
深度解读智能化编码的技术架构与实践案例

向更智能、更兼容演进。
陈高星|演讲者
大家好,我是阿里云视频云的陈高星,今天和大家分享的主题是“多”维演进:智能化编码架构的研究与实践。
本次分享分为四部分:首先是视频编码与增强方向的业界趋势,其次是对在该背景下衍生的阿里云视频云智能编码架构进行介绍,以及其中关于“多”维演进的技术细节,最后是我们对于智能编码的一些思考和探索。
01 视频编码与增强方向的业界趋势
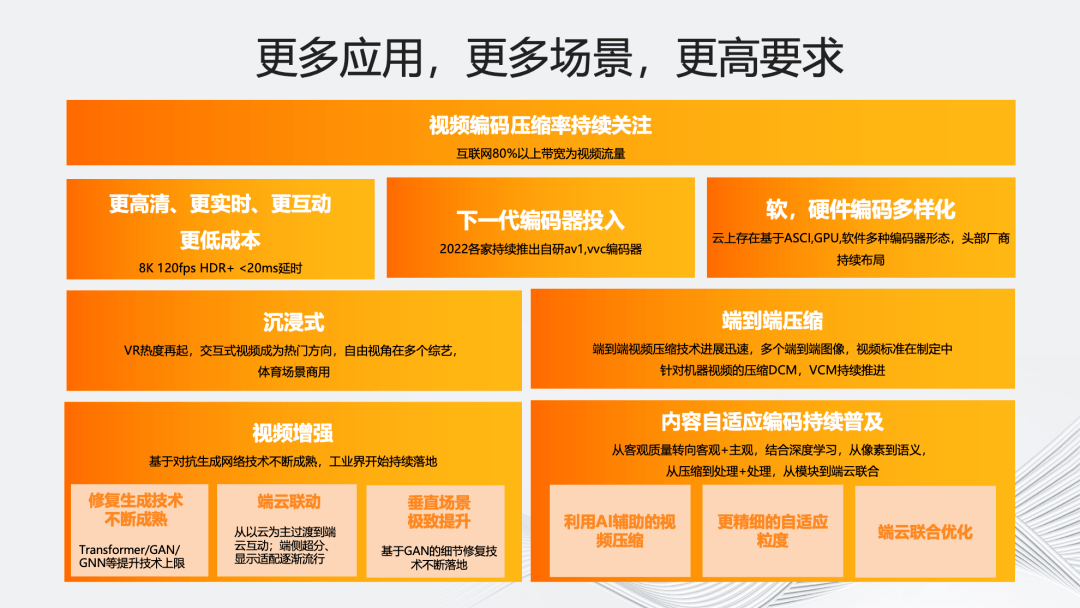
首先介绍视频编码与增强方向的业界趋势。视频技术发展的趋势始终在追求更高清、更实时、更互动、更低成本以及更智能。
过去几年直至 2022 年,虽然从“高清化”的角度围绕 AR/VR、沉浸式 8K 这些概念的话题热度有所降低,但随着 2023 年上半年苹果 VisionPro 的推出,VR 的热度再次升高。除概念化炒作外,视频“高清化”也是实实在在的趋势。举个例子,相较于 2018 年世界杯直播,可以发现新一届 2022 年直播视频的码率和分辨率明显提升,预计下一届还会进一步提升。
围绕更“高清化”的趋势,我们能看到近年各大企业都在陆续推出自研的下一代编码器,包括 266、AV1,甚至是私有标准的编码器。同时,我们也在智能编码和增强上看到不少的需求。为了降低“高清化”带来的成本压力,视频编码的软硬异构方案成为热点,包括阿里云的倚天 710 ARM 异构和多个友商在 ASIC 硬件转码方案上的布局。
从“低时延”的角度,随着 5G 基础设施的普及,毫秒级的延迟技术逐步趋于成熟,并在多个场景得到了应用和落地。阿里云视频云支持的 2022 年 6 月央视云考古节目《三星堆奇幻之旅》以及 2023 年春晚推出的央博“新春云庙会”都用到了相关的超低延时云渲染技术。在 2022 年世界杯期间,超低时延的直播 RTS 也在逐步上量。当然,以大趋势来看,目前“超低延时”直播仅在个别领域和场景是刚需,真正的爆发还需依赖更多的实际应用场景。
在更“智能化”方面,我们观察到在编码内核的基础上,工业界持续聚焦利用 AI 能力提升视频编码压缩率,包括运用视频编码和处理的结合,视频编码与质量评价结合,视频编码与 AI 生成结合,以及端云联合优化来持续提升视频编码主客观压缩率。在近年来大家关注的“视频增强”和“内容自适应编码”等领域,也能看到基于 GAN 的细节修复生成技术不断落地。
随着 2023 年 ChatGPT 和大语言模型的爆发,AIGC 成为目前的技术热点。MidJourney 等一众绘图软件的风靡,以及 Stable Diffusion 等开源模型的快速发展让我们看到了 AIGC 在图片领域的巨大实力,同时文生视频技术也在逐步兴起。
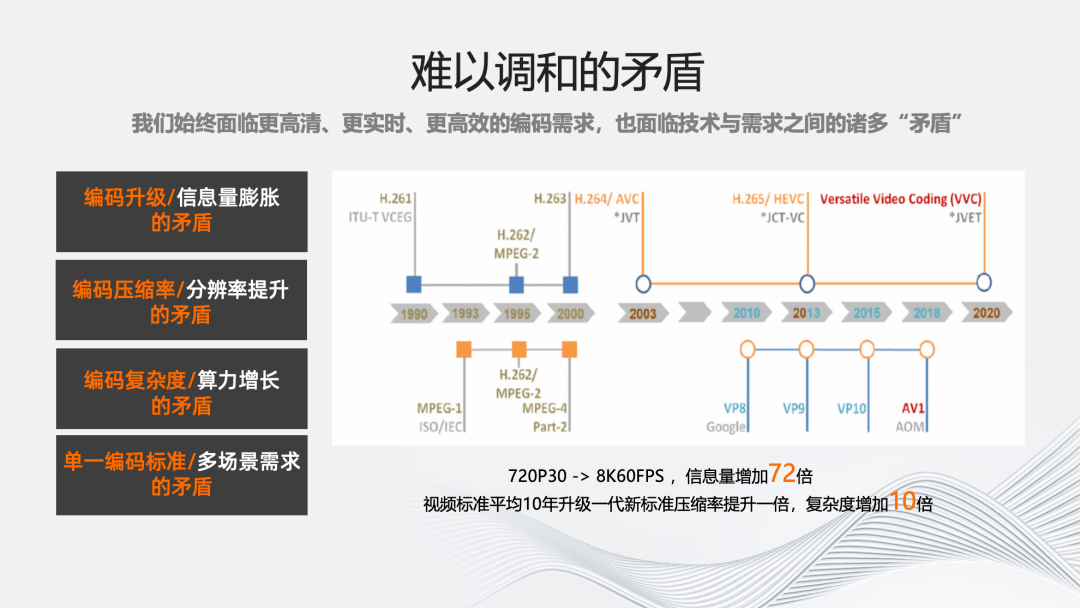
那么,伴随着更高清、更实时、更高效、更智能的编码需求,我们也面临许多技术与当前需求的矛盾。
随着 AR/VR 时代的到来,视频的分辨率、帧率以及色域都会不断的扩大,单一视频的信息量将会成倍的增加。低时延意味着对编码速度的更高要求,而 CPU 芯片处理能力不再遵循摩尔定律快速增长,清晰度、带宽、计算成本和编码速度的矛盾会越来越严重,主要体现为以下四点:
第一,编码标准升级速度远慢于视频信息量膨胀的速度。编码标准历经过去十年的发展仅带来了 50%压缩率的提升,这远远落后于视频化和体验升级带来的流量增长。
第二,新编码标准压缩率的提升速度远低于视频帧率、分辨率提升的速度。从 720P 30fps 到 8k 60fps,视频信息量将增加 72 倍,这与编码标准的发展速度出现了较大矛盾。
第三,新编码标准复杂度的增加远高于 CPU 性能增长。从 264 到 266,每一代编码标准相较上代大多增加 10 倍以上的复杂度,远高于 CPU 处理能力的增加。
第四,单一编码标准难以覆盖多种应用需求。随着视频在更多应用场景的扩展深化,如 VR 场景所需的沉浸式编码标准,以及面向机器视觉任务的 VCM 视频编码标准,更需要对编码标准进行特定场景下的优化。

在以上看似难以调和的矛盾背景下,如果想实现“鱼与熊掌兼得”,以下五个问题值得讨论。
首先,除了码率和质量,视频编码还可以关注哪些指标?例如不同内容的质量稳定性,保证序列级或者是序列片段,甚至是序列到 Gop 之间的质量稳定性,从客观到主观上,以及从资源消耗的角度去考虑编码复杂度的稳定性。
第二,如何用好现有的编码标准? 现有的各种标准,例如前述的 VR 沉浸式标准、 VCM 等,虽然具有开源代码,但从多年来 MSU 比赛的结果可以看到,它们还存在很大优化空间。因此,研发多标准的编码器也是业界一直关注和研究的方向。
第三,视频编码标准本身覆盖不到的维度有哪些?其实从每一代的标准来看,视频编码追求的目标都是尽可能与“源”一致,所以多数情况下纯编码器优化使用有源的客观指标作为参考标准,但这种方式对低画质场景并不适用。
鉴于编码后的视频还是为人眼观看服务的,虽然人眼主观评价较为耗时费力,但实际上它是能够给客户带来价值的方向。因此,将人眼评价引入视频智能增强来提升画质,也是我们的主要研究方向之一。
第四,在编码标准上,现有标准对视觉冗余的挖掘和场景自适应能力还有不足。现有标准其实只定义了大概的工具集以及解码器,但是如果能够引入多级的自适应编码,进一步挖掘各个模块之间的“耦合”能力,实际上可以进一步提升编码器的质量上限。
第五,如何打破资源堆叠,置换视频压缩效率提升的技术思维惯性。从复杂度的角度,其实我们不用单纯从硬件角度考虑,例如:仅通过硬件资源的堆叠的实现编码普惠的效果。我们可以通过多平台的支持,比如与底层架构的深度耦合或者将部分模块硬化的方式,兼顾软件的“灵活性”和硬件的“高效性”,达到算法普惠化。
因此阿里云视频云针对以上五个问题的解法就是右侧的五大“多”维。
02 智能编码架构介绍
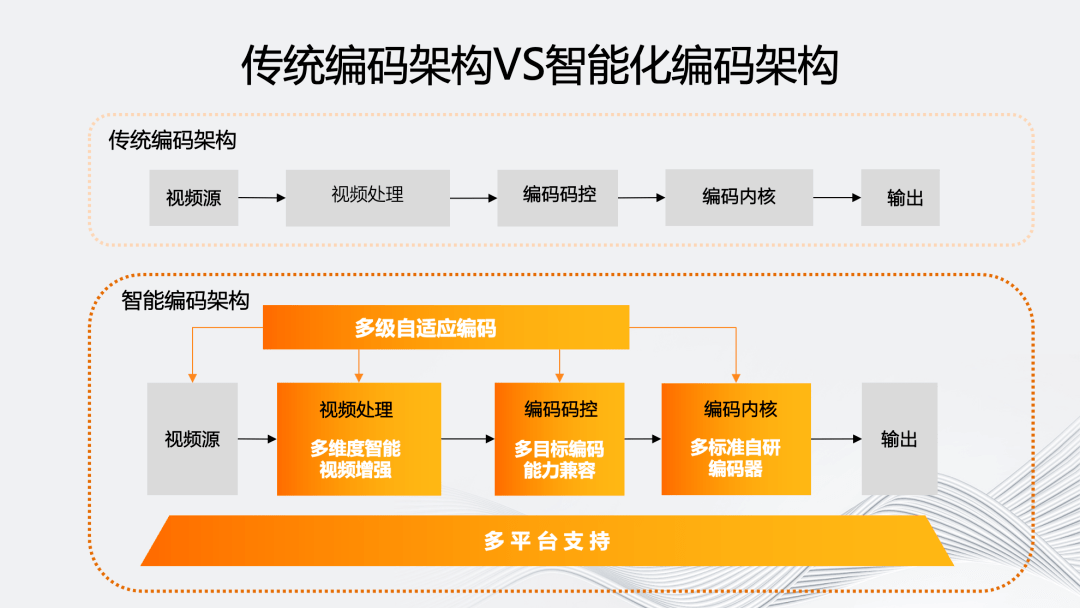
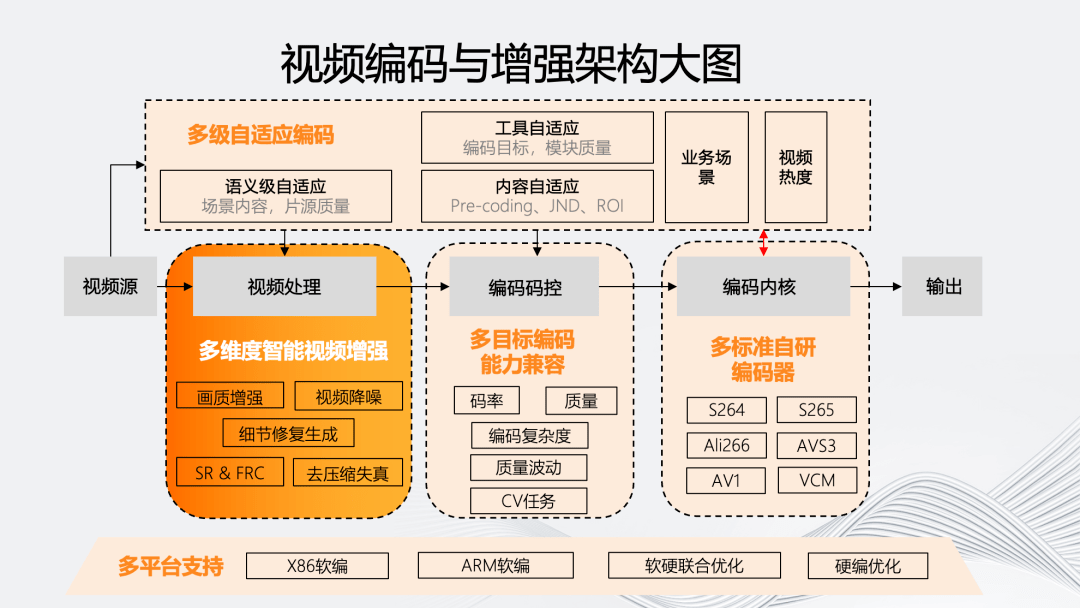
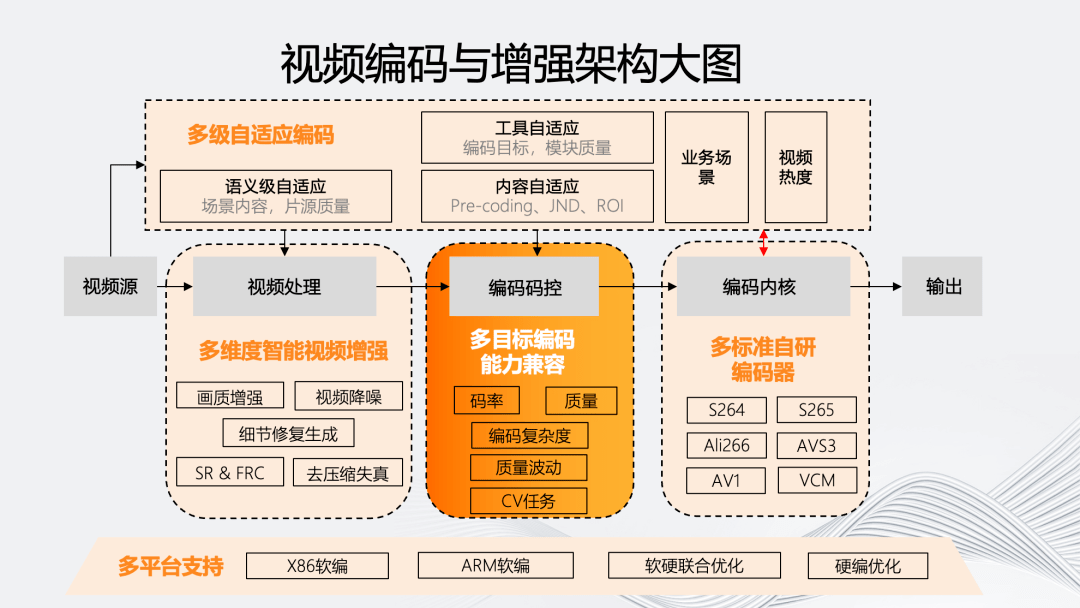
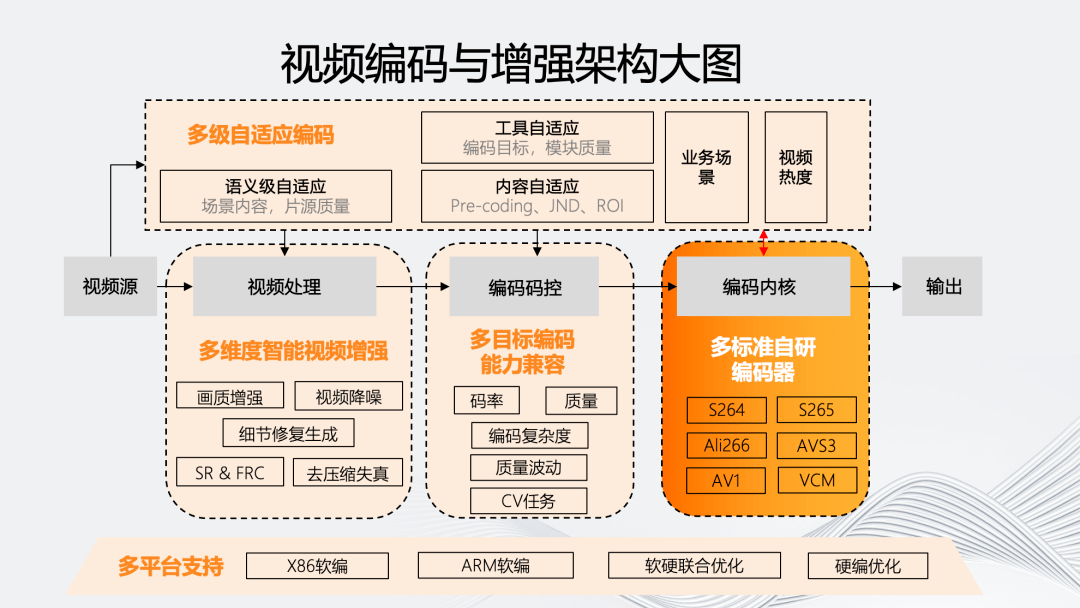
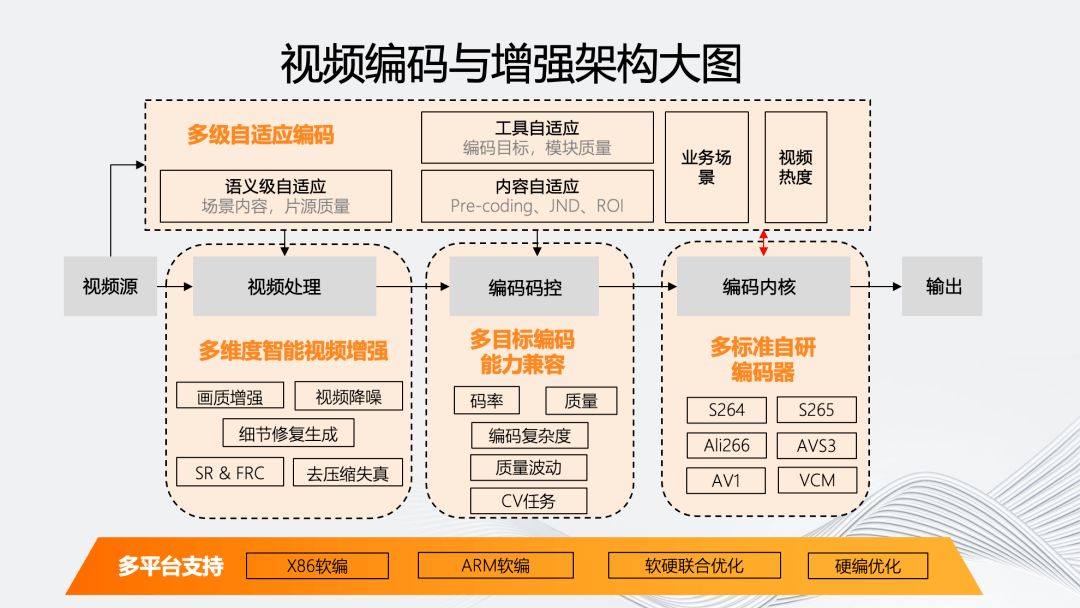
如图所示,我们的智能编码架构主要体现在五个维度。
传统编码架构的编码流程是从视频源开始,通过可选的视频处理模块进入编码的码控和内核部分,然后输出码流。
智能编码架构最显著的特点是“多级自适应编码能力”。它会对视频源进行分析,基于源评估编码流程中的处理、码控、内核等环节对于最终输出的影响,自适应决策模块内部的参数和工具组合。
同时,为了实现多级自适应编码,我们在视频处理、码控和内核上提供了多方位的编码工具和能力。最后,这个编码架构需要能够自适应的模块化,使其能够自适应地从软编到不同硬编平台。
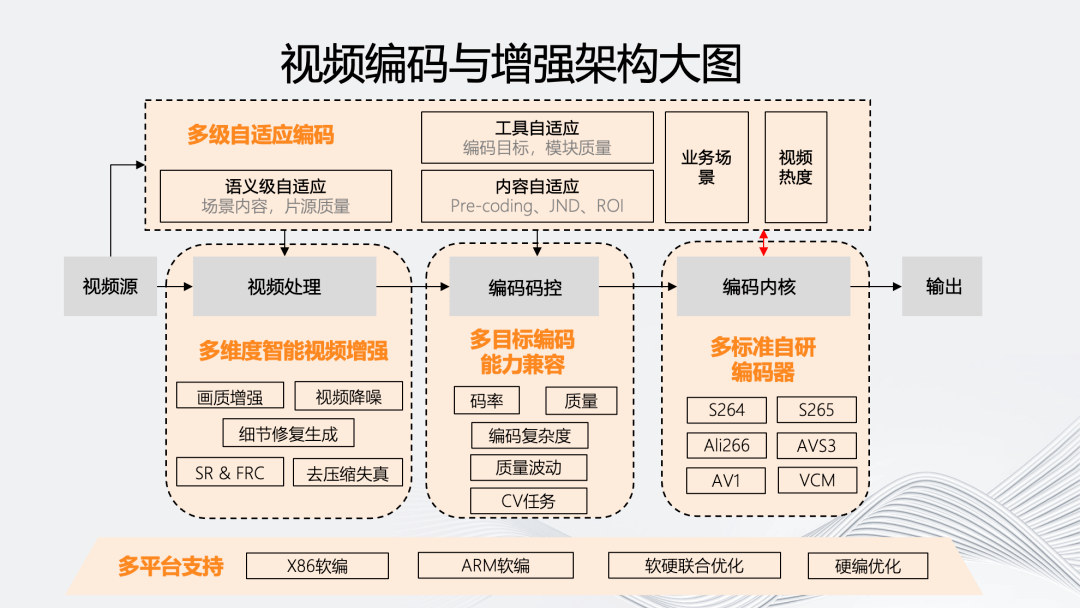
五个维度具体的原子能力如上图所示。多级自适应编码除业务场景和视频热度等分类外,还包括基于场景内容和片源质量的语义级自适应;而内容自适应则包含:基于不同编码目标的前处理 Pre-coding、以及基于人眼的 JND、ROI 等;工具自适应则是联合各个编码模块,包括码控和内核模块。
在视频处理方面,“多”维智能视频增强包括画质增强、视频降噪、细节修复生成、去压缩失真以及时域和空域的 SR 和 FRC 技术。
在编码码控上,多目标编码能力兼容在除码率、质量外,还包括针对目标编码复杂度、质量波动,以及一些 CV 任务的多目标编码兼容。
在内核上,我们有自研的多标准编码器,覆盖 264、265、266、AVS3、AV1 以及 VCM 编码器。
在多平台支持方面,我们的架构能够支持从软编的 X86、ARM 架构到部分使用硬编的联合优化平台。
03 智能编码架构的“多”维演进
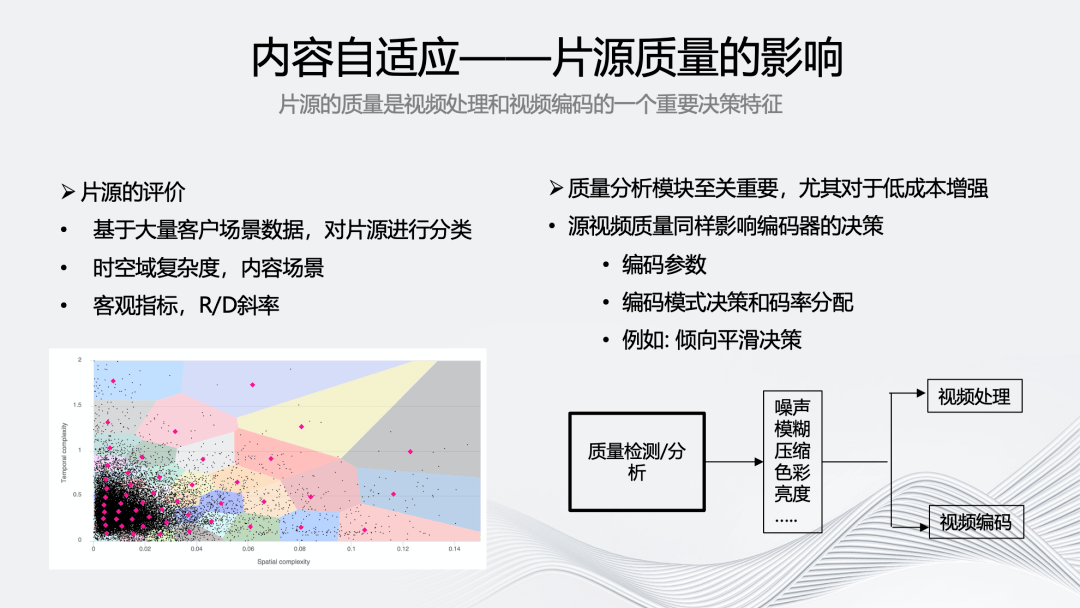
接下来,将对智能编码架构的“多”维演进进行详细介绍。首先是多级自适应编码,它的关键是基于片源质量的内容自适应,因为片源质量是视频处理和编码非常重要的决策特征。
我们基于大量客户场景数据,对片源进行多个维度的分类,除了片源的语义级质量之外,还有如上图所示的对时空域复杂度的评价,考虑编码影响进行 R/D 斜率分析,以及针对序列级中的不同序列进行智能的码率分配。
质量分析模块至关重要,在视频质量方面,充分了解视频是否有噪声、压缩或者传输带来的质量损失对后续的处理和增强将起到关键指导作用。特别是在需要使用一些低成本的增强和编码方案时,我们很难用一个模块去自适应处理所有的质量退化。因此,加入质量分析模块可以帮助我们更好的获取编码的质量上限。对于质量好的源,能有少量或者适中的增强效果。对于质量差的源,可以提升更多的质量。
另外,视频源的质量也会影响编码的决策。如果视频源的某一片段比较复杂,那在低码率的情况下很可能会出现大量的“块效应”,因此在该场景下我们会倾向于分配更多的码率。
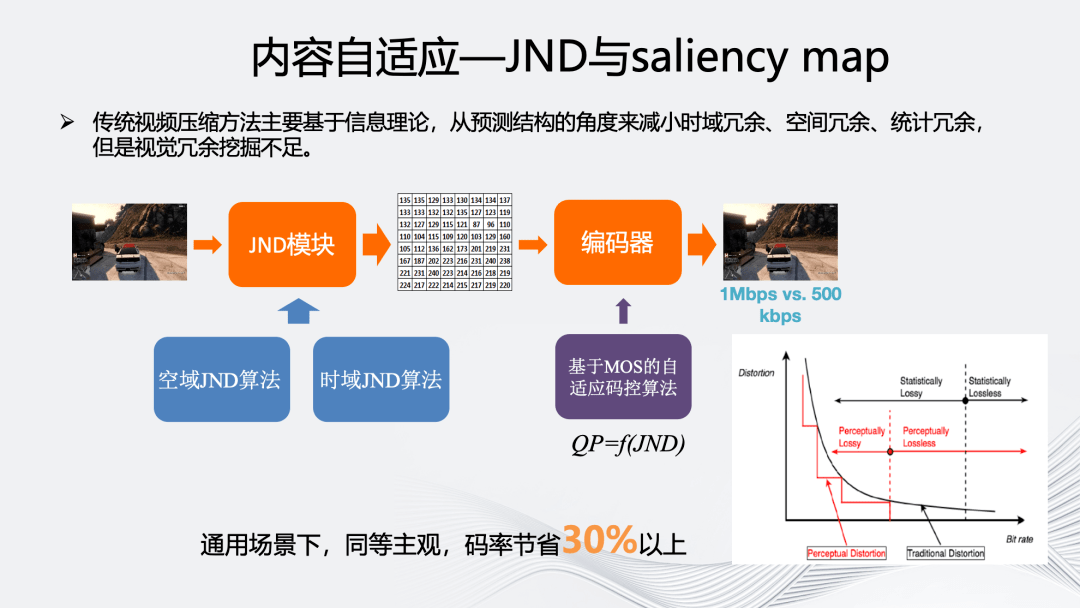
内容自适应的另一部分是基于人眼的 JND 和 saliency map。JND 对工业界来说是一个非常重要的方向。传统的视频编码是基于信息论的,它从预测结构的角度减小时域冗余、空间冗余、统计冗余等的冗余,从而实现对视频的压缩,但对视觉冗余的挖掘还远远不够。
JND 的基本原理如上图所示,传统视频编码使用的 RDO 曲线是连续的凸曲线,但人眼实际感知到的是非连续的阶梯状线。如果利用阶梯状曲线替换凸曲线,在相同失真的情况下可以使用更少的码率。
传统的 JND 方案分为“自顶向下”和“自底向上”两种方式。我们更多选择“自底向上”方式,对视觉皮层的视觉特征来进行表征,如颜色、亮度、对比度、运动等方式。从空域上考虑亮度掩蔽、对比度掩蔽,从时域上考虑基于运动的掩蔽。
我们会引入深度学习方法预测 JND 模块对人眼主观的影响,然后结合编码内部的码控模块计算当前每一块可以进一步扩大量化步长的空间。目前,我们的 JND 模块在通用场景,同等主观下,能节省 30%以上码率,在一些垂直场景下甚至可以节省 50%以上。

除了 JND, 挖掘人眼视觉冗余的另一个重要技术就是 saliency map。我们在 saliency map 上布局了两个方向:一是低成本的基于人脸的 ROI,为了能用在更普惠的直播以及超低时延场景,我们针对人脸开发了该工具。它结合检测与跟踪算法,对于检测到的人脸区域综合 JND 以及周围的像素块进行调整,保证在提高主观画质的同时降低 ROI 区域和非 ROI 区域的边界感。
二是 saliency map 技术,如上图展示的一些体育场景以及 UGC 场景。我们利用眼动仪采集时域注意力等信息,通过采集两千多个视频,收集 10 亿以上的注视点,构建了一套人眼注意力模型。
上图中突出显示的区域代表了人眼主要关注的区域,它会随着时间的变化发生一些变动。该模型与编码器相结合,针对不同的区域进行码率分配。在连续观看下,能够提升主观画质。
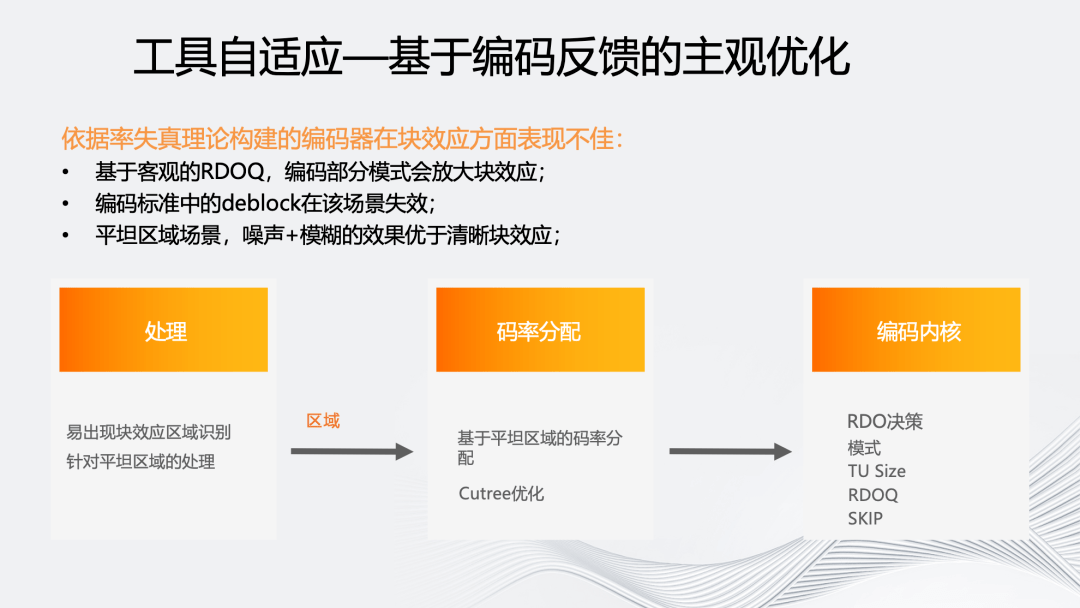
接下来介绍被应用于编码器内部的工具自适应技术。我们认为传统的率失真理论是基于客观的,在多数低码率的情况下会放大块效应。如低码率下选择 skip 或 DC 模式很容易出现块效应。
虽然编码标准中存在诸如 deblocking filter 等工具,但是它的强度不足以弥补实际产生的块效应。从主观上看,如果针对平坦区域增加一点噪声和模糊,带来的主观感受反而更好。
我们采用两种方式进行了主观优化,一种是单向的,基于源内容以及编码后信息预测,该区域后续是否容易出现块效应,并对后续区域进行针对性码率保护,同时也会区分块效应是片源自带还是编码导致的。第二种是针对点播场景的 2pass 编码,可以依据 first pass 的实际编码结果进行二次处理。

上图展示了主观对比结果,并排对比图中右侧为开启工具后效果,可以看到块效应在人脸区域明显减少,这一帧的码率大概增加了 5%。由于从编码器码控角度,保证序列整体码率不变的提升上限有限,可以看到图中人体的手臂位置还较为模糊。
对于多维度视频增强部分我们将主要介绍自研的窄带高清品牌。阿里云早在 2015 年便已经提出了“窄带高清”概念,在 2016 年正式推出窄带高清技术品牌并进行产品化。目前通过多轮筛选和讨论,沉淀为窄带高清 1.0 和窄带高清 2.0 两个方向。
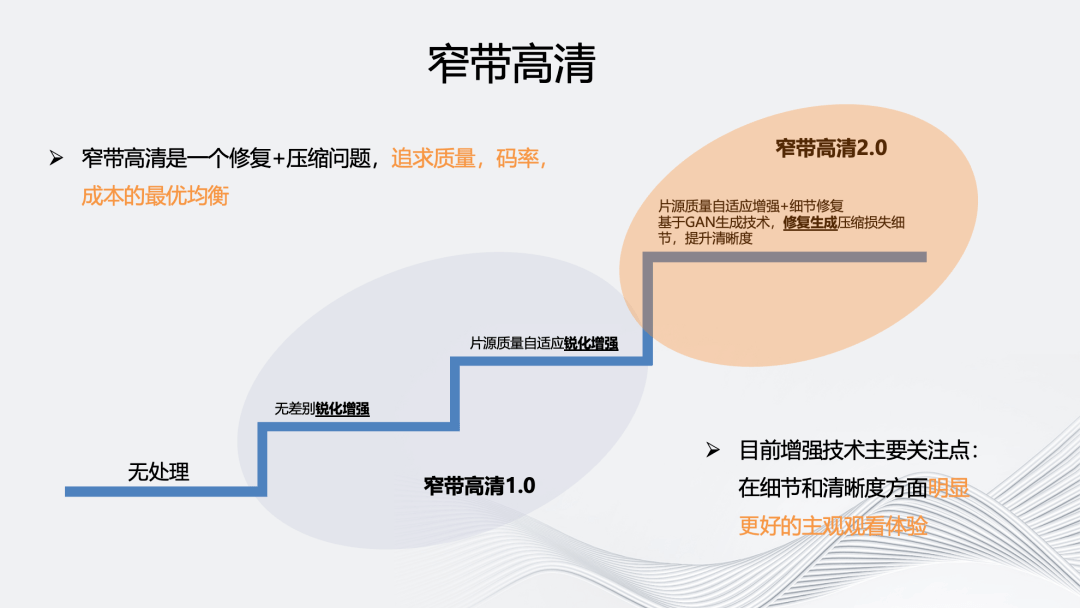
窄带高清 1.0 是均衡版,主要作用是使用最少的成本实现自适应内容处理和编码,在节省码率的同时实现画质的提升。它会充分利用编码器内的信息帮助视频处理,即用成本很小的前处理方法实现低成本的内容自适应。
窄道高清 1.0 在视频处理上分为两个细分档位,一种是计算复杂度相对较低的无差别锐化增强。另一种,会基于片源质量进行 de-artifacts 和 deblur 自适应锐化增强。对质量较差的片源,相应的 deartifacts 权重较大。
窄带高清 2.0 经过多次技术选型,最终定义为空间维度细节修复,解决视频生产链路造成的画质损失,即多次编码压缩导致的画质损失。在编码上也会增加更多自适应能力,包括 JND、ROI、SDR+等等。

上图展示了窄带高清 2.0 的增强效果。常规 CNN 模型对编码压缩造成的块效应、边缘锯齿、毛刺等 artifacts 有比较好的平滑作用,可以使整个画面看起来更加干净,但会造成一种磨皮效果。窄带高清 2.0 选择基于 GAN 的细节增强,以提升画面质感,如眼角、嘴唇等等。
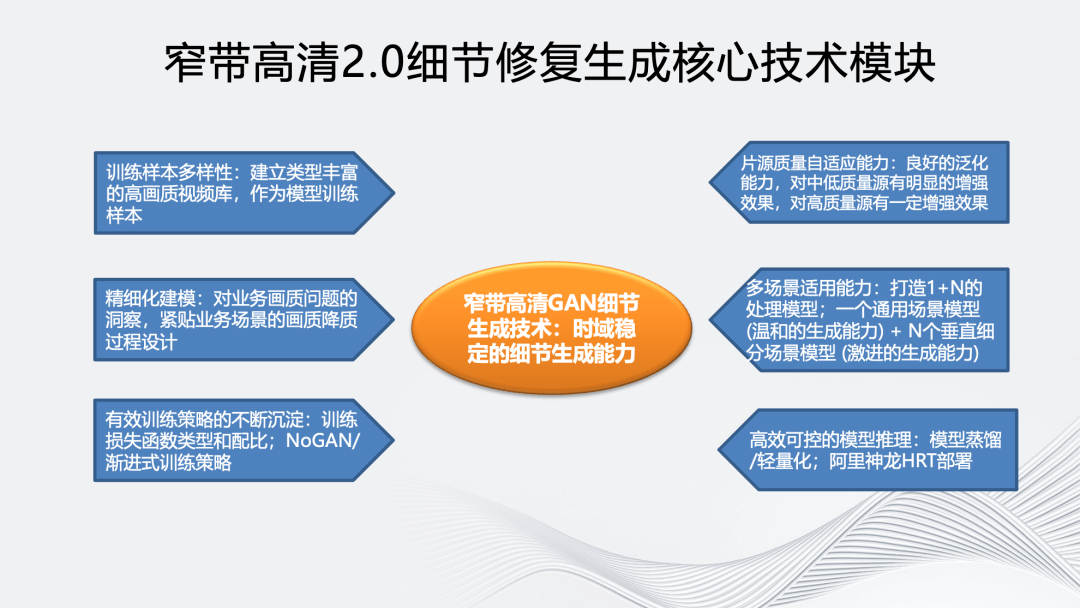
窄带高清 2.0 细节修复生成核心技术模块包括以下 7 个方面:
一是训练样本多样性:建立类型丰富的高画质视频库作为模型训练样本,训练样本包含多样的纹理特征,对 GAN 生成纹理的真实感有很大的帮助;
二是通过精细化建模不断优化训练数据,基于对业务场景面临的画质问题进行深入分析,贴合场景不断优化训练样本,以达到精细化建模效果;
三是探索更有效的模型训练策略,包括训练损失函数配置调优,例如 perceptual loss 使用不同 layer 的 feature 会影响生成纹理的颗粒度,不同 loss 的权重配比也会影响纹理生成的效果。我们在模型训练过程使用了一种名为 NoGAN/渐进式训练策略。一方面可以提升模型的处理效果,另一方面对模型生成效果的稳定性也有帮助。
四是为了提高模型对片源质量的自适应能力,我们在训练输入样本质量的多样性和训练流程方面做了很多工作。最终对中低质量的源有明显的增强效果,对高质量源有中等增强效果。
五是根据学术界的经验,处理目标先验信息越明确,GAN 的生成能力越强。因此为了提升 GAN 对不同场景的处理效果,我们采用了一种 1+N 的处理模式,即一个具备温和生成能力的通用场景模型+N 个具备激进生成能力的垂直细分场景模型,如足球的草地细节、动画场景的边缘线条、综艺场景的人像。
六是高效可控的模型推理,经过模型蒸馏/轻量化,同时基于阿里云神龙 HRT GPU 推理框架,GAN 细节生成模型在单卡 V100 上,处理效率可达 1080P 60fps。
七是为了保证 GAN 模型生成效果的帧间一致性,避免帧间不连续带来的视觉闪烁和编码负担,阿里云视频云通过与高校合作,提出一种即插即用的帧间一致性增强模型。
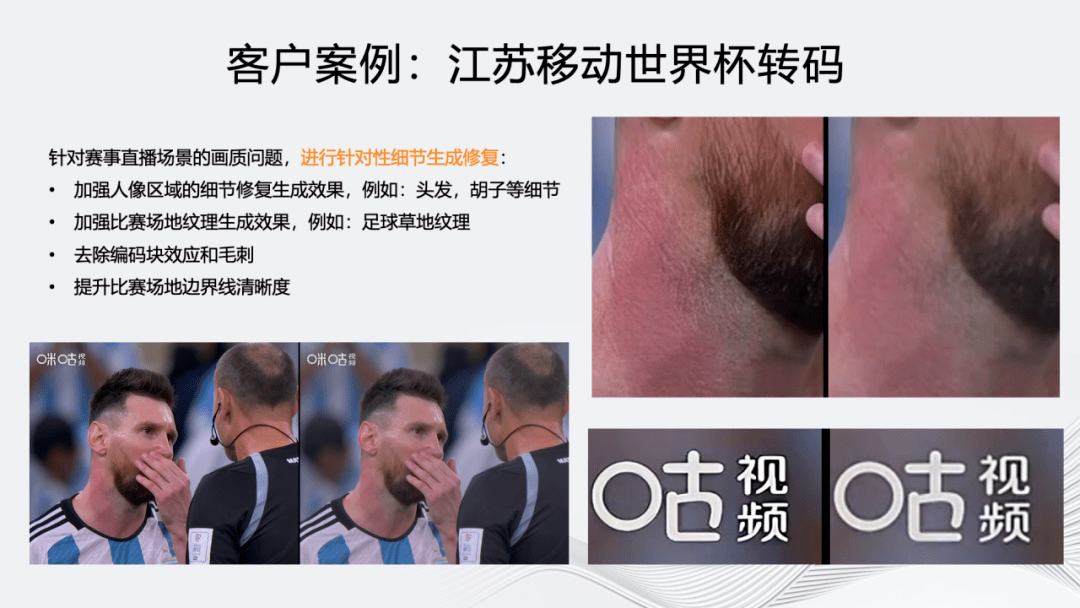
接下来介绍几个具体的客户案例。第一个是 2022 年江苏移动的世界杯转码。针对该场景主要用到了前述的细节修复生成能力。对比图左侧为经过修复生成并编码后的效果,右侧为片源。放大后可以看到,人体毛发细节和文字边缘锐度都获得了明显提升。
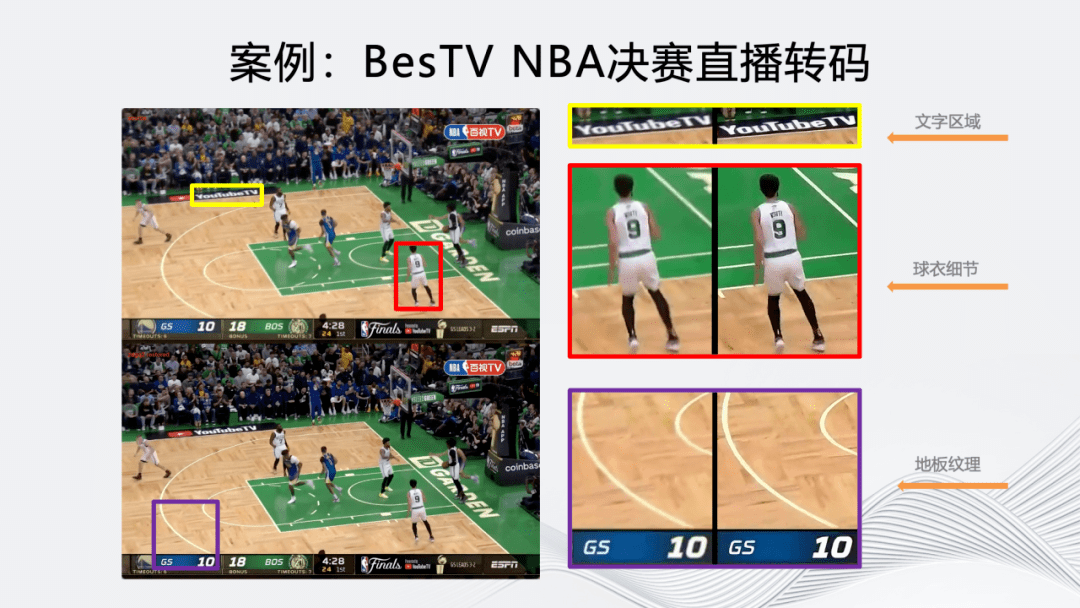
同样,在 BesTV 的 NBA 直播转码上也能达到类似效果。对比窄高编码后画面和片源可以看到,文字区域、球衣细节和地板纹理更加丰富。

除了体育场景外,我们还支持了《理想之途》演唱会场景,它的特点是片源质量较差(现场是暗场,伴随着灯光、烟雾和场景的频繁切换),可以看到画面有明显的块效应。针对该场景,除了窄带高清 2.0 外,我们同时使用了人像定制模板和基于语义的分割引导技术对图像进行还原。
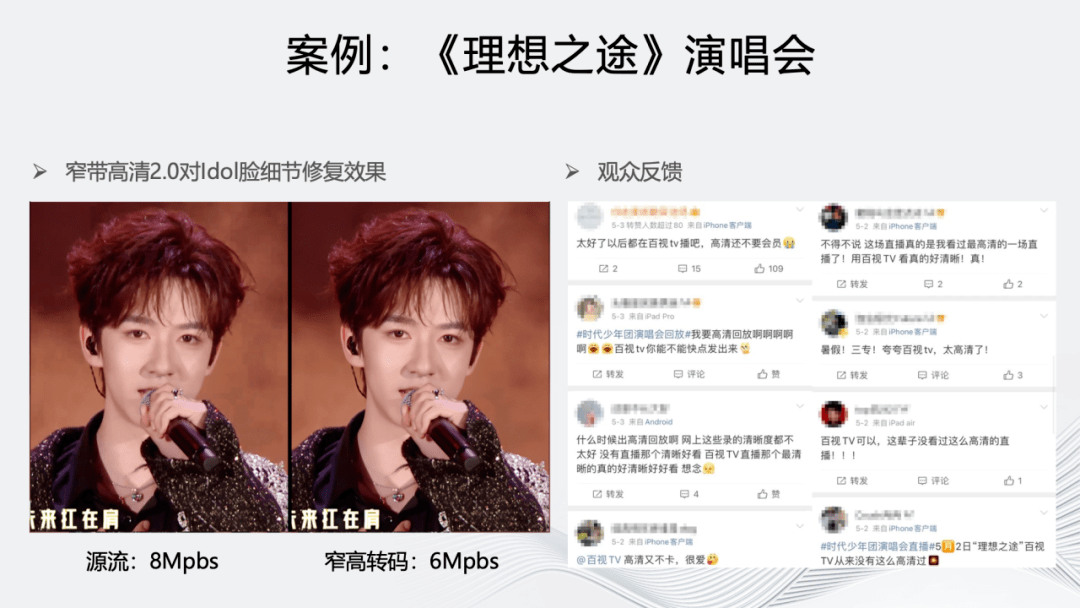
上图展示了转码图与原图的效果对比,可以看到人物背后烟雾的块效应得到改善,人脸、毛发等细节也得到提升。右图是观众反馈,对直播画面的清晰度评价很高。

除了前述的体育直播和演唱会场景外,我们对一些沉浸式场景也进行了优化,例如对 VR 场景窄高采用基于 VR 视角和经纬度的 JND 和 saliency map 技术。
为了进一步优化沉浸式体验,我们还提供了能够呈现声源空间方位的空间音频技术,使用户能够在听的过程中感受到声源的变换,使实时互动从“在线”变成 “在场”。
接下来介绍多目标编码能力兼容。除了常规关注的码率和质量外,我们还考虑了目标复杂度和目标质量编码。
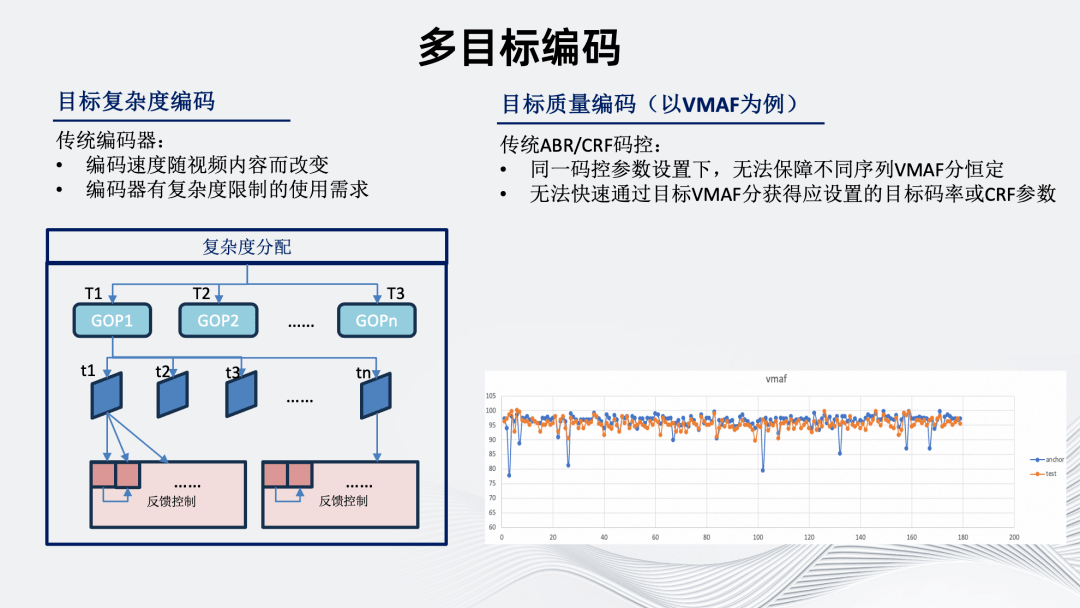
首先是目标复杂度编码。传统编码器编码速度、机器资源消耗随视频内容改变而改变,导致多数情况下编码水位相对不可控。因此在实际使用中我们对编码器也会有复杂度限制的使用需求。
复杂度分配具体从序列级到 GOP 级到帧级到块级进行反馈,反馈的内容包括编码质量、速度以及前述的一些自行分析内容。这使得简单场景下可以利用更多计算资源换取主客观质量提升。复杂场景下类似于码控 VBV 的概念,可以在避免降低主客观质量的同时限制编码复杂度。
其次是目标质量编码,在此以 VMAF 为例。传统 ABR/CRF 码控无法在同一码控参数设置下,保障不同序列 VMAF 分恒定。同时,也无法快速通过目标 VMAF 分获得应设置的目标码率或 CRF 参数。
虽然 CRF 是质量较为稳定的码控方式,但具体到某一个特定指标,不同序列的分数波动仍然较大。基于以上背景,我们开发了目标质量编码工具,右下图是工具开启前后的对比图,可以看到代表开启工具后的橙色线,不同序列间的质量分方差明显变小。
接下来介绍架构中的多标准自研编码内核。首先是我们自研的三大编码器:S264、S265 和 Ali266,每种都基于客观、主观及场景约束研发了 100+的算法,覆盖直播,点播,RTC 场景,以及云端,终端,自然场景,SCC 场景。
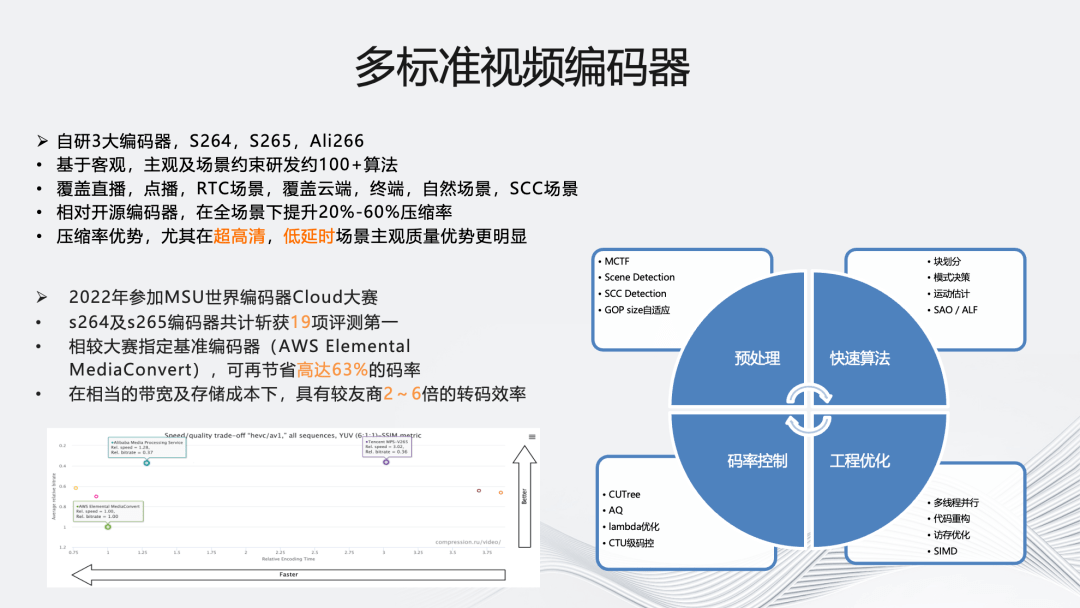
性能上,S264、S265 相对开源编码器,在全场景下可提升 20%~60%压缩率,特别是针对超高清,低延时场景进行了更深度优化。优化方式包括预处理(MCTF、Scene Detection、SCC Detection、GOP size 自适应)、快速算法(块划分、模式决策、运动估计、SAO/ALF)、码率控制(CUTree、AQ、lambda 优化、CTU 级码控)和工程优化(多线程并行、代码重构、访存优化、SIMD 优化)。
S264、S265 于 2022 年参加了世界编码器 Cloud 比赛,共获得 19 项第一,相较于大赛指定的基准编码器 AWS 可节省 63%的码率,从转码效率的角度,相较友商也拥有 2~6 倍的优势。
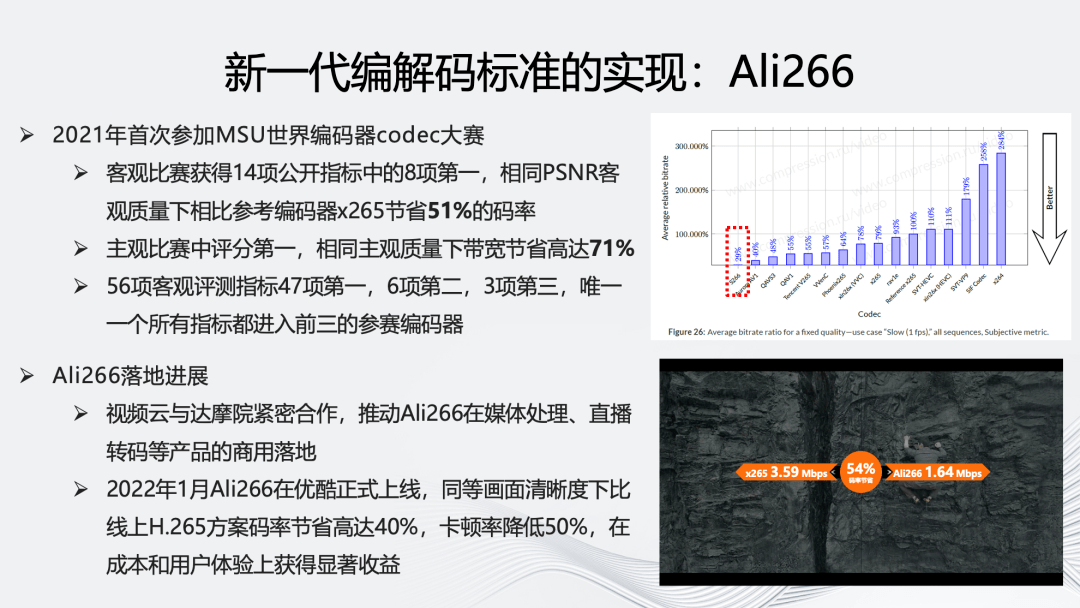
Ali266 于 2021 年首次参加世界编码器 codec 大赛,在客观比赛获得 8 项第一,相比于参考编码器 x265,在相同 PSNR 客观质量下可节省 51%的码率,同时它在主观比赛中评分第一。
在 Ali266 的落地方面,阿里云视频云与达摩院紧密合作,推动 Ali266 在媒体处理、直播转码等产品的商用落地。2022 年 1 月,Ali266 在优酷正式上线,在成本和用户体验上获得显著受益。
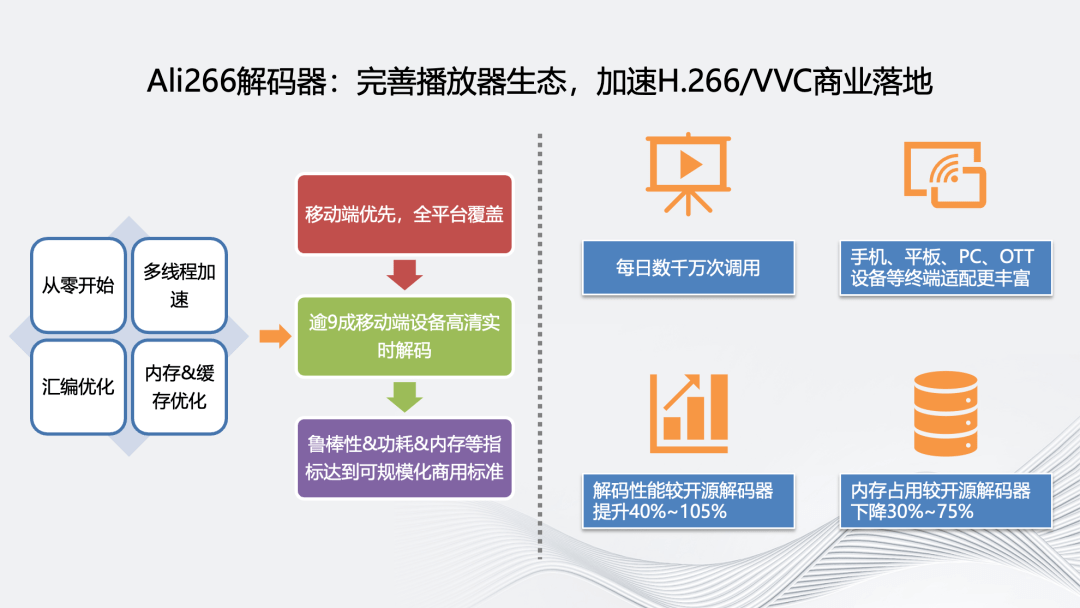
为了完善和推动 Ali266 的生态化,我们也优化了 Ali266 的解码器,方案包括多线程加速、汇编优化、内存 &缓存优化。优化后解码性能相较于开源解码器达到了 40%~105%的提升,内存占用下降 30%以上,支持超过九成移动端设备的高清实时解码。
接下来介绍关于多平台的支持。

首先,是阿里云视频云与平头哥解决方案团队合作的,基于倚天 ARM 服务器的优化。我们在倚天 710 上,主要针对 S264、S265 进行了架构的深度优化,主要包括三个方向,一是计算函数的汇编优化,使得总体性能提升 40%;二是计算函数并行优化,也实现了约 40%的性能提升;三是偏控制函数优化,将算法设计与优化相结合,再提升了 20%的性能。最终结果是,S264 和 S265 倚天相对于 C7 性能提升了 30%以上,并已在视频云点播场景大规模商用。

如图所示,展示了云渲染场景的一个案例:央博新春云庙会。它要求低时延并自带 Nvidia inc 编码器。我们通过接管该编码器的码控模块,融合自研的 JND 和基于空域特征码率分配的 AQ 算法,加上前处理增强技术,最终实现了窄高落地在云渲染场景的落地。并列图中右侧为窄高优化后的效果,可以看到实现了丰富的细节提升效果。
04 智能编码的思考和探索

最后,分享一些在智能编码上的实践和思考。首先,是我们在面对主客观优化的矛盾时,如何去定义“好”?现在的编码方向已经愈发从“客观”向“主观”靠拢。无论是以“人”为中心还是从最终的用户体验出发,视频都应该关注主观体验的。
在研发过程中,如果单纯考虑编码器优化,我们通常依赖如 PSNR、SSIM、VMAF-NEG 这样的有源客观指标。但当优化目标类似于窄高,是出于提升主观质量,那么客观指标分数的提升就不一定能反映到主观质量上。
更进一步来说,使用单一客观指标衡量视频质量也存在问题,从编码标准方面看,使用标准自带的 SAO 和 DB 工具,对 PSNR 和 SSIM 影响不大,但会导致 VMAF 分数降低;从开源软件方面看,X265 编码器的 PSY 工具能够在主观上增加一些高频细节,但对客观指标也有不良影响;我们自研的基于编码反馈的主观优化反映的客观指标同样不佳;前面提到的 JND 也是一样,明显在客观指标上反馈不好;
在前处理增强上,可以明显看到 SRGAN 中清晰而错误的纹理相较于模糊的细节主观表现更优,但 PSNR 和 SSIM 更差。
这是我们当下在编码优化中的一个困境。
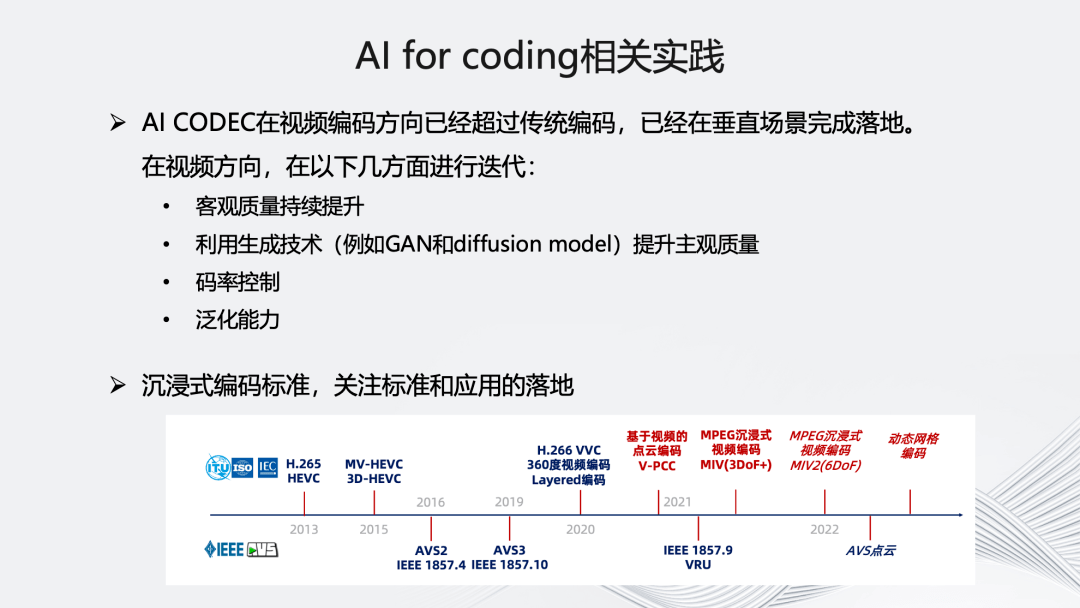
另一方面,是我们在 AI for coding 方面的一些相关实践,我们始终关注 AI Codec 在视频编码方向的发展。目前可以看到,它确实能够持续提升视频客观质量,在前处理以及编码方向能利用 GAN 以及 Diffusion Model 等生成技术提升主观质量。这也是我们正在研究的重要方向。
关于沉浸式编码标准,我们目前在持续关注基于“点云”的编码标准以及基于沉浸式的 MIV 编码标准,后续根据落地情况也会加入到多自研标准的编码器中。
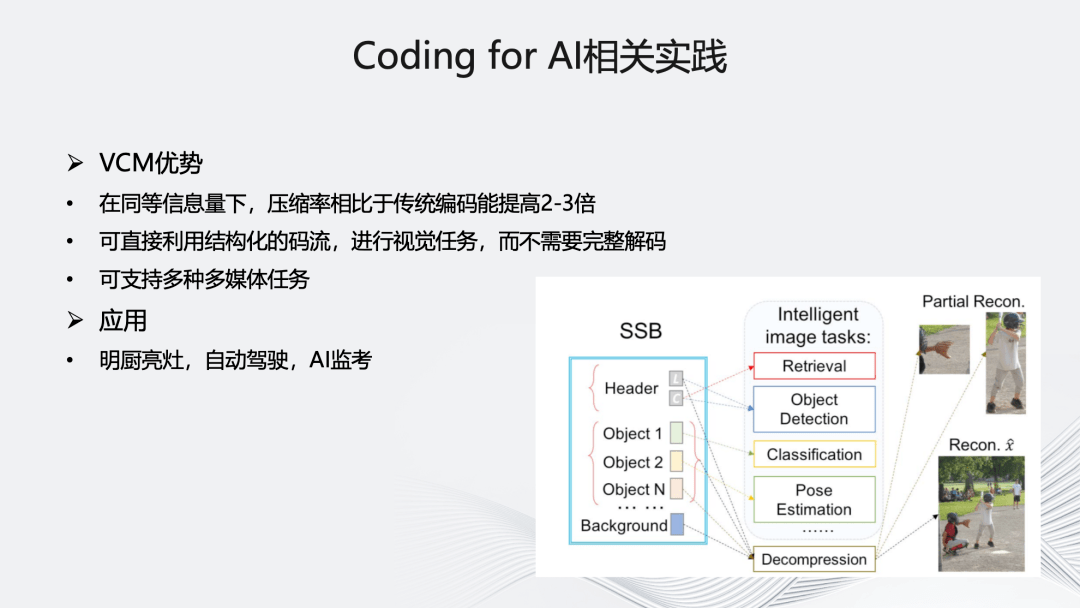
最后关于 Coding for AI,目前主要在关注 VCM,它在同等信息量下,压缩率相比传统编码能提高 2-3 倍,可直接利用结构化的码流进行视觉任务,同时支持多种多媒体任务。具体应用上,我们正在明厨亮灶、自动驾驶、AI 监考方向进行相关实践和探索。
以上就是今天的全部分享,谢谢大家!
版权声明: 本文为 InfoQ 作者【阿里云视频云】的原创文章。
原文链接:【http://xie.infoq.cn/article/b206d771b9c716a816ae93255】。文章转载请联系作者。

公众号:视频云技术 2020-10-20 加入
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。









评论