PyOD 是一个全面且易于使用的 Python 库,专门用于检测多变量数据中的异常点或离群点。异常点是指那些与大多数数据点显著不同的数据,它们可能表示错误、噪声或潜在的有趣现象。无论是处理小规模项目还是大型数据集,PyOD 提供了 50 多种算法以满足用户的需求。PyOD 的特点包括:
统一且用户友好的接口,适用于多种算法。
丰富的模型选择,从经典技术到最新的 PyTorch 深度学习方法。
高性能与高效率,利用 numba 和 joblib 实现即时编译与并行处理。
快速的训练和预测,通过 SUOD 框架实现。
1 使用说明
1.1 PyOD 背景介绍
PyOD 作者发布了一份长达 45 页的预印论文,名为ADBench: Anomaly Detection Benchmark,以及提供ADBench开源仓库对 30 种异常检测算法在 57 个基准数据集上的表现进行了比较。ADBench 结构图如下所示:
PyOD 提供了这些算法的接口类实现,具体算法对应的接口见:pyod-implemented-algorithms。同时 PyOD 对于这些算法提供了统一的 API 接口,如下所示:
pyod.models.base.BaseDetector.fit():训练模型,对于无监督方法,目标变量 y 将被忽略。
pyod.models.base.BaseDetector.decision_function():使用已训练的检测器预测输入数据的异常分数。
pyod.models.base.BaseDetector.predict():使用已训练的检测器预测特定样本是否为异常点。
pyod.models.base.BaseDetector.predict_proba():使用已训练的检测器预测样本为异常点的概率。
pyod.models.base.BaseDetector.predict_confidence():预测模型对每个样本的置信度(可在 predict 和 predict_proba 中使用)。
pyod.models.base.BaseDetector.decision_scores_:训练数据的异常分数。分数越高,越异常。
pyod.models.base.BaseDetector.labels_:训练数据的二进制标签。0 表示正常样本,1 表示异常样本。
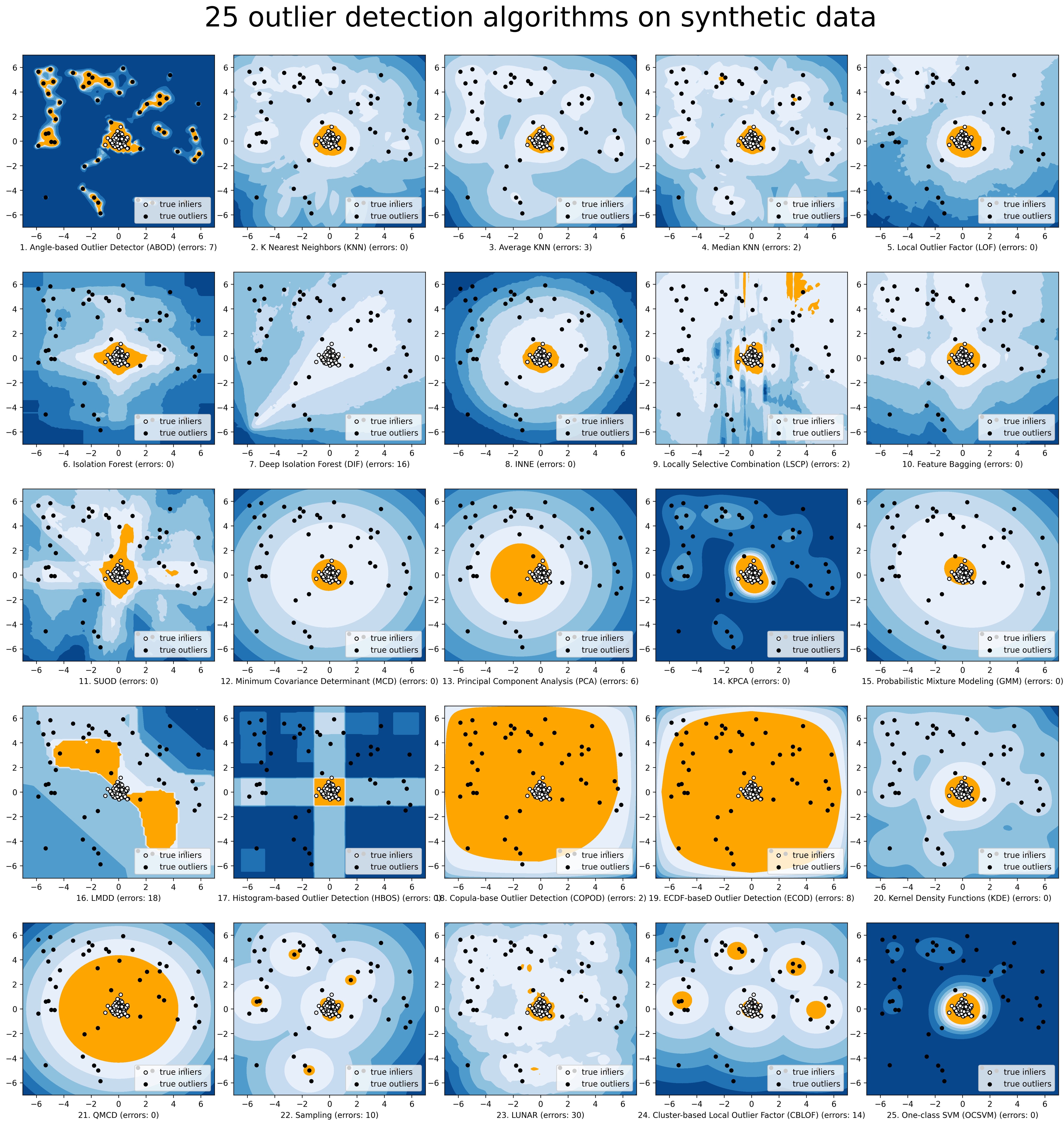
PyOD 还提供了不同算法的基准比较结果,详见链接:benchmark。下图展示了各种算法的检测结果与实际结果,并标出了识别错误样本的数量:
1.2 用法说明
1.2.1 基于 KNN 实现异常检测
本文以 KNN 为例说明 PyOD 实现异常点检测的一般流程。KNN(K-Nearest Neighbors)是一种非常常用的机器学习方法,它的核心思想非常简单直观:在特征空间中,如果一个数据点的 K 个最邻近点大多数属于某个特定类别,那么这个数据点很可能也属于该类别。
在异常检测中,KNN 算法不需要假设数据的分布,它通过计算每个样本点与其它样本点之间的距离,来确定样本点是否为异常点。异常点通常是那些与大多数样本点距离较远的点。以下示例代码展示了通过 PyOD 库创建 KNN 模型来实现异常检测:
创建数据集
以下代码创建一个二维坐标点数据集,正常数据通过多元高斯分布生成,而异常值则通过均匀分布生成。
from pyod.models.knn import KNN from pyod.utils.data import generate_data # 设置异常值比例和训练、测试样本数量contamination = 0.1 # 异常值的百分比n_train = 200 # 训练样本数量n_test = 100 # 测试样本数量 # 生成训练和测试数据集,包含正常数据和异常值,默认输入数据特征维度为2,标签为二进制标签(0: 正常点, 1: 异常点)# random_state为随机种子,保证能够复现结果X_train, X_test, y_train, y_test = generate_data(n_train=n_train, n_test=n_test, contamination=contamination, random_state=42)X_train.shape
复制代码
训练 KNN 检测器
# 训练KNN检测器clf_name = 'KNN' # 设置分类器的名称clf = KNN() # 创建kNN模型实例clf.fit(X_train) # 使用训练数据拟合模型 # 获取训练数据的预测标签和异常分数y_train_pred = clf.labels_ # 二进制标签(0: 正常点, 1: 异常点)y_train_scores = clf.decision_scores_ # 训练数据的异常分数 # 对测试数据进行预测y_test_pred = clf.predict(X_test) # 对测试数据的异常标签(0或1)y_test_scores = clf.decision_function(X_test) # 测试数据的异常分数 # 获取预测的置信度y_test_pred, y_test_pred_confidence = clf.predict(X_test, return_confidence=True) # 返回预测标签和置信度(范围[0,1])
复制代码
评估结果
from pyod.utils.data import evaluate_print # 导入评估工具 # 评估并打印结果print("\nOn Training Data:") # 打印训练数据的评估结果evaluate_print(clf_name, y_train, y_train_scores) # 评估训练数据print("\nOn Test Data:") # 打印测试数据的评估结果evaluate_print(clf_name, y_test, y_test_scores) # 评估测试数据
复制代码
On Training Data:KNN ROC:0.9992, precision @ rank n:0.95 On Test Data:KNN ROC:1.0, precision @ rank n:1.0
复制代码
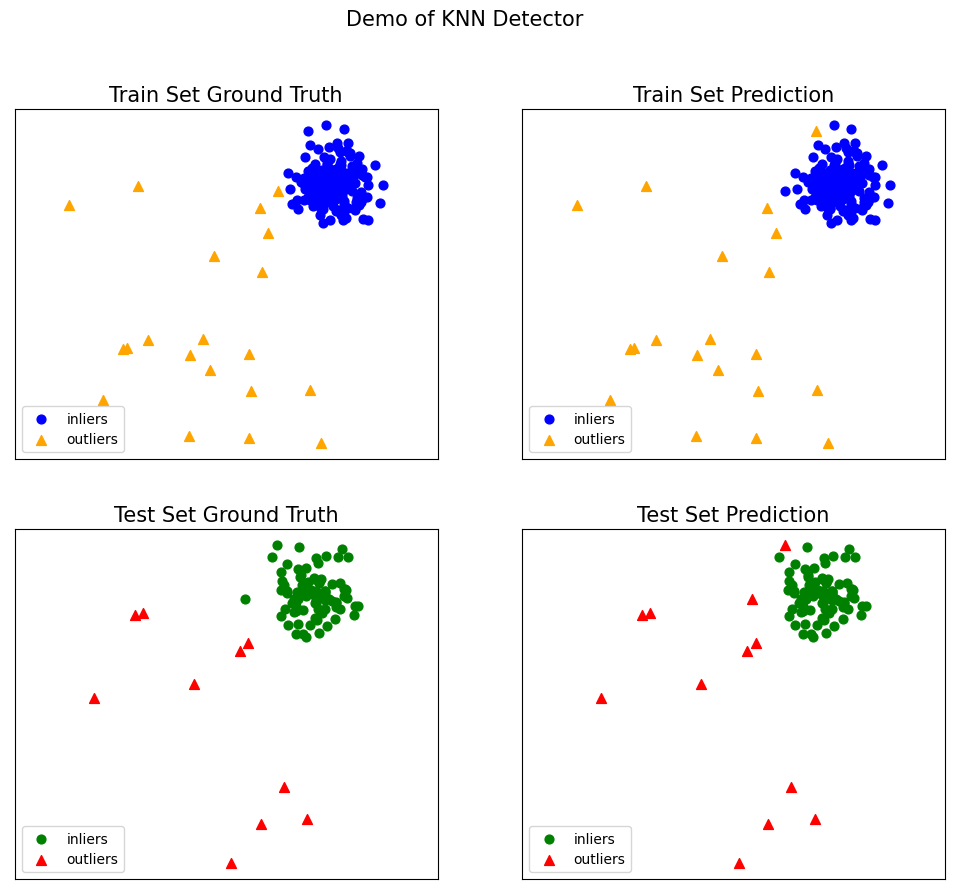
可视化结果
以下代码展示了模型在训练集和测试集上的异常标签预测结果,其中 inliers 表示正常点,outliers 表示异常点。
from pyod.utils.example import visualize # 可视化结果visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False) # 显示可视化图像
复制代码
模型替换
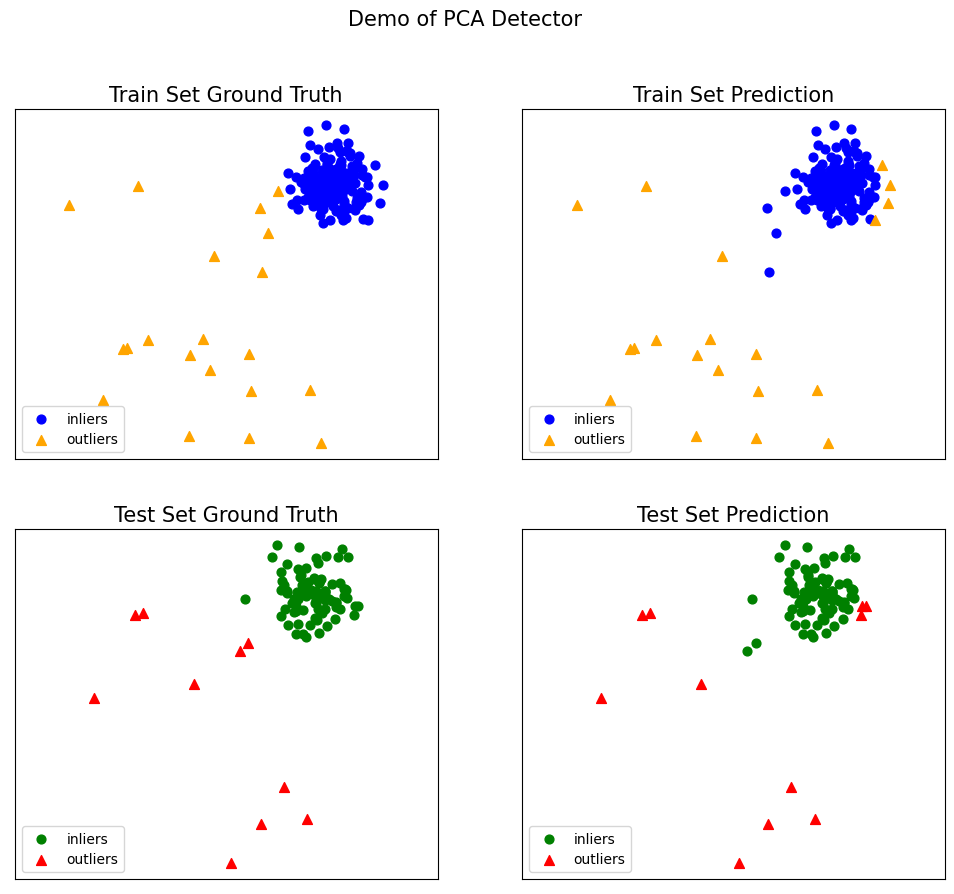
本文在 1.1 节提到,PyOD 为不同的异常检测算法提供了统一的 API 接口,并附上了各类算法的接口说明链接。在 PyOD 中,其他算法的检测流程与 KNN 算法类似,这一点与 sklearn 的模型构建方式相似。以 PCA 为例,只需更改模型的初始化方式,即可轻松替换模型,具体操作如下:
from pyod.models.pca import PCA# 训练PCA检测器clf_name = 'PCA' # 设置分类器的名称clf = PCA() # 创建kNN模型实例clf.fit(X_train) # 使用训练数据拟合模型
复制代码
PCA(contamination=0.1, copy=True, iterated_power='auto', n_components=None, n_selected_components=None, random_state=None, standardization=True, svd_solver='auto', tol=0.0, weighted=True, whiten=False)
复制代码
其他代码一样:
# 获取训练数据的预测标签和异常分数y_train_pred = clf.labels_ # 二进制标签(0: 正常点, 1: 异常点)y_train_scores = clf.decision_scores_ # 训练数据的异常分数 # 对测试数据进行预测y_test_pred = clf.predict(X_test) # 对测试数据的异常标签(0或1)y_test_scores = clf.decision_function(X_test) # 测试数据的异常分数 # 获取预测的置信度y_test_pred, y_test_pred_confidence = clf.predict(X_test, return_confidence=True) # 返回预测标签和置信度(范围[0,1]) from pyod.utils.data import evaluate_print # 导入评估工具 # 评估并打印结果print("\nOn Training Data:") # 打印训练数据的评估结果evaluate_print(clf_name, y_train, y_train_scores) # 评估训练数据print("\nOn Test Data:") # 打印测试数据的评估结果evaluate_print(clf_name, y_test, y_test_scores) # 评估测试数据 # 可视化结果visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False) # 显示可视化图像
复制代码
On Training Data:PCA ROC:0.8964, precision @ rank n:0.8 On Test Data:PCA ROC:0.9033, precision @ rank n:0.8
复制代码
1.2.2 模型组合
异常检测由于其无监督特性,常常面临模型不稳定的问题。因此,建议通过组合不同检测器的输出(例如,通过平均)来提高其稳健性。
本示例展示了四种评分组合机制:
以上组合机制的代码实现由 combo 库提供。combo 库是一个用于机器学习模型组合(集成学习)的 Python 工具库。它提供了多种模型合并方法,包括简单的平均、加权平均、中位数、多数投票,以及更复杂的动态分类器选择(Dynamic Classifier Selection)和堆叠(Stacking)等。combo 库支持多种不同的场景,如分类器合并、原始结果合并、聚类合并和异常检测器合并。combo 库官方仓库地址为:combo,安装命令如下:
pip install combo
以下示例代码展示了通过 PyOD 库和 combo 库组合模型来实现异常检测:
创建数据集
# 需要安装combo库,使用命令 pip install combofrom pyod.models.combination import aom, moa, median, average, maximizationfrom pyod.utils.data import generate_data, evaluate_printfrom pyod.utils.utility import standardizerfrom sklearn.model_selection import train_test_splitimport numpy as np # 导入模型并生成样本数据# n_train:训练样本个数,n_features:样本X的特征维度,train_only:是否仅包含训练集X, y = generate_data(n_train=5000, n_features=2, train_only=True, random_state=42) # 加载数据# test_size:测试集比例X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4) # 划分训练集和测试集 # 标准化数据以便处理X_train_norm, X_test_norm = standardizer(X_train, X_test)
复制代码
创建检测器
初始化 10 个 KNN 异常检测器,设置不同的 k 值,并获取异常分数。k 值决定了在进行预测时考虑多少个最近邻近点,较小的 k 值可能导致对噪声敏感,而较大的 k 值可能会使得模型过于平滑,从而失去某些细节。当然这段代码也可以组合不同类型的检测器,然后获取异常分数。
from pyod.models.knn import KNN n_clf = 10 # 基础检测器的数量 # 初始化n_clf个基础检测器用于组合k_list = list(range(1,100,n_clf)) train_scores = np.zeros([X_train.shape[0], n_clf]) # 创建训练集得分数组test_scores = np.zeros([X_test.shape[0], n_clf]) # 创建测试集得分数组 print('Combining {n_clf} kNN detectors'.format(n_clf=n_clf)) # 输出组合的KNN检测器数量 for i in range(n_clf): k = int(k_list[i]) # 获取当前检测器的邻居数量 clf = KNN(n_neighbors=k, method='largest') # 初始化KNN检测器 clf.fit(X_train_norm) # 拟合训练数据 train_scores[:, i] = clf.decision_scores_ # 记录训练得分 test_scores[:, i] = clf.decision_function(X_test_norm) # 记录测试得分
复制代码
Combining 10 kNN detectors
复制代码
标准化检测结果
各个检测器的检测结果需要被标准化为零均值和单位标准差,这是因为在进行模型结果组合时,如果各个模型的输出得分范围差异较大,直接组合可能会导致结果偏差。通过标准化,可以确保各个模型的得分在同一尺度上,从而进行有效的组合:
# 在组合之前,需要对检测结果进行标准化train_scores_norm, test_scores_norm = standardizer(train_scores, test_scores)
复制代码
组合结果
使用 combo 组合结果:
# 使用平均值进行组合y_by_average = average(test_scores_norm)evaluate_print('Combination by Average', y_test, y_by_average) # 输出平均组合的评估结果 # 使用最大值进行组合y_by_maximization = maximization(test_scores_norm)evaluate_print('Combination by Maximization', y_test, y_by_maximization) # 输出最大值组合的评估结果 # 使用中位数进行组合y_by_median = median(test_scores_norm)evaluate_print('Combination by Median', y_test, y_by_median) # 输出中位数组合的评估结果 # 使用AOM进行组合。n_buckets为子组个数y_by_aom = aom(test_scores_norm, n_buckets=5)evaluate_print('Combination by AOM', y_test, y_by_aom) # 输出AOM组合的评估结果 # 使用MOA进行组合,n_buckets为子组个数y_by_moa = moa(test_scores_norm, n_buckets=5)evaluate_print('Combination by MOA', y_test, y_by_moa) # 输出MOA组合的评估结果
复制代码
Combination by Average ROC:0.9899, precision @ rank n:0.9497Combination by Maximization ROC:0.9866, precision @ rank n:0.9447Combination by Median ROC:0.99, precision @ rank n:0.9548Combination by AOM ROC:0.9896, precision @ rank n:0.9447Combination by MOA ROC:0.9884, precision @ rank n:0.9447
复制代码
1.2.3 阈值处理
PyOD 通过模型计算数据的异常概率,并根据设定的阈值筛选出异常数据。在这个过程中,阈值的选择对异常检测结果的准确性具有重要影响。
PyThresh 是一个全面且可扩展的 Python 工具包,旨在自动设置和处理单变量或多变量数据中的异常检测概率分数。它与 PyOD 库兼容,采用类似的语法和数据结构,但并不限于该库。PyThresh 包含超过 30 种阈值算法,涵盖了从简单统计分析(如 Z-score)到更复杂的图论和拓扑数学方法的多种技术。PyThresh 库官方仓库地址为:pythresh,安装命令如下:
pip install pythresh
关于 PyThresh 的详细使用,可以查看其官方文档:pythresh-doc。以下示例代码展示了通过 PyOD 库和 PyThresh 库实现阈值处理的简单示例:
使用阈值处理算法
利用 PyThresh 与 PyOD 库自动选择阈值,可以提高识别精度。然而,请注意,使用 PyThresh 中的算法来自动确定阈值并不保证在所有情况下都能获得理想效果。
# 从pyod库中导入KNN模型、评估函数和数据生成函数from pyod.models.knn import KNNfrom pyod.utils.data import generate_datafrom sklearn.metrics import accuracy_score # 从pythresh库中导入KARCH阈值计算方法from pythresh.thresholds.karch import KARCH # 设置污染率,即异常值的比例contamination = 0.1 # percentage of outliers# 设置训练样本的数量n_train = 500 # number of training points# 设置测试样本的数量n_test = 1000 # number of testing points # 生成样本数据,返回训练和测试数据及其标签X_train, X_test, y_train, y_test = generate_data(n_train=n_train, n_test=n_test, n_features=2, # 特征数量 contamination=contamination, # 异常值比例 random_state=42) # 随机种子,以确保结果可重复 # 初始化KNN异常检测器clf_name = 'KNN' # 分类器名称clf = KNN() # 创建KNN模型实例clf.fit(X_train) # 使用训练数据拟合模型thres = KARCH() # 创建KARCH算法创建阈值处理实例# 对测试数据进行预测y_test_scores = clf.decision_function(X_test) # 计算测试集的异常分数# 基于阈值clf.threshold_y_test_pred = clf.predict(X_test) # 获取测试集,结果y_test_pred_thre = thres.eval(y_test_scores) # 对异常值结果进行处理 # 计算精度accuracy = accuracy_score(y_test, y_test_pred)print(f"阈值处理前精度: {accuracy:.4f}") accuracy = accuracy_score(y_test, y_test_pred_thre)print(f"阈值处理后精度: {accuracy:.4f}")
复制代码
阈值处理前精度: 0.9940阈值处理后精度: 0.9950
复制代码
contamination 参数
除了初始化 PyThresh 算法模型实例,也可以在初始化 PyOD 模型时基于 contamination 参数指定阈值选择算法:
from pyod.models.kde import KDE # 导入KDE模型from pyod.models.thresholds import FILTER from pyod.utils.data import generate_data from pyod.utils.data import evaluate_print contamination = 0.1 # 异常点的比例n_train = 200 # 训练数据点数量n_test = 100 # 测试数据点数量 # 生成样本数据X_train, X_test, y_train, y_test = generate_data(n_train=n_train, n_test=n_test, n_features=2, contamination=contamination, random_state=42) # 随机种子 # 训练KDE检测器clf_name = 'KDE' # 模型名称clf = KDE(contamination=FILTER()) # 添加阈值选择算法clf.fit(X_train) # 使用训练数据拟合模型 # 获取训练数据的预测标签和异常分数y_train_pred = clf.labels_ # 二元标签(0: 正常点, 1: 异常点)y_train_scores = clf.decision_scores_ # # 获取测试数据的预测结果y_test_pred = clf.predict(X_test) y_test_scores = clf.decision_function(X_test) # 评估并打印结果print("\n在训练数据上:")evaluate_print(clf_name, y_train, y_train_scores) # 评估训练数据print("\n在测试数据上:")evaluate_print(clf_name, y_test, y_test_scores) # 评估测试数据
复制代码
在训练数据上:KDE ROC:0.9992, precision @ rank n:0.95 在测试数据上:KDE ROC:1.0, precision @ rank n:1.0
复制代码
1.2.4 模型保存与加载
PyOD 使用joblib或pickle来保存和加载 PyOD 模型,如下所示:
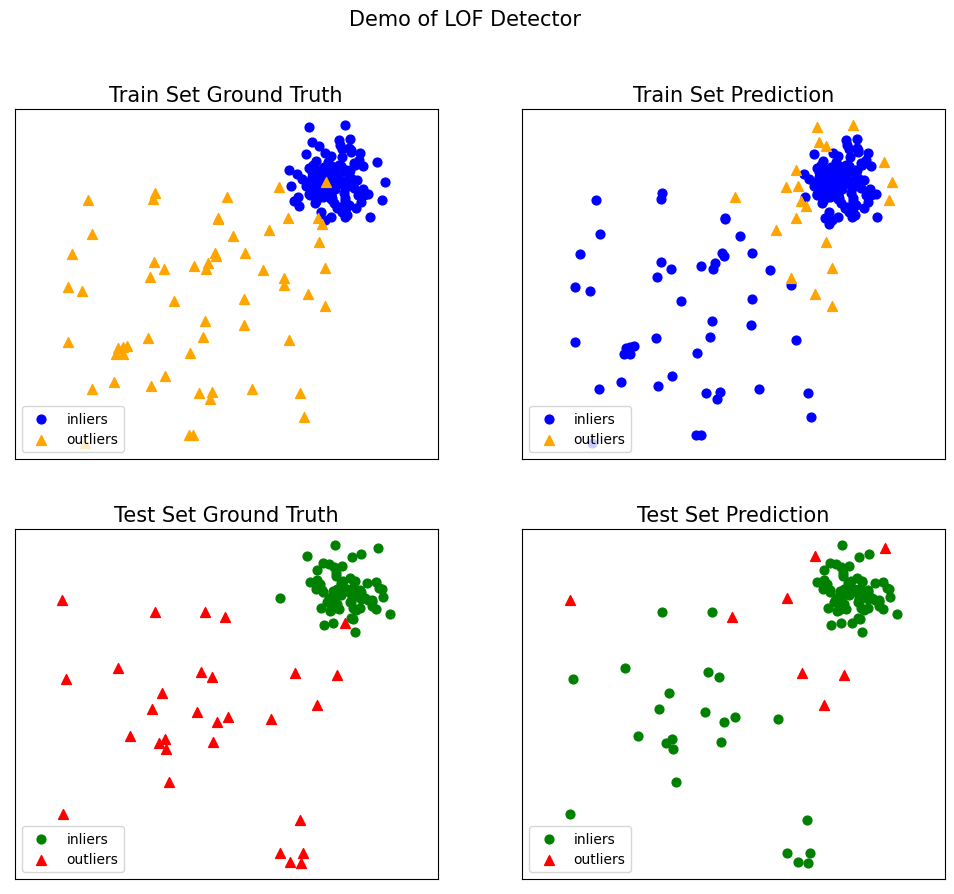
from pyod.models.lof import LOF from pyod.utils.data import generate_data from pyod.utils.data import evaluate_print from pyod.utils.example import visualize from joblib import dump, load # 从joblib库导入模型保存和加载工具 contamination = 0.3 # 异常点的比例n_train = 200 # 训练数据点的数量n_test = 100 # 测试数据点的数量 # 生成样本数据X_train, X_test, y_train, y_test = generate_data(n_train=n_train, n_test=n_test, n_features=2, # 特征数量为2 contamination=contamination, # 异常比例 random_state=42) # 随机状态设置 # 训练LOF检测器clf_name = 'LOF' # 分类器名称clf = LOF() # 实例化LOF模型clf.fit(X_train) # 在训练数据上拟合模型 # 获取训练数据的预测标签和异常分数y_train_pred = clf.labels_ # 二进制标签(0:正常点, 1:异常点)y_train_scores = clf.decision_scores_ # 原始异常分数 # 保存模型dump(clf, 'clf.joblib') # 将模型保存到文件# 加载模型clf_load = load('clf.joblib') # 从文件加载模型 # 获取测试数据的预测y_test_pred = clf_load.predict(X_test) # 测试数据的异常标签(0或1)y_test_scores = clf_load.decision_function(X_test) # 测试数据的异常分数 # 评估并打印结果print("\n在训练数据上的结果:")evaluate_print(clf_name, y_train, y_train_scores) # 评估训练数据的结果print("\n在测试数据上的结果:")evaluate_print(clf_name, y_test, y_test_scores) # 评估测试数据的结果 # 可视化结果visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False) # 可视化训练和测试结果
复制代码
在训练数据上的结果:LOF ROC:0.5502, precision @ rank n:0.3333 在测试数据上的结果:LOF ROC:0.4829, precision @ rank n:0.3333
复制代码
文章转载自:落痕的寒假
原文链接:https://www.cnblogs.com/luohenyueji/p/18442742
体验地址:http://www.jnpfsoft.com/?from=infoq















评论