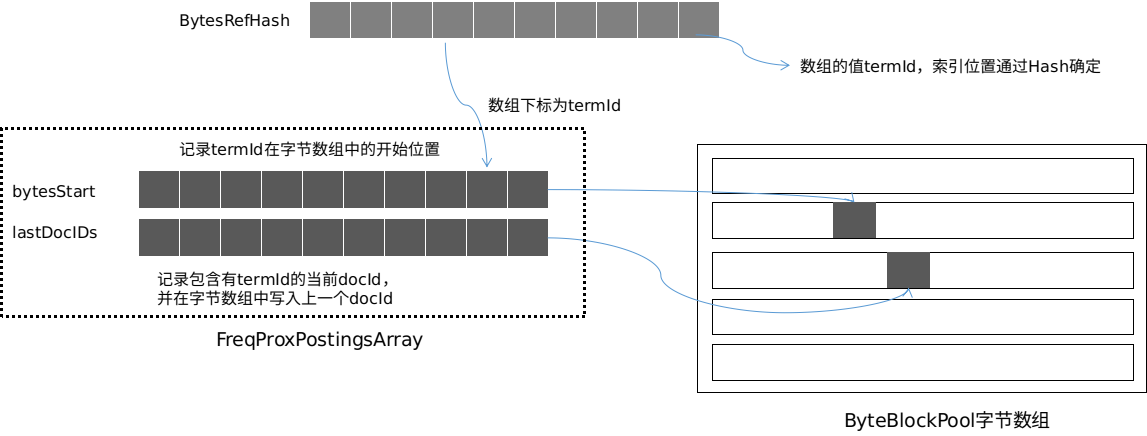
图 5
整体流程即为,Lucene 会为字段分词后的每个 term 生成唯一自增的 termId 值,并通过计算 term 的 Hash 值确定其在 BytesRefHash 中的位置。接着将 term 写入字节数组,并在 FreqProxPostingsArray 中记录字节数组的位置、长度等信息。BytesRefHash 通过引用 FreqProxPostingsArray 中的 byteStart 数组可以定位到 term 在字节数组中的位置,由此建立起 termId 到 term 值的映射关系。每处理一个文档,FreqProxPostingsArray 都会将 termId 的当前 docId 与上一个 docId 的差值通过 slice 写入字节数组并在 lastDocIDs 中记录下当前的 docID。随着文档的不断添加,建立起了 term 与 docID 的倒排链。 BytesRefHash 不仅实现了能通过 term 找到 termId 值,也能通过 termId 返回 term,它的功能等同于双向的 HashMap。
分词后的字段值可能会生成海量的 term, Lucene 内存中的倒排索引数据最终使用跳表的形式存储在磁盘上。在写入过程中,Lucene 为每个 Term 创建一个跳表的数据结构,从 FreqProxPostingsArray 中读出 term 的倒排数据,构建跳表并序列化到磁盘上。FreqProxPostingsArray 本质上是为了将内存的倒排数据写入磁盘服务的。为了保证查询时的读取性能,Lucene 在序列化写入磁盘时会对 term 进行排序并使用另一种结构进行存储。
Lucene 在索引查询时先将查询语句解析为 term, 然后根据 term 定位到文件中的倒排列表数据。为了节省存储空间并加快后续查询,Lucene 需要有一种能快速定位 term 及 term 对应的倒排列表在磁盘文件位置的数据结构。在查询时需要尽可能将 term 加载到内存中,降低随机 IO 导致的性能下降。这种通过 term 定位磁盘中倒排列表位置、同时需要支持 term 有序的数据结构,很容易想到使用 TreeMap,即 Map 的 Key 即为 Term,Map 的值为文档 Id 列表在磁盘文件中的位置。很多 Term 都有相同的前缀和后缀,使用 Map 会占用很多内存,也无法支持前缀查询、拼写检查等更丰富的功能,因此 Lucene 设计了 FST (Finite State Transducer) 的数据结构。
FST 是 Lucene 实现的用于代替 TreeMap 的数据结构,它是一种共享前缀与后缀的有向无环图,能判断某个 Term 是否存在,还能对查询的 Term 返回一个 output。它在时间复杂度和空间复杂度上都做了最大程度的优化,使得 Lucene 能够将 Term 字典完全加载到内存,并通过快速定位 Term 找到对应的 output(倒排列表在文件中的位置)。FST 结构如下图所示(在线演示:http://examples.mikemccandless.com/fst.py):

图 6
上图是 FST 树的简单示意图,节点的编号表达节点持久化后存储的位置。节点 1 为起始节点,节点 7 为终止节点。 有 ximly 和 xmlay 两个 term 存储其中,它们共享前缀 x 和后缀 y。节点和边都可以带输出值, 通过 ximly 路径(1 -> 2 -> 3 -> 4 -> 5 -> 7)的输出值为 4,xmlay 路径(1 -> 2 -> 6 -> 7 -> 5 -> 7)的输出值为 10。FST 不仅节省存储空间,还能支持同义词过滤、拼写检查、自动联想等功能。
每个文档字段域都至少有一个 FST 的数据结构来管理此字段下的所有 Term 。有些域下 Term 数量很大,一个 FST 无法存储,通常会使用多个有序的 FST, 并构建多层的 FST 树。为了平衡查询性能与空间使用,Lucene 将多层 FST 树压缩成只有一层 Block 的结构,通过 FST 快速定位到 Term 所在的 Block,然后在 Block 中通过遍历的方式查找到指定的 Term,最后定位到倒排索引在磁盘文件中的位置。通过读取相应 Term 的倒排索引,并根据查询条件对多个 Term 的倒排数据进行布尔操作,返回相应的查询结果。
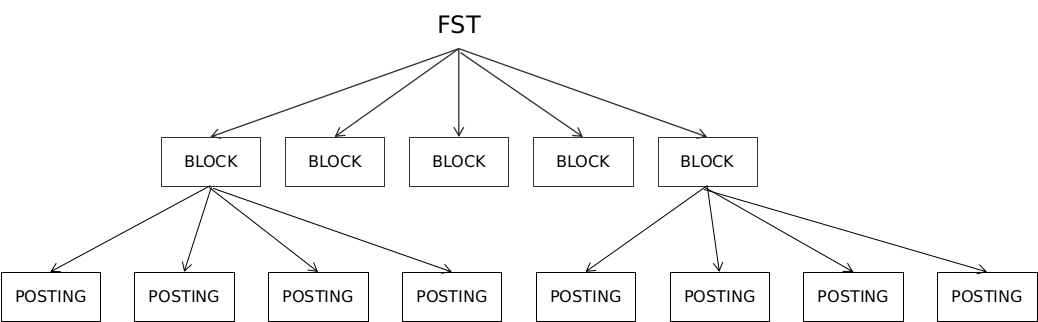
图 7
如前所述,文档分词后有大量的 Term 词典需要存储。Lucene 为了支撑海量数据的查询,在索引构建阶段使用了内存与磁盘相结合的方式。当数据量很大时,会存在大量磁盘的 IO 操作,影响查询时服务的性能。
倒排索引服务设计
索引数据的存储
设计一个高性能的索引服务,首先需要对存储部分使用的数据结构进行方案选择。对于我们的广告检索服务来说,广告物料集合的数量在百万级,可以使用内存进行存储。文档集合包含的单词数量也是有限的,能否快速定位某个单词,直接影响搜索时的响应速度,因此需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希表和 B 树等。倒排列表部分,我们需要存储的是文档编号的正整数列表,因此,使用位图来构建倒排数据则是一个常用的解决方案,它是一个性能好且节省内存的数据结构。
倒排列表的存储
倒排列表部分选择使用位图进行存储。位图是按位进行数据处理的。对于一个 32 位的整型数据,其中每一位用来标记一个整型是否存在。原来需要 32 位表示一个数据,现在则只需要 1 位表示一个数据,存储 40 亿个整型数据只需要约 500MB 内存空间。
下面以 Lucene 中使用的位图进行介绍。Lucene 中实现了 FixedBitSet 和 SparseFixedBitSet 两个位图数据结构。主要用于查询缓存场景。 FixedBitSet 使用 long 中的每一位来表示位图的每一个位置,整个位图是由多个 long 组成的,内部实现为一个 long 数组,如果数据稀疏,某些 long 未使用,会造成空间浪费。 SparseFixedBitSet 主要解决稀疏场景中 FixedBitSet 空间利用率低的问题。在 SparseFixedBitSet 中通过引入 block,将 long 数组按 block 分组,一个 block 最多管理 64 个 long,block 中的 long 是按需分配的,从而避免了无用 long 空间的浪费。Lucene 中对于选择使用 FixedBitSet 还是 SparseFixedBitSet,判断条件如下:
SparseFixedBitSet 只解决了 FixedBitSet 中对完全没有使用的 long 的空间浪费,但是如果每个 long 只有很少的有效位,则存在巨大的空间浪费。Lucene 通过参考 RoaringBitmap 实现了 RoaringDocIdSet,它能更进一步提高位图空间利用率。Lucene 对 RoaringBitmap 的实现做了简化,只能存储有序数据。
DocIdSet implementation inspired from http://roaringbitmap.org/ The space is divided into blocks of 2^16 bits and each block is encoded independently. In each block, if less than 2^12 bits are set, then documents are simply stored in a short[]. If more than 2^16-2^12 bits are set, then the inverse of the set is encoded in a simple short[]. Otherwise a FixedBitSet is used.
如上述代码注释所言,RoaringDocIdSet 会按数值的高 16 位分成 216 个桶,桶内存储低 16 位数值。当桶中存储的数据量少于 212(4096)时, RoaringDocIdSet 使用 short[]存储,当数据量大于 216-212 时,会使用 short[] 反向存储未添加的数值,否则会使用 FixedBitSet 位图存储。如下图所示:

图 8
第一个 block 中包含了 0~65533 共 65534 个文档号,因此反向存储未添加的文档号 65534、65535 两个值(使用类 NotDocIdSet),第二个 block 只有两个值,使用 ShortArrayDocIdSet 直接存储,第三个 block 的数据量大于 4096 小于 216-212 ,使用 FixedBitSet 存储。
RoaringBitmap 是一种高效压缩位图,简称 RBM。RBM 主要将 32 位的整型分为高 16 位和低 16 位的两个 short,其中高 16 位对应的数字使用 16 位整型有序数组存储,低 16 位根据不同的情况选择三种类型的 Container 容器来存储:ArrayContainer、BitmapContainer 和 RunContainer。当一个 Container 里面的 int 数量小于 4096 时,使用 ArrayContainer 存放,ArrayContainer 底层使用 16 位的 char 数组,char 数组始终有序,方便后续使用二分查找。ArrayContainer 只能存储少量数据,当大于 4096 时,则使用 BitmapContainer 按位图结构进行存储。BitmapContainer 底层使用 long 数组。每个 container 要存储 0~65535 间的数据,需要 65536 个 bit,每个 long 有 64 位,因此需要 1024 个 long 来提供 65536 个 bit;RunContainer 则用于存储连续的数据。
RoaringBitmap 作为节省内存的位图结构,对内存与性能都非常友好,因此可以作为我们索引服务倒排列表的核心数据结构。因此,我们的核心存储结构如下图所示:
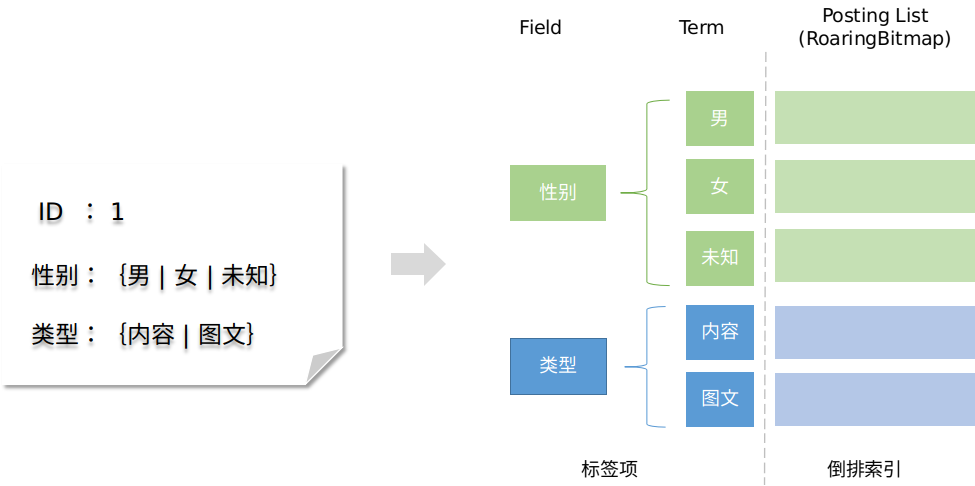
图 9
在上图中,左侧为需要存储的文档对象,右侧为索引库的存储结构。文档中有“性别”与“类型”两个域,“性别”域下有“男”、“女”和“未知”三个域值,“类型”域下有“内容”、“图文” 两个域值,域值即对应 Lucene 中分词后的 Term 词典。最后对每个 Term 构建一个倒排的数据结构,即上图右侧所示。
Term 词典的存储
如何对文档域中的 Term 进行表示呢? Lucene 在不同的场景下使用了不同的数据结构。在内存索引构建过程中,Lucene 通过 BytesRefHash 与 FreqProxPostingsArray 的配合,实现了一个双向 HashMap。它不仅能在 O(1) 的时间复杂度通过 key 找到 value,也能在 O(1) 时间复杂度通过 value 查找 key。在查询阶段,Lucene 使用了 FST 来管理字段 term 与磁盘中倒排列表的映射。
在我们的设计中,由于我们的 term 数量是有限且可控的,因此可以使用 HashMap 对 Term 及其倒排数据进行映射存储。如何对 Map 的 Key 进行设计呢?一方面,需要能快速查找到 term ,另一方面,又需要保证查询的性能与内存的使用。如果使用 String 类型作为 Key,则可以将 { 文档类型,域名,域值 } 拼接为字符串。这种设计有一个明显的问题,即文档类型和域名会有大量的重复字符,在内存的使用与查询比较时都不够高效。可以使用前缀树(Trie Tree),通过共享相同的前缀节省较大的内存空间,比前缀树更优化的数据结构为 PatriciaTrie,这种数据结构是对 Trie Tree 的优化,在字符串的存储和查找方面具有更多优势。但在我们的设计中,采用了将 { 文档类型,域名,域值 } 合并为一个 long 型数值的方式,long 型数值的存储相对于字符串来说内存固定且可控,查询比较时的性能也更好。另外,通过使用支持原生基础类型的 Map 集合可以避免大量的装箱与拆箱操作。
基数树( Radix tree)是一个有序字典树,比前缀字典树更加高效。它有效解决了使用 HashMap 时的 Hash 冲突和 Hash 表大小的问题。它查找速度快、节省存储空间,在 Linux 内核中应用广泛。在 Redis Stream 中,使用基数树存储消息 id 到消息的映射。在我们的场景中,通过将 term 转换为 long,也可以选择基数树进行存储。
我们的文档字段值都是与广告物料属性相关的标签,主要有单值和多值两种形式。如:对于投放人群的性别字段,只能选择“男”、“女” 或“所有”三个标签中的一个,而对于投放类型,则可以选择“音乐”、“有声书”、“娱乐”、“历史”等多个标签的组合。在字段解析的过程中不需要有复杂的分词解析操作。在实际的实现过程中,我们定义了通用标签类(GeneralLabel),用以表示字段及其属性值集合,然后通过将标签类转换为 Term 的形式,作为倒排索引的单词字典集合,如下图所示:

图 10
在将 Term 作为倒排标签项存入 Map 时,会将其转换为 long。long 有 64 位,共分 3 段,如下图所示,即文档类型(高 16 位)、字段类型(中间 16 位)与字段值(低 32 位)。

图 11
索引的建立,需要对文档进行解析。在 Lucene 中,主要使用了归并的设计思想。归并法会对当前处理的文档集合在内存中建立完整的倒排索引结构,当达到内存使用定额时,将内存中的倒排索引写入磁盘文件,最后针对每个索引文件进行合并。在内存倒排索引结构建立的过程中,采用迭代器的模式通过语义分析边解析边进行。
对于我们的内存索引服务来说,在文档解析与标签转换过程中,也使用了迭代器模式,并原地复用辅助对象,避免在整个倒排索引构建过程中创建大量临时对象导致严重的 gc 问题。
索引的更新
除了全量创建索引外,在服务的运行中也会有新的文档进入系统,原先的文档也可能更新或删除,因此需要使用动态索引来满足这种在线实时性的要求。在动态索引的设计中,主要有 3 种关键的索引结构:倒排索引、增量索引和已删除文档列表。
倒排索引就是先给初始文档集合建立好索引结构,单词词典一般存储在内存,对应的倒排列表存储在磁盘文件中。增量索引是在内存中实时建立的倒排索引,词典和倒排列表都在内存中存储。当有新文档进入系统时,实时解析文档并将其追加进这个临时索引结构中。已删除文档列表则用来存储已被删除的文档 ID,形成一个文档 ID 列表。更新文档通过删除旧文档,增加新文档来实现对文档内容的更改。当增量索引达到指定的内存量,需要进行一次索引合并,合并增量索引与老的倒排索引内容。在合并过程中,使用老索引响应用户请求,待合并结束后,释放老索引的存储空间。
对于我们的内存型倒排索引服务来说,单词词典和倒排列表都存储在内存中,因此可以使用原地更新(In-Place)策略,减少设计的复杂度。原地更新策略即直接更新受影响的倒排列表。更新线程与查询线程会产生资源竞争,出现多线程并发问题,需要使用锁机制进行并发操作控制。对于一个需要更新的文档来说,绝大部分字段都没有变更,受影响的只有部分字典 Term 的倒排索引。为了减少并发对查询性能的影响,锁粒度控制到 Term 级别。
索引的查询
索引数据的存储方案设计好之后,接下来需要提供合适的检索模型。在 Lucene 中,提供了各种各样的查询方式,像 TermQuery、BooleanQuery、PrefixQuery、PhraseQuery、TermRangeQuery 等等,其中最基本的查询为 TermQuery,所有其他类型的查询会通过重写(Rewrite)转换成最终的 TermQuery 查询。在我们的业务场景中,主要是基于用户画像查询相应标签的广告物料列表,并对多个标签的物料 ID 列表进行 AND、OR、NOT 的布尔运算。 因此,我们只需要提供类似 BooleanQuery 的查询方式。
Lucene 中 BooleanQuery 用来实现多个 Query 子类对象的组合查询。在 BooleanClause 类中对每一个 Query 定义了四种可选操作,分别描述了匹配的文档需要满足的要求,如下:
查询 API 使用示例如下:
满足查询要求的文档必须包含 "aa",不能包含“cc”,可以包含“bb”、“dd”中一个或者多个,Lucene 会对查询文档进行打分,包含的越多,文档的分数越高。
如上所示,Lucene 设计了 Term 类表达需要查询的域名(FieldName)与域值(FieldValue)。在我们的设计中,与之相似的类称为 Label 标签。我们的布尔查询类 BooleanQuery,通过提供 and、or、not 方法, 将多个 Label 标签的不同布尔计算进行封装,示例如下:
这是一种基于 API 调用的查询操作。为了支持 RPC 场景下的使用,还需要设计一种能将查询语句序列化为查询表达式的方案。在 Lucene 中,提供了查询表达式的支持,一个查询表达式由一系列的项(term)和运算操作符组合而成,下面是 Lucene 查询表达式的常用的运算符:
在上面 Lucene 查询 API 使用的例子中,用查询表达式书写如下:
Lucene 使用了 JavaCC 对表达式进行解析。JavaCC 根据定义的规则生成词法分析器和语法分析器。通过语法分析器将用户的查询表达式转换成一个 Query 查询语法树,执行语义解析实现与查询 API 一致的功能。
在我们的实现中,也提供了表达式语法,语法如下:
逻辑操作符: and, or, not
比较操作符: ==, !=, in (), not in (), not
表达式使用示例如下:
有了查询 API,需要对布尔查询的逻辑进行实现。在 Lucene 中所有的查询都需要转为 TermQuery,BooleanQuery 也不例外。Lucene 中的 BooleanQuery 实现了 Query 的 rewrite 方法,Lucene 中定义的 MUST、SHOULD、FILTER、MUST_NOT 操作与它们之间不同数量的组合有着不一样的 rewrite 逻辑, lucene 有多达 9 个逻辑来进行不同组合的实现。基于我们的业务场景,对整个过程进行了简化。我们定义了一个 QueryAction 的接口,并对 AND、OR、NOT 提供了三个实现类,类图如下:

图 12
在 QueryAction 的实现类中,需要将查询的 Label 转换为一个或多个 LabelItem 来获取相应的倒排列表,通过定义方法 computeLabelIterator 得到一个 LabelItem 的迭代器,在 LabelItem 迭代器中依次计算 Label 到 LabelItem 的转换。在对查询表达式进行语义解析的过程中,基于语法树按照执行优先级完成对表达式的依次解析执行。 QueryAction 的多个实现类通过查询迭代器类 BooleanQueryIterator 与语法树的解析相配合,实现每个标签的查询与计算,最终完成了布尔计算的核心逻辑。
复杂查询表达式的设计
在实际的使用中,业务场景会更加复杂,是否需要某个标签的物料是通过一系列逻辑判断决定的。在将已有的业务代码迁移到这套倒排检索服务时,会出现业务复杂而无法使用生成表达式的问题。在使用 ElasticSearch 的过程中,这个问题同样存在,最终能通过组装成 ElasticSearch 查询条件进行物料召回的,都是业务逻辑比较简单的查询场景。
如下代码所示,会基于某些条件进行广告物料属性的过滤,像这类函数很难直接构建查询表达式进行倒排索引的查询:
为了解决此类问题,在查询表达式中提供了个性化的函数定义。在上述场景中,通过提供 IF 函数,对 IF 表达式的定义如下, 保持 IF 函数的语义与原 Java 代码语义一致,这样大大简化业务代码向倒排检索服务的迁移:
上述表达式中,IF 函数接收三个参数,第一个参数为条件表达式,第二个参数为条件表达式为真时继续查询的表达式,第三个参数为条件表达式为假时继续查询的表达式。相当于如下逻辑语句:
上面示例中的表达式书写如下:
过滤统计
在我们的业务场景中,在执行查询时,需要对每个广告物料进行统计计数。在业务代码中我们会为每个查询策略(包括一个或多个表达式)定义一个过滤代号,查询时需要统计每个广告物料 id 是由于什么策略过滤的,方便后续的问题定位排查与投放策略的调整。在使用 ElasticSearch 的情况下,查询是在 ElasticSearch 内部处理的,这个功能很难实现,对于我们的倒排索引服务来说,需要能支持查询统计的能力。
由于物料量大,查询请求并发高,对每个物料的过滤情况进行统计,会严重影响到检索系统的性能。因此需要对这个功能进行合理的设计。先看一个简单的设计方案,定义一个 HashMap,HashMap 的 Key 为文档 ID 与过滤原因代号的组合,即组合标签 { 文档 Id,过滤代号 },在 Promotheus 的设计中,这个 Key 使用 List 结构存储这类标签组合值, Map 的 Value 为 一个 AtomicInteger 计数器,当每次过滤时,查找标签对应的计数器,并对计数器执行加 1 操作。在我们这种过滤量很大的场景下,这个方案会有严重的性能问题。一次查询可能会有万级的广告物料过滤量,在进行计数时,需要先对每个文档 Id 与过滤代号生成一个 Key 类型的标签对象,然后在 Map 中通过 Hash 和 equals 方法查找匹配的 Key ,这个查找过程会消耗大量的 CPU 时间,生成的标签对象也会对 gc 产生压力。另外,同步执行时会阻塞工作线程的执行。因此,需要有更好的优化方案。
首先,统计计数不应该直接影响到查询业务线程的响应时间,这里我们选择使用 Disruptor 框架作为异步消息队列进行线程间通信的数据结构。Disruptor 是一个高性能的消息队列,它使用 CAS 代替传统锁机制,使用独占缓存行避免多核 CPU 下的缓存更新失效问题,通过环形队列并一次性初始化全部对象的方式减少重复对象的创建,降低了 gc 的频率 ,在我们的场景中是一个合理的选择。
其次,计数过程也要足够轻量。上述方案需要通过计算标签的 hash 值与 equal 方法从 Map 中查找计数器,当过滤的物料数很多时,从火焰图上观察到这个过程 cpu 的使用占比极大,是主要的性能瓶颈。
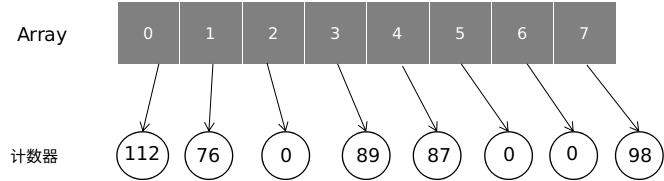
图 13
改进的方案如上图所示。对每个文档 Id 维护一个过滤代号的统计数组对象,数组元素为计数器对象 AtomicInteger,给每个过滤代号分配一个数组索引值。这样可以通过数组索引值在 O(1)时间内定位到对应的计数器对象,整个过程避免了 HashMap 中 Key 对象创建和 Hash 值的计算与比较操作,性能有了很大的提升。计数器数组使用 List 数据结构进行包装,实现了过滤统计的动态扩容。数组定义如下:
本质上来说,这是一种通过内存换 cpu 时间的解决方案。每个文档 Id 都有一个 counters 的数组结构,如下图所示:
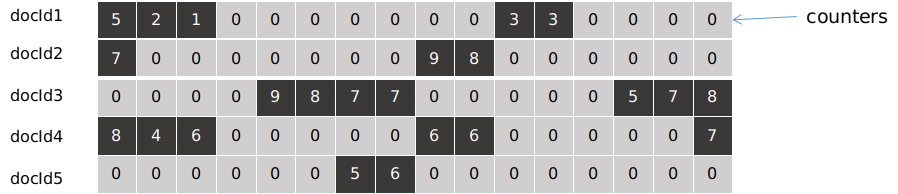
图 14
从实际运行情况看,绝大部分广告物料都是由于某些特定的策略过滤的,在 counters 数组里面大部分索引位的计数器为 0 值,在物料数量很大的情况下,这些数组占用了很大一部分的内存。因此,可以对数组进行如下优化:

图 15
将原来的 Array 数组按固定长度进行分割,将一维数组转换成二维矩阵。通过过滤代号的索引值从二维矩阵结构中定位到计数器的位置。当文档 ID 某行没有任何过滤原因需要统计时,这一行的计数器则不需要创建。使用这种方式,可以节省大量内存。二维矩阵定义如下:
这种处理方案与前文提到的 SparseFixedBitSet 类似,这是一个结合业务场景进行的优化。这个优化将原来的密集矩阵改进为稀疏矩阵的方案,内存的使用量也大幅降低。
总结
本文主要通过对 Lucene 存储与查询原理的分析,讨论了自研内存型倒排索引服务设计的主要环节。当然,一个稳定可用的服务还有很多细节的工作需要完善。我们自研的内存倒排索引服务上线后,一次耗时 50ms 的 ElasticSearch 查询降低到 5ms 以下,服务稳定性和能支撑的广告物料数都有了大幅度的提升,保证了我们后续业务的发展 。
版权声明: 本文为 InfoQ 作者【喜马拉雅技术团队】的原创文章。
原文链接:【http://xie.infoq.cn/article/bcb0ad180a6665112132cbc3d】。文章转载请联系作者。

还未添加个人签名 2020-07-01 加入
喜马拉雅技术团队官方账号,技术经验沉淀与总结分享,与你一同进步。









评论