
GaussDB 细粒度资源管控技术透视
背景
对数据库集群内资源管控与资源隔离一直是企业客户长久以来的诉求。华为云 GaussDB 作为一款企业级分布式数据库,一直致力于满足企业对大型数据库集群的管理需要。
数据库可以管理的资源有计算资源与存储资源,计算资源包括 CPU、内存、IO 与网络,存储资源包括数据存储空间、日志存储空间与临时文件等。
从用户角度来看,资源管控通过设定阈值或者优先级限定程序对资源的使用,保证承诺服务等级协议的同时,又满足不同用户间资源隔离,达成多个租户共享数据库资源的目的。
从系统的角度来看,引入资源监控与控制的手段,可以实现资源在可控情况下被合理利用的目的,避免资源耗尽,防止系统停止响应、崩溃等情况的发生。作业优先级,可以保证作业平稳运行,避免某个作业占用资源过高时影响其他作业,并在资源富裕时,实现资源利用的最大化。除此以外,还能满足外部的期望,保证系统资源使用最大化。通过对作业控制,可以保证作业是平稳的,避免作业执行过程中出现不可控的行为。
为了解决上述目标,华为云 GaussDB 数据库提供了一种对数据库集群内资源进行细粒度管控的方案——细粒度资源管控。该方案在不同的管控粒度(如用户级、会话级与语句级)和不同的管控维度(CPU、内存与 IO)都提供了对应的管控能力。用户可以根据自己业务需求采取合适的管控维度与管控粒度来达成资源管控与资源隔离的目标,满足不同场景的资源控制的需要。
技术架构
我们先来看下细粒度资源管控的技术架构和运行原理:
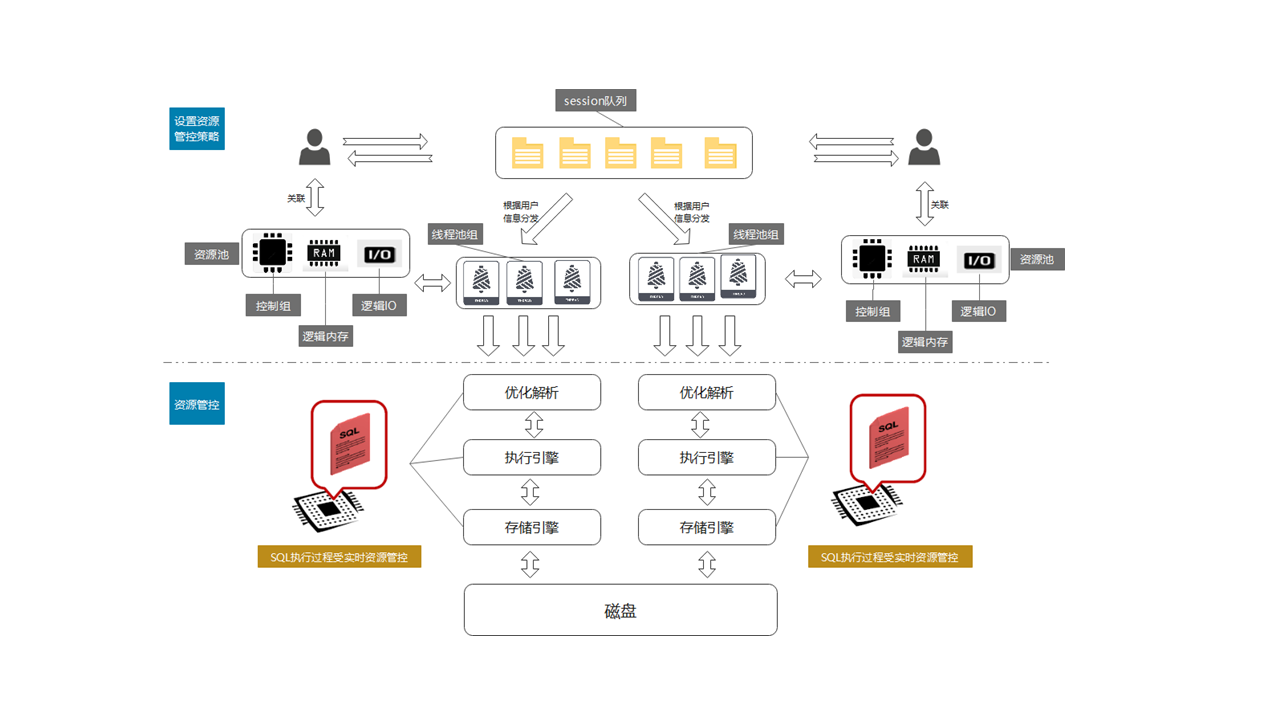
从上图中可以看到,GaussDB 提供资源池模块来完成 CPU、内存与 IO 的管控逻辑。用户可以创建一个资源池并指定其可以使用的 CPU、内存与 IO 的份额,并把资源池与用户绑定。之后该用户发起的作业在数据库内核优化解析、执行引擎以及存储引擎模块运行的过程中都会受到实时资源管控,确保其 CPU、内存与 IO 都在对应资源池的范围内。
假设 A 公司部署了一套 GaussDB 实例,其同时存在三个不同的应用来访问该实例,如 OLTP 业务、报表业务、其他低优先级业务。A 公司希望对三个业务做资源的合理管控,在保证资源使用最大化的情况下,系统平稳运行。我们可以使用系统管理员执行如下命令来为三个业务的用户设置,其资源份额比例为 50:30:10,剩余的 10%为系统预留。
这里仅做简单的使用示例,每一个参数的具体含义会在后面的章节进行详细说明。
如上操作后,OLTP 业务、报表业务与其他低优先级业务分别使用 tp_user、report_user 与 other_user 连入 GaussDB 执行作业时,这三个业务则会受到对应的资源池 respool_tp、respool_report 与 respool_other 的管控,在资源发生争抢的时候保证三个业务分别可以使用 GaussDB 集群 50%、30%以及 10%的资源。
关键能力
在了解了细粒度资源管控的整体架构和使用方法之后,我们再来看看它具备哪些关键能力,这些能力可以为客户带来什么样的业务价值。
CPU 管控
GaussDB 的 CPU 管控是以资源池粒度来做用户资源管控的,每一个资源池绑定一个控制组,通过控制组(Control Group,CGroup)来实现 CPU 的管控。CGroup 是 Linux 内核提供的一种限制、记录、隔离进程组所使用的物理资源(如 CPU、Memory、IO 等)的机制。
考虑到数据库系统、用户、作业不同维度的隔离性和可配置性,GaussDB 使用控制组的层级特性构造符合数据库场景的模型(见下图),其满足客户 SLA 的关键特性,并支持三个维度的层次隔离和控制:数据库程序与非数据库程序隔离、数据库常驻后备线程与执行作业线程隔离以及数据库多用户之间的隔离。
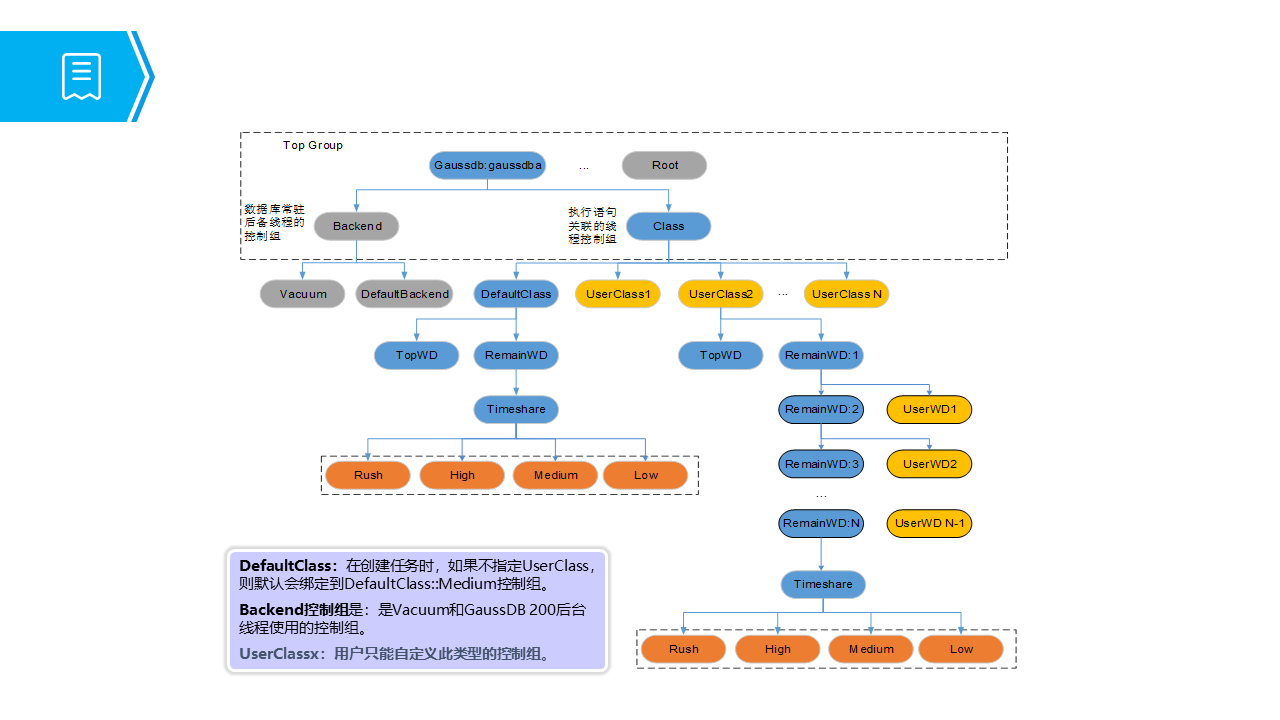
GaussDB 控制组可以设置 CPU 的百分比以及核数的上限,其中根节点负责管控 GaussDB 进程可用的 CPU 份额;Backend 控制组负责管控数据库常驻后台线程的 CPU 份额(Vacuum、DefaultBackend);Class 控制组负责管控用户的作业线程的 CPU 份额(UserClass1,UserClass2,...UserClassN);Class 控制组内还可以创建 Workload 控制组(TopWD,RemainWD...)进行更细粒度的管控。
接上面的示例,我们用 GaussDB 提供的 CGroup 工具来为 A 公司的 OLTP 业务、报表业务以及其他低优先级业务分别创建控制组,CPU 分配比例为 50%、30%与 10%。
执行如上命令就代表我们成功创建了 3 个控制组,之后可以在创建资源池时指定该控制组名称。绑定资源池的用户所发起的作业就会收到控制组对应 CPU 份额的管控。
CGroup 管控 CPU 有两个问题需要注意:
一是,如果线程的 CPU 需要受 CGroup 管控,那么需要执行 CGroup 的系统 API 来为线程绑定对应的 CGroup,该操作较为耗时;
二是,CGroup 的 CPU 管控效果,在线程数与 CPU 成比例的情况下,管控效果最佳。
基于这些问题 GaussDB 提出了线程组的概念,每一个资源池对应一个线程组,线程组里的线程都绑定了该资源池所对应的 CGroup。同时,GaussDB 会将每一个线程组的线程数量调整到与对应 CGroup 的 CPU 份额一致。具体可见下图:

每一个用户发起的作业都会被分发到对应的线程组里的线程来执行,由于线程已经绑定了对应的 Cgroup 节点,所以操作系统会在线程调度时完成 CPU 管控。
GaussDB 提供两层用户机制,绑定 Class 控制组的资源池称之为组资源池,对应的用户为组用户,绑定 Workload 控制组的资源池称之为业务资源池,对应的用户为业务用户。组用户一般对应一个部门,而业务用户对应这个部门的不同的业务。业务资源池的各个资源维度的资源份额会不会超过所属组资源池的份额,从而达到两级资源管控的目标。
CPU 管控也提供名称为 session_respool 的 GUC 来限制单个会话的 CPU 不超过对应资源池的 CPU 上限。
内存管控
GaussDB 提供动态内存与共享缓存的管控,创建资源池时可以指定 max_dynamic_memory 与 max_shared_memory 来分别完成动态内存与共享缓存的阈值设置。
动态内存管控并没有更改其原有的内存资源分配机制,仅在分配内存之前增加一个逻辑判断层,对多分配出的内存进行记账,通过检查该记账值是否达到允许使用的内存上限来完成内存的管控。当动态内存超过上限时,作业申请内存会失败。作业退出时,该作业已申请的内存会进行释放来保证其他作业可以正常执行。同理,当作业使用的共享缓存超过资源池的管控上限时,再次申请共享缓存,需要先释放自己已经占用的共享缓存,比如 BufferPool,作业申请页面时,会对自己已经占用的页面进行淘汰,淘汰之后空余出来的页面供自己继续使用。
GaussDB 除了用户粒度的内存管控外,也提供 session_max_dynamic_memory 与 query_max_mem 两个 GUC 参数来完成会话级与语句级动态内存的管控,当一个会话或者语句所使用的动态内存达到 GUC 的阈值时,作业申请内存失败。
IO 管控
GaussDB 的磁盘读写 IO 都由后台线程完成,该线程无法区分页面属主,只是按照时间顺序依次落盘,无法针对不同用户管控不同的 IO 使用。基于此,考虑 IO 管控功能采用逻辑 IO 统计方式,对用户或者会话的读写 IO 进行管控限制,在工作线程和共享缓存之间增加了逻辑 IO 计数,对于行存表来说每 6000(可通过 io_control_unit GUC 进行修改)行算做一次 IO,当一秒产生的读写 IO 请求数超过资源池设置的阈值时,则将该 IO 请求加入到后台线程的一个等待队列里,后台线程将对等待队列里的这些 IO 请求进行监控,当其等待时间符合条件时,将这些 IO 请求从等待队列中唤醒。
GaussDB 支持两种模式的 IO 资源管控,上线数值模式是通过设置固定的触发 IO 次数的数值,进行 IO 资源控制;优先级模式是指在当前磁盘长时间使用率达到 95%以上,所有作业都无法达到上线数值模式时,用户可通过该模式进行 IO 控制,控制该作业原本触发 IO 的优先级比例,优先级包含三挡:High、Medium 与 Low。
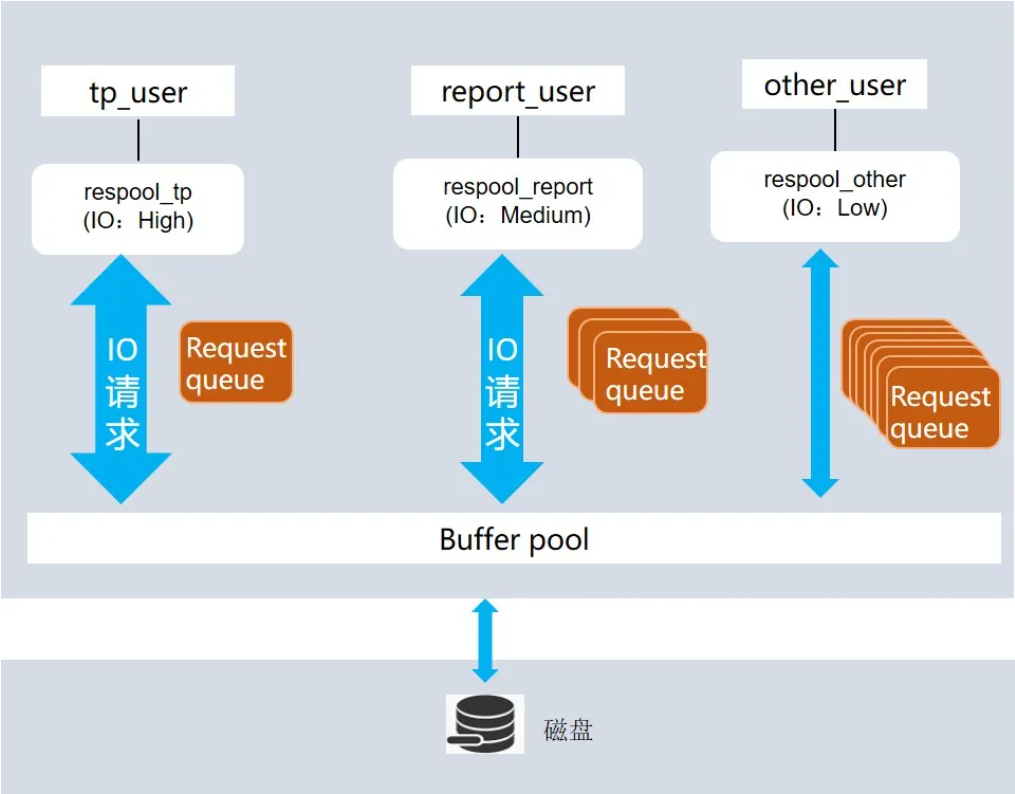
接上面的示例,我们为 A 公司的 OLTP 业务、报表业务以及其他低优先级业务分别创建资源池,IO 权重分别设置的为 High、Medium 与 Low。那么,OLTP 业务能使用 50%的 IO 请求向 BufferPool 中读取或写入数据,少量的 IO 请求会进入等待队列等待;报表业务能使用 20%的 IO 请求向 BufferPool 中读取或写入数据,较多的 IO 请求会进入等待队列等待;其他低优先级业务能使用 10%的 IO 请求向 BufferPool 中读取或写入数据,较多的 IO 请求会进入等待队列等待;后台监控线程会周期性的遍历 IO 等待队列,唤醒等待时间符合要求的 IO 请求从 BufferPool 读取或写入数据。
GaussDB 除了支持用户粒度的 IO 管控外,也支持通过设置会话级 GUC 参数 io_limits 与 io_priority,来完成指定会话上允许作业的 IO 管控。
连接数与并发管控
GaussDB 提供基于资源池的连接数管控与并发管控,创建资源池时可以指定 max_connections 与 max_concurrency 来分别完成连接数与并发数的设置,可以使用如下 SQL,为前面示例 A 公司的三个业务对应的资源池完成连接数与并发数管控:
如上 SQL 执行成功后,实时生效。A 公司 OLTP 业务的连接数与并发数不受限制,只有集群有资源它都可以使用到;报表业务的最大连接数为 200,其他低优先级业务的最大连接数为 100,当这两个业务建立的连接数超过该值时,GaussDB 内核会自动拦截,报当前连接数不足,链接失败;报表业务的最大并发数为 100,其他低优先级业务的最大并发数为 50,当这两个业务同时发起的作业数超过该值时,超出的作业将会进入等待队列,直到已有的作业完成之后 GaussDB 才会将其唤醒继续执行作业。
存储空间管控
存储空间管控,用于限定不同用户可以使用的空间配额,防止单用户存储空间使用过大导致整个数据库业务受阻。GaussDB 通过在创建用户时指定存储空间的大小来实现对存储资源的管控。
存储空间资源分为三种类型:永久表空间(Perm Space)、临时表空间(Temp Space)与算子下盘空间(Spill Space)。
可以使用如下 SQL,为前面示例 A 公司的三个业务对应的用户完成磁盘空间额管控。
存储空间管理支持对组用户和业务用户的存储空间管理。当业务用户对应的组用户存在空间限制时,业务用户的空间也受到该组用户的空间限制。指定存储空间的大小后,该用户在 DN 上所有的写操作会增加用户已用空间,删除操作减少用户已用空间,CN 会周期性的从 DN 获取一次已用空间总和,并对用户已用空间进行判断,超过最大值后 cancel 掉写作业(insert/create table as/copy),后面写作业报错退出。
特性演示
特性演示这里我们就简单的为大家演示一下 CPU 的管控效果,因为对业务影响最大的就是 CPU。
创建两个资源池分别设置 20%与 60%的 CPU,然后使用两个绑定了该资源池的用户开始跑业务。观测 CPU 的实际使用情况。
1. 创建控制组:
2. 创建资源池:
3. 创建用户绑定资源池:
4. 通过 Top 观察系统 CPU 状态,同时细粒度资源管控提供 gs_wlm_respool_cpu_info 函数来观察各个资源池的 CPU 实时情况。
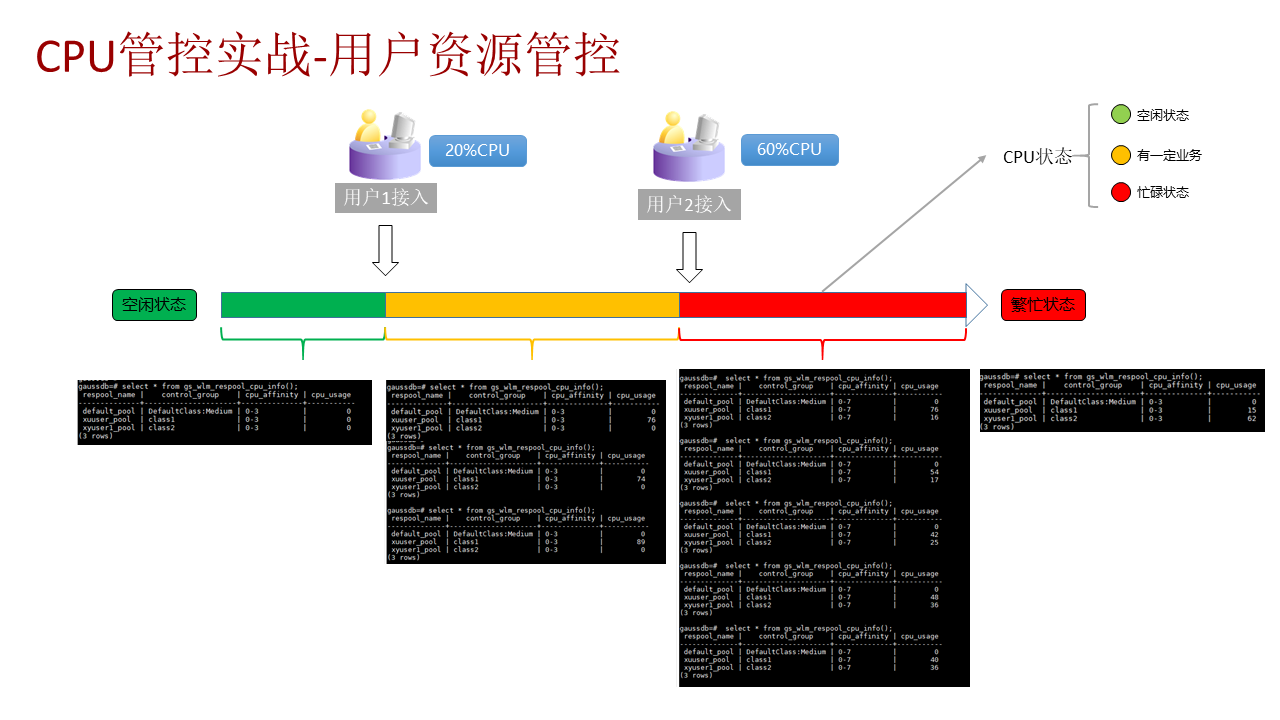
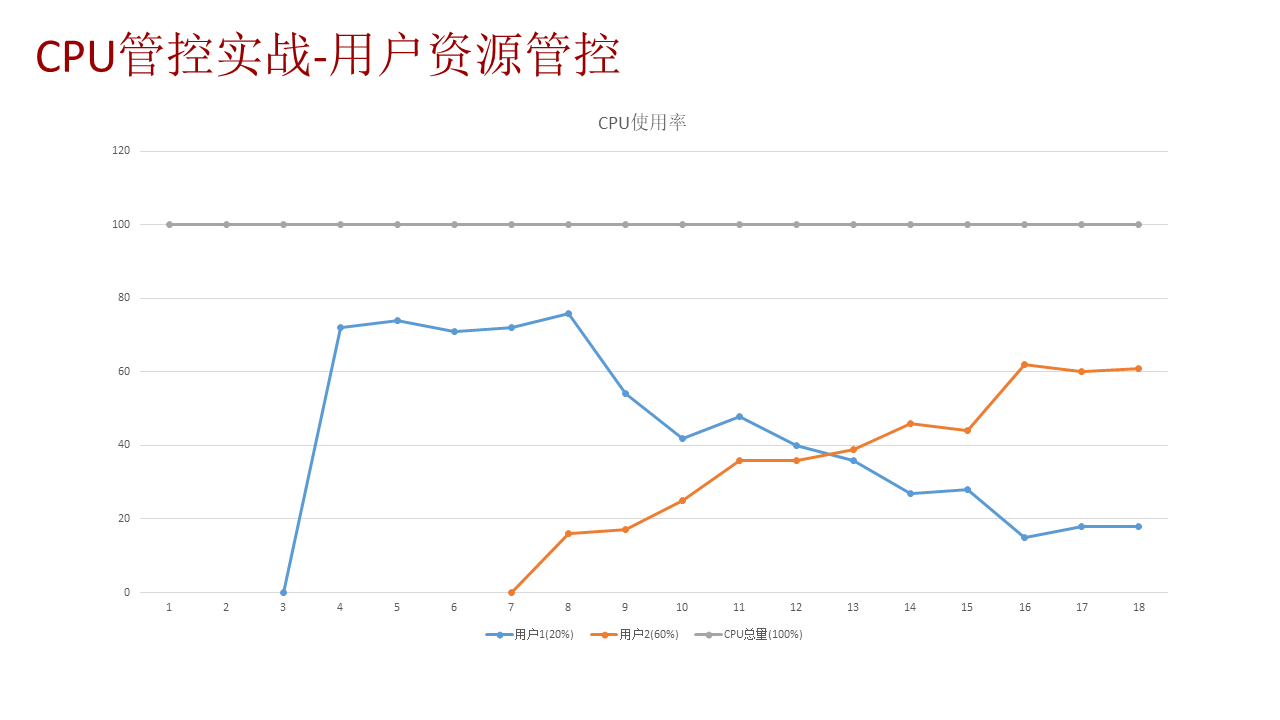
如上图,可知初期系统 CPU 是空闲状态,资源池的 CPU 监控视图也显示 CPU 使用为 0。让 user1 开始跑业务,观测可知系统 CPU 有一定业务占用,查询资源池的 CPU 监控视图显示,user1 可以使用 80%的 CPU。此时,让 user2 也开始跑业务,观测可知系统 CPU 进入繁忙状态,查询资源池的 CPU 资源监控的系统函数可知 user1 的 CPU 使用率开始下降,user2 的 CPU 使用率开始上升。
整理两个用户的 CPU 使用率并绘制曲线图如下图,可看出 user1 与 user2 的 CPU 使用率最终会平衡到 3 比 1 的状态,符合资源池对应的 CGroup 控制组里设置的 20%与 60%的比例,达到了 CPU 管控的效果。
总结
细粒度资源管控特性目前支持集中式与分布式。分布式下的计算资源管控是各个节点独立管控自己节点的资源,存储资源管控是以集群维度来整体管控的。
细粒度资源管控作为多租户的资源隔离的底座,实现资源的精准划分与控制,并解决高负载场景下资源不足而导致集群不可服务的问题。该特性适用于数据隔离不敏感,但对不同业务有资源隔离需求的场景,如果客户对资源隔离和数据隔离都有需求的话,可以关注一下我们后面即将分享的多租数据库特性哦!
文章转载自:华为云开发者联盟

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论