
从根上理解 elasticsearch(lucene) 查询原理 (1)-lucece 查询逻辑介绍
大家好,最近在做一些 elasticsearch 慢查询优化的事情,通常用分析 elasticsearch 慢查询的时候可以通过 profile api 去分析,分析结果显示的底层 lucene 在搜索过程中使用到的函数调用。所以要想彻底弄懂 elasticsearch 慢查询的原因,还必须将 lucene 的查询原理搞懂,今天我们就先来介绍下 lucene 的查询逻辑的各个阶段。
lucene 查询过程分析
先放上一张查询过程的流程图,下面的分析其实都是对这张图的更详细的介绍。
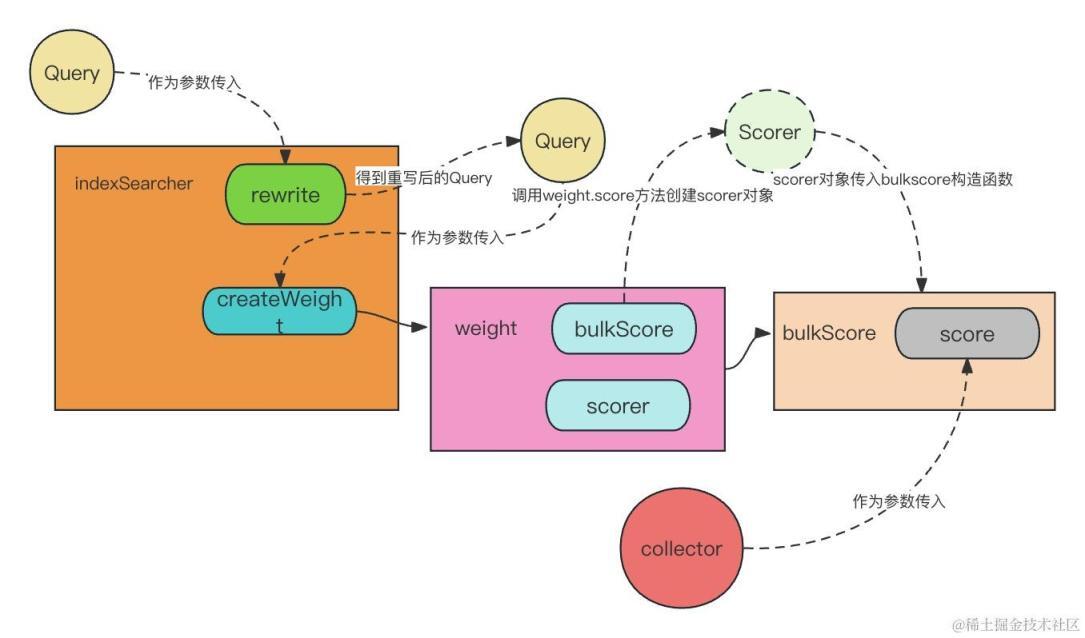
lucene 的查询可以大致分为 4 个阶段,重写查询,创建查询 weight 对象,创建 scorer 对象准备计分,进行统计计分。
简单解释下这 4 个阶段;
1, 重写查询语句( rewrite query )
lucene 提供了比较丰富的外部查询类型,像 wildcardQuery,MatchQuery 等等,但它们最后都会替换为比较底层的查询类型,例如 wildcardQuery 会被重写为 MultiTermsQuery。
2, 创建查询 weight 对象( createWeight )
Query 对象创建的权重对象, lucece 的每个查询都会计算一个该查询占用的权重值,如果是不需要计分的,则权重值是一个固定常量,得到的文档结果是根据多个查询的权重值计算其得分的。下面是 Weight 对象涉及的方法,
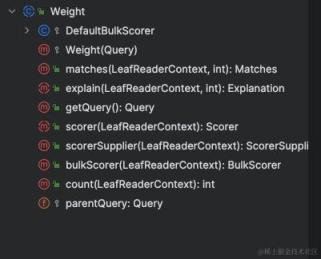
其中,scorer(LeafReaderContext context) 方法是个抽象方法,需要子类去实现的。
方法返回的 scorer 对象拥有遍历倒排列表和统计文档得分的功能,下面会讲到实际上 weight 对象是创建 BulkScore 进行计分的,但 BulkScore 内部还是通过 score 对象进行计分。
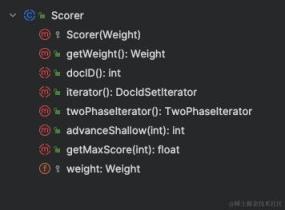
再详细解释下 Scorer 对象中比较重要的方法;
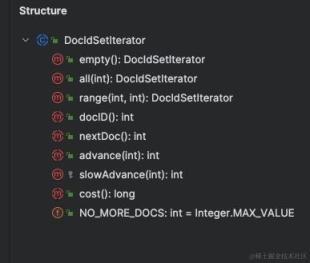
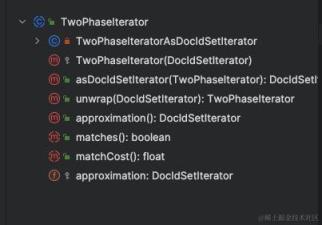
iterator() 方法返回的 DocIdSetIterator 对象提供了遍历倒排列表的能力。如下是 DocIdSetIterator 涉及的方法,其中 docID()是为了返回当前遍历到的倒排列表的文档 id,nextDoc()则是将遍历指针移动到下一个文档,并且返回文档 id,advance 用于移动遍历指针。
twoPhaseIterator 方法提供对文档二次精准匹配的能力,比如在 matchPhrase 查询中,不但要查出某个词,还要求查出的词之间相对顺序不变,那么这个相对顺序则是通过 twoPhaseIterator 的 matches 方法去进行判断。
3, 创建 bulkScorer 对象( weight.bulkScore)
weight 对象会调用 BulkScore 方法创建 BulkScorer 对象,bulkScorer 内部首先调用的是 scorer 抽象方法(需要由 weight 子类去实现的方法),得到的 scorer 对象再拿去构建 DefaultBulkScorer 对象,所以说,实际上最后计分的还是通过 scorer 对象进行计分的。
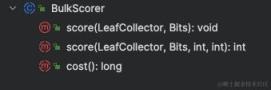
bulkScorer 类有如下方法,一个是提供对段所有文档进行计分,一个是可以在段的某个文档 id 范围内进行计分。
4, 进行统计计分
最后则是通过 collector 对象进行统计,这里提到了 collecor 对象,它其实是作为了上述 bulkScorer 的 score 方法参数传入的,在 bulkScore.score 方法内部,遍历文档时,对筛选出的文档会通过调用 collector.collect(doc)方法进行收集,在 collect 方法内部,则是调用 scorer 对象对文档进行打分。
完整的搜索流程如下
profile api 返回结果分析
理清楚了 lucene 的搜索逻辑,我们再来看看通过 profile api 返回的各个阶段耗时是统计的哪段逻辑。
在使用 elasticsearch 的 profile api 时,会返回如下的统计阶段
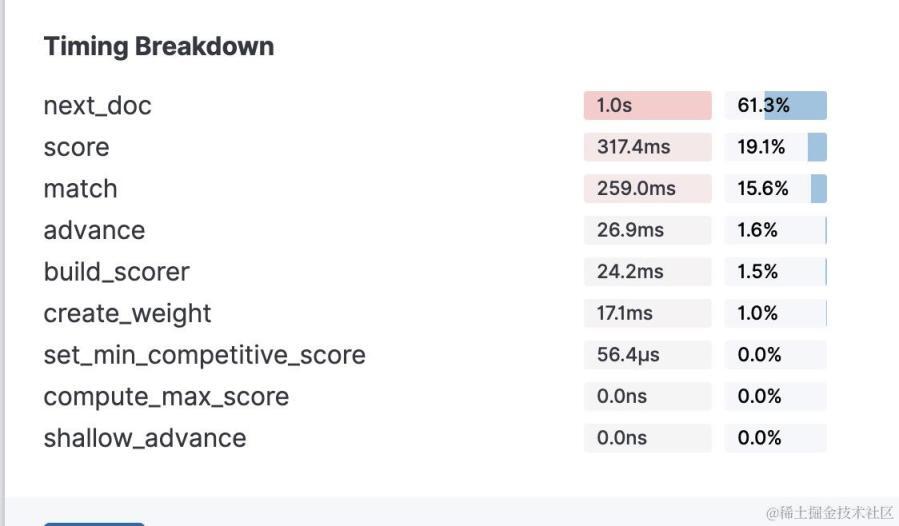
如果不了解源码可能会对这些统计指标比较疑惑,结合刚才对 lucece 源码的了解来看下几个比较常见的统计指标。
next_doc 是取倒排链表中当前遍历到的文档 id,并且把遍历的指针移动到下一个文档 id 消耗的时长。
score 是 weight.scorer 方法创建的 score 对象,进行文档计分的操作时消耗的时长。
match 是 twoPhaseIterator 进行二次匹配判断时消耗的时长。
advance 是直接将遍历的指针移动到特定文档 id 处消耗的时长。
build_score 是 weight 对象在通过 weight.scorer 方法创建 score 对象时所耗费的时长。
create_weight 是 query 对象在调用其自身 createWeight 方法创建 weight 对象时耗费的时长。
set_min_competitive_score,compute_max_score,shallow_advance 我也还没彻底弄懂它们用到的所有场景,这里暂不做分析。
这里还要注意的一点是,像布尔查询是结合了多个子查询的结果,它内部会构造特别的 scorer 对象,比如 ConjunctionScorer 交集 scorer,它的 next_doc 方法则是需要对其子查询的倒排链表求交集,所以你在用 profile api 分析时,可能会看到布尔查询的 next_doc 耗时较长,而其子查询耗时较长的逻辑则是 advance,因为倒排列表合并逻辑会有比较多的 advance 移动指针的动作。
profile api 的实现原理
最后,我再来谈谈 elasticsearch 是如何实现 profile 的,lucene 的搜索都是通过 IndexSearcher 对象来执行的,IndexSearcher 在调用 query 对象自身的 rewrite 方法重写 query 后,会调用 IndexSearcher 的 createWeight 方法来创建 weight 对象(本质上底层还是使用的 query 的 createWeight 方法)。
elasticsearch 继承了 IndexSearcher ,重写了 createWeight,在原本 weight 对象的基础上,封装了一个 profileWeight 对象。以下是关键代码。
基于文章开头的 lucene 查询逻辑分析,可以知道,scorer 对象最后也是通过 weight 对象的 scorer 方法得到的,所以创建出来的 profileWeight 的 scorer 方法通用也对返回的 scorer 对象封装了一层,返回的是 profileScorer 对象。
剩下的就好办了,在 profileScore 对象里对 scorer 对象的原生方法前后加上时间统计即可对特定方法进行计时了。比如下面代码中 profileScore 的 advanceShallow 方法。
总结
通过本篇文章,应该可以对 lucene 的查询过程有了大概的了解,但其实对于 elasticsearch 的慢查询分析还远远不够,因为像布尔查询,wilcard 之类的比较复杂的查询,我们还得弄懂,它们底层是究竟如何把一个大查询分解成小查询的。才能更好的弄懂查询耗时的原因,所以在下一节,我会讲解这些比较常见的查询类型的内部重写和查询逻辑。
文章转载自:蓝胖子的编程梦

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论