
干货 | 企业如何快速采集分析日志?
数字化时代,企业对快速采集日志的需求日益递增,对于个人开发者和企业来说,日志采集也有的截然不同的复杂度。
“快速”这个需求的本质在于,如何利用比较方便部署且成熟可靠的技术选型,来降低搭建一套能满足业务诉求的日志平台所需的时间成本,其中要解决的核心问题就是:日志架构的复杂度。在此我们重点聚焦于企业用户,深度解析企业级的日志平台架构建设复杂度以及建设思路分享。
01
企业级日志架构复杂度
一套企业级的日志平台架构建设复杂度总结归纳下来,主要体现在三个方面:
采集端部署分散;
服务端部署组件多;
日志流对性能有一定要求。
采集端部署分散
比较常用的采集器是开源的 filebeat,filebeat 功能强大,安装配置也相对简单。但问题在于,一旦需要采集的对象数量多起来,种类多起来,或者这些采集对象是动态变化的,即使单节点安装简易的 filebeat 也会需要花费大量的精力来安装和维护。这也是很多企业在建设统一日志平台面临的一个实际问题。这时,运维往往会写脚本去批量下发,能做到部分解决问题,但是后期的配置维护、版本更新等等,都将带来新的问题。
那么,有什么方案可以解决呢?有,那就是采取集中管理的思路,由一个统一的控制中心,通过在不同节点上安装代理来收集信息+下发配置。一般一个中大型企业,基本都会有一套自己的 agent 来控制各方资源,agent 往往是在虚拟机模板或者容器镜像中就已经打入,主要的作用也就是上报信息以及下发配置。日志的采集便可以利用好这种集中式的管理工具,基于 agent 做插件来充当采集端,统一管理采集配置(包括路径、级别、过滤、预处理等等)。
服务端部署组件多
对于个人开发者或小规模企业来说,部署组件多也许还可以接受。拿开源的 ELK 举例,日志服务端部署需要 Logstash 集群和 ES 集群,以及一个 Kibana 的前端,完整一套集群也许就可以解决相当体量的日志集中管理。但对于一家中大型企业来讲,体量和业务复杂度上来之后,情况往往是非常复杂的。
这时建设人员可能会有一种思路:直接采用多套 ELK,也能解决问题,部署也就写个脚本的事情,批量复制,还可以做“物理隔离”。这样确实行之有效,但这种方案会带来另外的问题,就是日志无法进一步聚合聚类,导致各业务的日志数据成了数据孤岛,如果组织内有那种横向组织,他们就需要来回切换集群进行诸如日志检索,日志清洗等操作。
要解决这个问题,其实只需要再增加一个服务端,能够将分布在不同 ELK 的日志存储统一管理起来,让上述场景统一通过这个服务端提供的接口完成,也就能在使用日志的时候,不再受到存储分散的影响。
性能要求高
日志数据不同于指标类数据,日志数据无论是从时间密度还是从空间密度上来说都要远远大于其他类型的观测数据。因此,中大型企业的大型业务系统以及庞大的基础设施产生的日志量让企业开发者不得不思考这其中的性能和成本如何平衡。
总结三个关键的性能瓶颈以及对应的解决方案:
分散到集中存储所消耗的带宽压力:
通过采集端做预先过滤
分多条传输链路
做好网络链路规划,尽量避免跨域传输
清洗和存储压力:
通过 Kafka 等消息队列做写入缓冲
使用非结构化分片存储
检索响应速度的压力:
冷热数据分离,减少索引大小
完善数据预处理和清洗,索引高效(一定程度依赖日志输出规范化)
02
整体技术架构
整体技术架构介绍
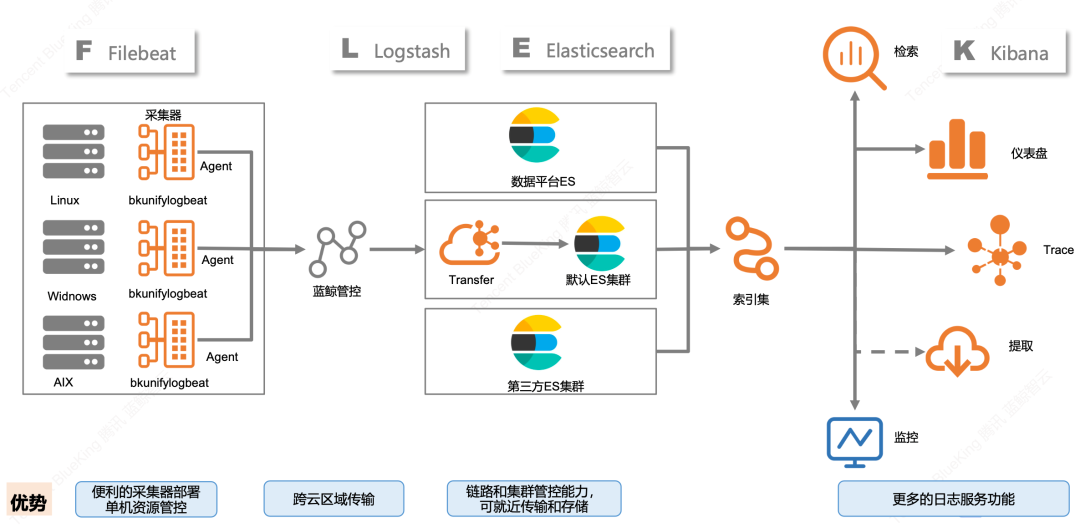
蓝鲸平台在腾讯内部业务场景的探索
其实刚刚展示的这套日志架构,源自腾讯 IEG 蓝鲸日志平台的数据流示意图。
蓝鲸平台在早期就将日志的各类应用场景作为整个自动化运营中的关键环节,并规划建造出了一套适合中大型企业使用的日志平台。直至目前,蓝鲸日志平台已经历经上百次的迭代,在腾讯内部积累了大量的实践经验,支持了上千项业务的日志需求,总结出了不少技术优化举措,在此结合这个话题进行分享总结。
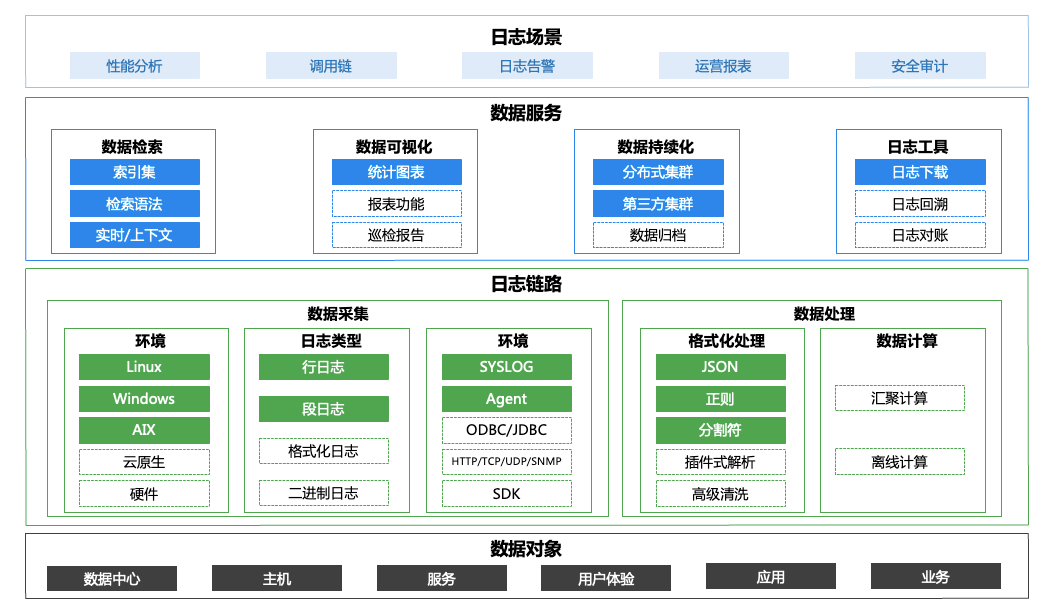
关键技术优化举措 &经验
采集端统一 Agent,用 Agent 装采集插件的方式来实现日志采集,便于安装管理。
对于难以运行 Agent 的设备,可以采取用一些节点主动调用接口获取 syslog 的方式,集中存储再用 Agent 采集。
Transfer 预处理和 Kafka 高吞吐衔接,加强数据管道性能。
统一存储端管理,支持第三方 ES 接入,通过索引集的设计拓展后续的日志应用场景。
分析类的计算任务会借助已有的成熟的数据平台,而并非在自己内部进行。
数据可视化重点关注指标和维度的体系建设,而并非界面的优化(grafana 可以解决绝大部分可视化需求)。
各服务节点均可云原生集群化部署。
实践效果
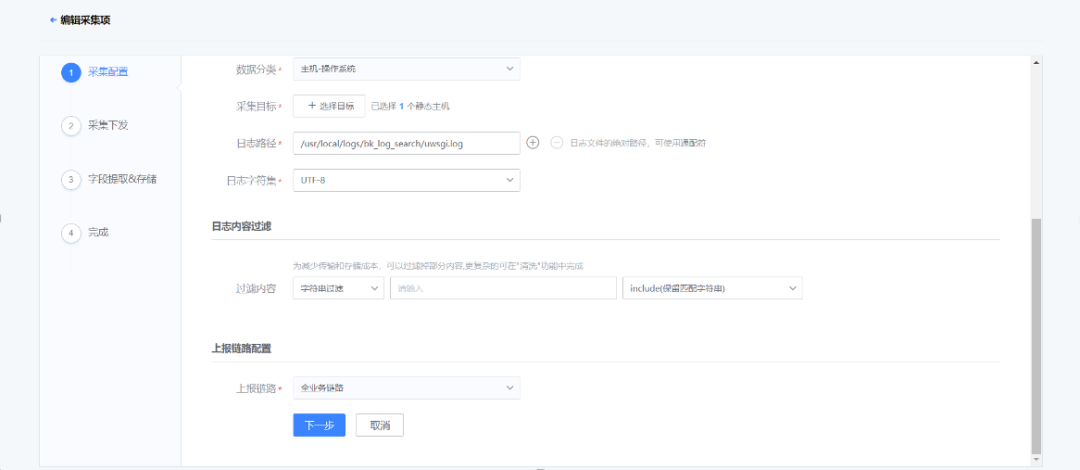
通过 Agent,支持各类日志的采集。
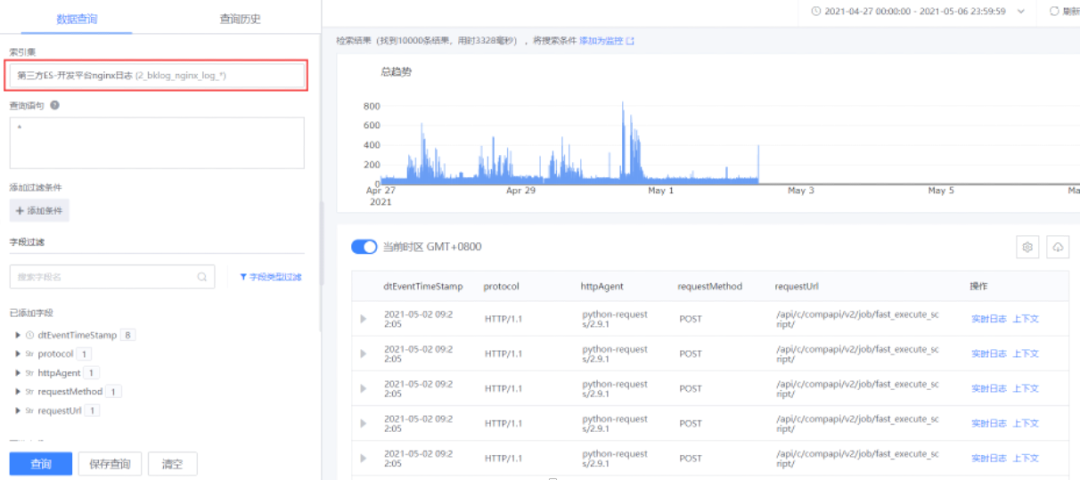
统一服务端后,使用索引集进行跨节点的日志检索。
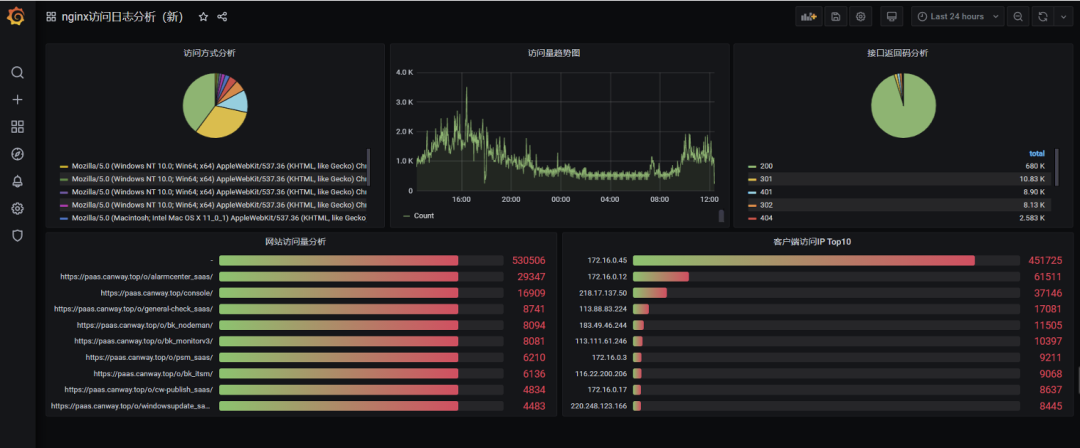
配合 grafana 分析日志清洗后的指标数据(以 Nginx 访问日志为例)。
了解更多内容,欢迎关注公众号嘉为蓝鲸。


研运至简,无限可为 2020-08-13 加入
蓝鲸智云一级技术合作伙伴,中国领先的研发运营一体化解决方案提供商








评论