
采用 Excel 作为设计器的开源中国式报表引擎:NopReport
中国式报表是复杂结构报表的代名词,它泛指国内信息化领域经常出现的基于多源数据,采用行列交叉、多层级表头、自由分片合并等形式所展现的信息汇总报表。
润乾报表的创始人蒋步星是写入了中国历史的传奇人物(国际奥林匹克数学竞赛的首届中国金牌得主,来自新疆石河子,参见顾险峰教授的回忆),他发明了中国式报表模型相关的理论,并引领了整整一代报表软件的技术潮流。
目前国内商业化的报表工具都支持中国式报表的制作,但是开源的报表引擎中只有UReport支持中国式报表,而且目前已经不再维护。
NopReport 是基于可逆计算理论从零开始独立实现的一套开源中国式报表引擎,它的核心代码很短,只有 3000 多行(参见nop-report-core模块),具有较高的性能(性能测试代码参见TestReportSpeed.java),以及其他报表引擎难以达到的灵活性和可扩展性。
NopReport 在Nop平台中的定位是对表格形式数据结构的通用建模工具,所有需要生成表格形式数据的功能都可以转化为 NopReport 报表模型对象来实现。例如,NopCli 命令行工具提供的数据库逆向工程命令会逆向分析数据库表结构,生成 Excel 模型文件,这个 Excel 模型文件就是通过将导入模板转化为报表输出模型来生成。
与其他报表引擎相比,NopReport 具有如下非常鲜明的个性化特点:
一. 采用 Excel 作为设计器
根据可逆计算原理,报表引擎的本质是定义了一个针对表格形式数据结构的 DSL(参见元模型定义workbook.xdef),而可视化设计器不过是这个 DSL 的一种可视化展现形式。Nop 平台为了实现模型驱动的代码生成器,已经实现了 Excel 文件的解析和生成,那么只要再做少量扩展标注,就可以把 Excel 作为报表设计器来使用。具体做法是将 Excel 的批注作为扩展信息,并识别单元格文本中的表达式语法。目前 NopReport 已经可以支持如下几种报表:
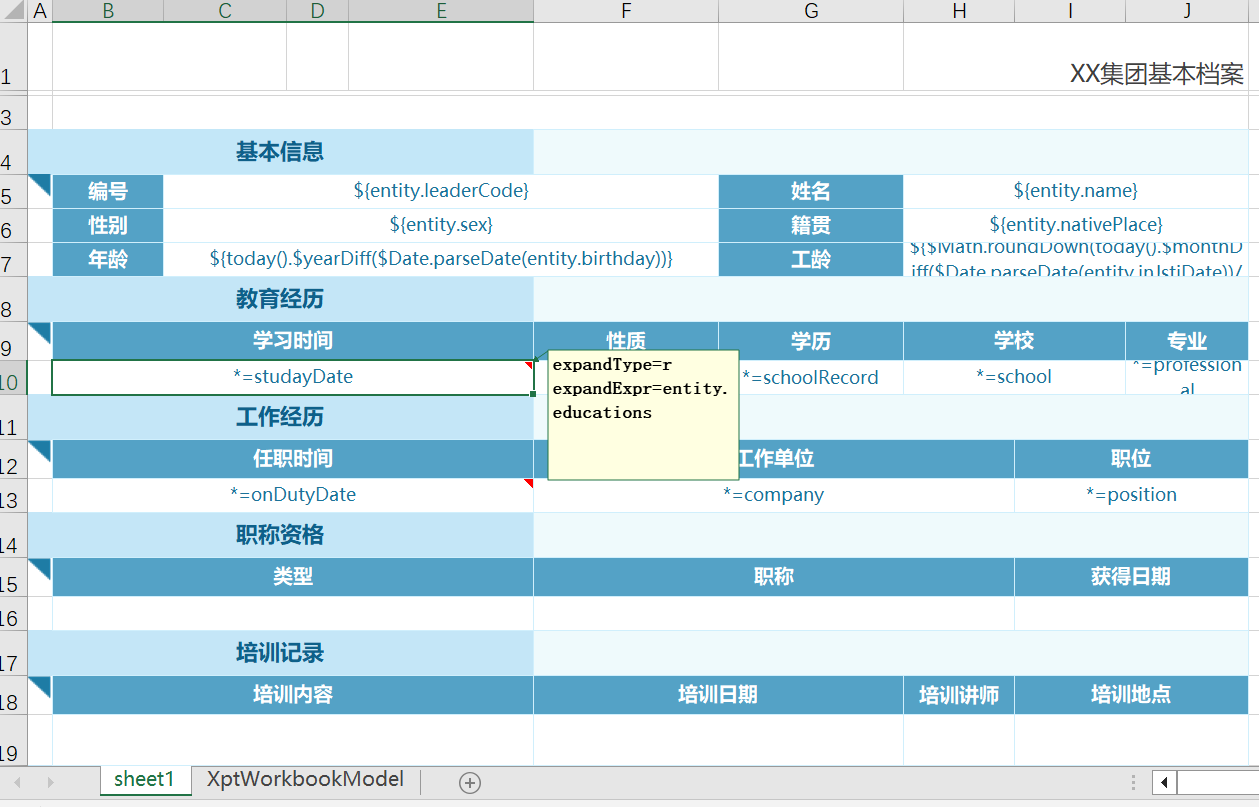
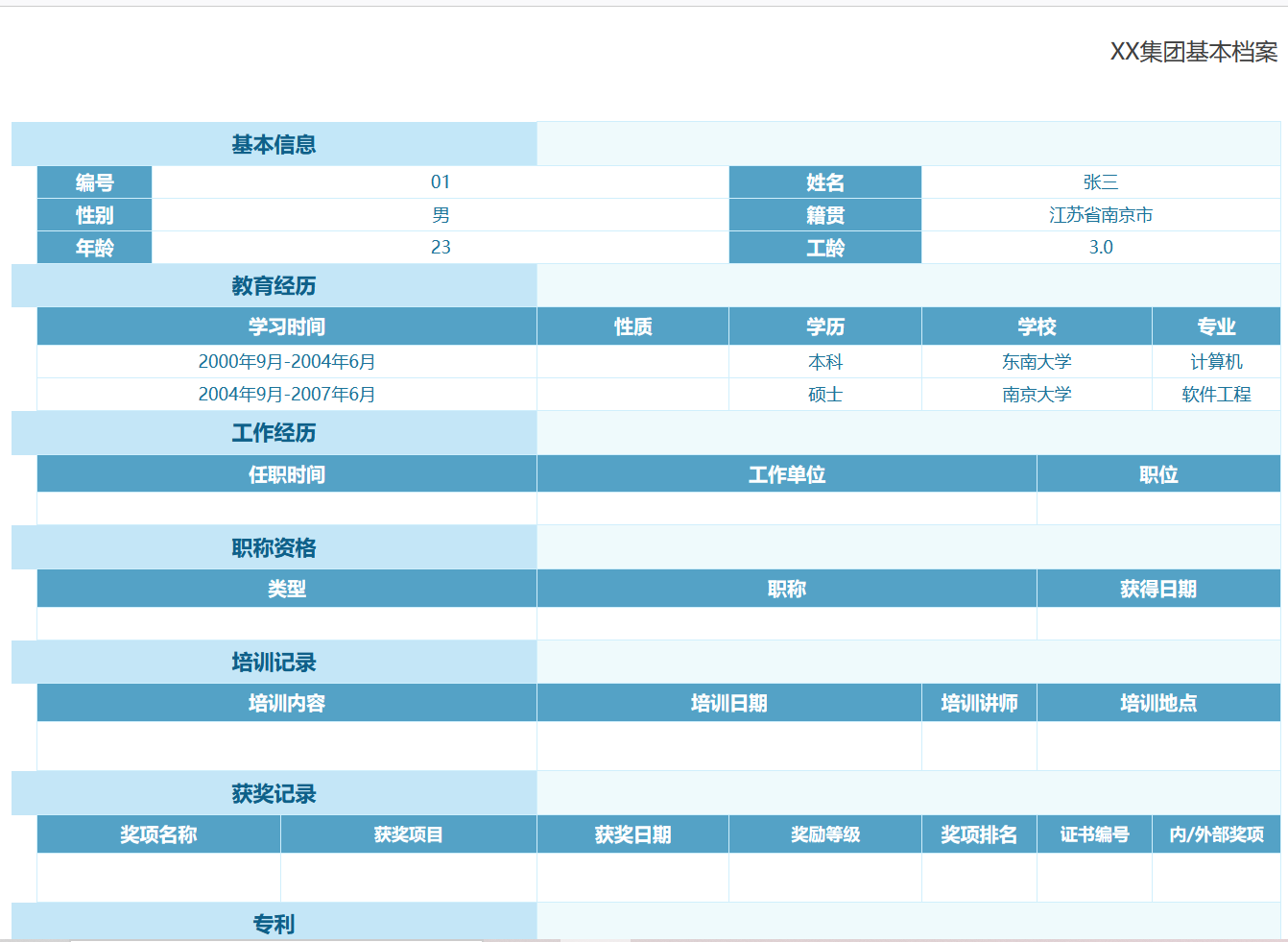
档案式报表
段落明细表
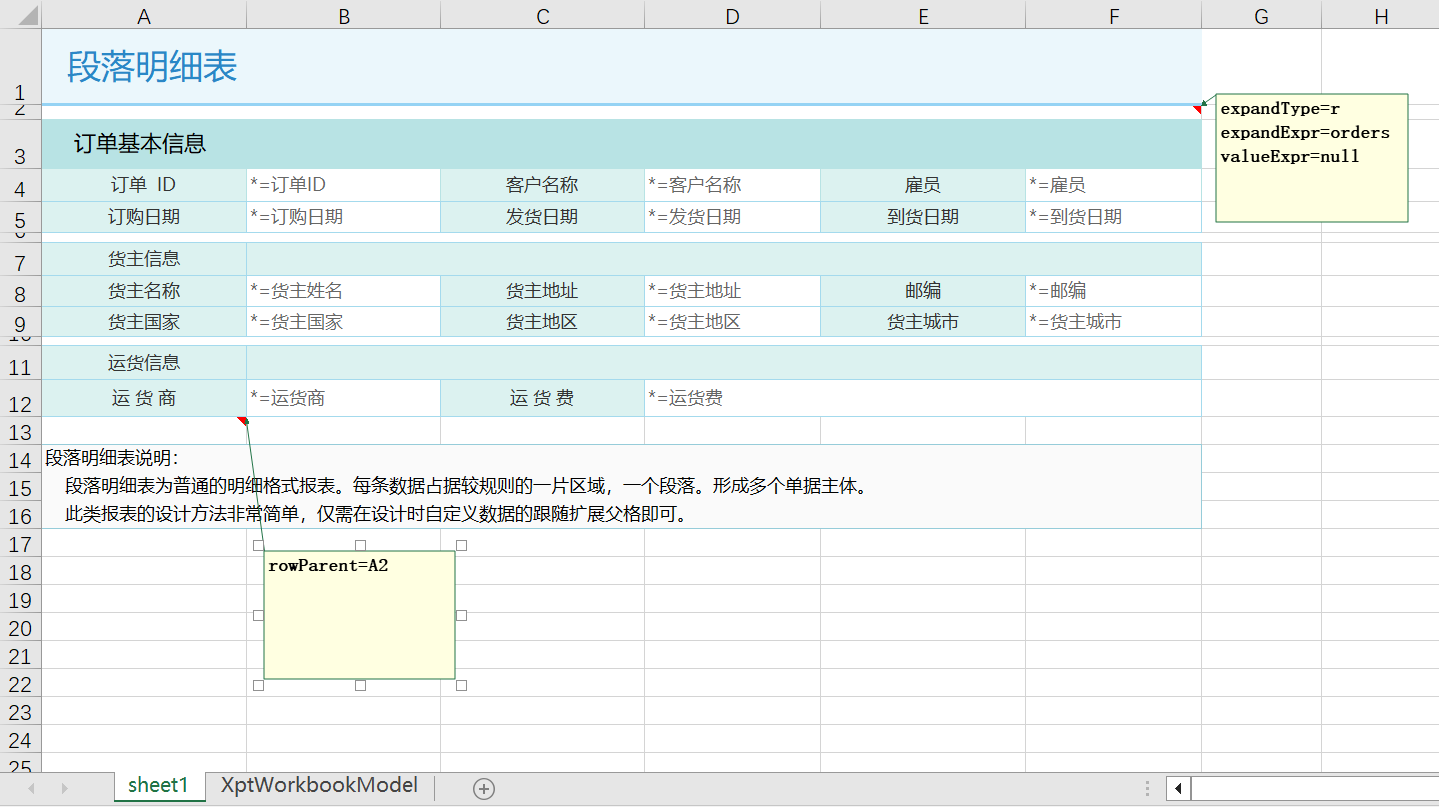
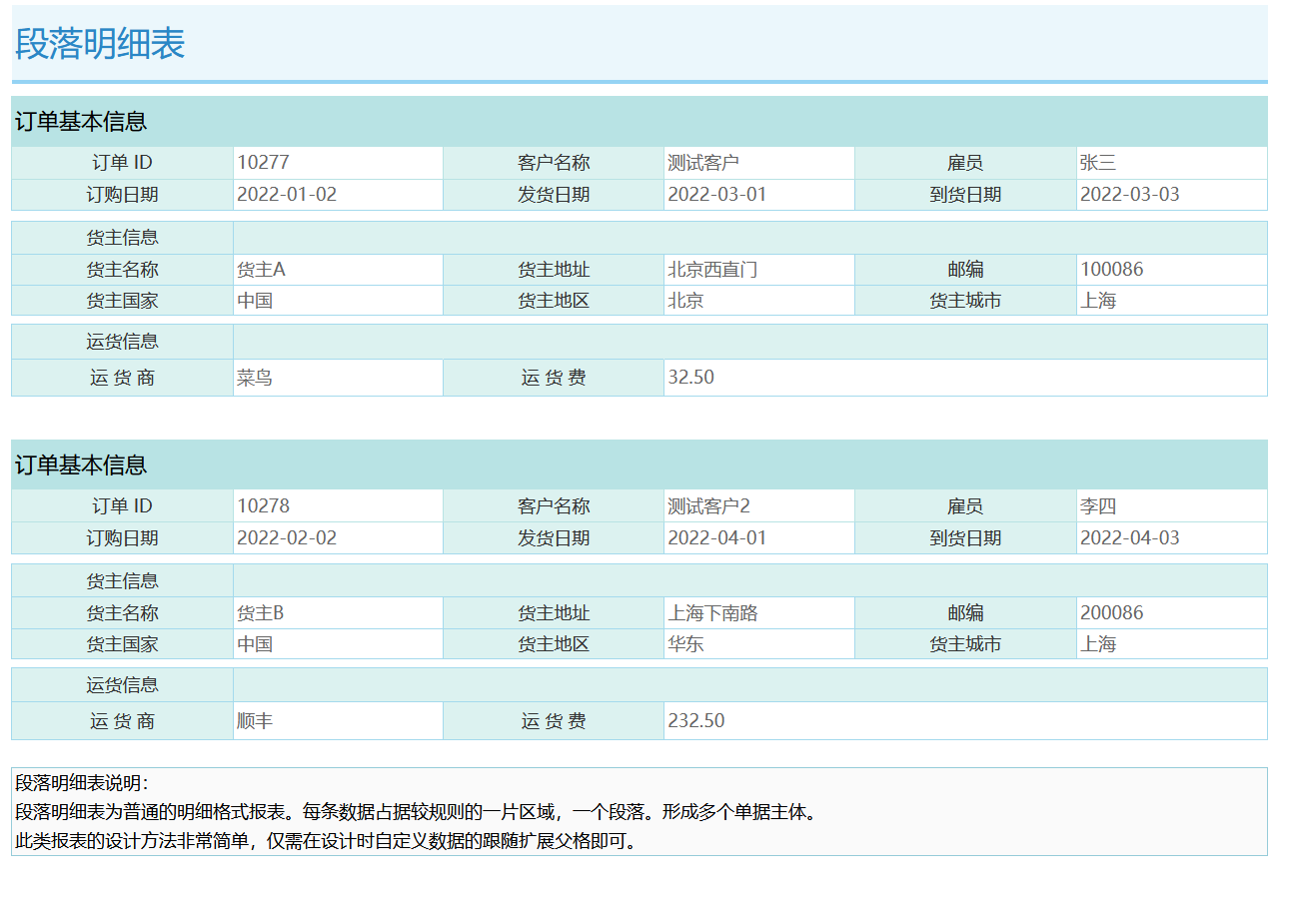
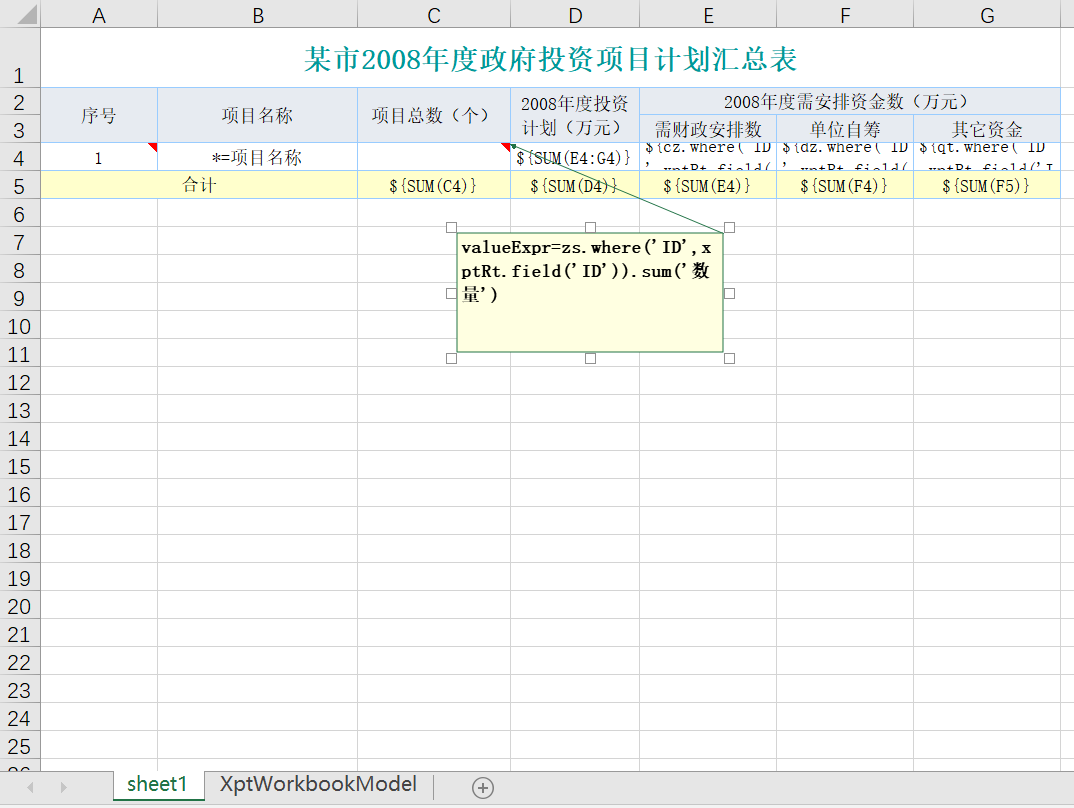
复杂多源报表
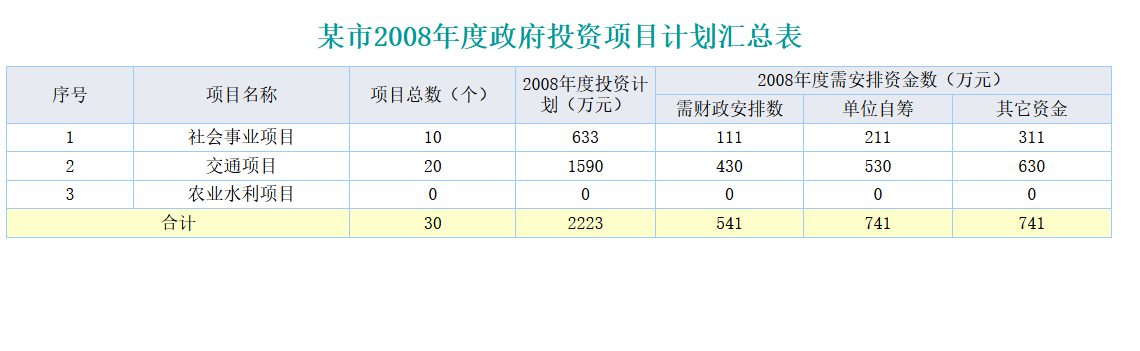
交叉报表—数据双向扩展
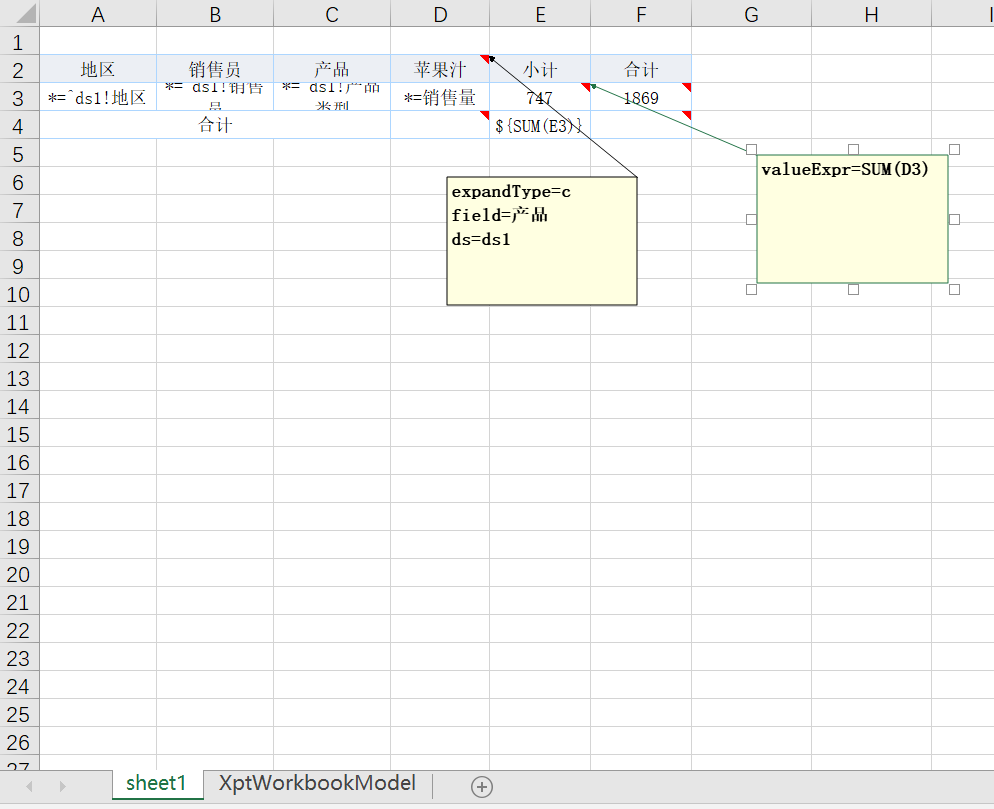

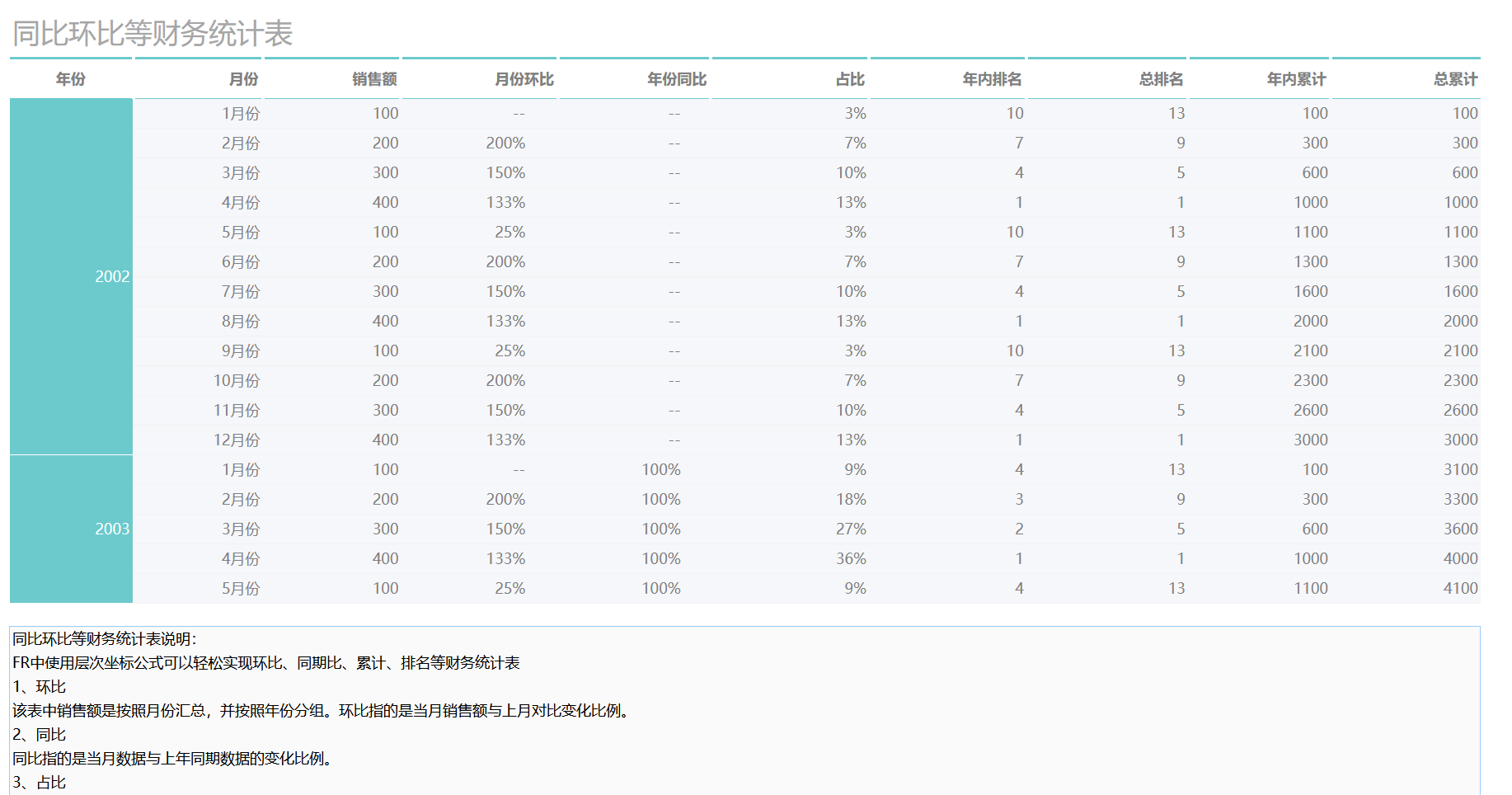
同比环比等财务统计表
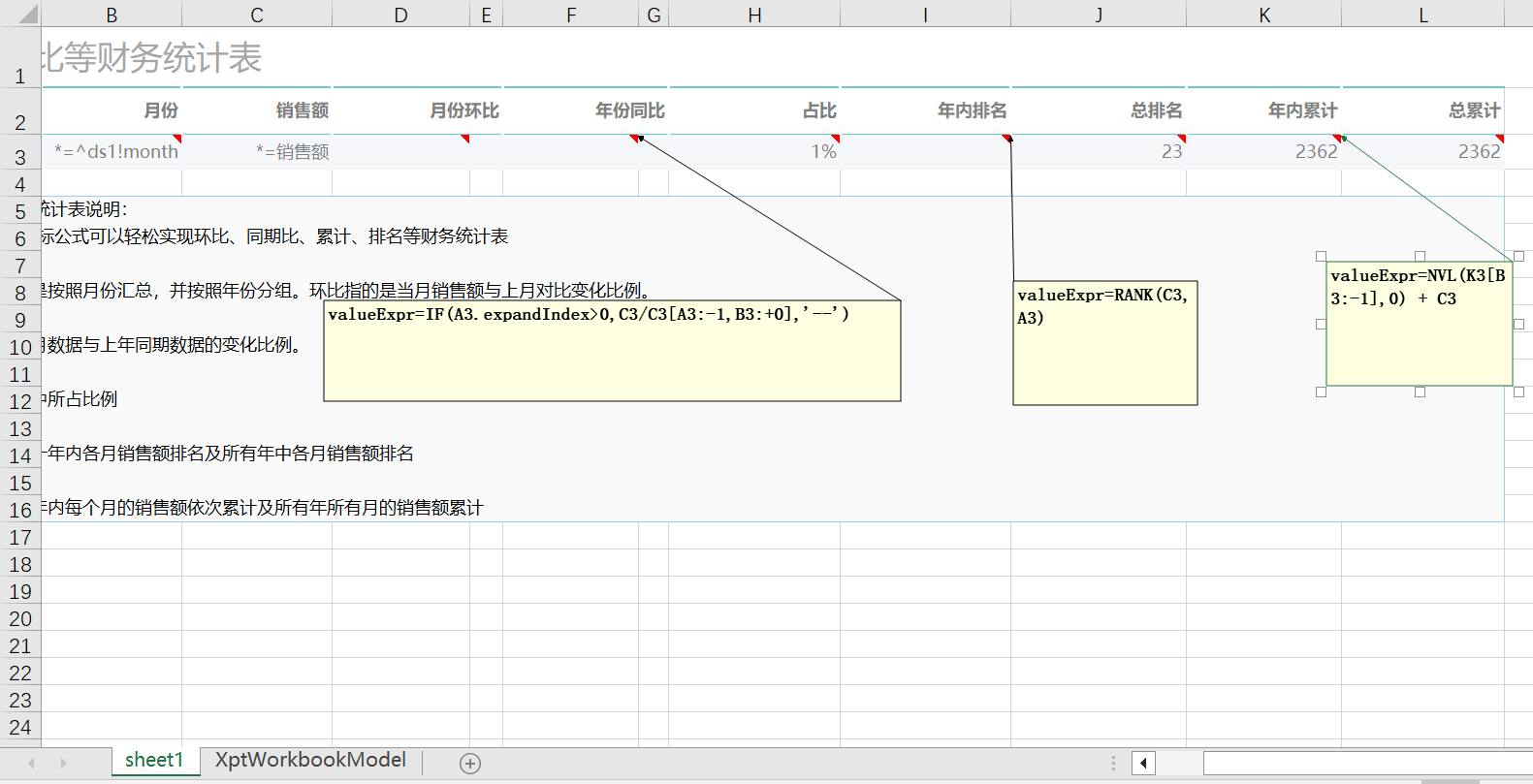
Excel 模型扩展
NopReport 报表模型可以看作是对 Excel 模型的一种扩展。在单元格的批注中我们可以通过 expandType、expandExpr 和 field 等属性来指定单元格展开方向和展开内容。另外在单元格的文本中,我们可以直接写表达式语法。优点是在界面上可以直接看见表达式内容,而不需要把批注展开。支持两种格式的文本表达式语法:
EL 表达式:例如 ${entity.myField}
展开表达式:它采用
*=作为前缀 A.*=fieldName等价于配置 field=fieldNameB.*=^ds1!fieldName,等价于配置 expandType=r, ds=ds1, field=fieldNameC.*=>ds1!fieldName等价于配置 expandType=c, ds=ds1, field=fieldName
详细说明参见文档xpt-report.md
二. 高度灵活的数据对象支持
一般的报表引擎在数据管理层面都只面向平面表数据结构,基本操作流程都是先建立数据源(DataSource),然后建立数据集(DataSet),数据集对应于数据库中的表或者视图,而数据集所管理的就是一行行的数据记录。
这种做法的好处是报表引擎比较容易通用化,可以独立于业务系统运行。但是坏处也很明显,那就是报表引擎无法直接使用应用程序内部已经建立的领域对象模型,也无法利用领域模型内在的结构关系来进行性能优化。
NopReport 采用的是一种更加灵活、开放的分层式设计,它的运行时直接面向领域模型对象,而数据集(DataSet)仅仅是作为可选的一种数据组织形式。例如,在上一节介绍的档案式报表中,通过 JSON 变量直接构造报表数据
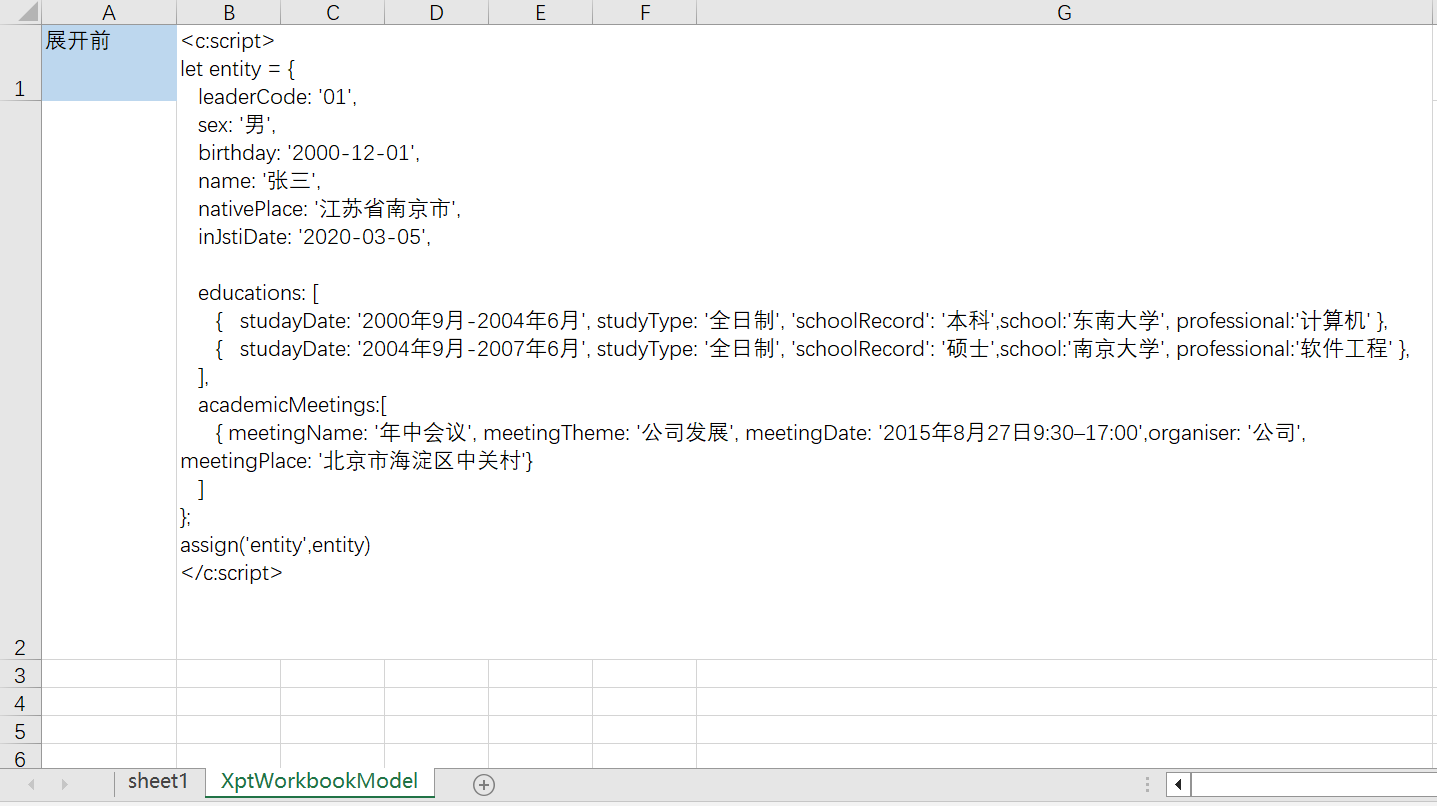
展开【教育经历】时,只需要配置 expandType=r, expandExpr=entity.educations。而类似帆软报表的报表工具需要定义多个数据集: ds_study、ds_work 等,然后再配置这些数据集之间的关联过滤条件。而在 NopReport 中,我们直接假定用户信息按照树状结构进行组织。从 NopOrm 引擎中查询得到的用户对象可以直接送到报表引擎中作为输入数据,并不需要在报表引擎中重新定义一个专为报表导出而用的数据集。
NopOrm 引擎中已经针对对象关联属性的存取进行了优化(例如解决 ORM 引擎常见的N+1问题等),使用起来也非常符合业务直觉: 表格单元格上的父子关系很直接的对应于实体对象上的属性关联关系。
NopReport 对数据来源没有任何特殊要求,在【展开前】配置中,我们可以使用 Xpl 模板语言对数据进行自由加工。一般的报表引擎可以通过可视化设计器来设计数据集,而在基于可逆计算原理构建的 NopReport 报表引擎中,我们其实可以很容易的模拟实现这一点。
例如【展开前】可以引入 Xpl 标签抽象,将具体数据集的获取方式封装为 Xpl 标签。
我们可以将<rpt:UseJdbcDataSet>等标签看作是一种配置文件,利用 Nop 平台的 GenericTreeEditor(目前尚在开发过程中)就可以自动生成数据集的可视化设计器。
利用 Nop 平台作为技术底座,我们可以积累出专门适用于自己领域的数据模型定义,而不用完全依赖平台内置提供的数据模型。
三. 使用通用的表达式语法
中国式报表理论中非常独特的地方是所谓的层次坐标。例如 B2[A2:+1]表示返回以 A2 单元格为父格的下一个 B2 单元格纵向扩展的数值(这个所谓的下一个是相对于当前行中的 B2 单元格而言)。为了配合层次坐标表达式,报表引擎一般都会引入报表专用的表达式引擎,它具有自己特定的语法、函数,从而导致和一般的业务开发中使用的表达式语法有着较大的差异,无法直接复用相应的代码,也需要重新学习相应的表达式语法。
NopReport 直接复用 XScript 表达式引擎,在 XScript 表达式语法(类似于 JavaScript 语法)的基础上扩展了层次坐标语法。实际上只需要几十行代码即可为表达式引擎引入层次坐标支持,具体可以参见ReportExpressionParser.java。
每个坐标表达式会返回一个 ExpandedCellSet 对象,
NopReport 的层次坐标语法不支持 Filter 过滤条件,但是在返回的 ExpandedCellSet 对象上具有 filter 方法,我们通过调用此函数来实现类似的效果。
ExpandedCellSet 实现了 Iterable 接口,在报表函数可以直接作为值的列表来使用,例如在 SUM 函数中
我们并不需要特殊识别 ExpandedCellSet 类型进行特殊处理。
在 NopReport 中,数据集对于层次坐标的支持也完全被屏蔽在 ReportDataSet 类型中,而完全不需要在表达式引擎中做出任何特殊的定制。
@EvalMethod是 XScript 所识别的一种语法标记,它表示在表达式调用时会自动传入 scope 环境对象。例如ds.sum('金额')实际会调用到 ReportDataSet.sum(IEvalScope, String)方法。current 函数会根据隐式传递的 scope 变量来确定当前单元格所对应的层次坐标,然后再确定满足该层次坐标条件的数据条目是哪些。
上一节中复杂多源报表中为了获得项目总数,我们使用了表达式配置 valueExpr=zs.where('ID',xptRt.field('ID')).sum('数量'),这就是一个普通的 JavaScript 函数调用。而在帆软报表的配置中,我们需要配置数据集之间的关联过滤条件,还需要约定特殊的数据集调用表达式 zs.求和(数量)。
在 Nop 平台中,我们可以很容易的在表达式计算过程中引入我们自定义的封装函数,而不需要所有函数都是在报表引擎已经内置的函数。例如在【展开前】配置中我们增加针对当前报表的函数,而不需要注册为全局函数。
在ReportFunctions类中增加的静态函数会自动成为 ReportFunctionProvider.INSTANCE 中注册的全局报表函数。
四. 性能优化友好的设计
NopReport 采用了大量性能优化的结构设计,并且大幅简化了报表层次展开算法。
最基础的展开单元格对象采用了单向链表设计,当频繁进行单元格插入操作时可以提高性能。
在 ExpandedCell 对象上增加了扩展属性支持,表达式引擎计算过程中将会利用这些扩展属性来缓存可以被复用的中间计算结果。
例如 PROPORTION 函数用于计算一个单元格的值在所有满足条件的单元格的汇总值中占比是多少。
我们利用了 rangeCell 的扩展属性缓存了 rangeCell 的具有指定名称的所有子单元格的汇总值。
五. 多 Sheet 支持和循环生成
NopReport 的设计支持多 Sheet 页,可以在 Excel 中增加多个 Sheet 页,每个 Sheet 页都可以有自己对应的配置。此外可以配置【循环变量】,从而动态确定具体生成多少个 Sheet 页,每个 Sheet 页的名称是什么。利用这个机制,可以更容易的生成档案式报表。
基于可逆计算理论设计的低代码平台 NopPlatform 已开源:
版权声明: 本文为 InfoQ 作者【canonical】的原创文章。
原文链接:【http://xie.infoq.cn/article/bca9f8024062c87bde758c567】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2022-08-30 加入
还未添加个人简介









评论