
索引的基础知识
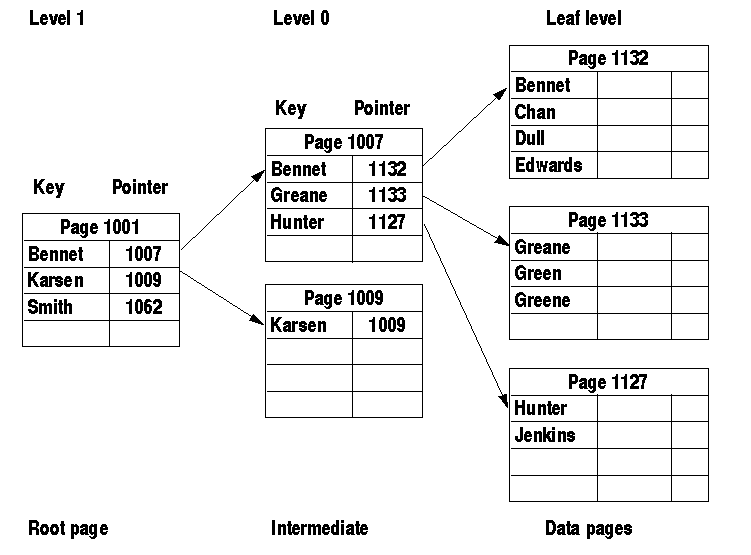
用户对数据库最频繁的操作是数据查询。一般情况下,数据库在进行查询操作时,需要对整个表进行搜索。当表中的数据很多时,搜索数据就需要很长的时间,这就造成了服务器的资源浪费。为了提高检索数据的能力,数据库引入了索引机制。
索引是一个单独的、物理的数据库结构,是数据库的一个表中所包含的值的列表,其中注明了表的各个值所在的存储位置。索引是依赖于表建立的,提供了编排表中数据的方法。
实际上,一个表的存储是由两部分组成的,一部分用来存放表的数据页面,另一部分存放索引页面,索引就存放在索引页面上。通常,索引页面相对于数据页面来说小得多。当进行数据检索时,系统先搜索索引页面,从中找到所需数据的指针,再通过指针从数据页面中读取数据。
从某种程度上,我们可以把数据库看作一本书,把索引看作书的目录,通过目录查找书中的信息。显然,与没有目录的书相比,这显得方便和快捷。
一般的数据库,如 SQL Server、Oracle 等,按存储结构的不同将索引分为两类,簇索引(ClusteredIndex)和非簇索引(Nonclustered Index)。
簇索引
簇索引对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即簇索引与数据是混为一体的,它的叶节点中存储的是实际的数据。
簇索引对表中的数据一一进行了排序,因此用簇索引查找数据很快。但由于簇索引将表的所有数据完全重新排列了,所需要的空间也就特别大,大概相当于表中数据所占空间的 120%。表的数据行只能以一种排序方式存储在磁盘上,所以一个表只能有一个簇索引。
非簇索引
非簇索引具有与表的数据完全分离的结构,使用非簇索引不必将物理数据页中的数据按列排序。非簇索引的叶节点中存储了关键字的值和行定位器。行定位器的结构和存储内容取决于数据的存储方式。如果数据是以簇索引方式存储的,则行定位器中存储的是簇索引的索引键;如果数据不是以簇索引方式存储的,则行定位器存储的是指向数据行的指针,这种方式又称为堆存储方式(Heap Structure)。非簇索引将行定位器按关键字进行排序,这个顺序与表的行在数据页中的排序是不匹配的。
由于非簇索引使用索引页存储,比簇索引需要更多的存储空间,且检索效率较低。但一个表只能建一个簇索引,当用户需要建立多个索引时,就需要使用非簇索引了。从理论上讲,一个表最多可以建 249 个非簇索引。
版权声明: 本文为 InfoQ 作者【阿泽🧸】的原创文章。
原文链接:【http://xie.infoq.cn/article/bba7470a38f078bc0ce2efd07】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2020-11-12 加入
还未添加个人简介








评论