什么是函数式编程
函数式编程是一种是一种编程范式,它将计算视为函数的运算,并避免变化状态和可变数据。它是一种声明式编程范式,也就是说,编程是用表达式或声明而不是语句来完成的,即强调做什么,而不是以什么形式去做。
Lamda 表达式:
比起指令式编程,函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。
1. Lambda 表达式
在了解 Lambda 表达式之前,先看这样一个需求:
通过 Runnable 启动一个线程,并打印:线程已启动
对于这样一个需求,有以下三种方式:
方式一
实现 Runnable 接口,如下:
class MyRunnable implements Runnable{ @Override public void run() { log.info("线程已启动"); }}
@Testvoid test_runnable_01() { MyRunnable myRunnable = new MyRunnable(); Thread thread = new Thread(myRunnable); thread.start();}
复制代码
方式二
匿名内部类,如下:
@Testvoid test_runnable_02() { Thread thread = new Thread(new Runnable() { @Override public void run() { log.info("线程已启动"); } }); thread.start();}
复制代码
方式三
Lambda 表达式,如下:
@Testvoid test_runnable_03() { Thread thread = new Thread(() -> { log.info("线程已启动"); }); thread.start();}
复制代码
可以看到使用 Lambda 表达式使得代码看起来更简单。
1.1 标准格式
匿名内部类中重写 run() 方法的代码分析:
Lambda 表达式的代码分析:
由此可得知,组成 Lambda 表达式的三要素:形式参数、箭头、代码块。
Lambda 表达式的格式:
格式:(形式参数)-> { 代码块 }
形式参数:如果有多个参数,参数之间用逗号隔开;如果没有参数,留空即可
->:由英文中画线和大于符号组成,固定写法,代表指向动作
代码块:是我们具体要做的事情,也就是以前我们写的方法体内容
1.2 使用前提
Lambda 表达式的使用前提:
在 Runnable 的测试中,其 run()是一个无参数的方法,接下来我们按照上述前提来创建一个参数和多个参数的接口来实现 Lambda 表达式。
1.2.1 一个参数
定义一个名为 LambdaFunction 的接口,在定义其抽象方法为 func(String str),如下:
public interface LambdaFunction {
public abstract void func(String str);
}
复制代码
测试:
@Testvoid test_Lambda_function() { Lambda_function((String str) -> { log.info(str); }, "一个形参");}
void Lambda_function(LambdaFunction function, String str) { function.func(str);}
复制代码
1.2.2 多个参数
同上,定义包含 2 个参数的抽象方法。
public interface LambdaFunction2 {
public abstract void func2(String str, int i);
}
复制代码
测试:
@Testvoid test_Lambda_function2() { Lambda_function2((String str, int i) -> { log.info(str + ": " + i); }, "多个参数", 2);}
void Lambda_function2(LambdaFunction2 function, String str, int i) { function.func(str, i);}
复制代码
1.2.3 有返回值
除了多参数,还要存在返回值的情况,如下定义:
public interface LambdaFunction3 {
public abstract int add(int i1, int i2);
}
复制代码
测试:
@Testvoid test_Lambda_function3() { int i = Lambda_function3((int i1, int i2) -> { return i1 + i2; }, 1, 2); log.info(i + "");}
int Lambda_function3(LambdaFunction3 function, int i1, int i2) { return function.add(i1, i2);}
复制代码
1.3 省略简化
Lambda 表达式可以省略简化,它的规则如下:
因此我们可以把上面的简化,如下:
@Testvoid test_Lambda_function_simplify() { Lambda_function(str -> log.info(str), "一个参数");}
@Testvoid test_Lambda_function2_simplify() { Lambda_function2((str, i) -> log.info(str + ": " + i), "多个参数", 2);}
@Testvoid test_Lambda_function3_simplify() { int i = Lambda_function3((i1, i2) -> i1 + i2, 1, 2); log.info(i + "");}
复制代码
1.4 函数式接口
函数式接口:有且仅有一个抽象方法的接口
Java 中的函数式编程体现就是 Lambda 表达式,所以函数式接口就是可以使用于 Lambda 使用的接口只有确保接口中有且仅有一个抽象方法,Java 中的 Lambda 才能顺利地进行推导。
如何检测一个接口是不是函数式接口呢?
@FunctionalInterface 注解,放在接口定义的上方,如果接口是函数接口,编译通过;如果不是,编译失败。
注意:
我们自己定义函数式接口的时候,@FunctionalInterface 是可选的,就算我们不写这个注解,只要保证满足函数式接口定义的条件,也照样是函数式接口。但是,建议加上注解。
Java 8 在 java.util.function 包下预定了大量的函数式接口供我们使用,常用如下:
Supplier 接口
Consumer 接口
Predicate 接口
Function 接口
1.4.1 Supplier
Supplier 接口被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的 get 方法就会生产什么类型的数据供我们使用。
@FunctionalInterfacepublic interface Supplier<T> {
/** * Gets a result. * * @return a result */ T get();}
复制代码
该方法不需要参数,它会按照某种实现逻辑(由 Lambda 表达式实现)返回一个数据,如下:
@Testvoid supplier_test() { String string = getString(() -> "String"); log.info(string); Integer integer = getInteger(() -> 1); log.info(integer + "");}
String getString(Supplier<String> supplier) { return supplier.get();}
Integer getInteger(Supplier<Integer> supplier) { return supplier.get();}
复制代码
1.4.2 Consumer
Consumer 接口被称为消费型接口,与 Supplier 接口相反,它消费的数据类型由泛型指定。
① accept
@FunctionalInterfacepublic interface Consumer<T> {
/** * 消费一个指定泛型的数据 * * @param t the input argument */ void accept(T t);
/** * 默认方法 */ default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; }}
复制代码
对于 accept() 方法,它是消费,如下:
@Testvoid consumer_test() { consumer_accept(100, money -> log.info("本次消费: " + money));}
/** * 定义一个方法 * * @param money 传递一个int类型的 money * @param consumer */void consumer_accept(Integer money, Consumer<Integer> consumer) { consumer.accept(money);}
复制代码
② andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费数据的时候,首先做一个操作, 然后再做一个操作,实现组合。
要想实现组合,需要两个或多个 Lambda 表达式即可,而 andThen 的语义正是一步接一步操作。例如两个步骤组 合的情况:
@Testvoid consumer_andThen_test() { consumer_andThen("abcdefg", // 先转为大写 str -> log.info(str.toUpperCase()), // 在转为小写 str -> log.info(str.toLowerCase()));}
void consumer_andThen(String str, Consumer<String> consumer1, Consumer<String> consumer2) { consumer1.andThen(consumer2).accept(str);}
复制代码
例子:
给出一个字符数组:
String[] array = { "张三,女", "李四,女", "王五,男" };
复制代码
让它们按照以下格式打印:
代码如下:
@Testvoid printInfo() { String[] array = {"张三,女", "李四,女", "王五,男"}; printInfo(array, str -> System.out.print("姓名: " + str.split(",")[0]), str -> System.out.println(" 性别: " + str.split(",")[1]) );}void printInfo(String[] arr, Consumer<String> consumer1, Consumer<String> consumer2) { for (String s : arr) { consumer1.andThen(consumer2).accept(s); }}
复制代码
结果如下:
在实际开发中,可以应用为对象。
1.4.3 Predicate
① test()
可以用来判断某个值是否满足条件,如下:
/** * 判断字符串的长度是否满足条件 */@Testvoid predicate_test() { boolean predicate = predicate_test("predicate", str -> str.length() > 10); System.out.println(predicate);}
boolean predicate_test(String str, Predicate<String> predicate) { boolean b = predicate.test(str); return b;}
复制代码
② and() && or()
这两个是相对的,且和或的关系,会短路,如下:
/** * 判断字符串是否以 A 开头,并且 equals B */@Testvoid predicate_and_test() { boolean b = predicate_and("A", x -> x.startsWith("A"), y -> y.equals("B")); System.out.println(b);}boolean predicate_and(String str, Predicate<String> predicate1, Predicate<String> predicate2) { boolean b = predicate1.and(predicate2).test(str); return b;}
输出: false /** * 判断字符串是否以 A 开头,或者 equals B */@Testvoid predicate_or_test() { boolean b = predicate_or("A", x -> x.startsWith("A"), y -> y.equals("B")); System.out.println(b);}boolean predicate_or(String str, Predicate<String> predicate1, Predicate<String> predicate2) { boolean b = predicate1.or(predicate2).test(str); return b;}
输出: true
复制代码
③ negate()
该方法就是对 test() 取反,该方法的源码如下:
default Predicate<T> negate() { return (t) -> !test(t);}
复制代码
例子:
/** * 判断字符串的长度是否大于 5 */@Testvoid predicate_negate_test() { Predicate<String> predicate = s -> s.length() > 5; boolean b1 = predicate.test("predicate"); System.out.println(b1); // true boolean b2 = predicate.negate().test("predicate"); System.out.println(b2); // false}
复制代码
1.4.4 Function
该接口通常用于对参数进行处理,转换然后返回一个新的值。
① apply()
该方法根据类型 T 的参数获取类型 R 的结果。 例如:将 String 类型转换为 int 类型。
@Testvoid function_test() { int i = function_apply("1234", x -> Integer.valueOf(x)); System.out.println(i);}
/** * 吧字符串类型转为 int 类型 * @param str * @param fun * @return */int function_apply(String str, Function<String, Integer> fun) { Integer apply = fun.apply(str); return apply;}
复制代码
② andThen()
该方法和 Consumer#andThen 类似,如下例子:
@Testvoid function_andThen_test() { double d = function_andThen("10", x -> Integer.parseInt(x) + 10, y -> Double.valueOf(y)); System.out.println(d);}
/** * 把 String 类型转为 Integer 加10,然后再转为 Double 类型 */double function_andThen(String str, Function<String, Integer> fun1, Function<Integer, Double> fun2) { double apply = fun1.andThen(fun2).apply(str);//自动拆箱 return apply;}
复制代码
1.5 方法引用
方法引用可以看成是对 Lambda 表达式的一种简化写法,但它的前提是:
如果 Lambda 表达式的方法体中只调用了一个方法,并且调用的方法和函数式接口中定义的抽象方法的参数列表和返回值都一致,就可以使用方法引用进行简化。
方法引用通过方法引用符来表示:::
常见的几种引用方式:
对象 :: 实例方法
类 :: 静态方法
类 :: 实例方法
类 :: new
1.5.1 对象 :: 实例方法
引用对象的实例方法,其实就是引用类中的成员方法。
格式:对象 :: 实例方法
示例:System.out::println
/** * 1. 对象::实例方法 */@Testvoid test1() { // 1.匿名内部类 Consumer<String> consumer = new Consumer<>() { @Override public void accept(String s) { System.out.println(s); } }; consumer.accept("使用方式1: 匿名内部类"); // 2.lambda表达式 consumer = s -> System.out.println(s); consumer.accept("使用方式2: lambda表达式"); //3.方法引用 consumer = System.out::println; consumer.accept("使用方式3: 方法引用");}
复制代码
分析:
只调用了一个方法
省略的代码块中只调用了System.out.println(s)方法。
调用的方法和函数式接口中定义的抽象方法的参数列表和返回值都一致
上面定义的Consumer<String>,因此 accept(T t) 的入参和 println(String x)都是 String 类型且都没有返回值。
1.5.2 类 :: 静态方法
格式:类名::静态方法
示例:Integer::parseInt,Integer::compare
/** * 2. 类::静态方法 */@Testvoid test2() { // 1.匿名内部类 Comparator<Integer> comparator = new Comparator<>() { @Override public int compare(Integer o1, Integer o2) { return Integer.compare(o1, o2); } }; System.out.println("匿名内部类: " + comparator.compare(10, 20)); // 2.lambda表达式 comparator = (o1, o2) -> Integer.compare(o1, o2); System.out.println("lambda表达式: " + comparator.compare(10, 20)); // 3.方法引用 comparator = Integer::compare; System.out.println("方法引用: " + comparator.compare(10, 20));}
复制代码
1.5.3 类 :: 实例方法
格式:类 :: 实例方法
这个比较特殊,如下:
/** * 3. 类::实例方法 */@Testvoid test3() { Person person = new Person("Lambda"); // 1.匿名内部类 Function<Person, String> function = new Function<Person, String>() { @Override public String apply(Person person) { return person.getName(); } }; System.out.println("匿名内部类: " + function.apply(person)); // 2.lambda表达式 function = p -> p.getName(); System.out.println("lambda表达式: " + function.apply(person)); // 3.方法引用 function = Person::getName; System.out.println("方法引用: " + function.apply(person));}
class Person { private String name; public Person(String name) { this.name = name; } public String getName() { return this.name; }}
复制代码
1.5.4 类 :: new
引用构造器,其实就是引用构造方法
格式:类 :: new
/** * 4. 类::new */@Testvoid test4() { // 1.匿名内部类 Supplier<String> supplier = new Supplier<String>() { @Override public String get() { return new String("匿名内部类"); } }; System.out.println(supplier.get()); // 2.lambda表达式 supplier = () -> new String("lambda表达式"); System.out.println(supplier.get()); // 3.方法引用 supplier = String::new; System.out.println(supplier.get());}
复制代码
注:在使用 Lanbda 表达式时方法体中使用到了某个局部变量,则这个变量默认被 final 修饰。
2. Stream 流
2.1 什么是流
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来对 Java 集合运算和表达的高阶抽象。 Stream API 可以极大提高 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。 这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 变换,聚合等。
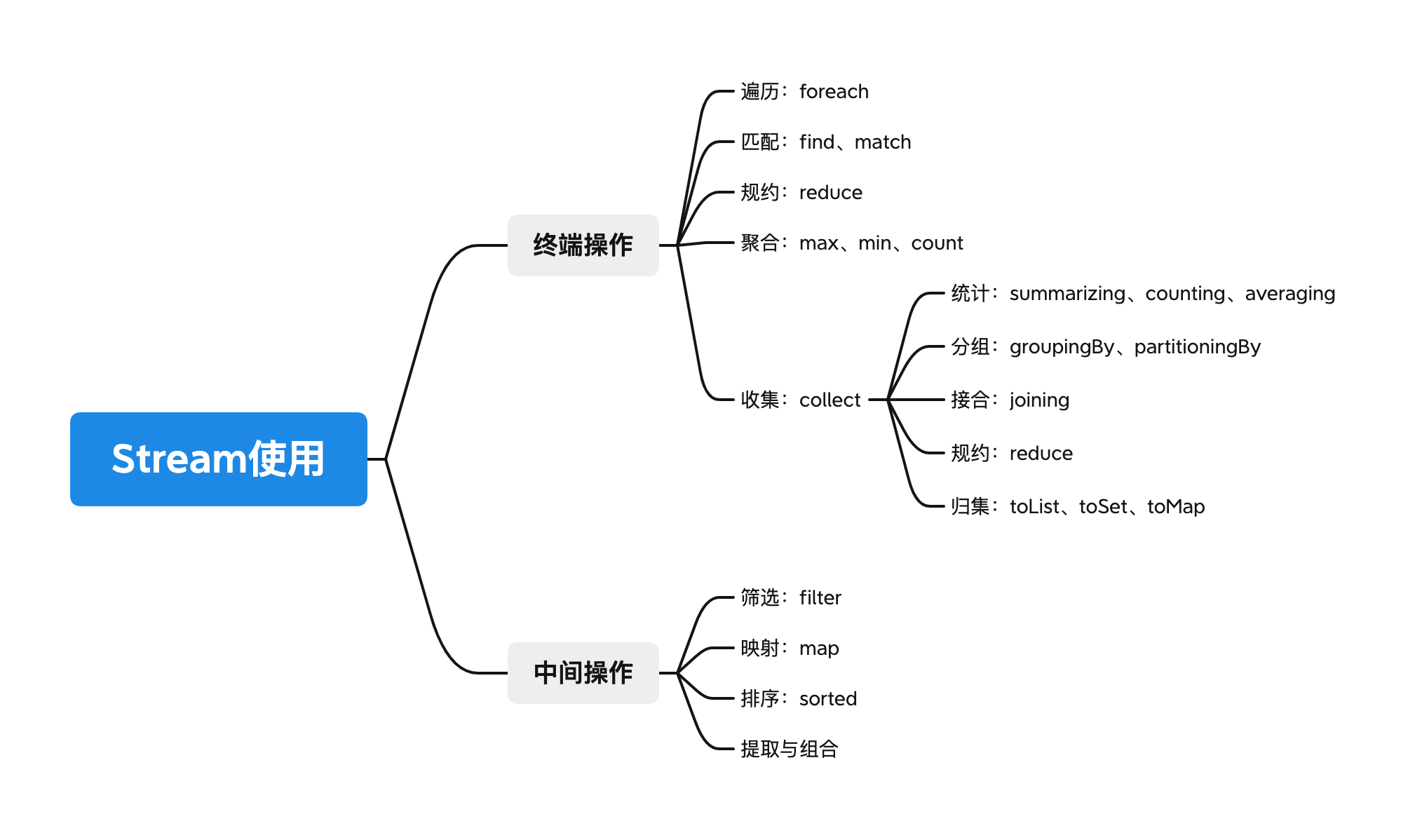
2.2 操作分类
流的种类分为两种,元素流在管道中经过中间操作的处理,最后由终端操作得到前面处理的结果:
中间操作:对流中的数据进行各种各样的处理,可以连续操作,每个操作的返回值都是 Stream 对象;
终端操作:终端操作执行结束后,会关闭这个流,流中的所有数据都会销毁。
因此它具有以下特性:
不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
不改变数据源,通常情况下会产生一个新的集合或一个值;
具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
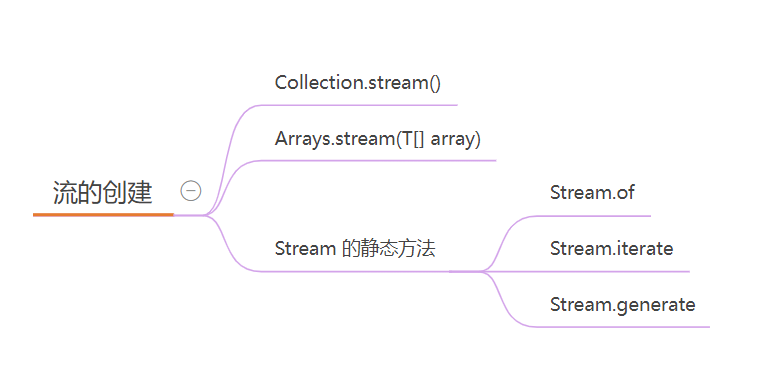
2.3 创建方式
Stream 的创建方式主要有以下几种:
1. Collection.stream()
@Testvoid collection_stream_test() { List<String> list = Arrays.asList("a", "b", "c", "d"); Stream<String> stream = list.stream();}
复制代码
2. Arrays.stream(T[] array)
@Testvoid arrays_stream_test() { int[] array = {1,2,3,4,5,6}; IntStream stream = Arrays.stream(array);}
复制代码
3. Stream.of
@Testvoid stream_of_test() { Stream<Integer> stream = Stream.of(1, 2, 3);}
复制代码
4. Stream.iterate
/** * 指定一个常量seed,生成从seed到常量 f(由 UnaryOperator返回的值得到)的流。 * 如下: * 根据起始值seed(0),每次生成一个指定递增值(n+1)的数,limit(5)用于截断流的长度,即只获取前5个元素。 */@Testvoid stream_iterate_test() { Stream<Integer> stream = Stream.iterate(0, n -> n + 1).limit(5); stream.forEach(System.out::println);}
复制代码
5. Stream.generate
/** * 返回一个新的无限顺序无序的流 */@Testvoid stream_generate_test() { Stream<Double> stream = Stream.generate(Math::random).limit(3); stream.forEach(System.out::println);}
复制代码
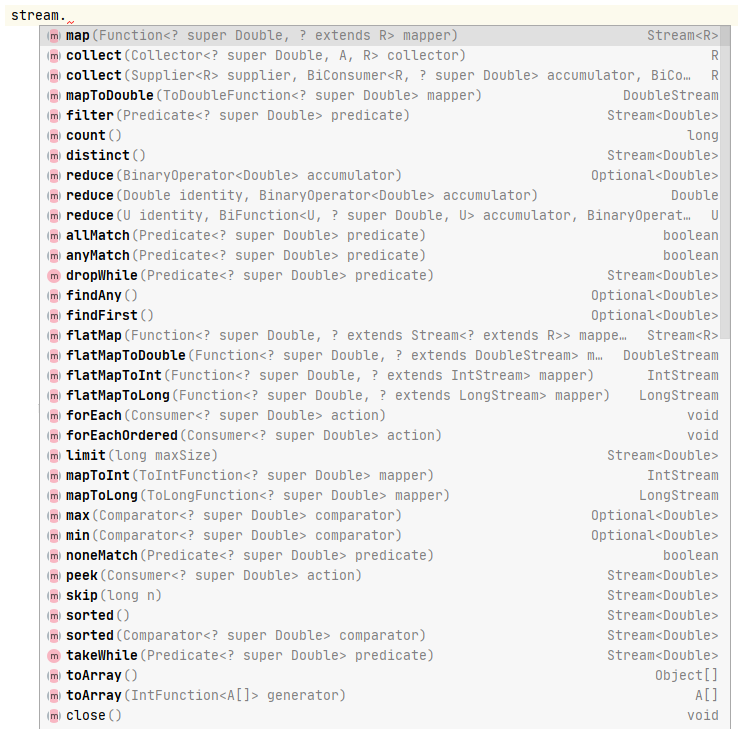
2.4 Stream API
Stream 有很多的 API 供我们使用,如下:
数据准备如下:
@Data@AllArgsConstructorclass User { // 姓名 private String name; // 年龄 private int age; //性别 private String sex; // 薪资 private int salary;}
@BeforeEachvoid init() { list = List.of(new User("亚索", 20, "男", 1000), new User("阿狸", 18, "女", 2000), new User("李青", 21, "男", 5000), new User("菲奥娜", 25, "女", 2500), new User("乐芙兰", 18, "女", 8000), new User("千珏", 30, "男", 10000));}
复制代码
2.4.1 遍历: foreach
对于数组、集合等可以通过 foreach 遍历。
@Testvoid foreach_test() { List<String> list = Arrays.asList("a", "b", "c", "d"); Stream<String> stream = list.stream(); stream.forEach(System.out::println);}
复制代码
2.4.2 筛选: filter
条件过滤,仅保留流中满足指定条件的数据,其他不满足的数据都会被删除。
因为 filter 方法接收的是一个 Predicate 接口,该接口的 boolean test(T t) 方法对给定的参数进行判断,然后返回一个布尔值。
@Testvoid filter_test() { // 查询年纪大于 20 的对象 Stream<User> stream = list.stream().filter(user -> user.getAge() > 20); stream.forEach(System.out::println); System.out.println("----------------------分割线--------------------------"); // 查询年纪大于 20 且性别为 男 的对象 stream = list.stream().filter(user -> user.getAge() > 20 && "男".equals(user.getSex())); stream.forEach(System.out::println);}
复制代码
测试如下:
StreamAPITests.User(name=李青, age=21, sex=男, salary=5000)StreamAPITests.User(name=菲奥娜, age=25, sex=女, salary=2500)StreamAPITests.User(name=千珏, age=30, sex=男, salary=10000)------------------------分割线------------------------StreamAPITests.User(name=李青, age=21, sex=男, salary=5000)StreamAPITests.User(name=千珏, age=30, sex=男, salary=10000)
复制代码
2.4.3 去重: distinct
去除集合中重复的元素,该方法没有参数,去重的规则与 HashSet 相同。
@Testvoid distinct_test() { List<String> list = Arrays.asList("a", "b", "a", "d"); Stream<String> stream = list.stream().distinct(); stream.forEach(System.out::println);}
复制代码
2.4.4 排序: sorted
将流中的数据进行排序,存在默认排序和自定义排序。
@Testvoid sorted_test() { // 按薪资排序 Stream<User> stream = list.stream().sorted((o1, o2) -> o1.getSalary() - o2.getSalary()); stream.forEach(System.out::println);}
复制代码
2.4.5 提取与组合:limit & skip
limit:限制,截取流中开头指定数量的元素
skip:跳过,跳过流中的指定数量的元素
配合使用,截取中间部分元素
@Testvoid limit_skip_test() { // 截取 list 中的前 3 个 Stream<User> stream = list.stream().limit(3); stream.forEach(System.out::println); System.out.println("----------------------------分割线--------------------------"); // 跳过 list 中的前 2 个 stream = list.stream().skip(2); stream.forEach(System.out::println); System.out.println("----------------------------分割线--------------------------"); // 跳过 list 中的前 2 个,然后截取 2个 stream = list.stream().skip(2).limit(2); stream.forEach(System.out::println);}
复制代码
2.4.6 映射: map、flatMap
① map
对流中的数据进行映射,用新的数据替换旧的数据,简单来说就是转为为你想要的 Stream 流。
因为 map 方法接收的是一个 Function 接口,该接口的 R apply(T t) 方法可以根据类型 T 的参数获取类型 R 的结果。
@Testvoid map_test() { // 把所有人的年龄改为 18 Stream<User> stream = list.stream().map(user -> { user.setAge(18); return user; }); stream.forEach(System.out::println); System.out.println("----------------------------分割线--------------------------"); // 返回所有人的名字 Stream<String> streamAllName = list.stream().map(user -> user.getName()); streamAllName.forEach(System.out::println);}
复制代码
② flatMap
对流扁平化处理,如下面 2 个例子。
一、获取用户所有的角色信息:
public class FlatMapTests {
static List<User> list = new ArrayList<>();
@Data @AllArgsConstructor class User { // id private Integer id; // 姓名 private String name; // 年龄 private int age; //性别 private String sex; // 薪资 private int salary; // 角色 public List<String> roles; }
/** * 应在当前类中的每个@Test方法之前执行注解方法 */ @BeforeEach void init() { list = List.of(new User(1, "admin", 20, "男", 1000, List.of("ROLE_ADMIN", "ROLE_USER")), new User(2, "张三", 18, "女", 2000, List.of("ROLE_USER")), new User(3, "李四", 21, "男", 5000, List.of("ROLE_ADMIN"))); }
/** * 获取用户所有的角色信息 * 不使用 flatmap */ @Test public void without_flatMap_test() { List<List<String>> roleList = list.stream() .map(User::getRoles) .peek(roles -> System.out.println(roles)) .collect(toList()); System.out.println(roleList); }
/** * 获取用户所有的角色信息 * 使用 flatmap */ @Test public void flatMap_test() { List<String> roleList = list.stream() .flatMap(user -> user.getRoles().stream()) .peek(roles -> System.out.println(roles)) .collect(toList()); System.out.println(roleList); }}
复制代码
可以看到,如果不使用 flatMap 返回值为 List<List<String>> 类型,使用之后为 List<String>。
二、处理流种产生的 Optional 元素:
当我们在调用某个方法时,它的返回值可能是一个 Optional 类型,如下:
/** * 不使用 flatmap */@Testpublic void without_flatMap_test1() { List<Optional<User>> collect = list.stream() .map(user -> findUserByName(user.getName())) .peek(roles -> System.out.println(roles)) .collect(toList()); System.out.println(collect);}/** * 使用 flatmap */@Testpublic void flatMap_test1() { List<User> userList = list.stream() .map(user -> findUserByName(user.getName())) .flatMap(Optional::stream) .collect(toList()); System.out.println(userList);}
public Optional<User> findUserByName(String name) { if ("admin".equals(name)) { return Optional.of(list.get(0)); } return Optional.empty();}
复制代码
2.4.7 查找: find
findFirst:从流中获取第一个元素
findAny:从流中获取任意一个元素
@Testvoid findFirst_test() throws Exception { // 查询第一个,返回一个 Optional Optional<User> first = list.stream().findFirst(); User user = first.get(); System.out.println(user); // 随机查询一个 Optional<User> any = list.stream().findAny(); User anyUser = any.get(); System.out.println(anyUser);}
复制代码
2.4.9 查找: match
allMatch:只有当流中所有的元素,都匹配指定的规则,才会返回 true
anyMatch:只要流中有任意的数据,满足指定的规则,都会返回 true
noneMatch:只有当流中的所有的元素,都不满足指定的规则,才会返回 true
@Testvoid match_test() throws Exception { // 判断年龄是否都大于 20 boolean allMatch = list.stream().allMatch(user -> user.getAge() > 20); System.out.println(allMatch); // 判断是否有年龄大于 20 boolean anyMatch = list.stream().anyMatch(user -> user.getAge() > 20); System.out.println(anyMatch); // 判断是否都不大于 20 boolean noneMatch = list.stream().noneMatch(user -> user.getAge() > 20); System.out.println(noneMatch);}
复制代码
2.4.10 归约: reduce
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
2.4.11 收集: collect
collect 主要是对一些进行操作过后的流收集起来,然后形成一个新的集合。
① 集合
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。常用是toList、toSet和toMap。
@Testvoid to_list_set_map_test() throws Exception { // 查询出所有人的名字并转为一个 List 集合 List<String> names = list.stream().map(User::getName).collect(Collectors.toList()); System.out.println(names); // 查询所有人的年龄去重 Set<Integer> ages = list.stream().map(User::getAge).collect(Collectors.toSet()); System.out.println(ages); // 查询工资大于 5000 的每个人的名字及其对应的工资 Map<String, Integer> map = list.stream().filter(user -> user.getSalary() > 5000).collect(Collectors.toMap(User::getName, User::getSalary)); System.out.println(map);}
复制代码
② 统计
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
@Testvoid count_test() throws Exception { // 统计平均工资 Double avg = list.stream().collect(Collectors.averagingDouble(User::getSalary)); System.out.println(avg); // 最高工资 Optional<Integer> max = list.stream().map(User::getSalary).collect(Collectors.maxBy(Integer::compare)); System.out.println(max.get());}
复制代码
③ 分组
partitioningBy 和 groupingBy 都是用于将数据进行分组的函数:
partitioningBy
public static <T>Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) { return partitioningBy(predicate, toList());}
复制代码
可以看出函数的参数一个 Predicate 接口,那么这个接口的返回值是 boolean 类型的,也只能是 boolean 类型,然后他的返回值是 Map 的 key 是 boolean 类型,也就是这个函数的返回值只能将数据分为两组也就是 ture 和 false 两组数据。
groupingBy
public static <T, K> Collector<T, ?, Map<K, List<T>>>groupingBy(Function<? super T, ? extends K> classifier) { return groupingBy(classifier, toList());}
复制代码
groupingBy 的函数参数为 Function 然后他的返回值也是 Map,但是他的 key 是泛型,那么这个分组就会将数据分组成多个 key 的形式。
@Testvoid group_test() throws Exception { // 按工资是否高于 5000 分为两部分 Map<Boolean, List<User>> partitioningBy = list.stream().collect(Collectors.partitioningBy(user -> user.getSalary() > 5000)); System.out.println(partitioningBy); // 按照性别分组 Map<String, List<User>> groupingBySex = list.stream().collect(Collectors.groupingBy(User::getSex)); System.out.println(groupingBySex); // 先按照性别分组,在按照年龄分组 Map<String, Map<Integer, List<User>>> groupingBySexAge = list.stream().collect(Collectors.groupingBy(User::getSex, Collectors.groupingBy(User::getAge))); System.out.println(groupingBySexAge);}
复制代码
④ joining
joining可以将 stream 中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。比如常见的逗号分割字符。
@Testvoid joining_test() throws Exception { // 将姓名按照逗号分割 String names = list.stream().map(User::getName).collect(Collectors.joining(",")); System.out.println(names);}
复制代码
3. Optional
Optional 类是一个可以为 null 的容器对象。如果值存在则 isPresent() 方法会返回 true,调用 get() 方法会返回该对象。
Optional 是个容器:它可以保存类型 T 的值,或者仅仅保存 null。Optional 提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
3.1 创建和获取
@Testvoid optional_stream_test() { Optional<Object> empty = Optional.empty(); System.out.println(empty.get()); Optional<String> of = Optional.of("of"); System.out.println(of.get()); Optional<String> nullable = Optional.ofNullable(null); System.out.println(nullable.get());}
复制代码
3.2 判断
3.3 过滤
3.4 映射
















评论