
一篇文章带你掌握性能测试工具——Jmeter
在目前的中大型企业中,仅仅进行功能测试已经不足以满足企业的需求,在重大客户基数下性能测试将会直接影响到用户体验
所以在这篇文章中我们将会学习性能测试的相关知识以及常用工具 Jmeter
我们将会从以下角度进行介绍:
性能测试基础信息
性能测试工具介绍
性能测试基础信息
首先我们需要去系统的了解一下性能测试的相关信息
性能测试简述
首先我们需要了解我们为什么需要学习性能测试:
在目前企业里功能测试是最基本的需求,但随着用户量的增加,产品的品质也需要逐渐优化
性能测试主要是针对产品的执行速率,执行占用资源,并发度,最大可承受执行次数等多方面进行测试并判断是否满足产品需求
接下来我们需要理解性能主要针对什么:
性能测试主要针对两方面进行评估
时间层面:用户执行该操作最后效果展现所消耗的时间
资源层面:用户执行该操作对自身计算机所占用 CPU 等资源的消耗比率
那么性能测试就是在多种情况下对性能情况进行测试得出结果:
使用自动化工具,模拟不同场景下,对软件各项性能指标进行测试和评估的过程
最后我们简单讲一下性能测试的目的:
评估当前系统能力
寻找性能瓶颈,优化性能
评估软件是否满足未来需求,是否需要优化
性能测试对比
我们在之前的文章中已经学习了功能测试,那么我们简单给出两者的区别:
我们还需要知道其两者之间的先后顺序关系:
在前后端提测之后,我们首先需要进行功能测试并回归完完全功能之后,判断该产品无任何问题后再进行性能测试
在完成功能测试和性能测试后,两者自动化的书写无先后顺序关系
性能测试分类
我们下面来介绍性能测试的多种测试方式
基准测试
首先我们需要介绍基准测试:
狭义:基准测试其实就是单用户测试
广义:基准测试是采用单用户测试在某一固定场景下进行测试并得到具体数据,以该数据作为基准和后续测试数据进行对比
我们给出一个简单实例来说明基准测试:
我们在最开始采用一种情况进行测试并得到结果进行记录,后续我们采用其他方式进行测试并与基准测试结果进行对比
基准测试:项目 1.0 版本,测试机配置(8G+16G),单用户查询一万条数据采用 3.0s
后续测试:项目 1.0 版本,测试机配置(8G+32G),单用户查询一万条数据采用 2.0s
后续测试:项目 1.1 版本,测试机配置(8G+16G),单用户查询一万条数据采用 2.5s
那么基准测试的用途也很明显:
基准测试从不会单独出现,它需要与其他数据比较才有意义
基准测试采用单用户测试,主要是为了给后续多用户测试综合测试场景提供参考意义
基准测试采用测试机测试,主要是为了给后续不同配置测试机测试综合测试场景提供参考意义
负载测试
我们同样首先来介绍负载测试的意义:
通过逐步增加系统负载,确定满足系统性能指标情况下(响应时间或 CPU 占用率),找到该系统的最大承受量
我们给出一个简单实例来说明负载测试:
我们首先会从产品那里得到一个客户性能需求,例如该电梯从 1 楼运输到 5 楼的运行时间控制在 15s 内
那么我们就需要采用不同重量进行测试,判断是否满足客户需求并将该负载结果告诉产品
我们会从下述 case 中选择最大的满足性能需求的重量作为负载测试的最终结果
case1:100KG 物品在电梯中从 1 楼运输到 5 楼的运行时间是 10s
case2:500KG 物品在电梯中从 1 楼运输到 5 楼的运行时间是 10s
case3:700KG 物品在电梯中从 1 楼运输到 5 楼的运行时间是 14s
case4:900KG 物品在电梯中从 1 楼运输到 5 楼的运行时间是 17s
针对负载测试我们还需要知道这些内容:
系统对外宣称的一般是最大负载量
负载测试的测试时间一般为 1-2 小时
通过负载测试可以确定系统的最大负载量和极限负载量
负载测试的用途主要针对客户需求:
系统最大负载量达到客户需求时,系统才能正式上线使用
稳定测试
我们首先给出稳定性测试的概念:
稳定性测试主要是针对产品在稳定运行(正常业务负载下)的情况下进行长时间测试,并保证产品满足线上业务需求
我们现实中其实存在很多案例:
因为不同业务存在不同业务场景,所以稳定性测试的测试时间是不同的
例如 12306 铁路抢票软件,每天的 0 点到 6 点之间是不允许抢票的,那么我们只需要测试在一天情况下能否满足业务需求
例如淘宝京东购物软件,每天无时无刻都可以进行购物,那么我们测试时长就需要稍微拉长一些来判断能否满足业务需求
负载测试的用途主要针对产品持久性:
系统在用户要求的业务负载下达到规定的执行时间时,系统才能正式上线使用
压力测试
我们首先给出压力测试的概念:
压力测试主要针对在高压情况下,查看系统是否存在功能隐患,判断是否是否良好的容错能力和可恢复能力
针对压力测试主要分为两方面的压力测试:
系统在持续高压情况下的稳定性测试
系统在超高压情况下崩溃后的恢复能力测试
我们分别给出两个案例:
并发测试
我们同样给出并发测试的概念:
并发测试是在极短的时间内,发送多个请求,判断是否出现资源争夺导致的异常情况
我们在日常生活中可以见到很多案例:
双十一定时抢券活动
春节火车票抢购时间
但是我们需要注意到的是并发测试和负载测试虽然都是测试资源消耗或者说是资源的最大承受量,但两者是不同的:
负载测试:是指一段时间内,在高负载的情况对于资源的消耗,是否会存在资源耗尽问题
并发测试:是指在极短时间内,判断是否会出现由于资源互相抢夺而导致功能无法实现问题
其实并发测试的主要测试点更像是我们操作系统中出现的死锁情况:
假设我们的资源 A 存在 10 个,资源 B 存在 10 个
同时存在 20 个线程都需要资源 A 和资源 B,同时启动导致 10 个线程得到资源 A,10 个线程得到资源 B
但两者都无法得到剩余的线程,从而出现资源死锁问题,导致资源无法释放,功能无法实现从而出现并发问题
性能测试指标
我们在进行性能测试时,当然不能只根据我们的感觉来判断该性能是否符合标准,因此就出现指标这一概念
响应时间
首先我们来介绍响应时间:
狭义:用户进行操作后,得到最后结果之间所消耗的时间
广义:主要包含浏览器传输时间,服务器处理时间,服务器传输时间,数据库处理时间等多时间汇总所得到的结果
我们可以简单给出一张图片进行解释:
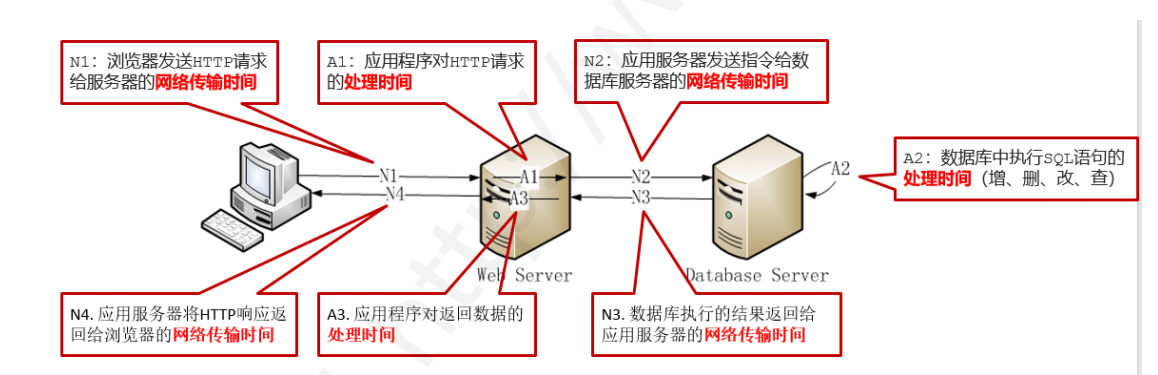
我们的响应时间通常是我们进行性能测试最直接的判断结果:
例如我们查询一万条数据时所需要得到的响应时间在 3s 之内
但我们还需要注意一点:
我们所获取的响应时间并不能是单次运行所得到的时间
而是在多次运行下,所得到的所有运行时间的平均值(Jmeter 会有一个字段存储平均响应时间)
吞吐量
我们来简单介绍一下吞吐量:
吞吐量指单位时间内处理客户端的请求数量,可以直接体现出系统的性能承载能力
吞吐量主要分为两种:
TPS 每秒事务数
QPS 每秒查询数
我们首先来介绍 TPS:
即控制服务器每秒处理的事务请求的数量
该计算仅仅针对事务的数量进行计算,一次事务(一次点击)可能会出现 1 个或多个请求,而这些请求都被划分为一次事务
我们采用一张图片解释:
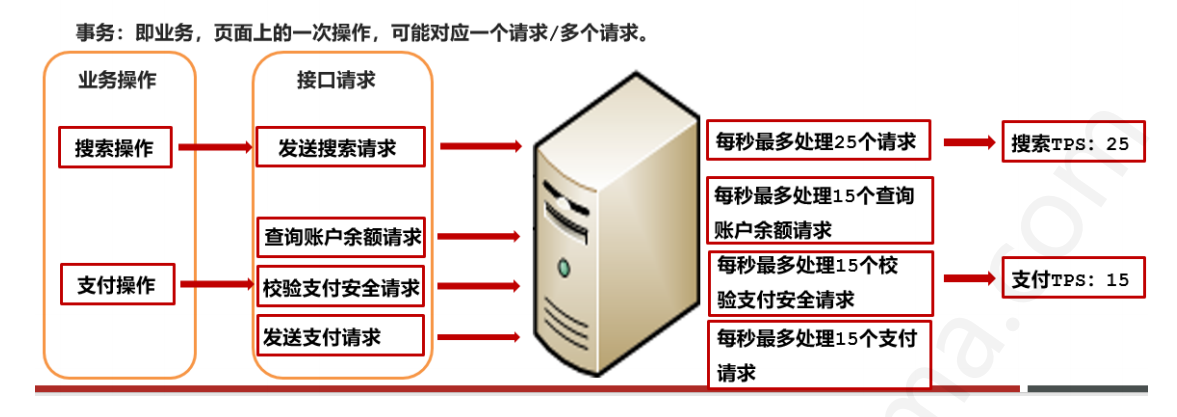
我们再来介绍 QPS:
即控制服务器每秒处理的指定请求的数量
该计算是指针对某单一接口请求,去统计该单位时间内所处理的请求个数
我们同样采用一张图片解释:

资源利用率
我们来简单介绍一下资源利用率:
即计算机内各种资源的使用情况
通常是一个比率值,采用当前使用资源数/计算机全部资源数来获取
我们常见的一些计算机资源包括有:
CPU 使用率
显卡使用率
内存使用率
磁盘 IO 效率
网络传输率
性能测试流程
首先我们直接给出一张性能测试流程图:
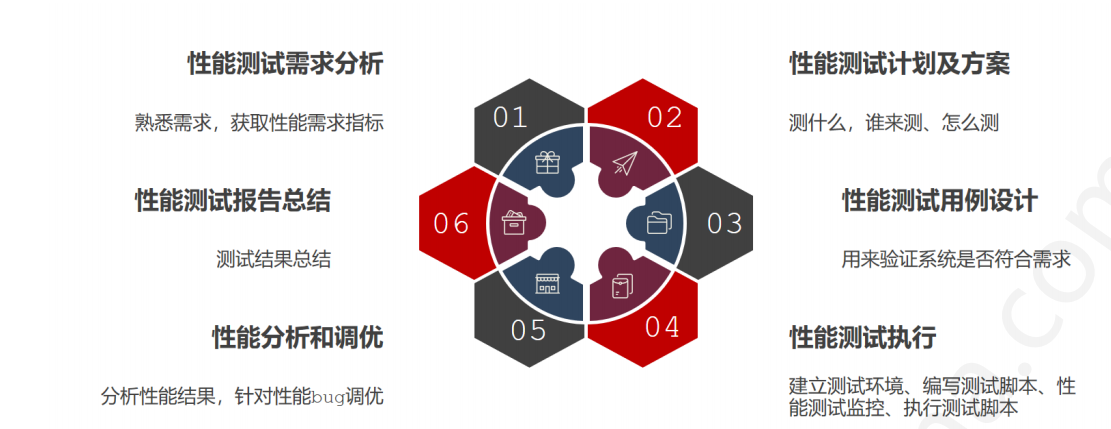
需求分析
首先我们来讲解性能测试需求分析:
所有测试的需求分析的过程都是相同的,由产品给出具体指标,由我们进行解析梳理
我们通常将性能测试需求分析划分为四步:
测试计划
测试计划其实主要依照公司主管所制定的计划:
所测内容:依据项目背景,给出测试目的及测试范围即可
所测人员:由主管进行分配各个人员的分工以及完成时间等信息
所测方法:测试方法可以由主管指定,也可以由各个人员进行判断
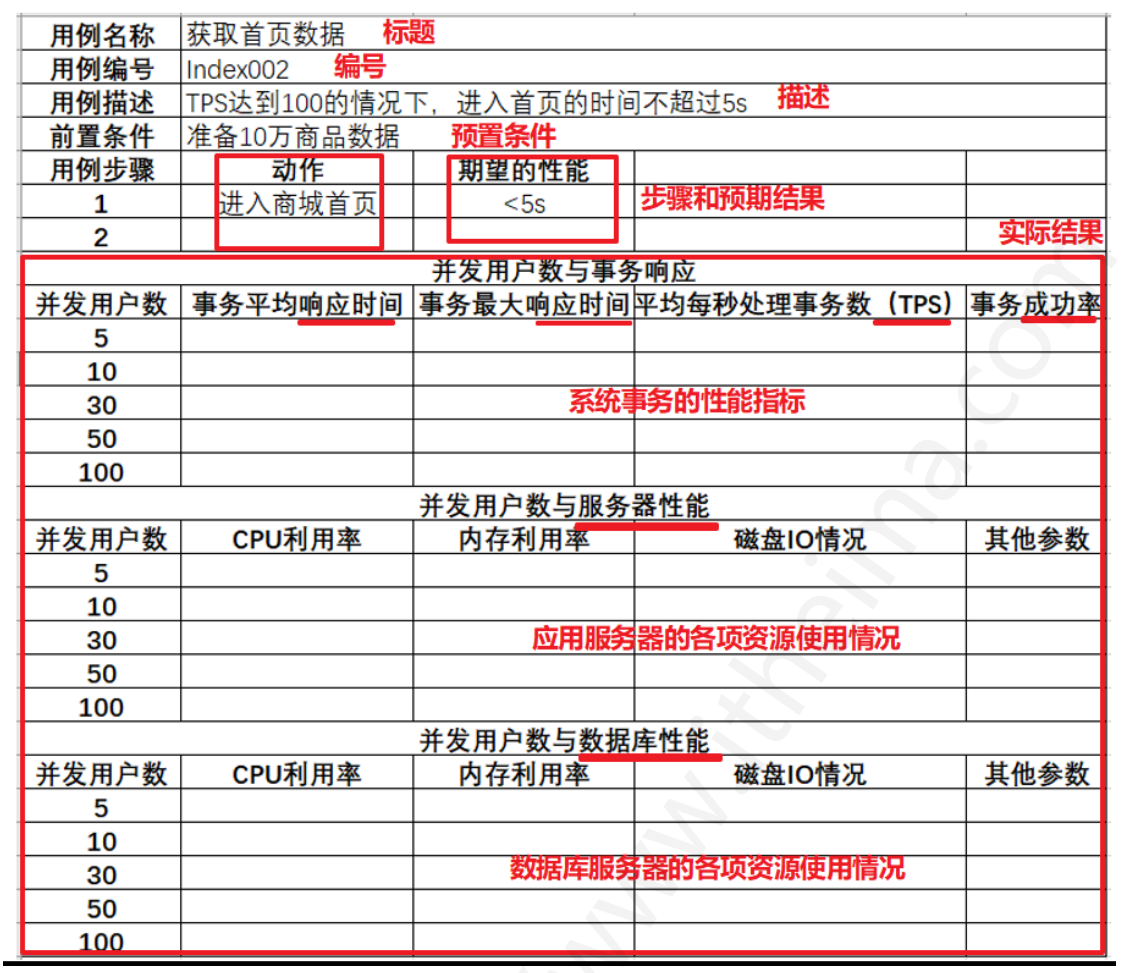
测试用例
我们给出一张测试用例的常用模板图即可:
测试执行
我们的性能测试通常通过工具进行测试:
由于性能测试需要长时间点击或频繁点击,人工无法实现
我们通常通过参数化和脚本等,然后结合测试工具 Jmeter 或其他性能测试工具等去结合执行
我们的性能测试执行大概划分为四阶段:
测试分析
我们在执行测试用例之后会获取到其性能测试结果,我们只需要对比即可:
针对不满足产品需求的性能测试结果,我们需要要求后端对其进行优化,并在优化后回归测试
测试报告
我们在测试结束之后通常需要去书写测试报告,主要是为了我们后续测试作为对照,主要包含以下内容:
测试流程记录
测试风险评估
测试结果记录
测试分析记录
测试总结改进
性能测试工具介绍
接下来我们开始正式介绍 Jmeter 工具的使用
Jmeter 性能比较
其实除了 Jmeter 之外,我们还有很多性能测试工具,其中之前比较出名的就是 Loadrunner,我们这里简单介绍一下两者的区别:
Jmeter 下载安装
Jmeter 的下载非常简单,我们只需要到官网下载对应压缩包即可:Apache JMeter - Download Apache JMeter

我们将其压缩到对应文件夹即可,注意需要是全英文文件夹,下面我们使用一张图来介绍各文件内容:
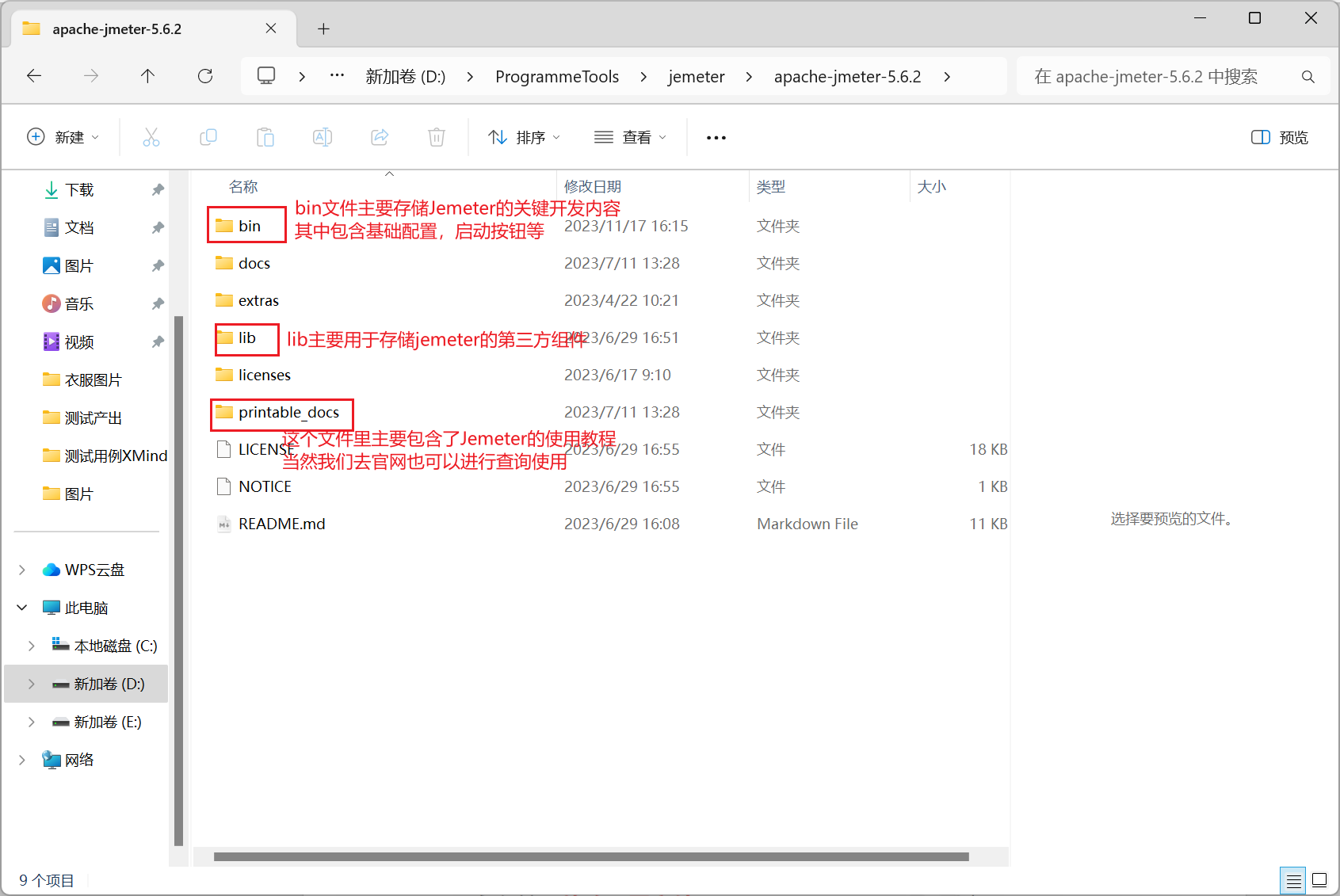
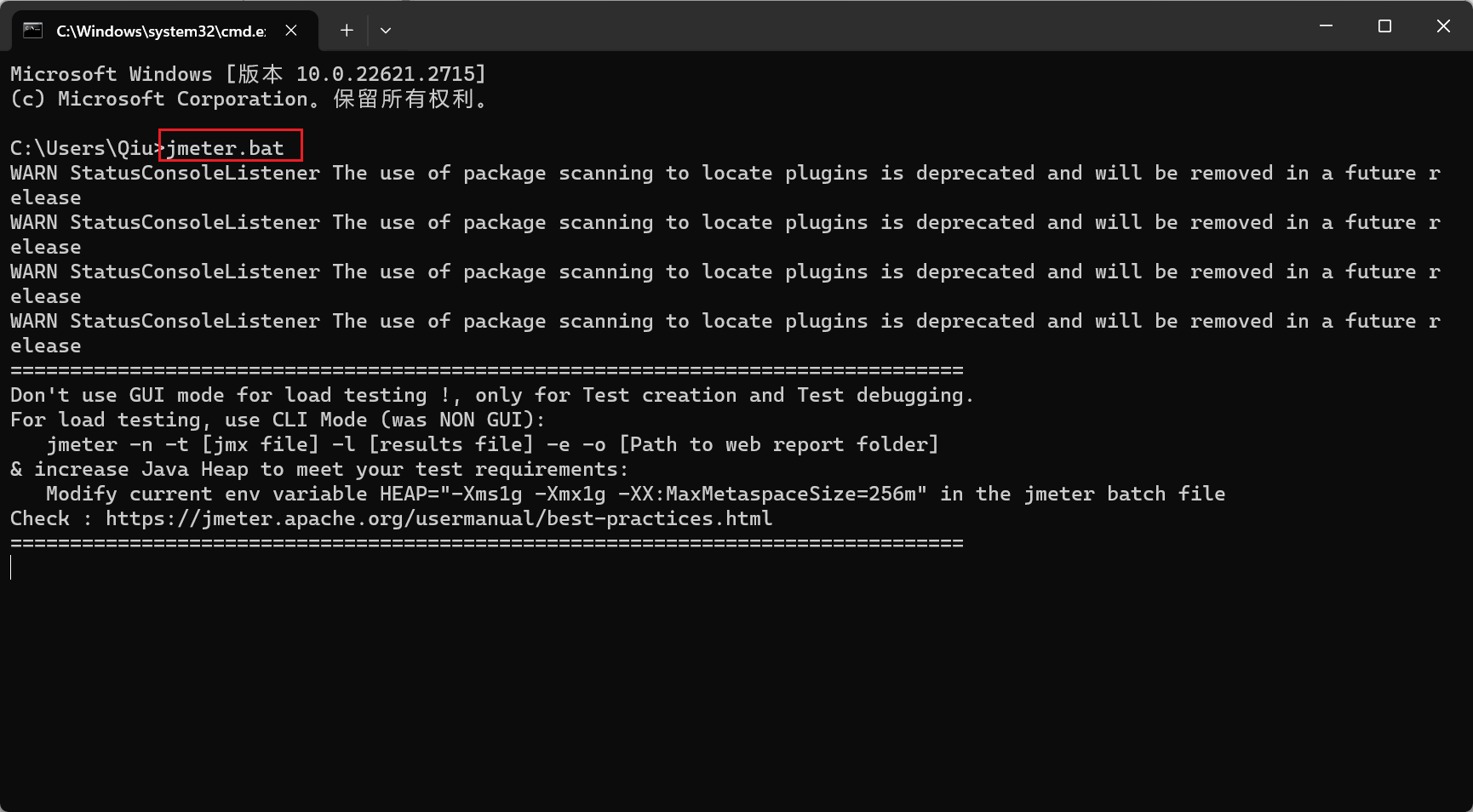
如果我们希望快速打开 Jmeter,我们通常会将该文件的 bin 目录放入我们的环境变量,那么我们仅需要使用一行简单命令就开启服务:
最后我们给出一下 Jmeter 的一个页面展示:
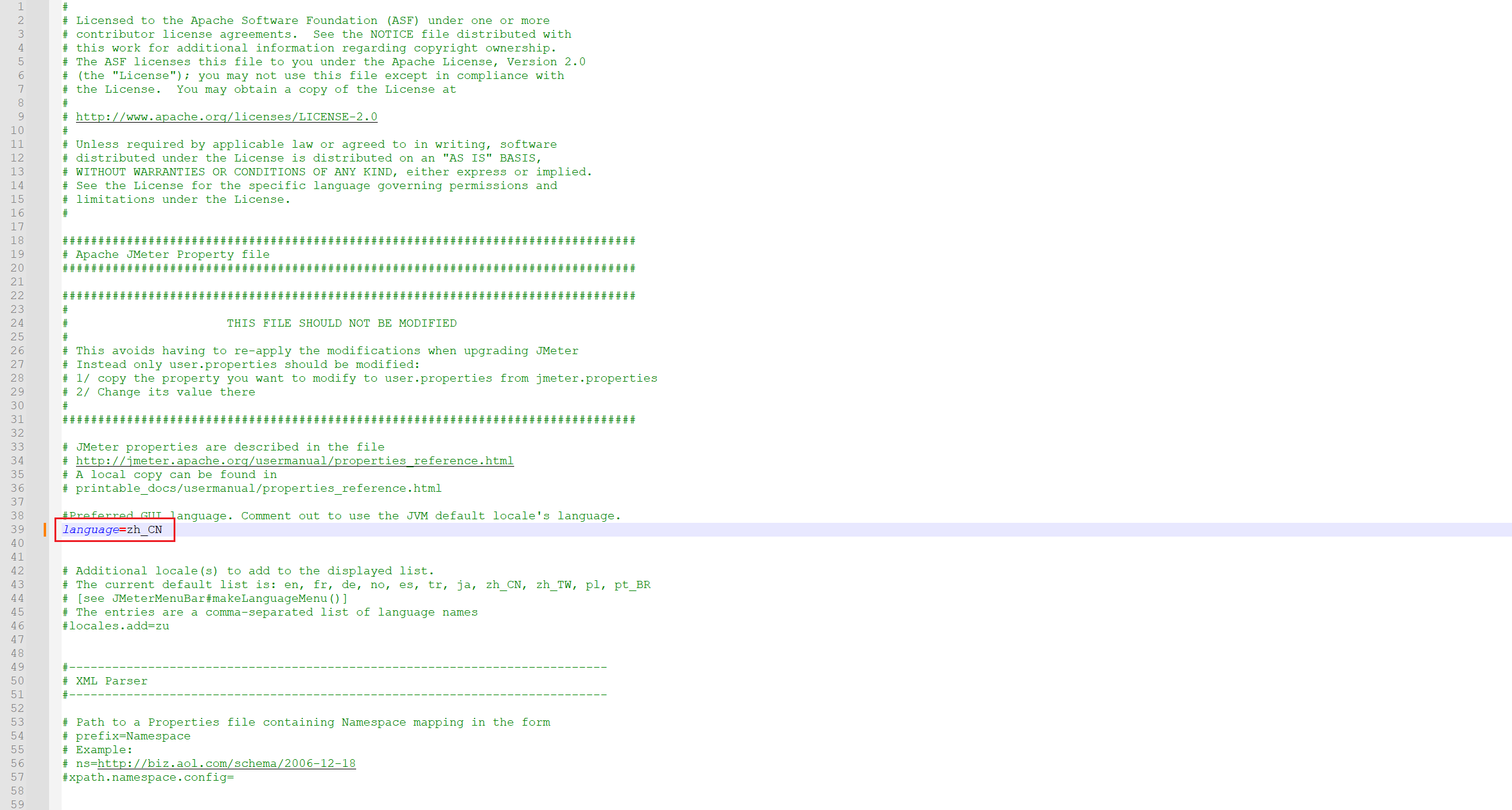
这里我们所看到的是英文界面,当然我们可以将其变为中文界面,我只需要进入 bin 目录的 Jmeter.properties 文件修改:
最后我们给出一个小提示,因为我的电脑存在这个问题,所以记录下来:
Jmeter 元件介绍
我们首先给出一张 Jmeter 工具的相关元件图,我们会在下面进行解释:
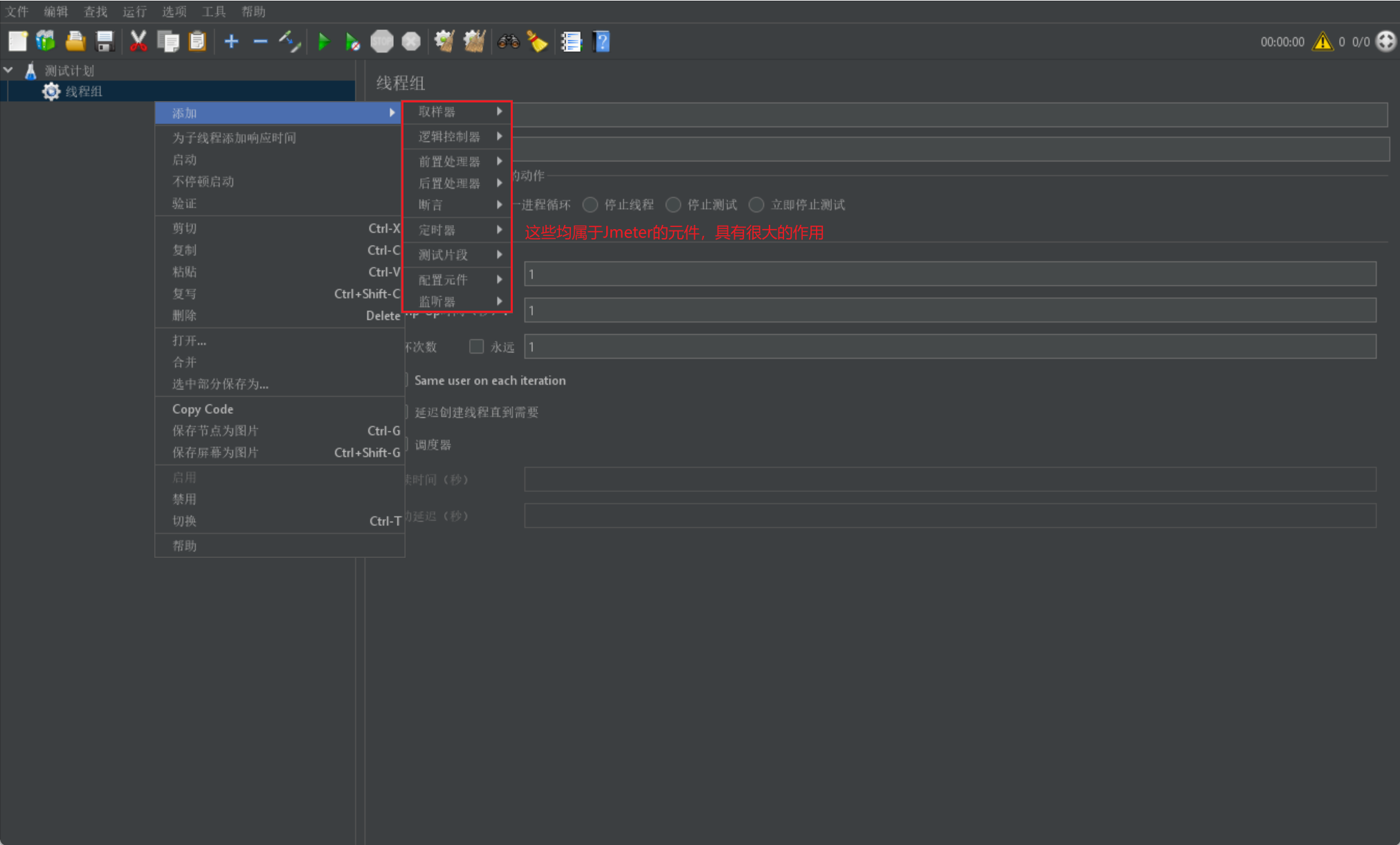
下面我们依次来介绍上述元件的作用:
接下来我们需要知道元件的作用范围都在哪里:
我们还需要注意其执行顺序:
我们给出一张图,并给出它的执行顺序,大家可以明白其作用范围:
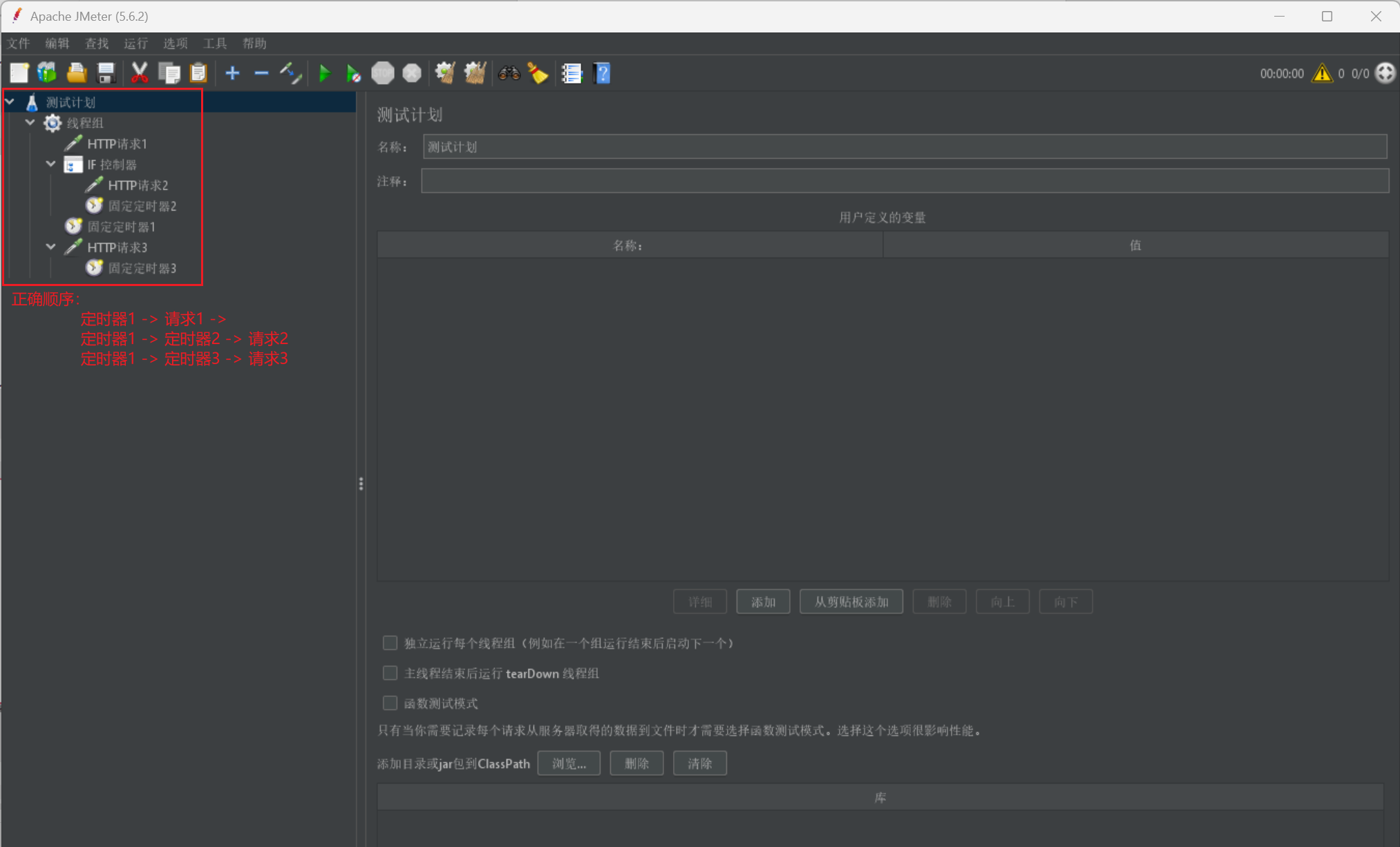
Jmeter 案例展示
首先我们给出一个最简单的案例进行展示:
我们这里首先给出 http 请求的界面展示,后续我们会详细介绍:

然后我们这里直接启动,给出查看结果树的执行界面展示:
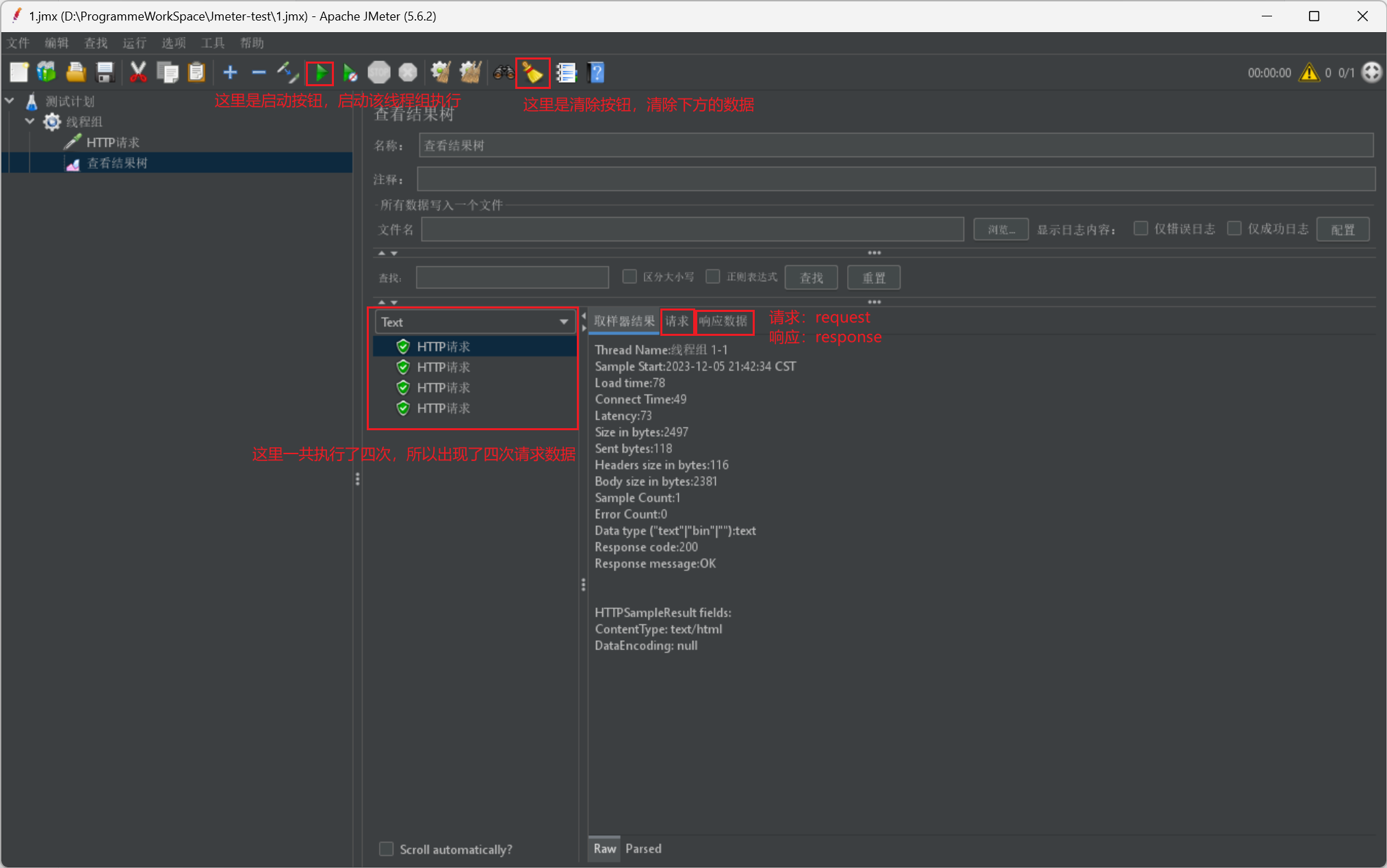
Jmeter 线程介绍
在了解其元组具体信息之前,我们首先需要了解一下线程组:
我们给出线程组的展示图并说明其具体使用参数信息:
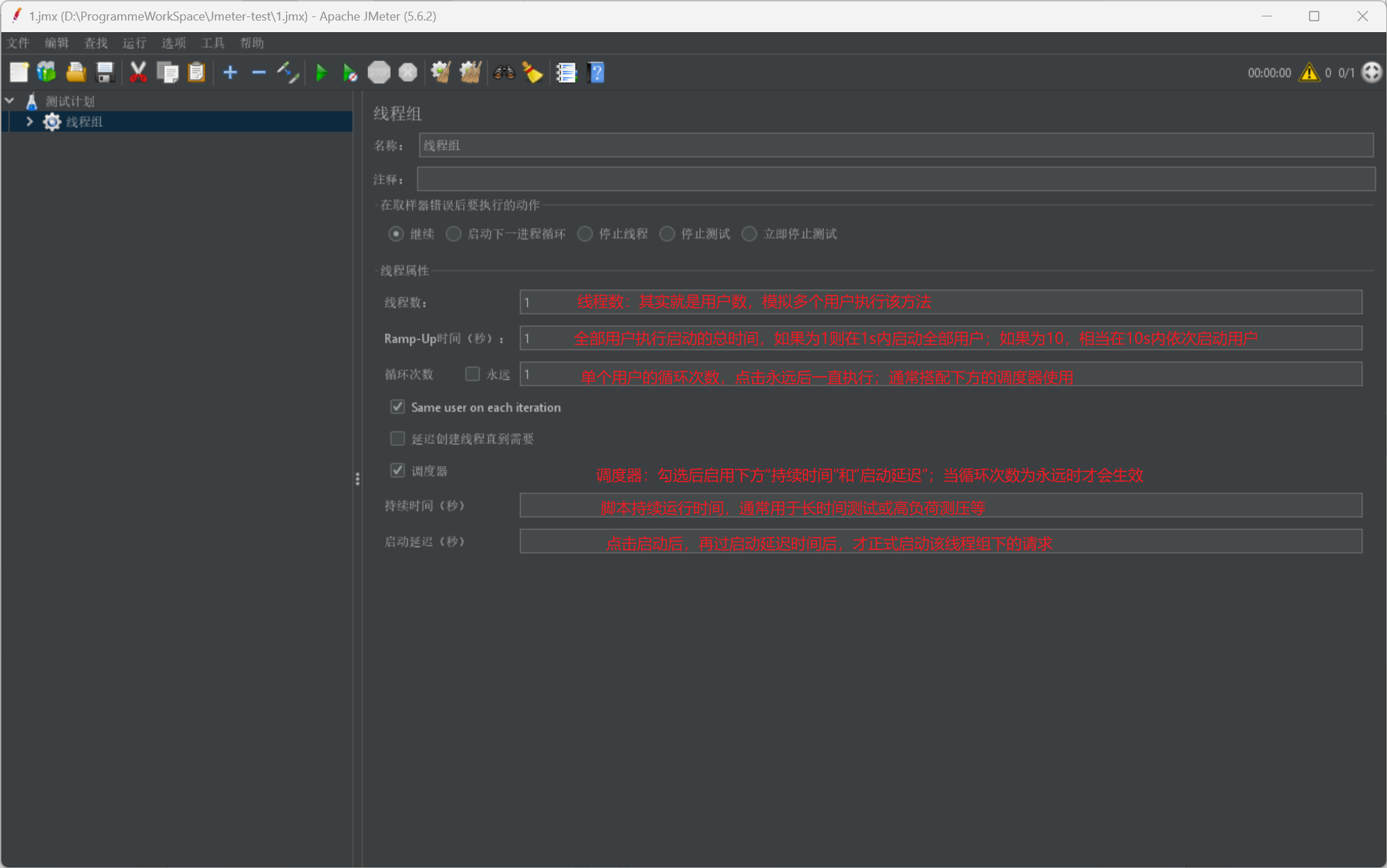
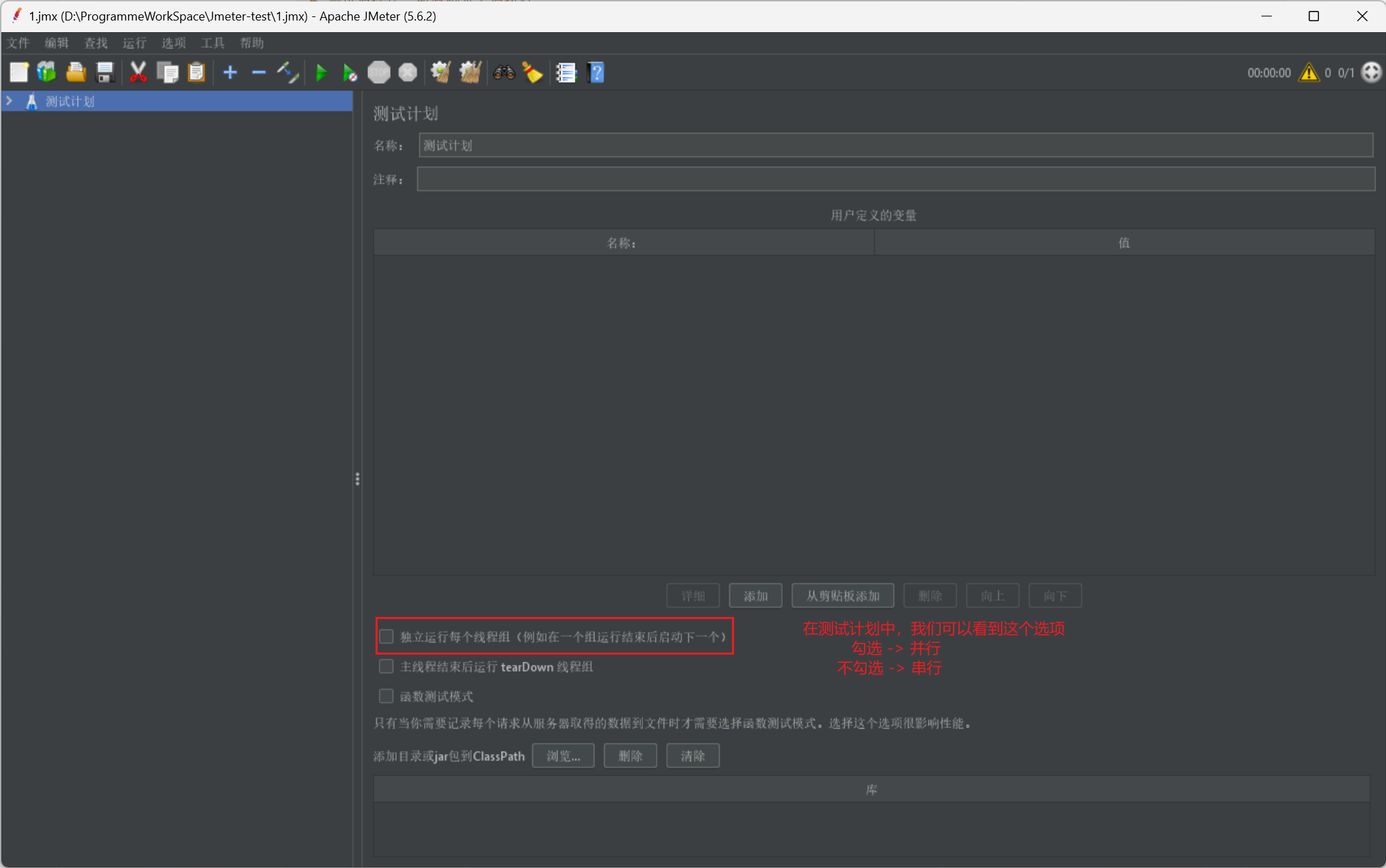
而最后我们在给出一个小贴士,是关于线程组的并行或串行启动的开关按钮:
Jmeter 交互介绍
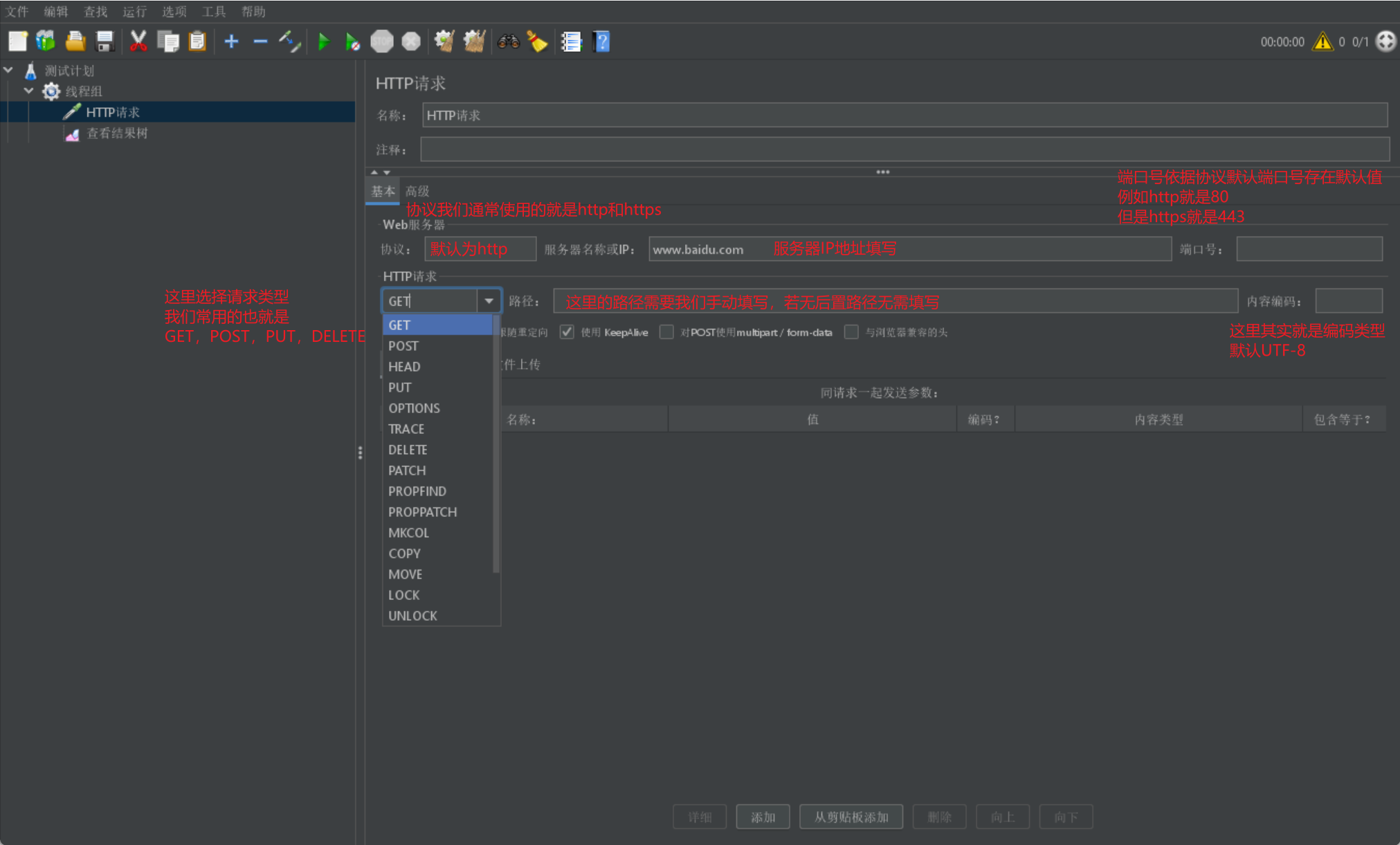
我们直接给出 Jmeter 请求的一张展示图,并在该展示图上进行介绍:
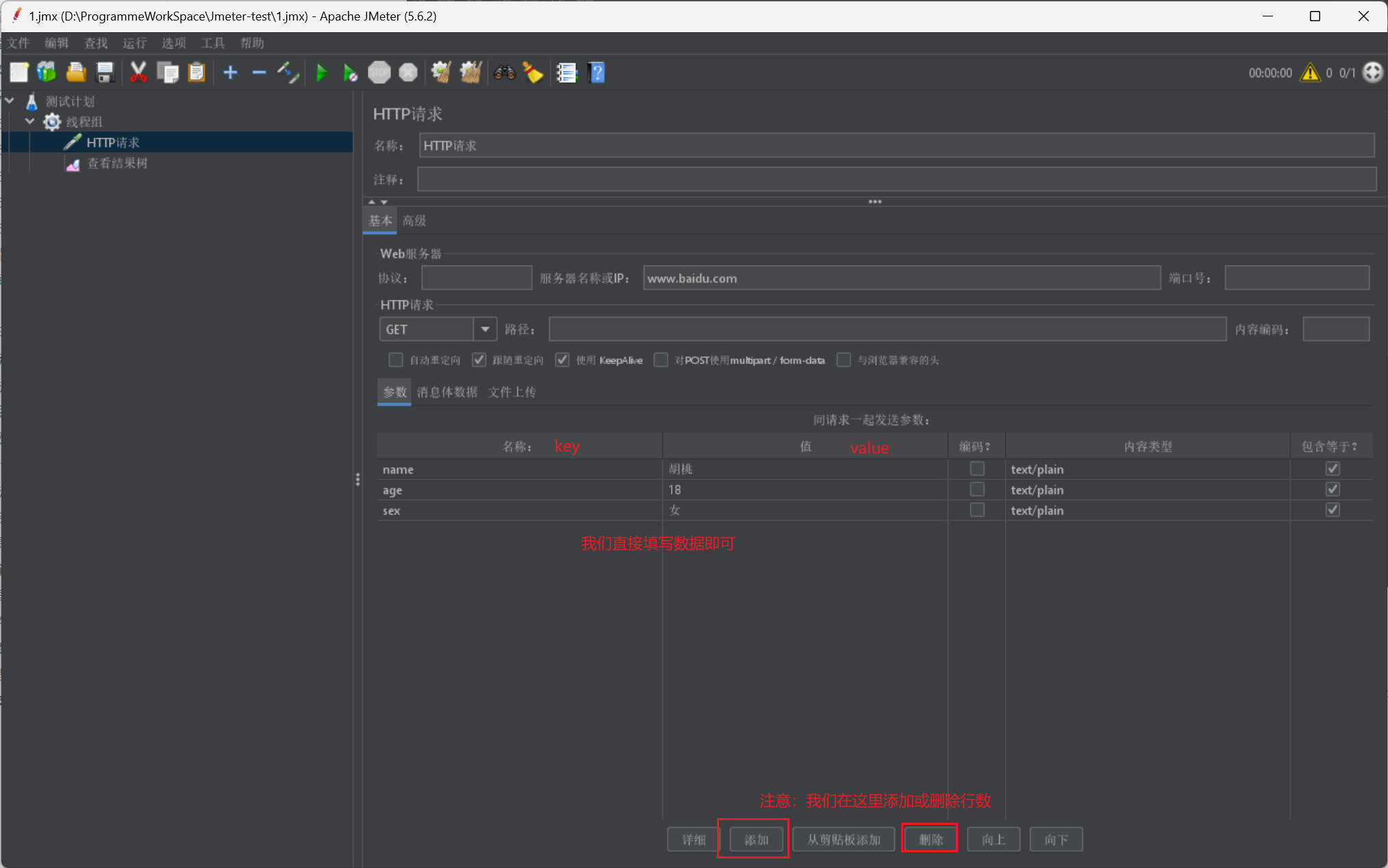
除了这些请求之外,我们在请求时,还需要传递参数信息:
如果是 get 请求,我们可以直接在路径后以?key1=value1&key2=value2 的形式进行传递
其他请求类型,我们通常在下方的参数栏进行传递,也可以选择消息体数据采用 JSON 或其他格式传递,如果传递文件可以选择第三种
我们给出一张展示图:
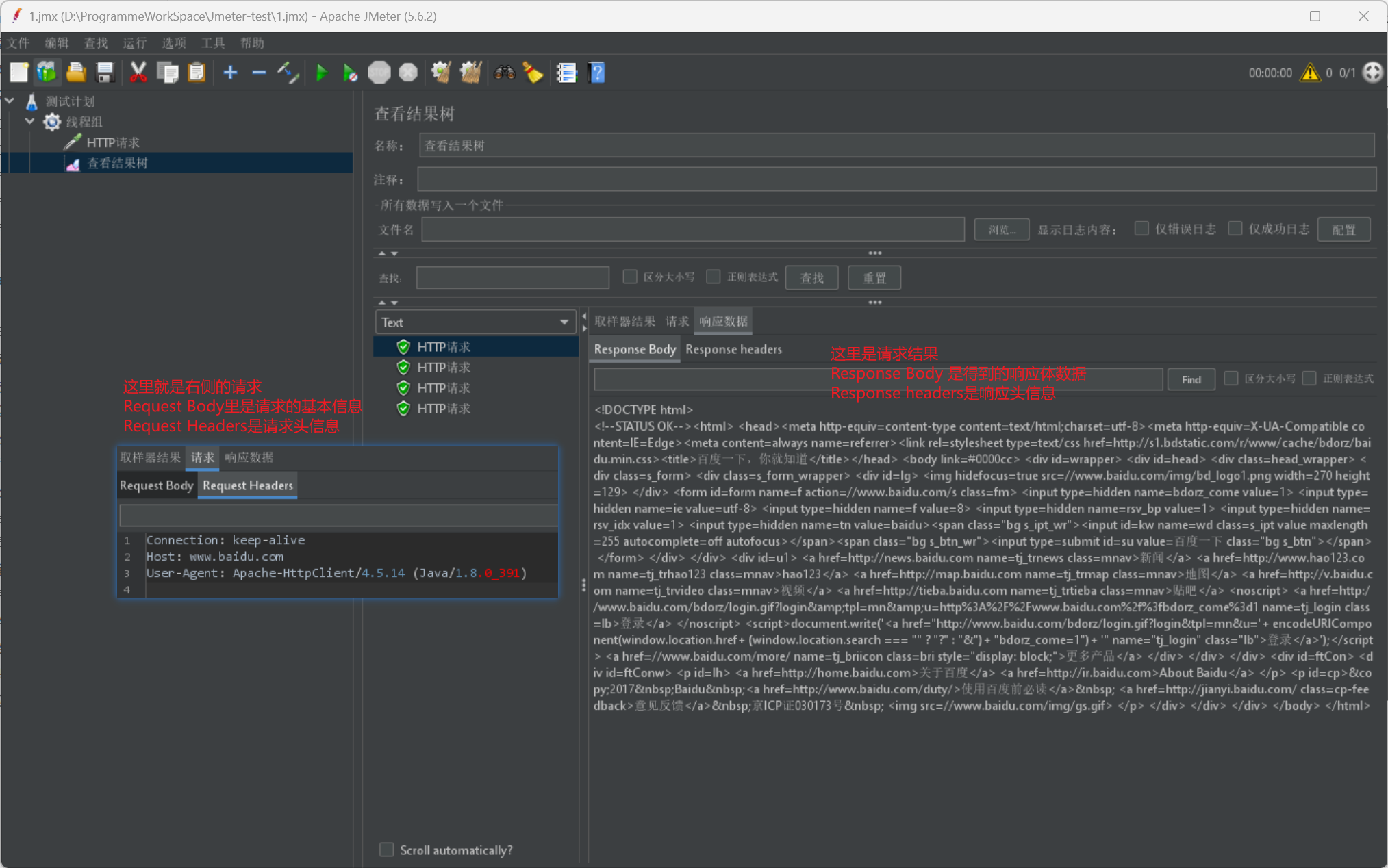
我们顺便给出一张查看结果树的请求和响应展示图:
Jmeter 参数处理
我们在之前的自动化测试中也学习到了参数化,现在我们来学习 Jmeter 的参数化设置:
参数化的本质就是实现测试数据与测试方法的分离
参数化主要使用不同的测试数据,调用相同的测试方法进行测试
全局变量
我们首先学习 Jmeter 参数化最基本的全局变量:
用户定义的变量 —— 全局变量
首先我们进行一些全局变量信息的讲解:
我们直接给出全局变量定义的界面:
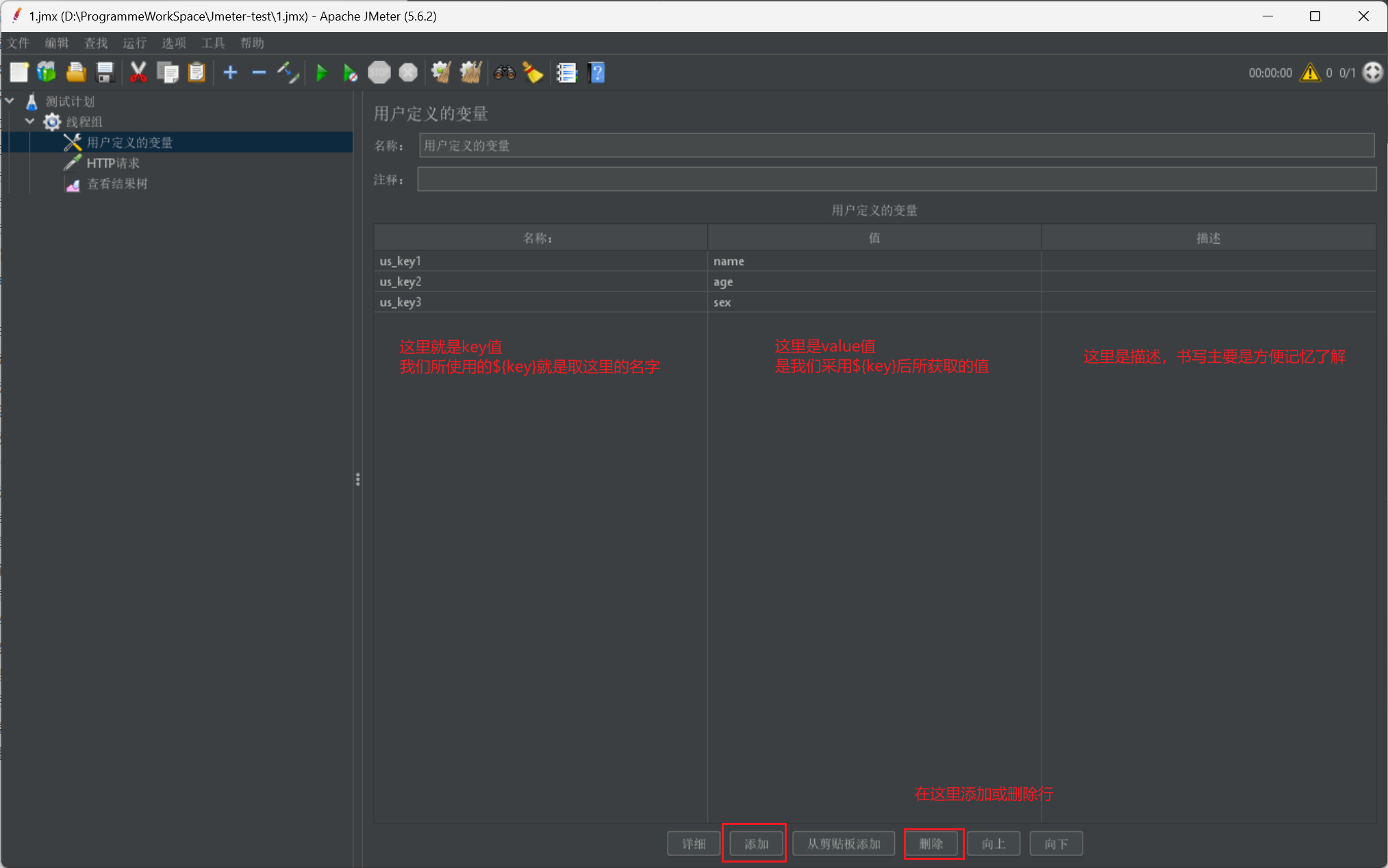
我们再给出一张使用图:
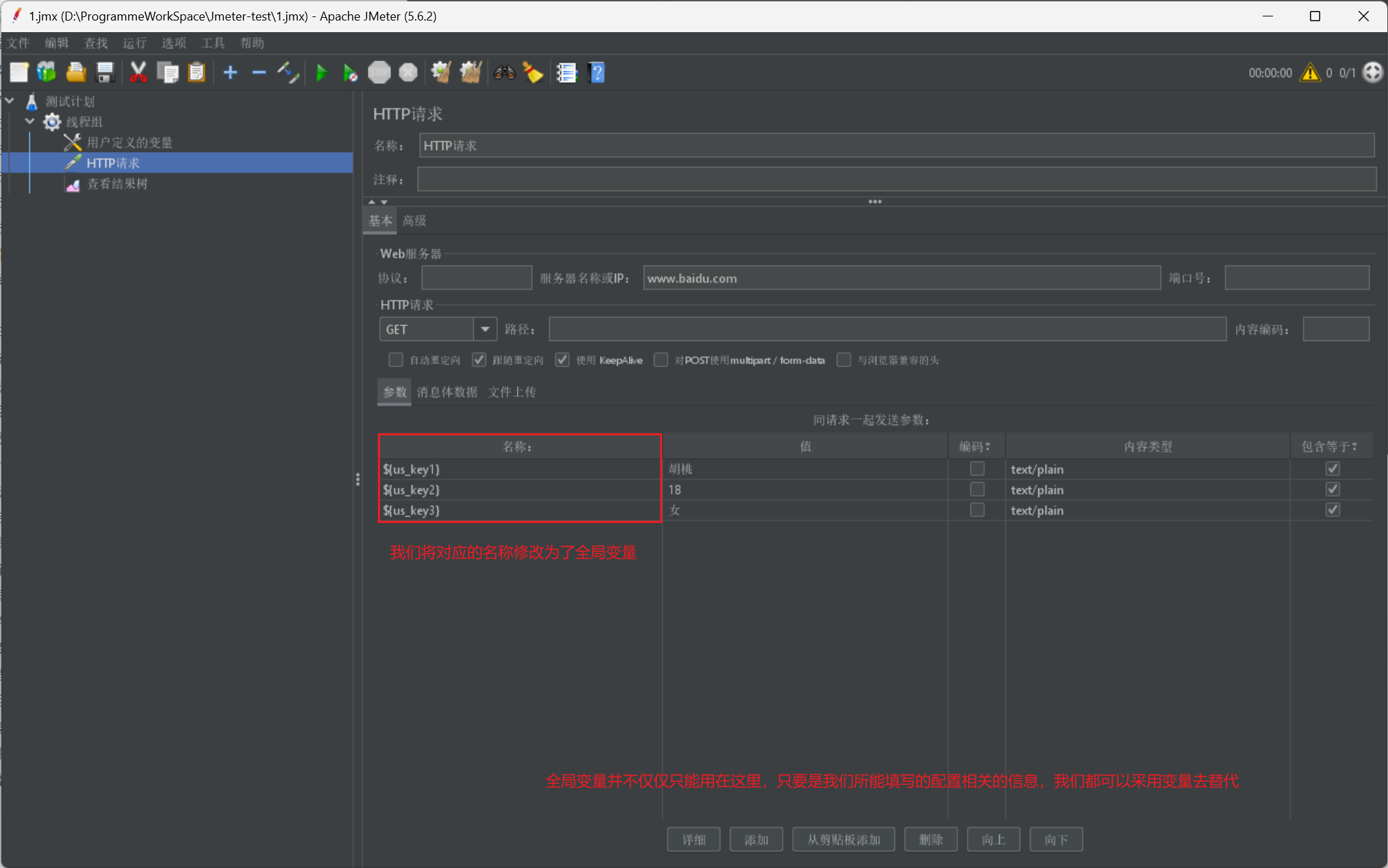
用户参数
同样我们首先给出用户参数的相关概念:
用户参数 —— 为每个用户分配不同的参数值
我们先来进行简单介绍:
我们首先给出一张用户参数设置图:
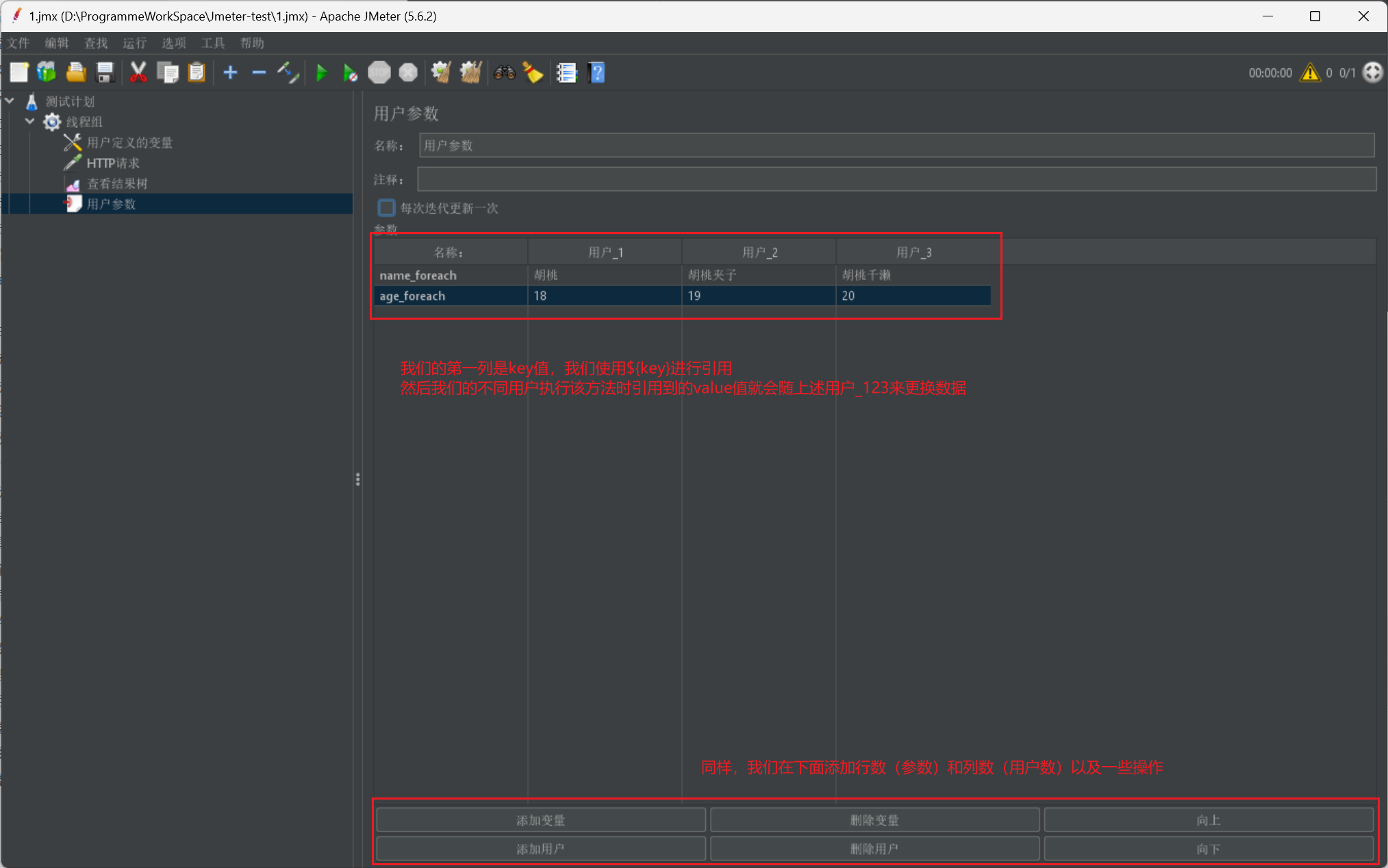
然后我们再给出一张使用图或者说我们的设置图:
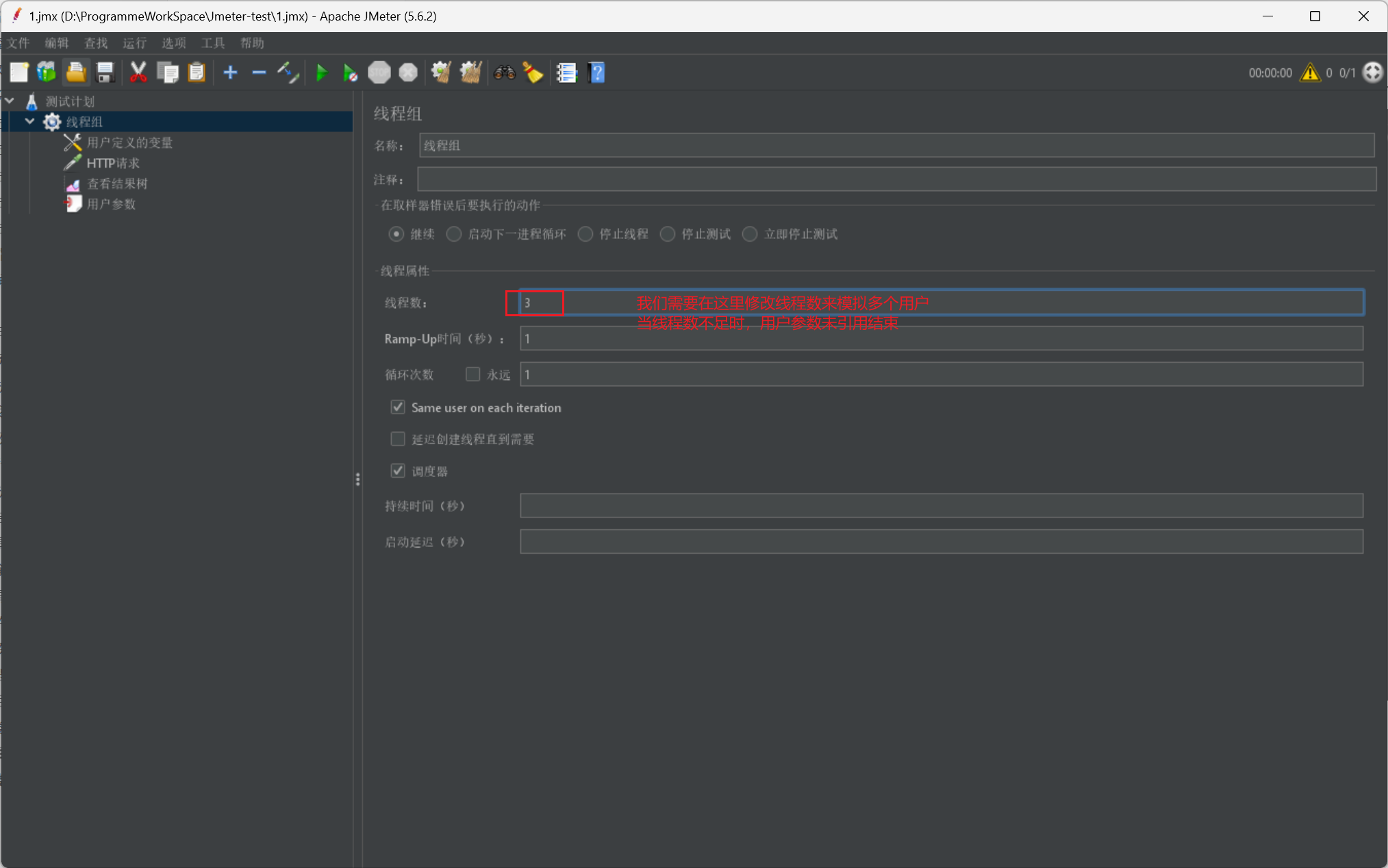
数据文件
我们首先给出数据文件的相关定义:
CSV 数据文件设置 —— 文件方式参数化
我们同样给出介绍:
我们首先给出一张 CSV 文件导入 Jmeter 的展示图:
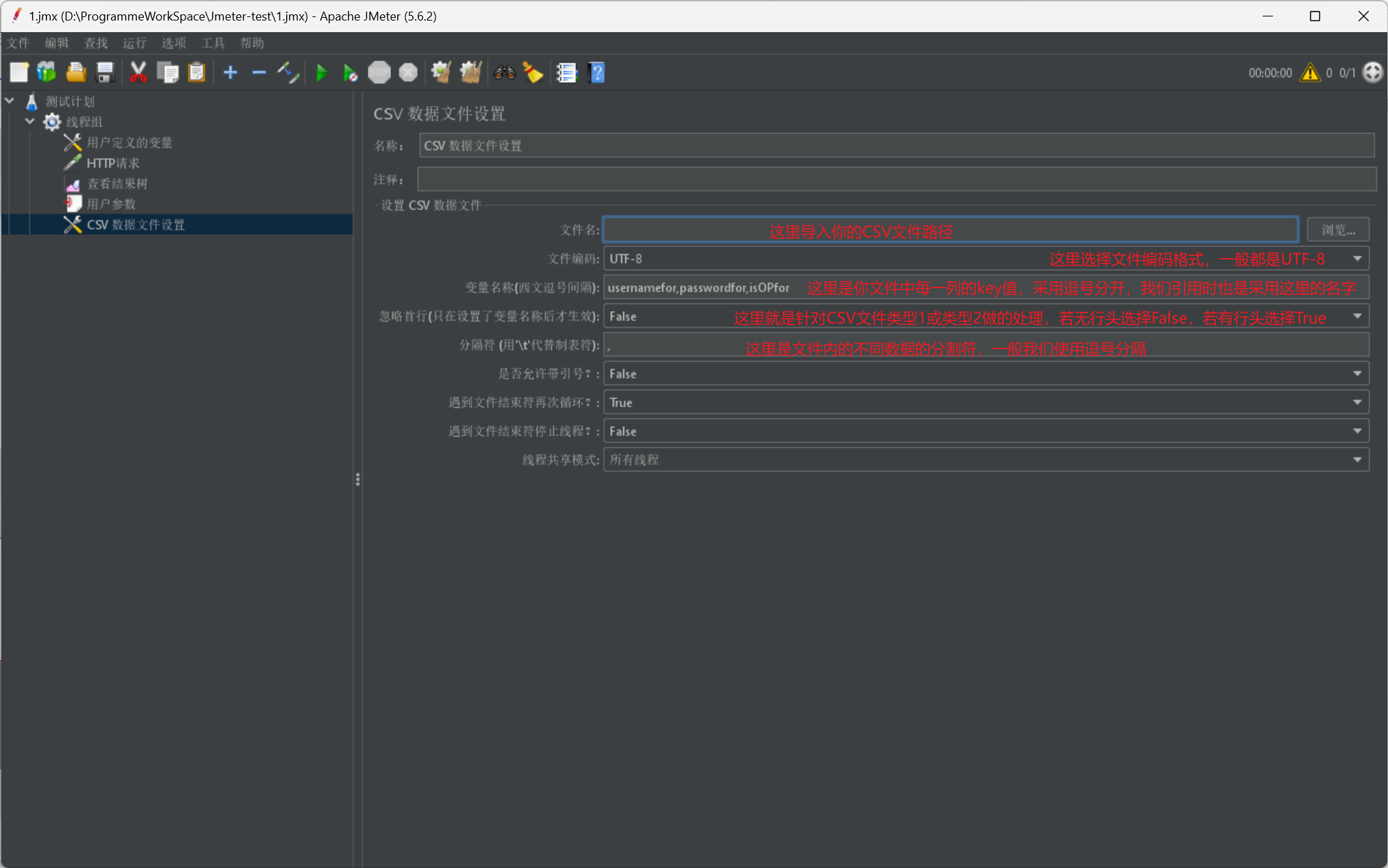
我们在使用时,同样采用 $符进行数据导入,注意 key 值是我们在 CSV 数据文件设置里设置的变量名称:
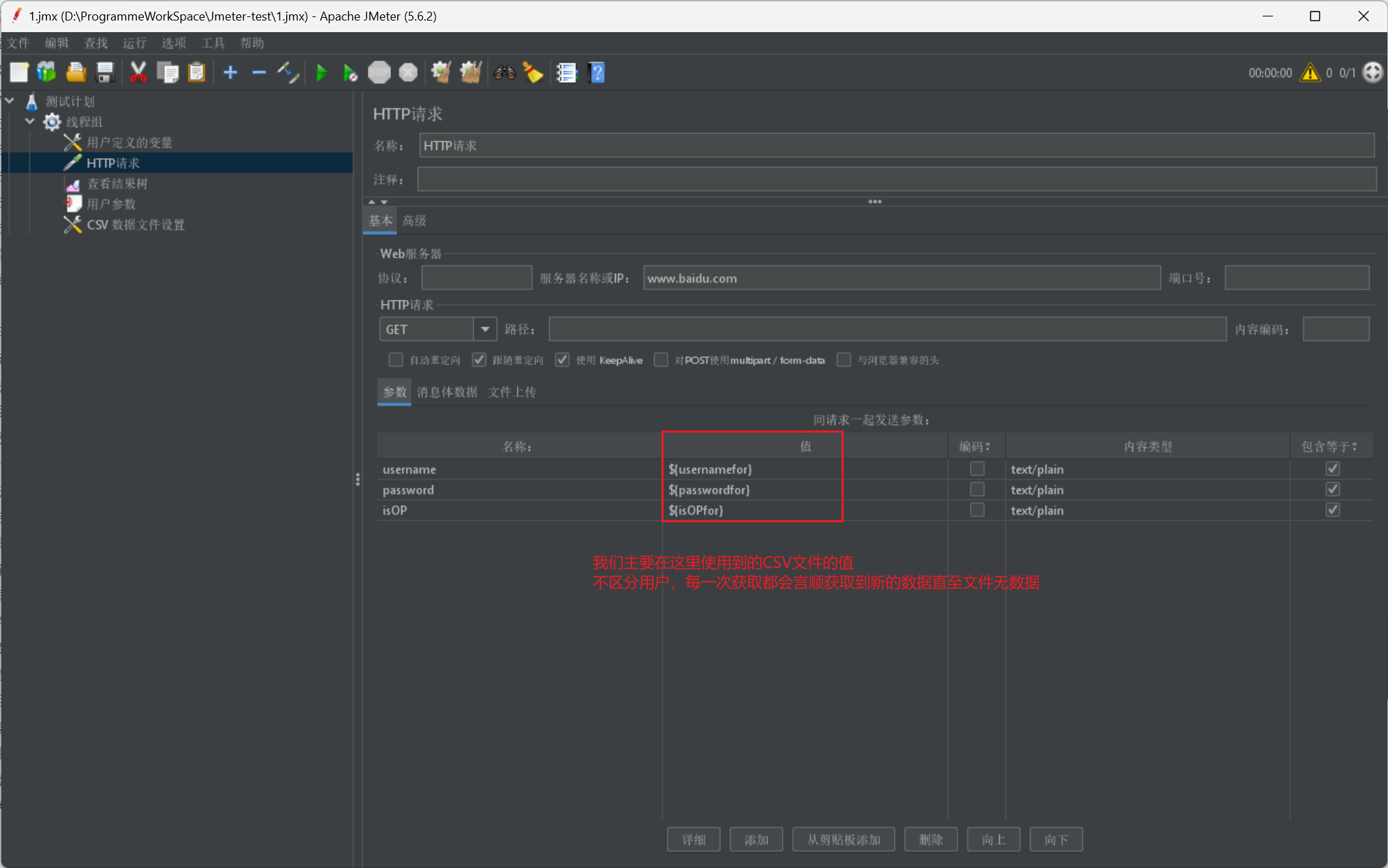
函数参数
最后我们介绍一下函数参数:
函数 —— 随机数据
我们同样给出基本介绍:
我们给出函数定义界面展示:
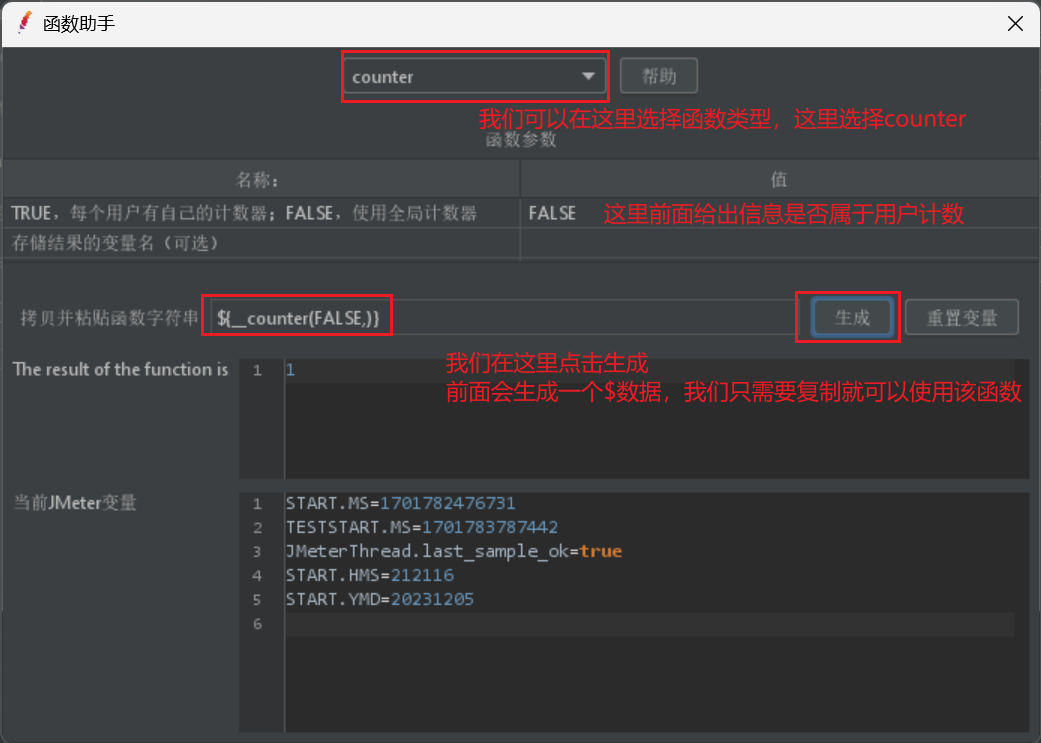
最后我们给出一个数据使用展示:
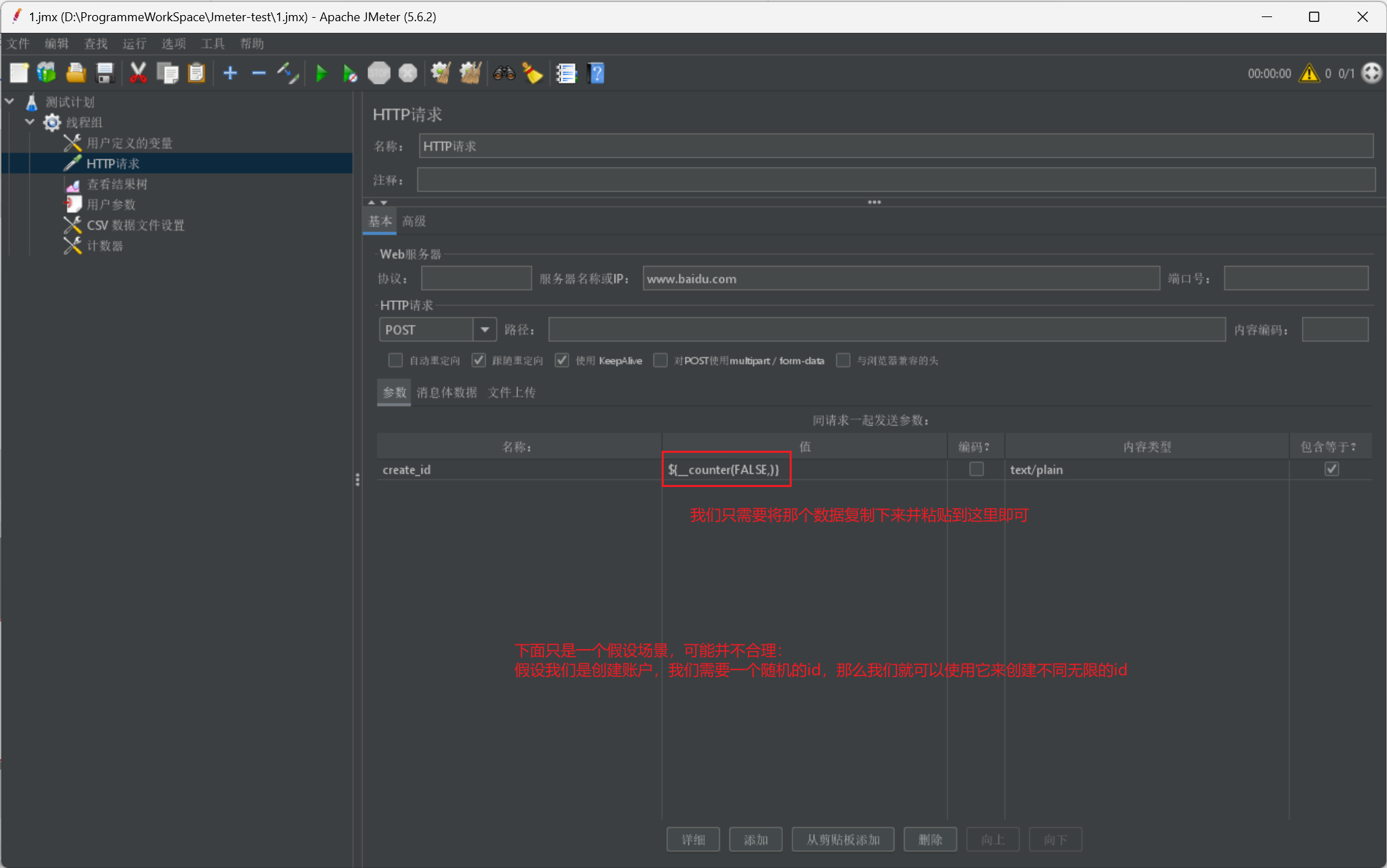
汇总展示
最后我们分别给出四种参数化处理的优缺点:
Jmeter 断言介绍
下面我们来介绍 Jmeter 中的结果自动判断工具:
我们的 Jmeter 本身有一个响应码自动判断,若结果并非 200 就会进行报错显示
但是存在某些情况,即使响应码为 200 但也可能因为结果不对从而导致功能不符合需求
所以我们需要学习断言,我们采用断言来完成字段的匹配,若字段不符合我们的需求则报错显示
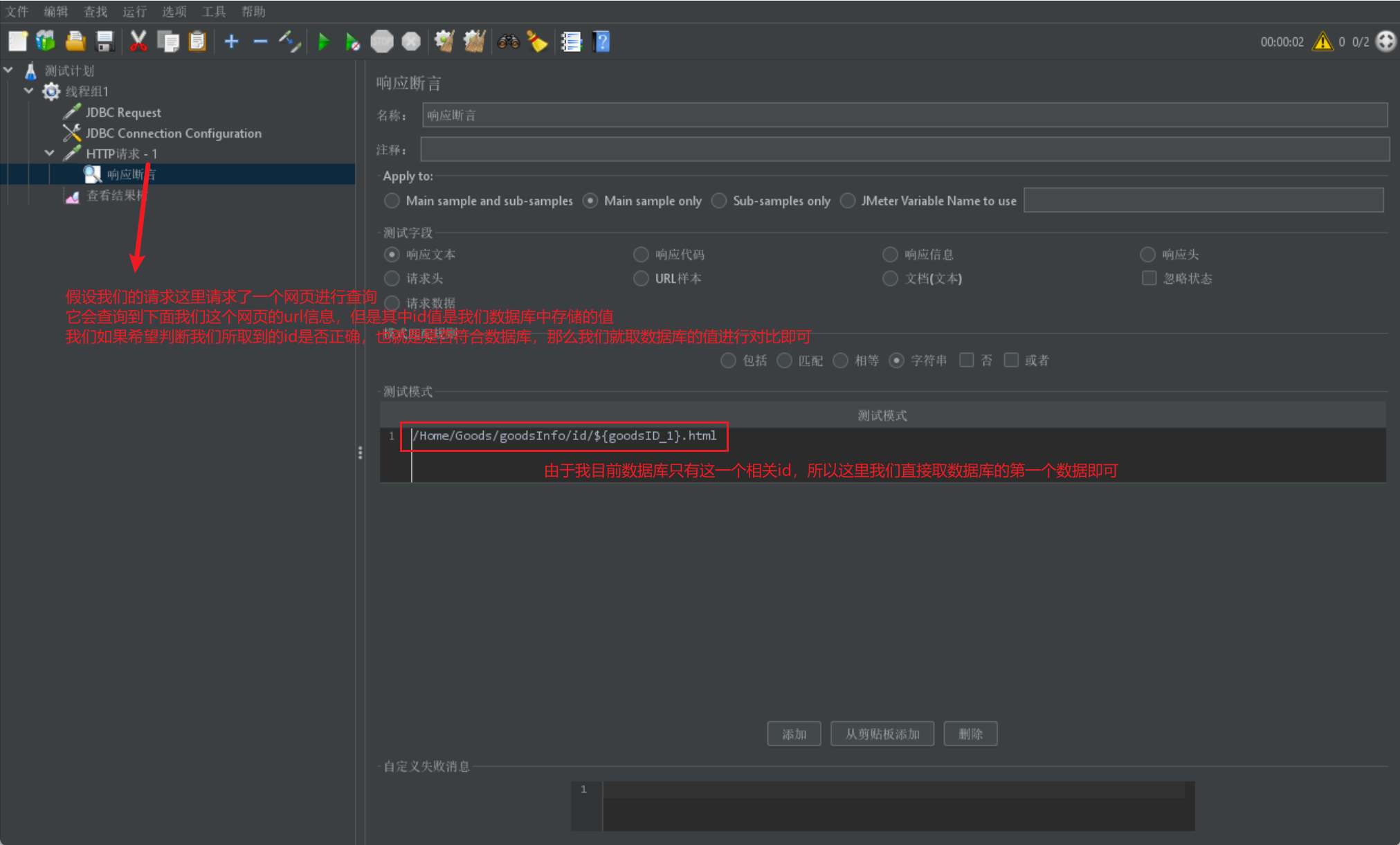
响应断言
我们首先给出一张响应断言页的图片:
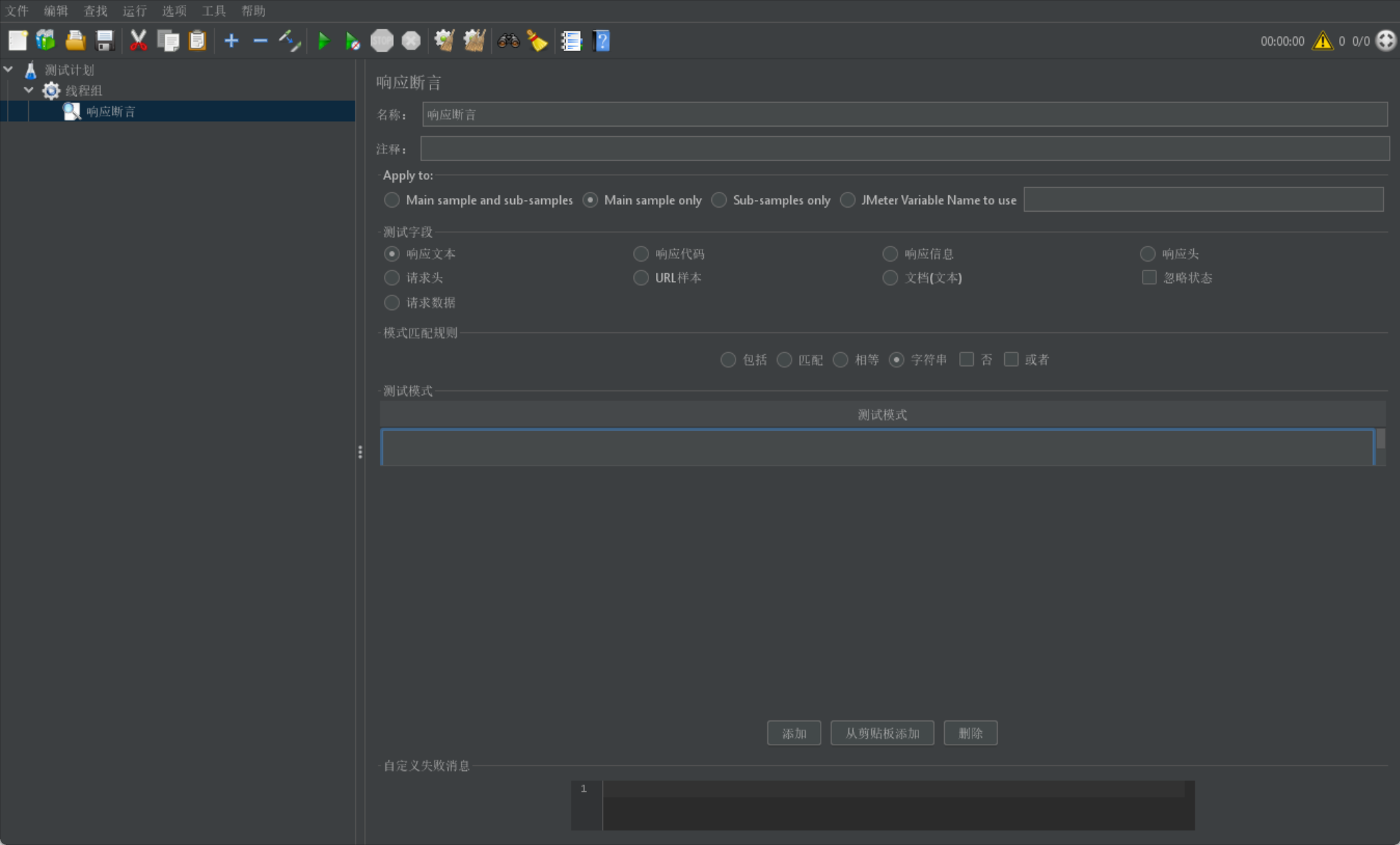
由于页面内容过多无法在图中展示所有字段含义,我们单独在下面介绍上述字段意义:
我们使用断言一般是放在请求的下层,当请求执行后就会采用请求返回的 response 来进行断言判断:
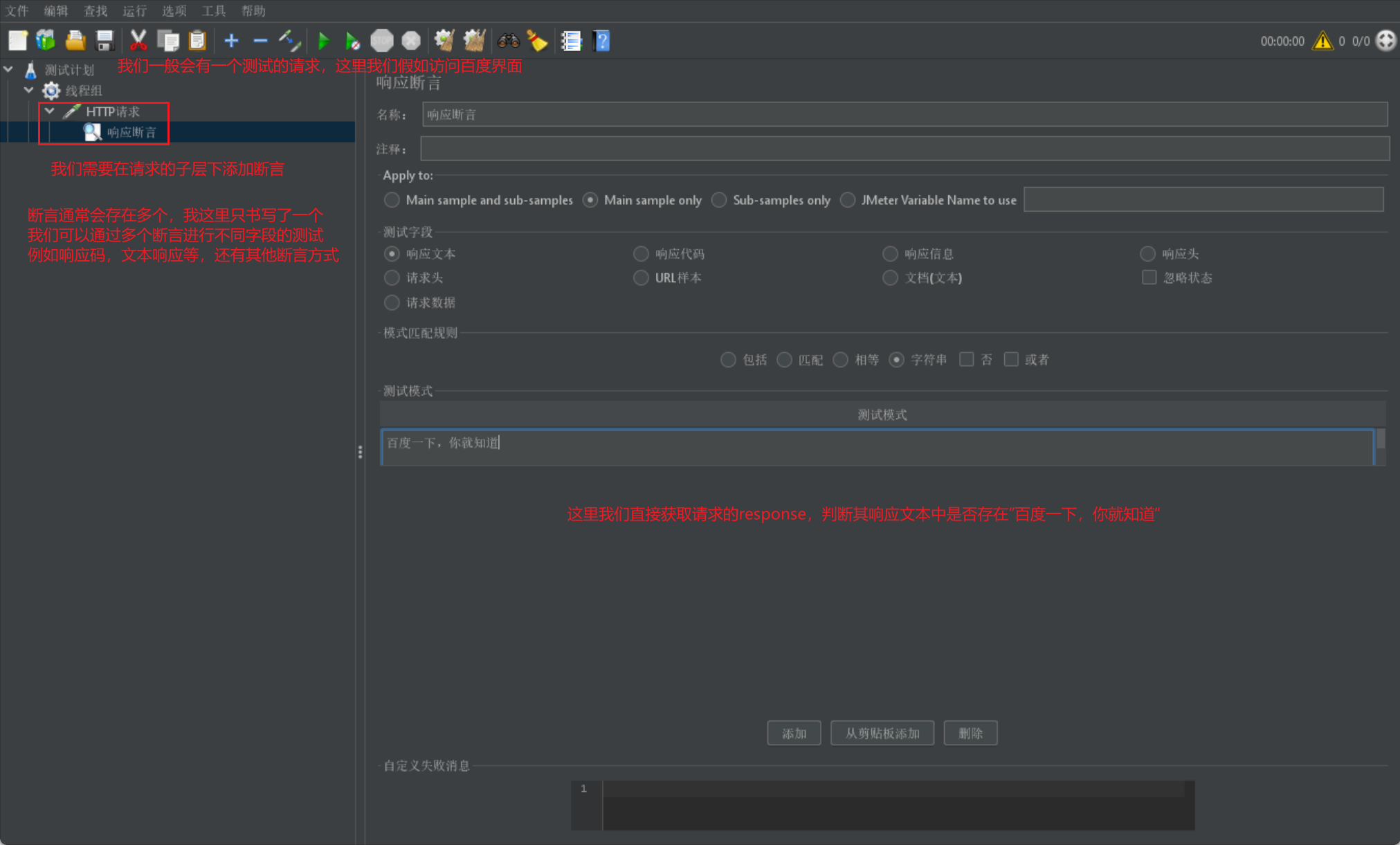
JSON 断言
下面我们来介绍 JSON 断言,同样我们直接给出一张图片:

我们已经介绍过上述概念了,我们首先给出一个请求所获取的返回结果:
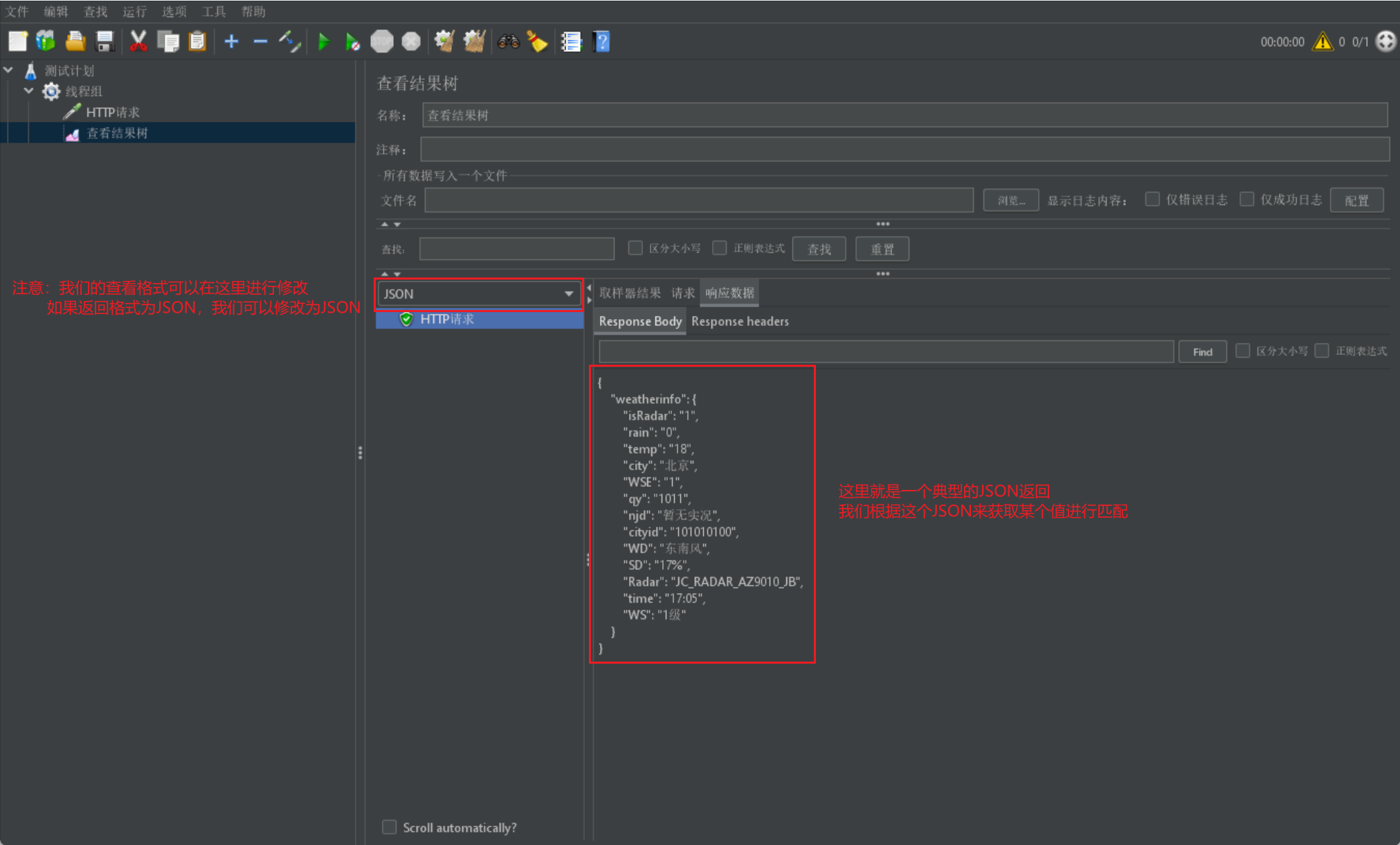
下面我们来获取上述 JSON 中的某个字段来进行匹配判断:
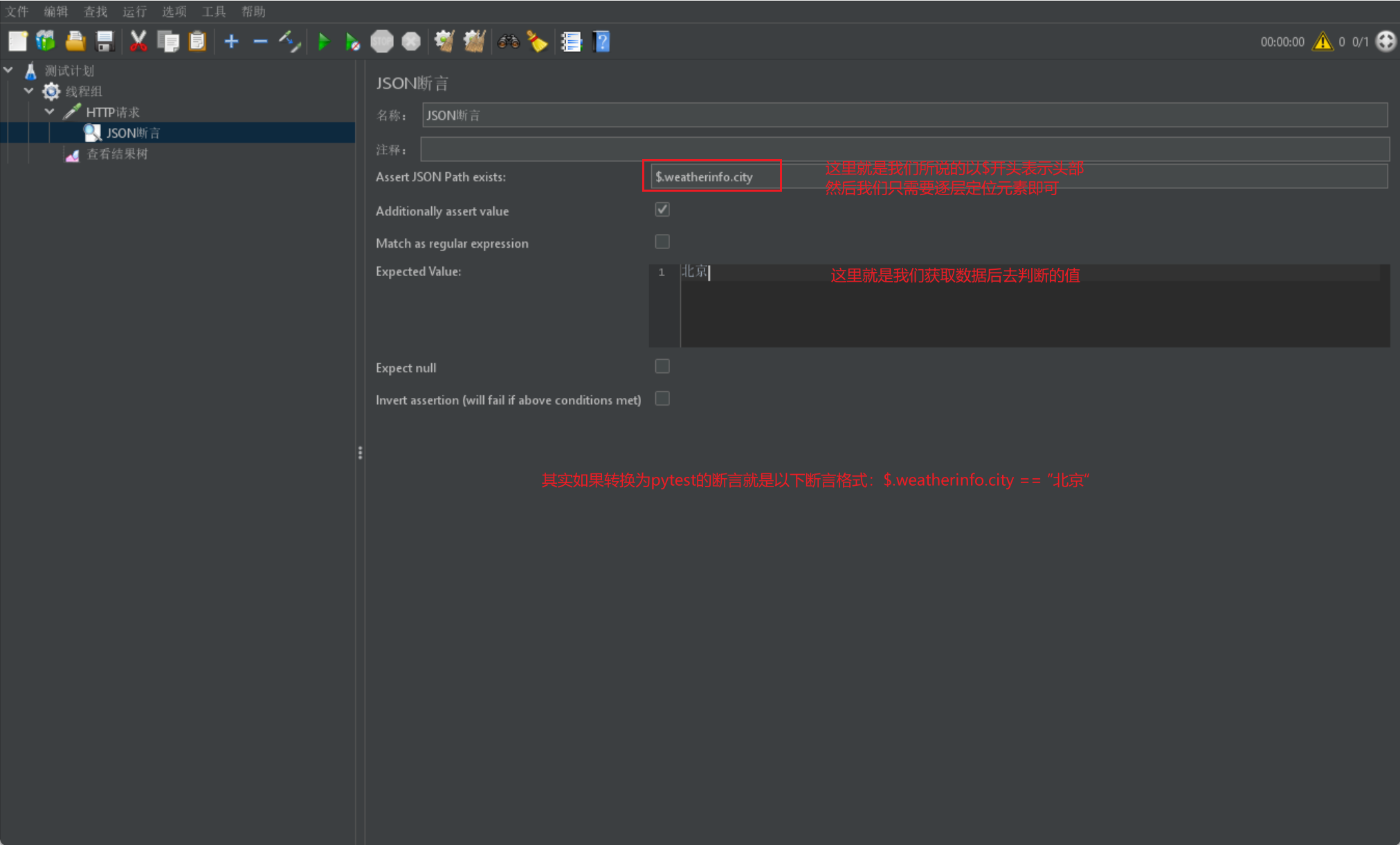
时间断言
除了上述我们对结果进行断言判断外,我们有时还需要进行性能测试,我们就需要判断在规定时间内是否满足条件:
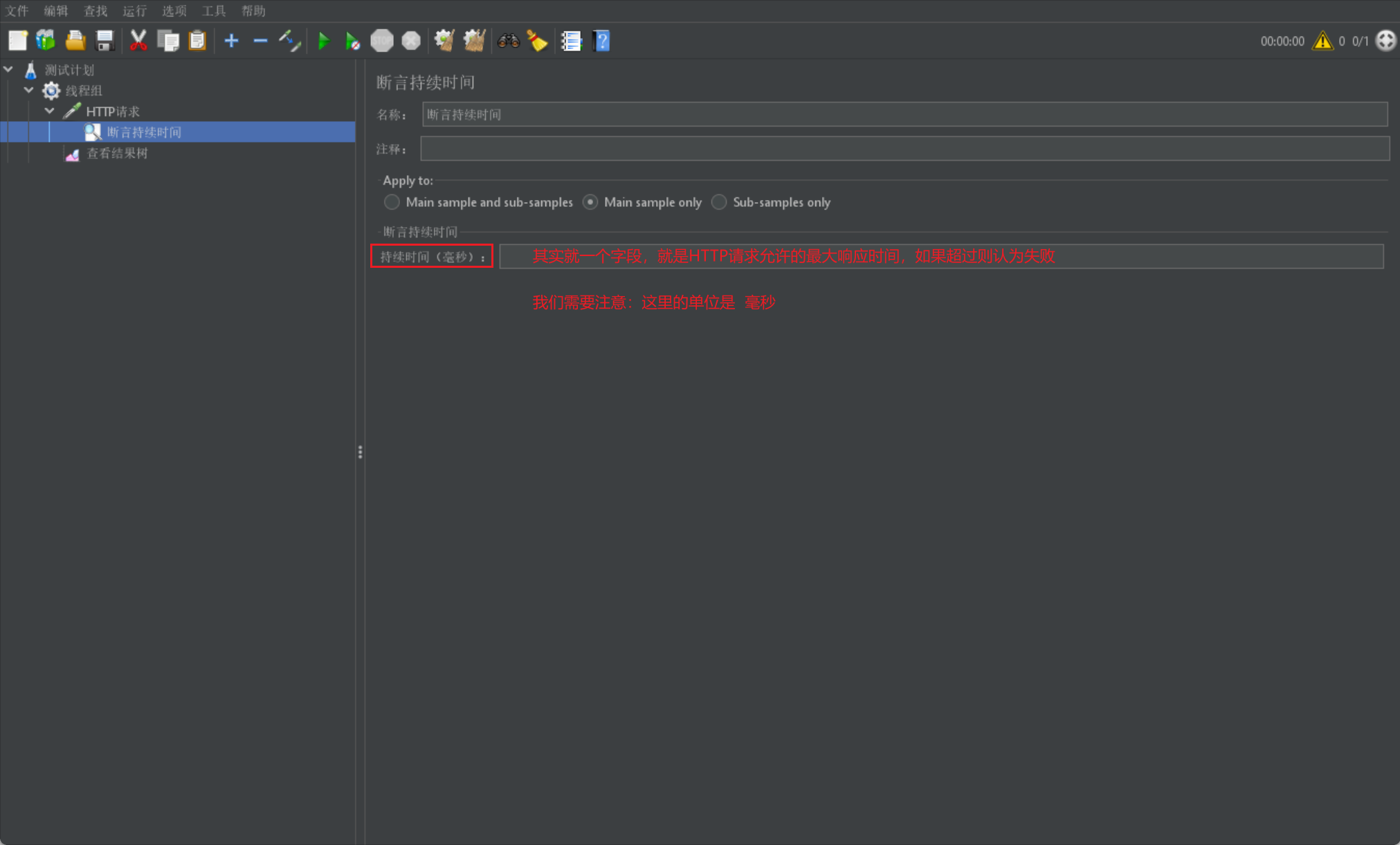
”断言持续时间”就是专门用来进行时间判断的断言
我们直接给出一张断言持续时间界面图:
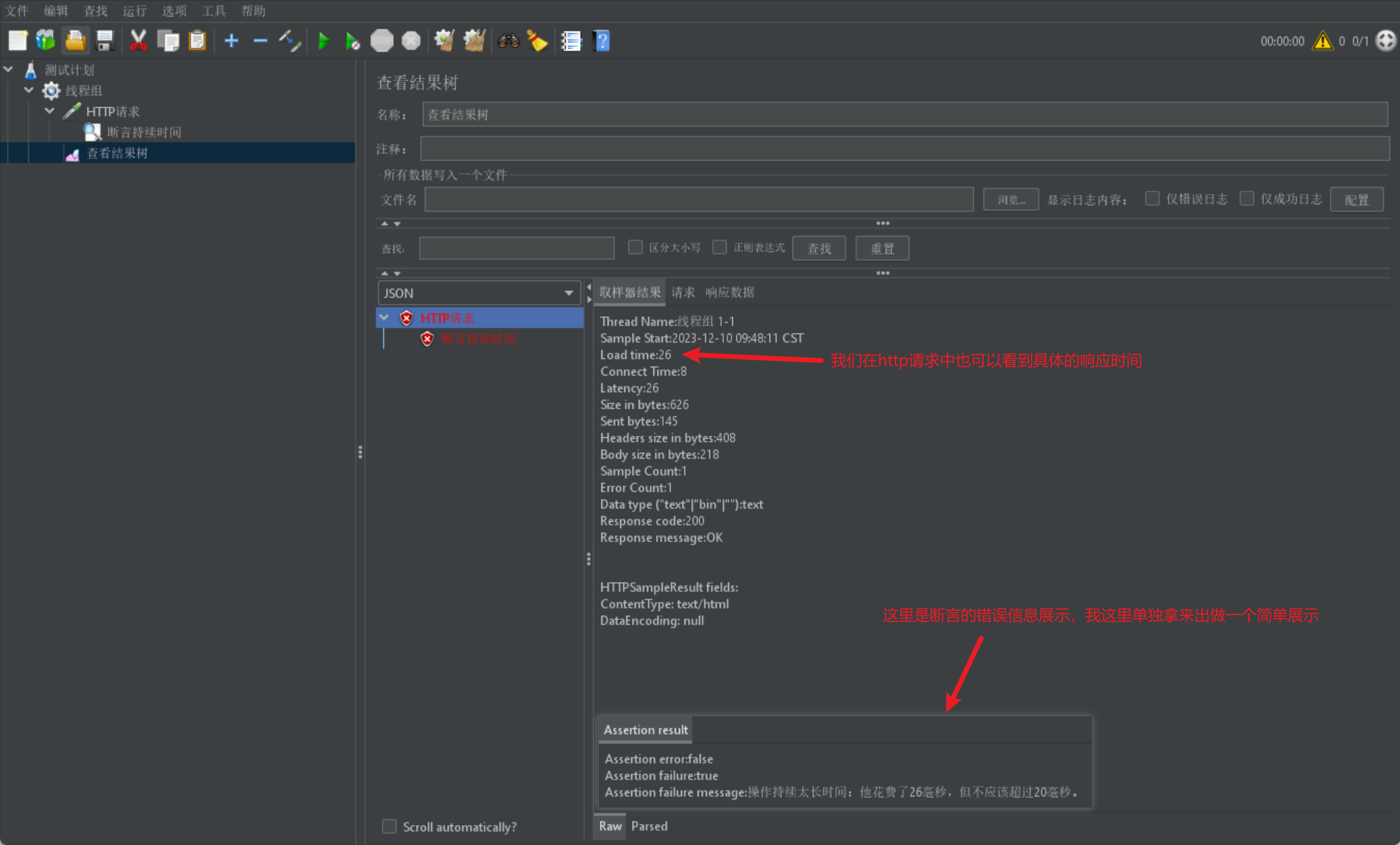
我们同样给出一个简单的结果实例展示:
Jmeter 关联介绍
我们在使用 Jmeter 时难免会遇到关联关系:
当请求之间有依赖关系,就被称为关联
例如一个请求的请求参数是另一个请求的请求响应结果
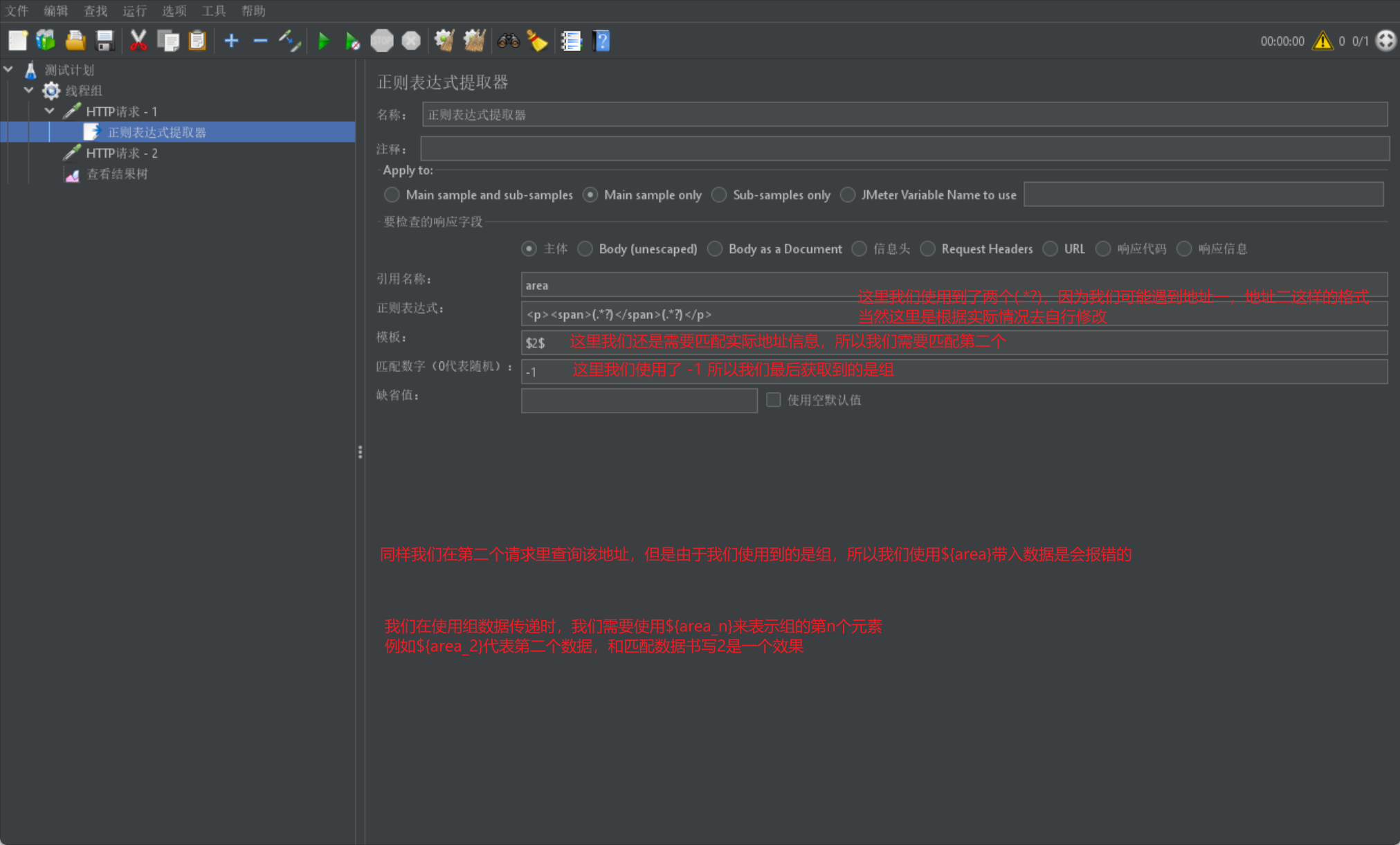
正则表达式提取器
我们首先来介绍正则表达式提取器:
我们首先给出案例图来进行介绍:
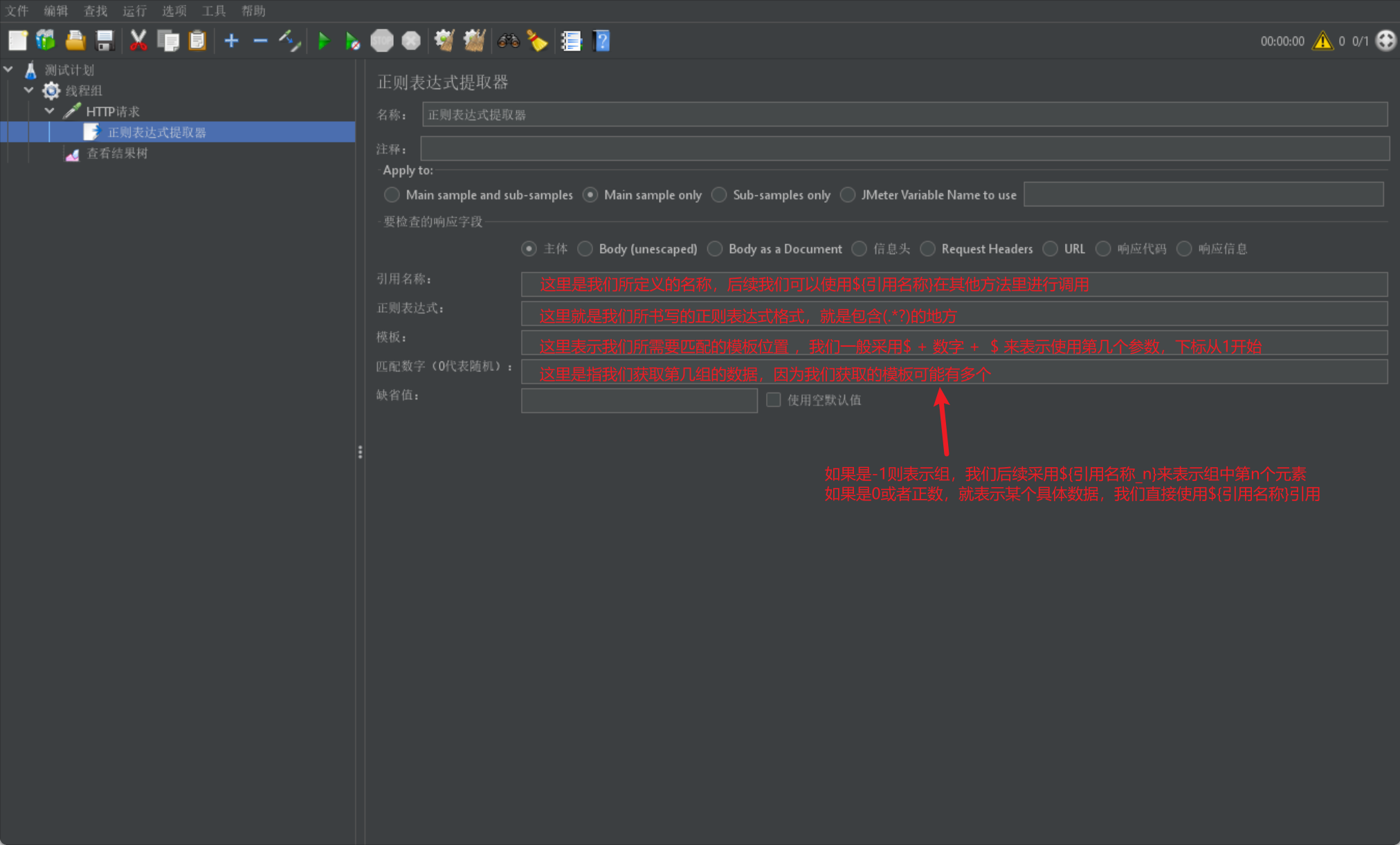
我们首先给出正则表达式的正常使用示例图:
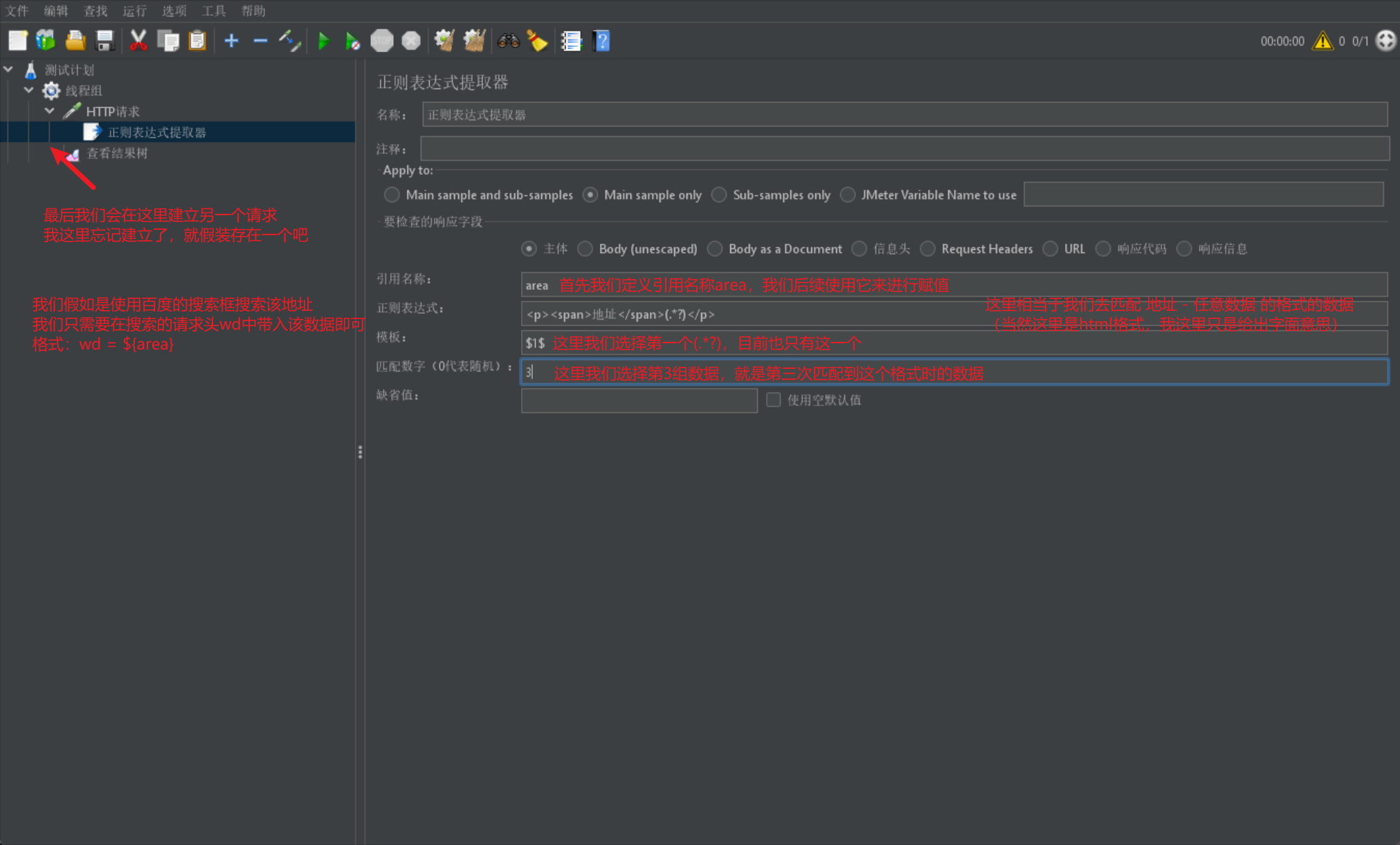
然后我们通过一张图来展示模板和匹配数字组的格式:
XPath 提取器
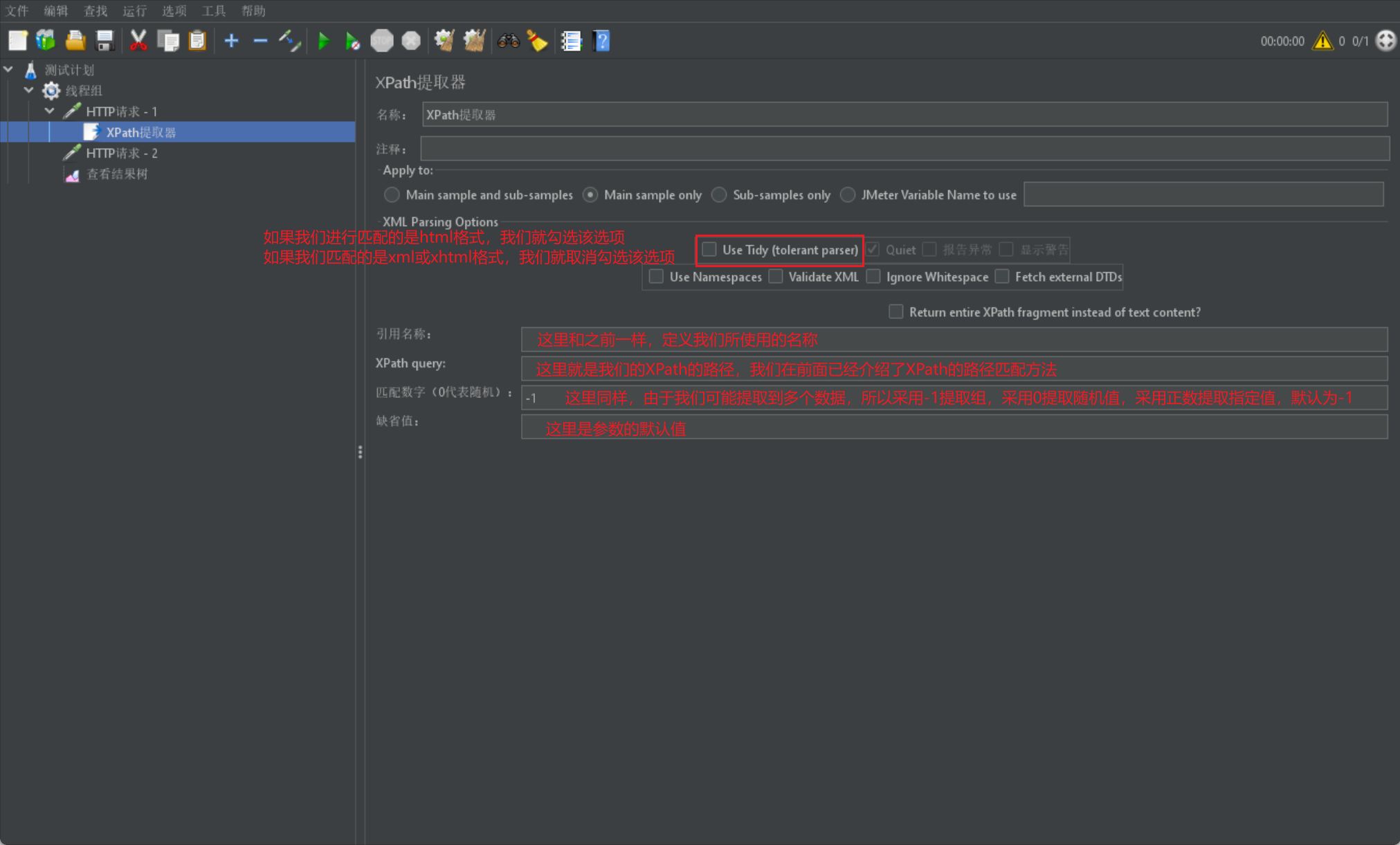
下面我们来介绍 XPath 提取器,其实就是一个 html 提取器:
XPath 提取器主要针对 HTML 格式的响应结果数据进行提取
我们在 Selenium 的介绍文章里已经介绍过 XPath 的具体匹配原则,这里我把介绍文本粘贴了一下方便大家查看:
那么我们首先还是给出 XPath 的展示图:
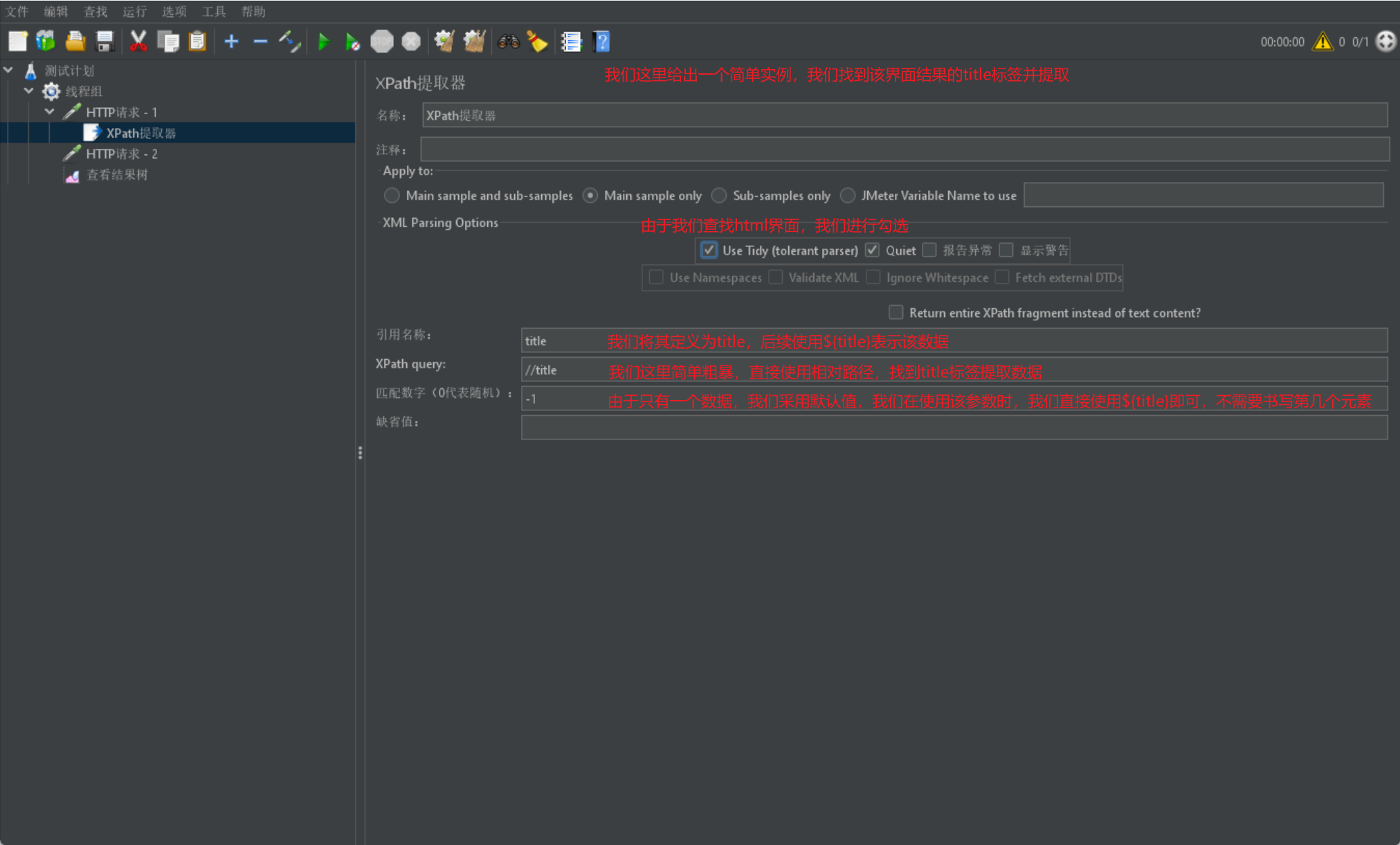
我们同样给出一张简单示例图:
JSON 提取器
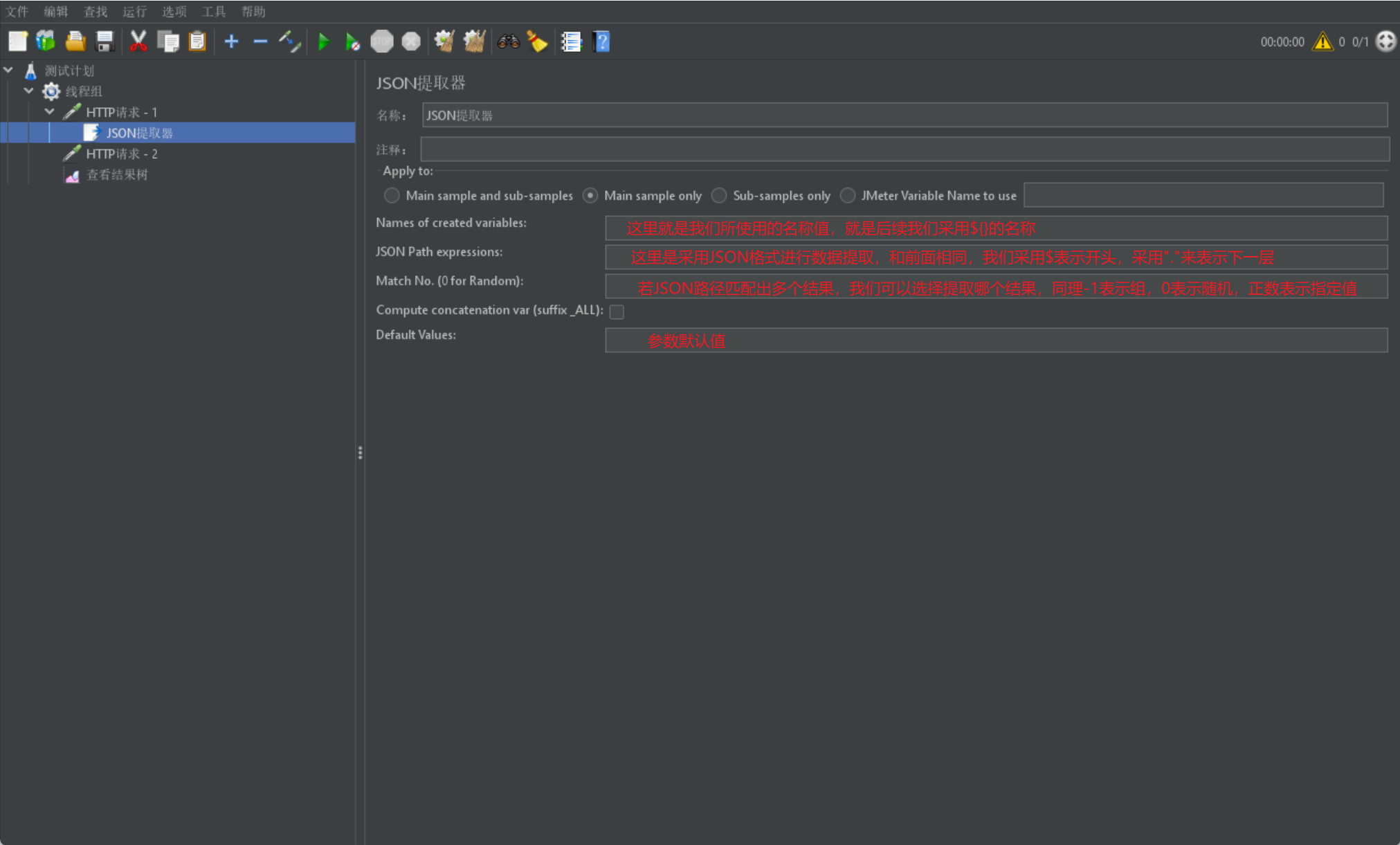
最后我们再来介绍一个 JSON 提取器,同样也是很简单的格式:
JSON 提取器主要针对返回结果是 JSON 的响应结果数据进行提取
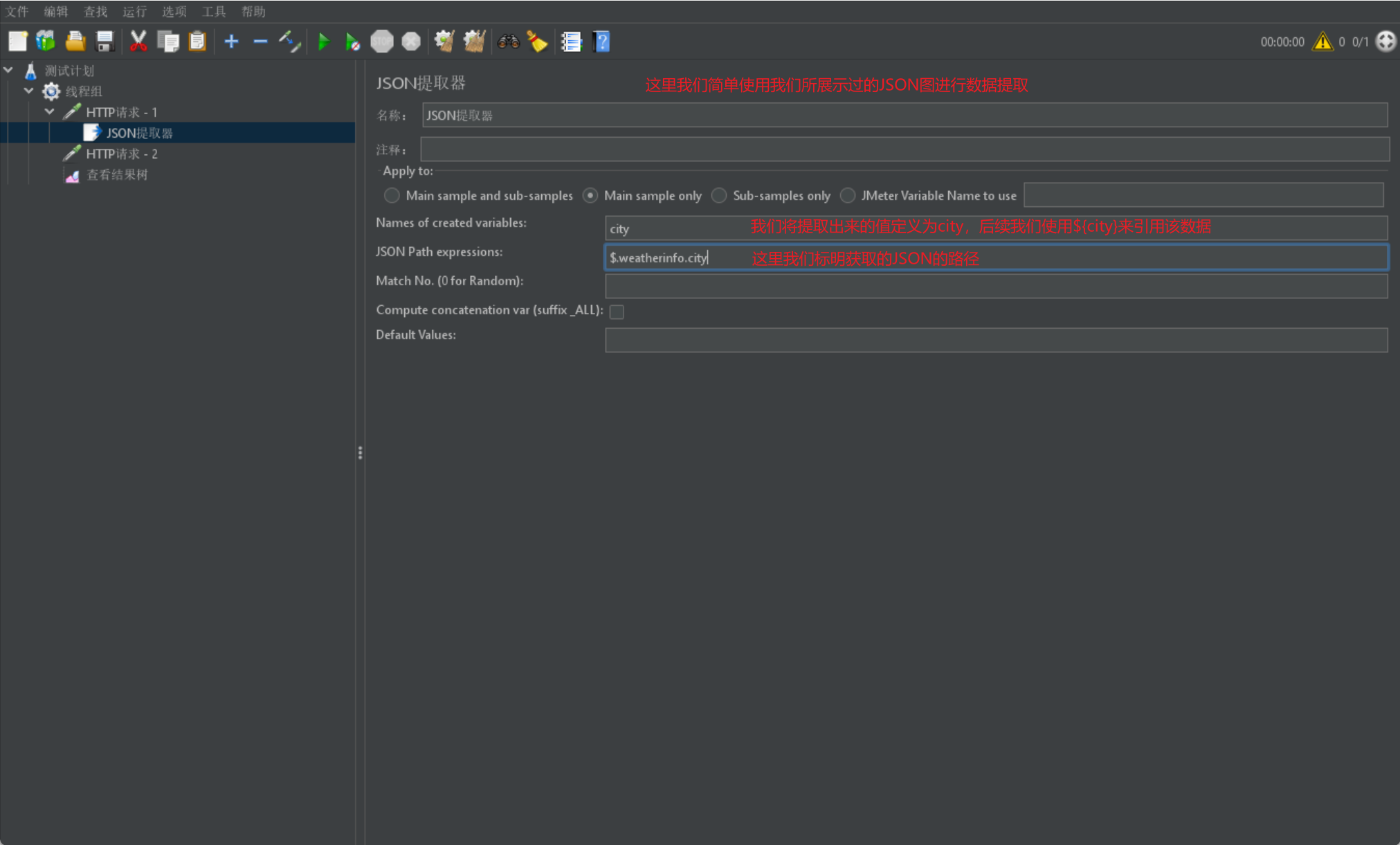
我们同样首先给出一张展示图并进行解释:
我们给出一张简单实例图解释:
Jmeter 属性介绍
下面我们来介绍 Jmeter 的属性相关信息:
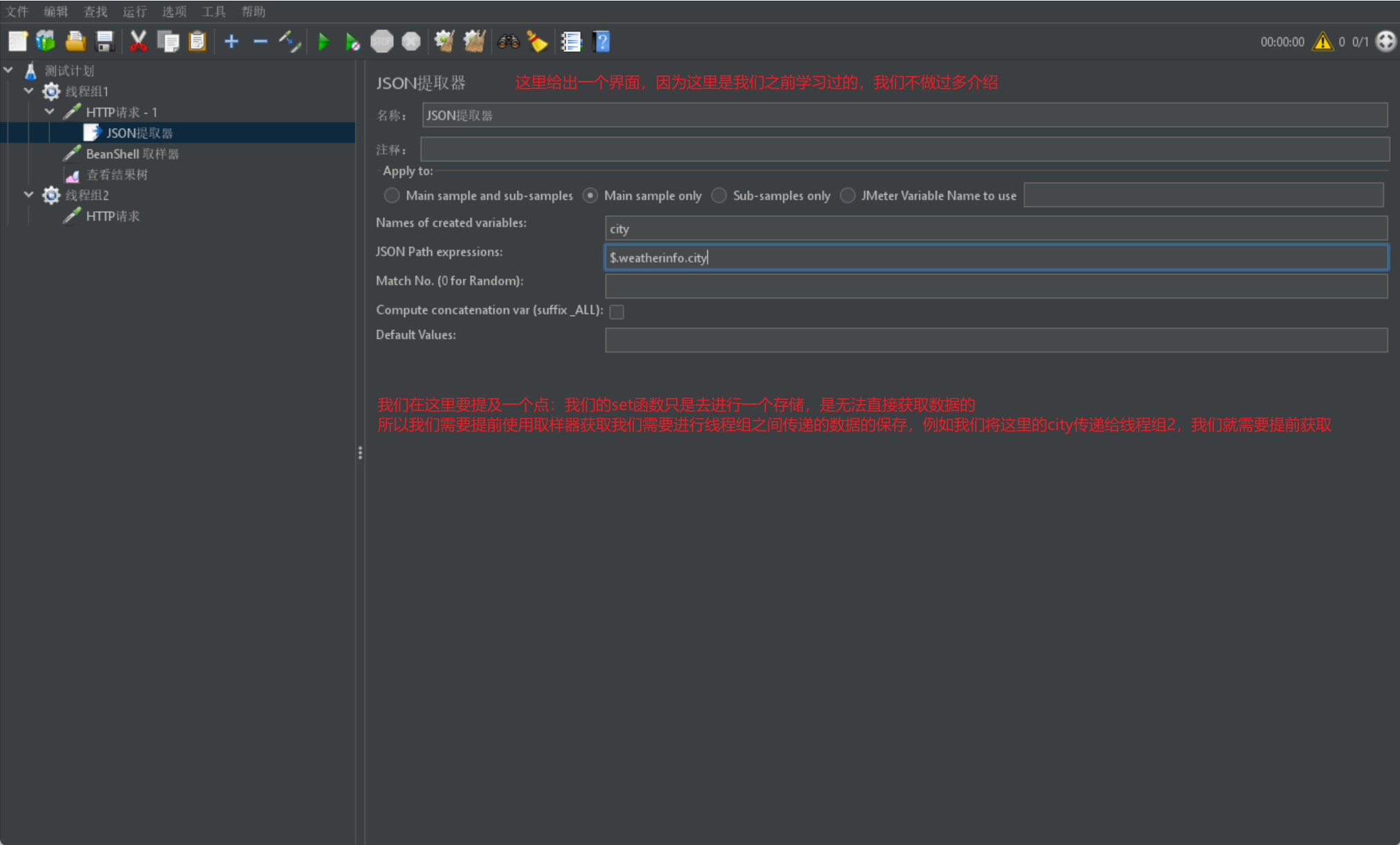
我们前面使用的关联仅仅能在同一个线程组中进行使用,若我们想在不同线程组中使用就需要采用属性
我们需要将我们所需要使用到的数据定义成 Jmeter 的全局变量,然后我们才能在不同线程组中使用该属性
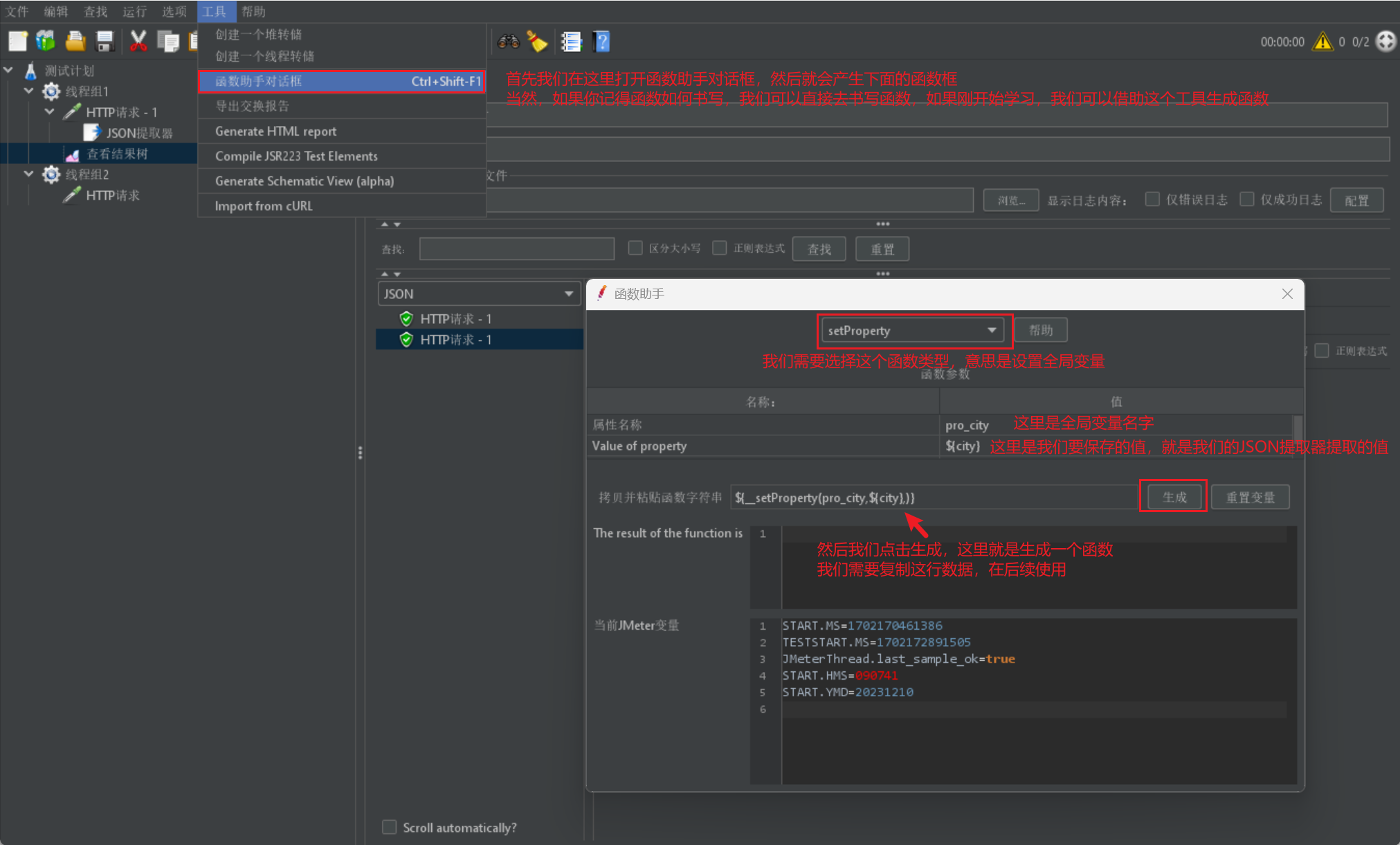
Jmeter 属性的设置同样需要函数来进行 set 和 get 操作:
首先我们需要有一个线程组 1,然后线程组 1 里调用请求,我们采取 JSON 取样器获得请求中的 city 属性:
我们在获取数据之后,我们首先需要去创建函数,我们可以直接书写函数,也可以采用工具书写:
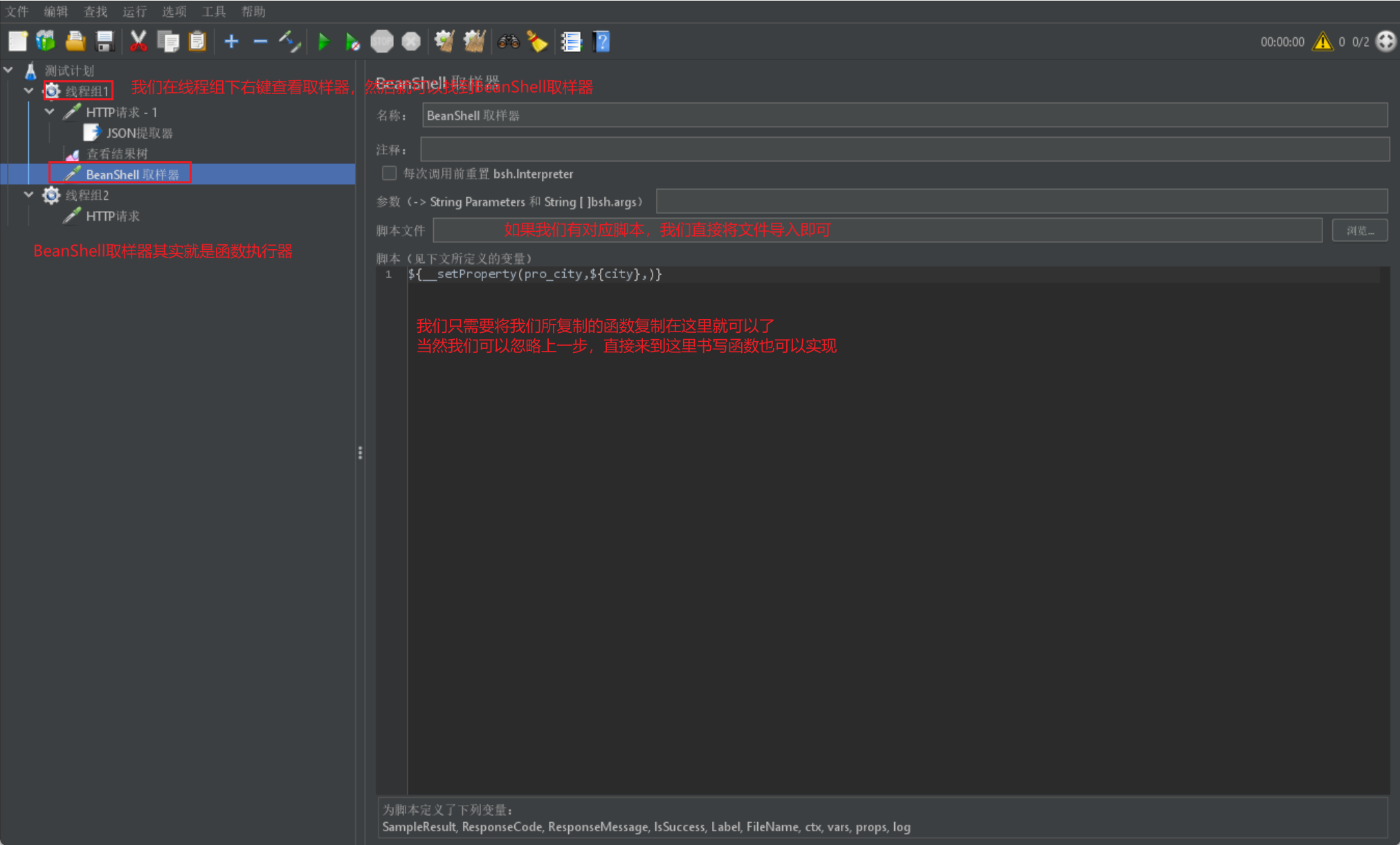
然后我们需要采用一个 BeanShell 取样器来进行函数执行:
如果我们希望调用我们定义的全局变量,我们同样需要使用函数,我们同样去获取函数:

最后我们只需要在另一个线程组里的请求里直接使用该函数即可,不需要额外操作:
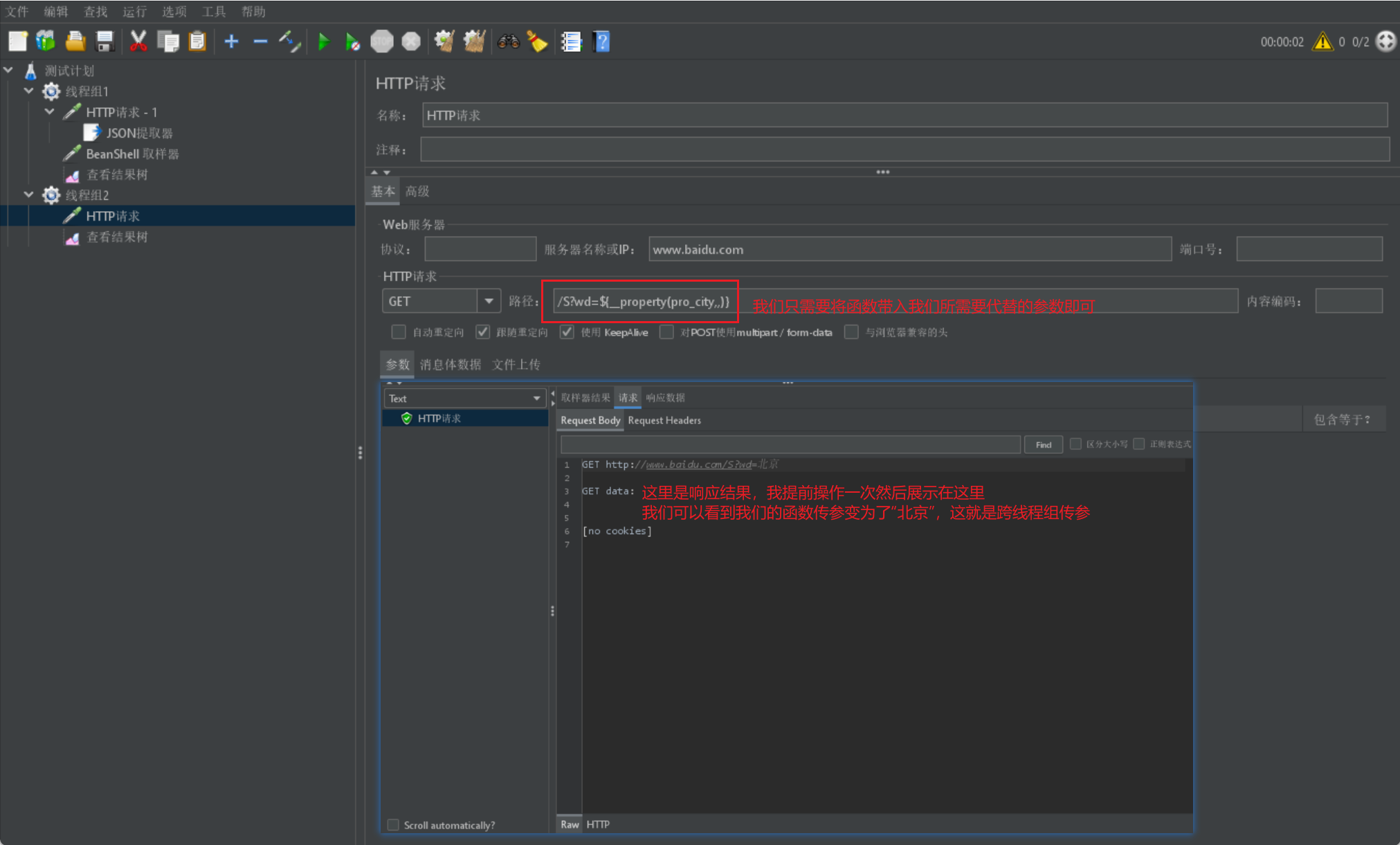
Jmeter 数据库连接
首先我们介绍一下 Jmeter 连接数据库的主要作用:
用作请求参数化:例如登录界面所需账号密码,可以直接从数据库获取
用作结果的断言:例如我们通过查询获取的数据,我们可以判断该数据是否真实存在,与数据库信息进行比较
用作清除无用数据:当我们重复使用某功能时,可能存在某个字段不能重复使用,那么我们就需要在调用该功能之前删除该字段
用作准备测试数据:当我们需要大量数据时,我们可以直接从数据库中获取大量数据进行调用
接下来我们就来讲解如何进行数据库连接:
首先我们需要对 Jmeter 添加对应的数据库 jar 包,下载后放在 lib 目录的 ext 目录下即可(下载方法在末尾):
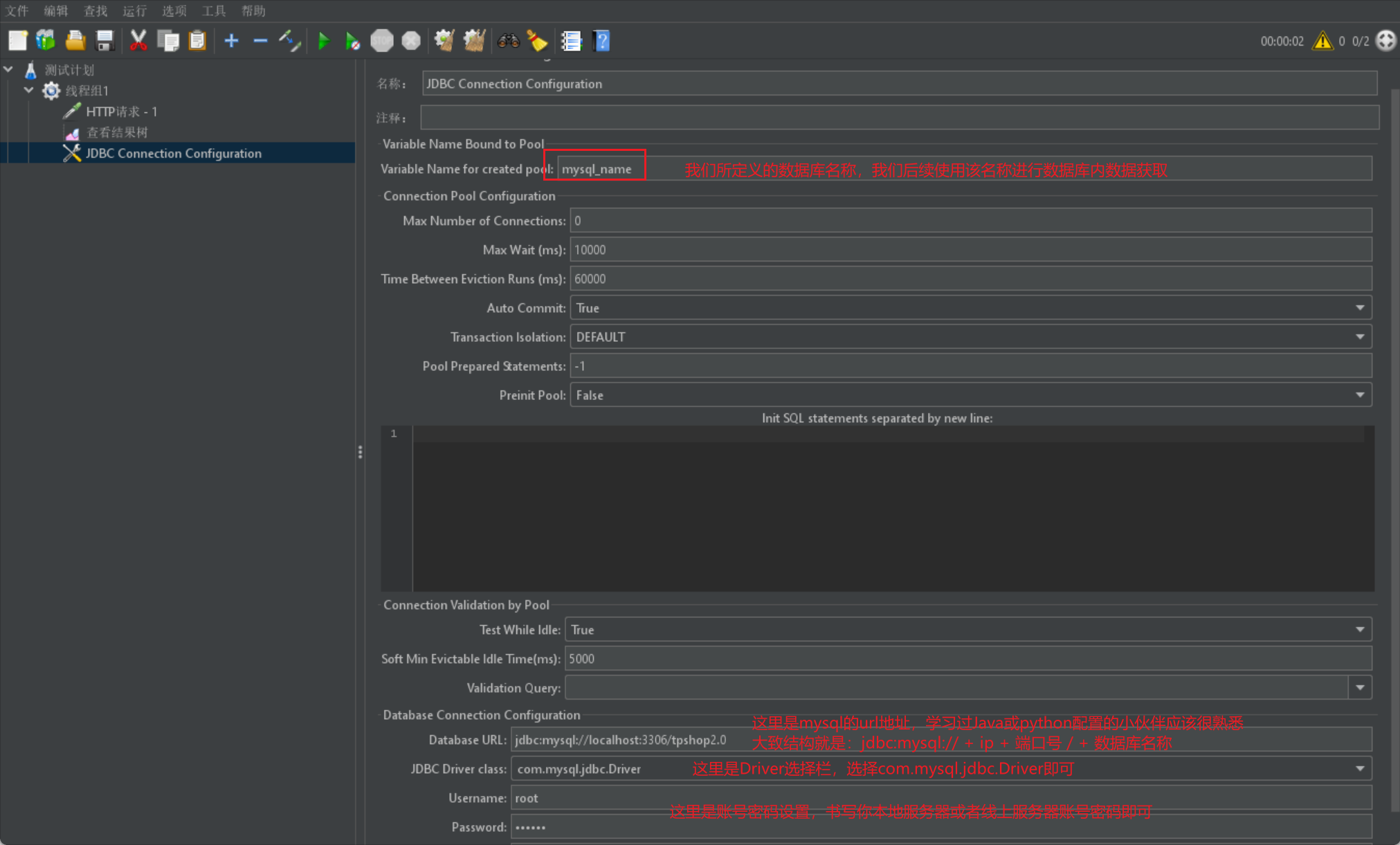
然后我们在 Jmeter 里面配置 JDBC Connection Configuration 信息:
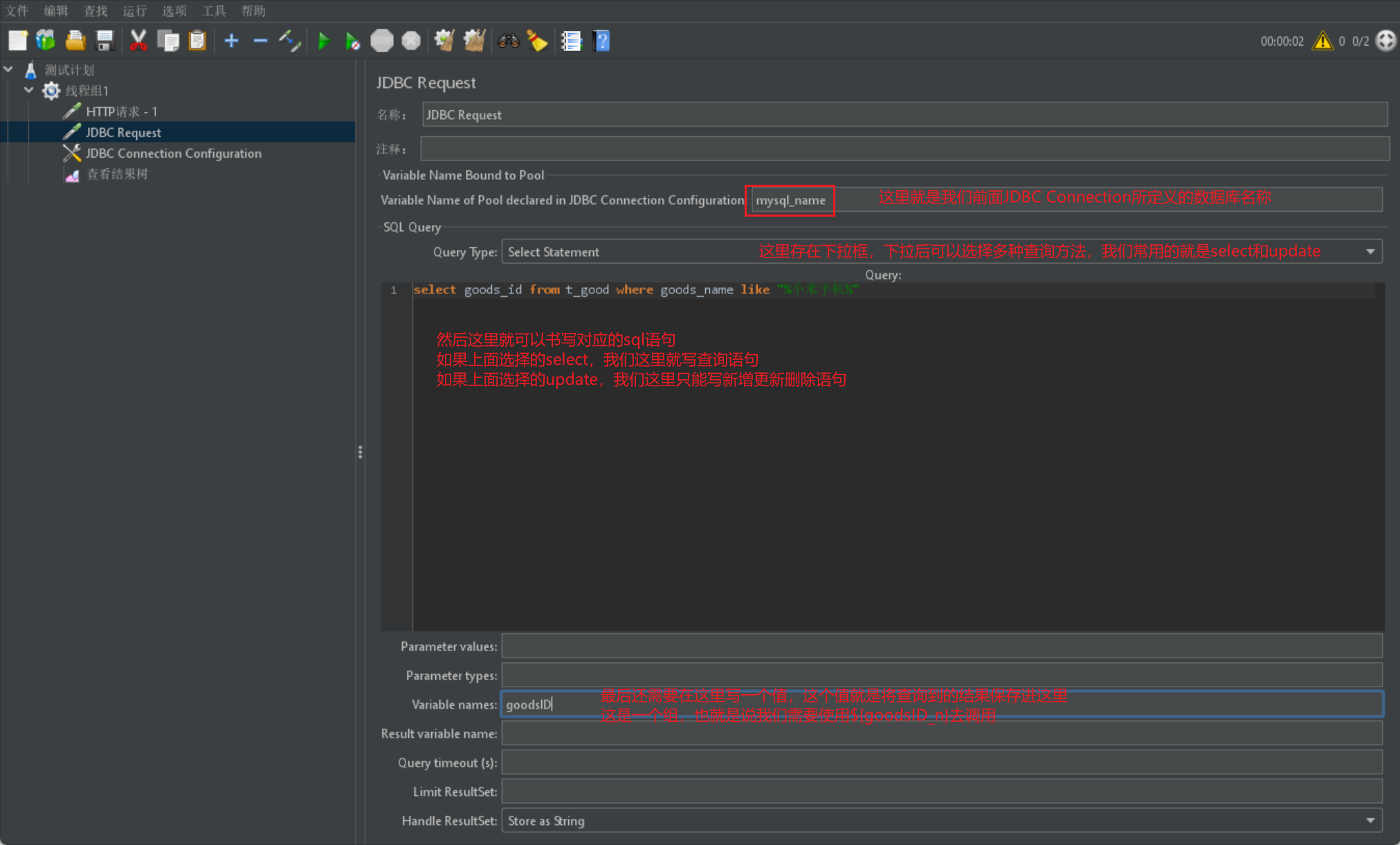
然后我们就可以通过 JDBC 请求来书写数据库代码来进行数据获取:
最后我们就可以采用这个 JDBC Request 去做一些断言之类的操作:
Jmeter 逻辑控制器
我们在进行 Jmeter 操作的时候可能会进行过滤或者重复操作等,我们就会使用到逻辑控制器
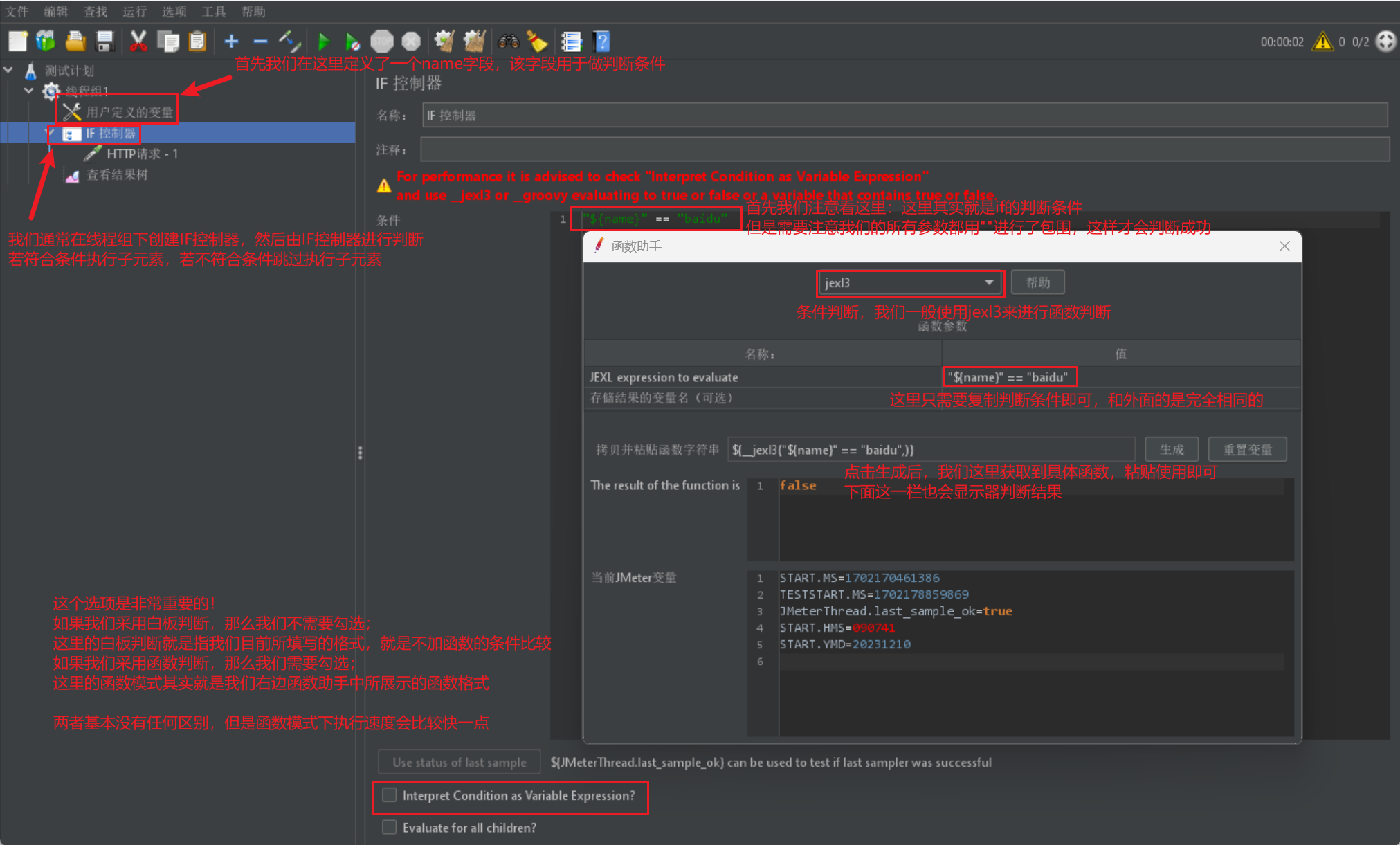
If 逻辑控制器
If 逻辑控制器用来控制它下面的测试元素是否执行
然后我们给出一张 if 逻辑控制器的展示图进行参数介绍:
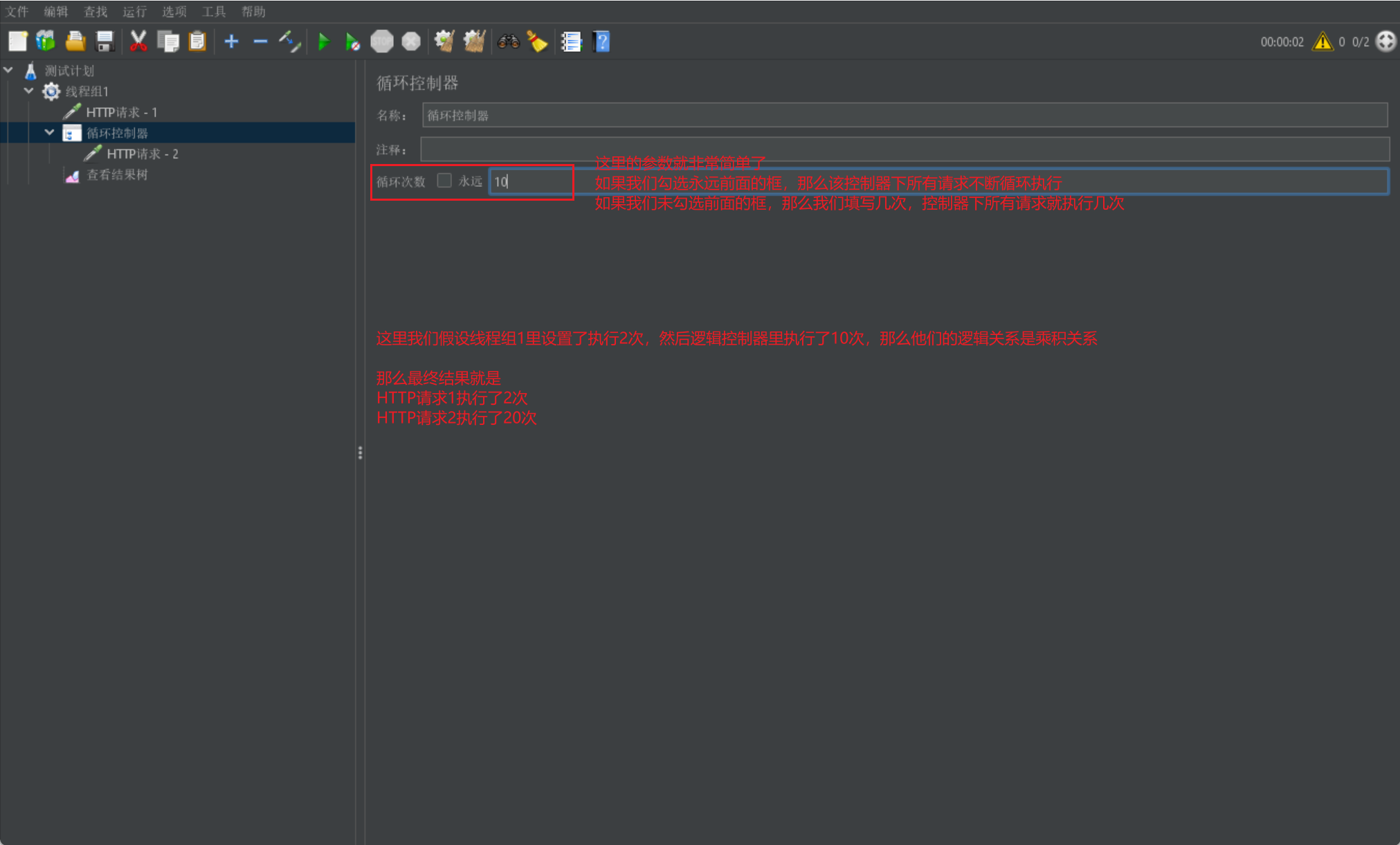
while 逻辑控制器
下面我们来介绍 while 逻辑控制器:
当我们需要某些特定语句去进行多次执行时,我们可以采用循环逻辑控制器
如果我们该线程组下所有请求都在 while 逻辑控制器内,那么和线程组中控制循环次数的效果是一样的,这里就是为了单个请求做重复操作而设置的
我们直接给出逻辑控制器的展示图进行参数介绍:
Foreach 逻辑控制器
最后我们介绍一个 ForEach 逻辑控制器,它是用于对组中元素均执行所创建的控制器:
一般和用户自定义变量和正则表达式一同使用,用于使用该组中所有元素去执行请求
我们首先给出 Foreach 逻辑控制器的展示界面:
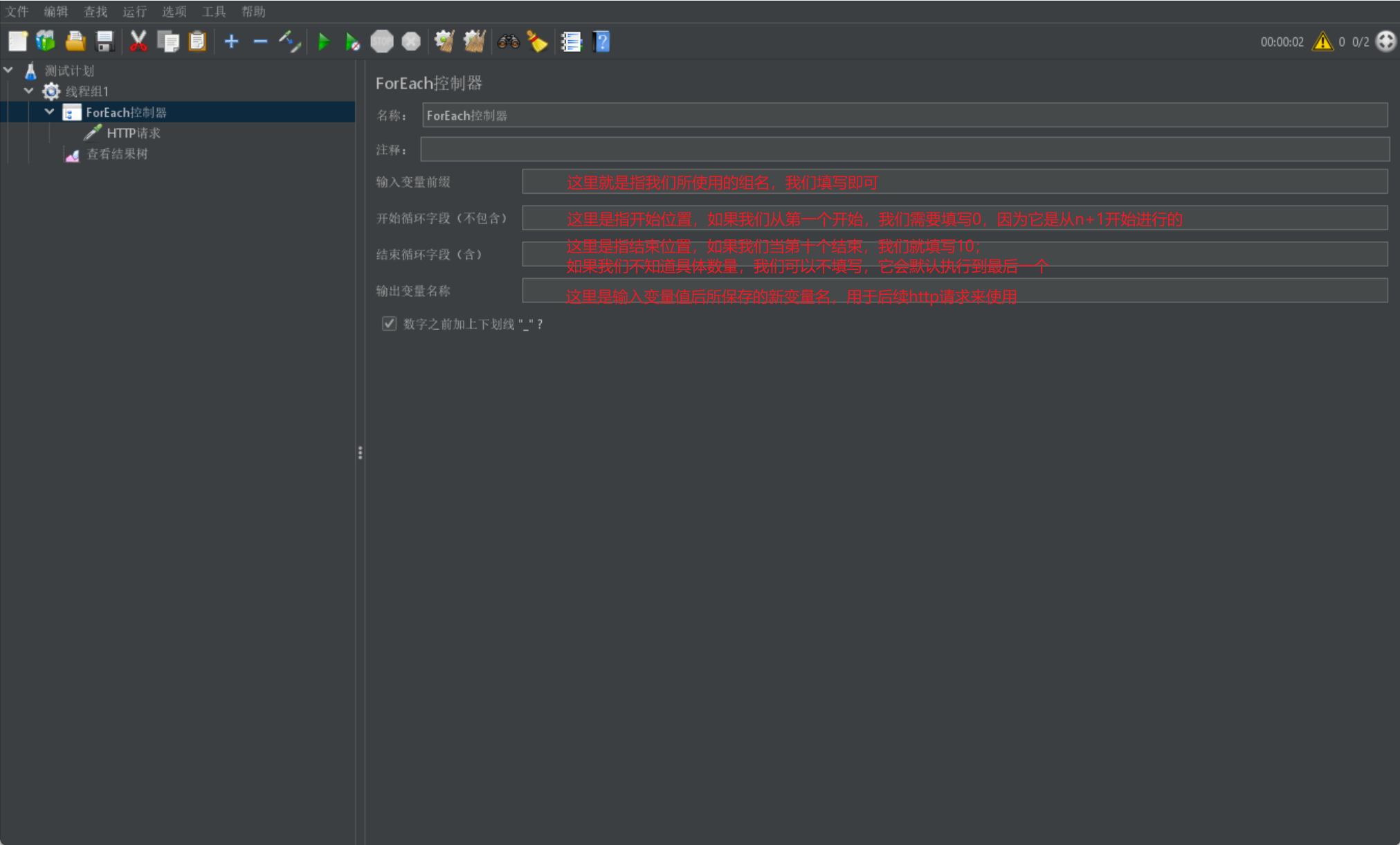
我们这里只介绍 foreach 如何与用户自定义变量来结合使用,其实原理都是相同的,针对组我们都可以采用 foreach 进行遍历操作:
定义用户自定义变量:
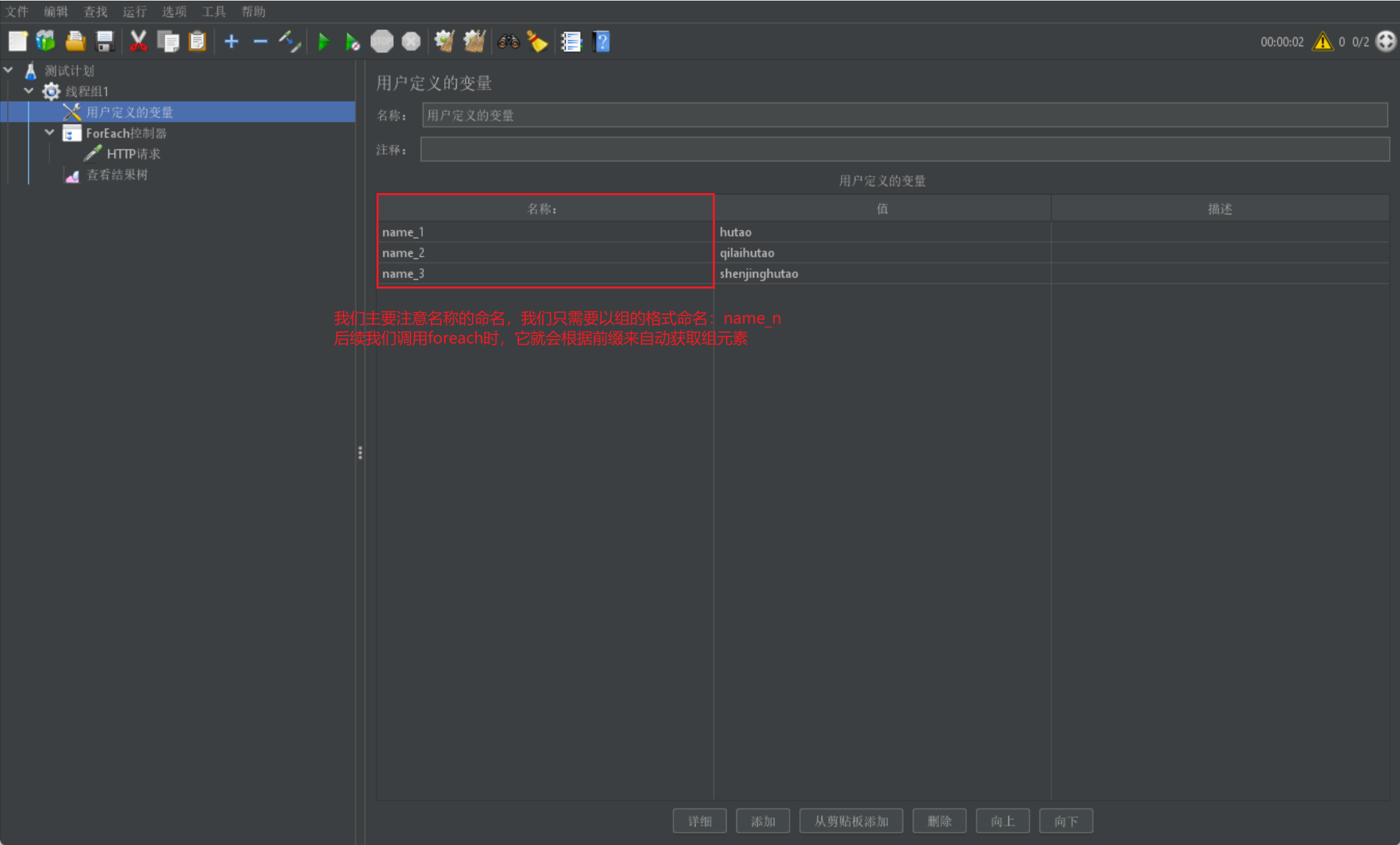
书写 foreach 控制器:
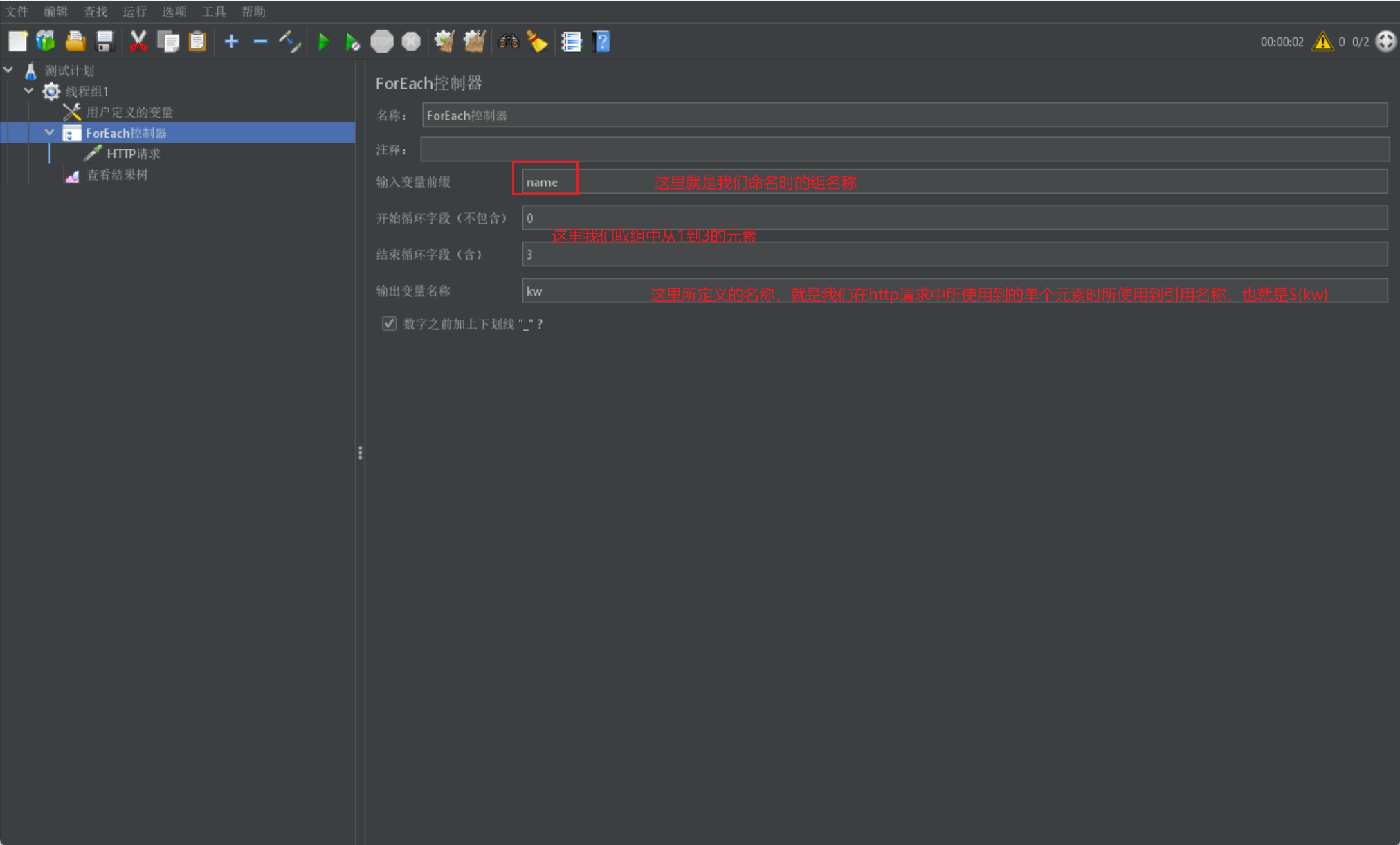
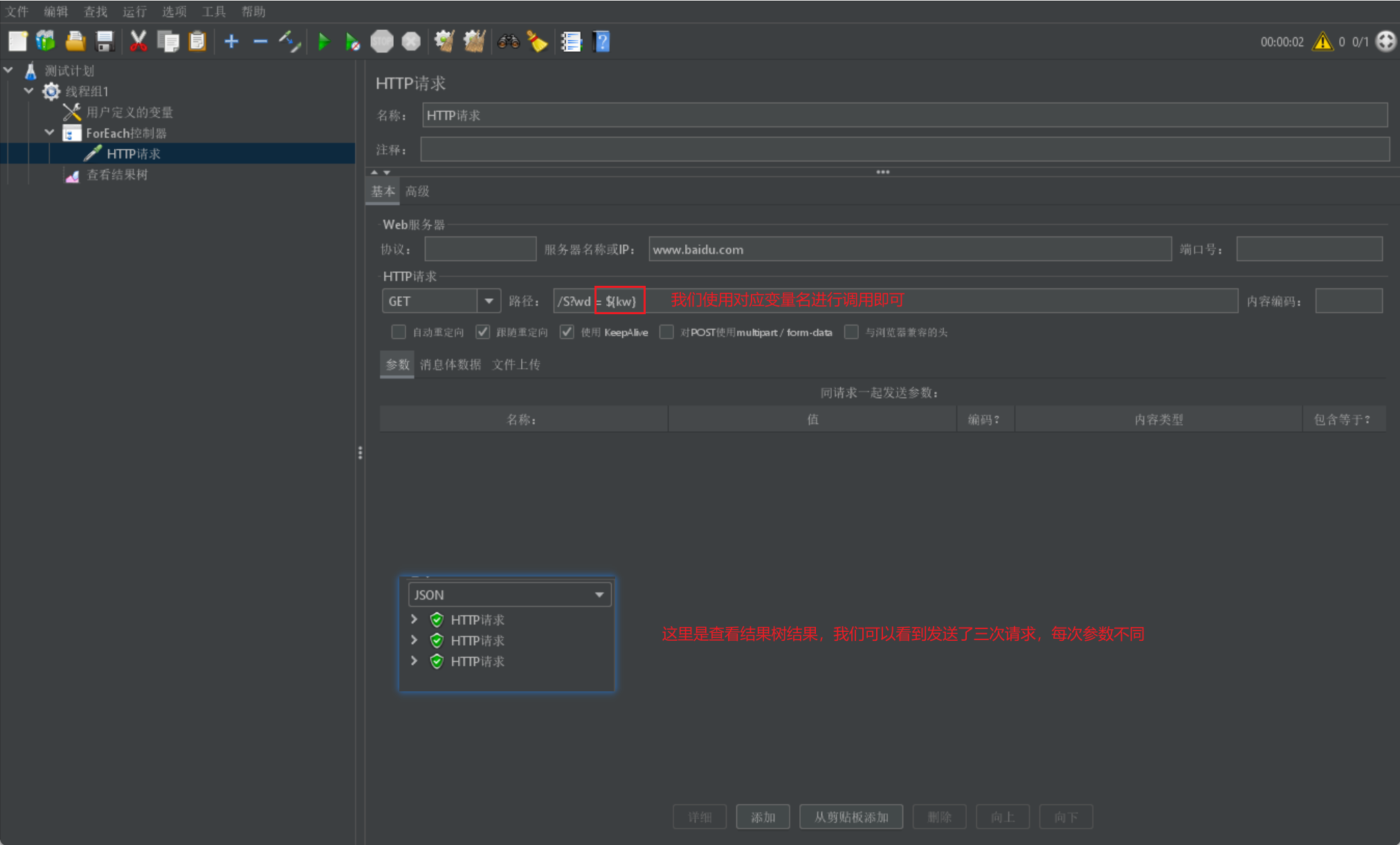
最后我们在 HTTP 请求中调用我们的 kw 即可,我们会在结果树中查看到三个结果:
Jmeter 定时器介绍
最后我们来介绍 Jmeter 中最常用的三种定时器:
定时器主要是方便我们通过控制 dps 和 time 来进行压力测试或性能测试等
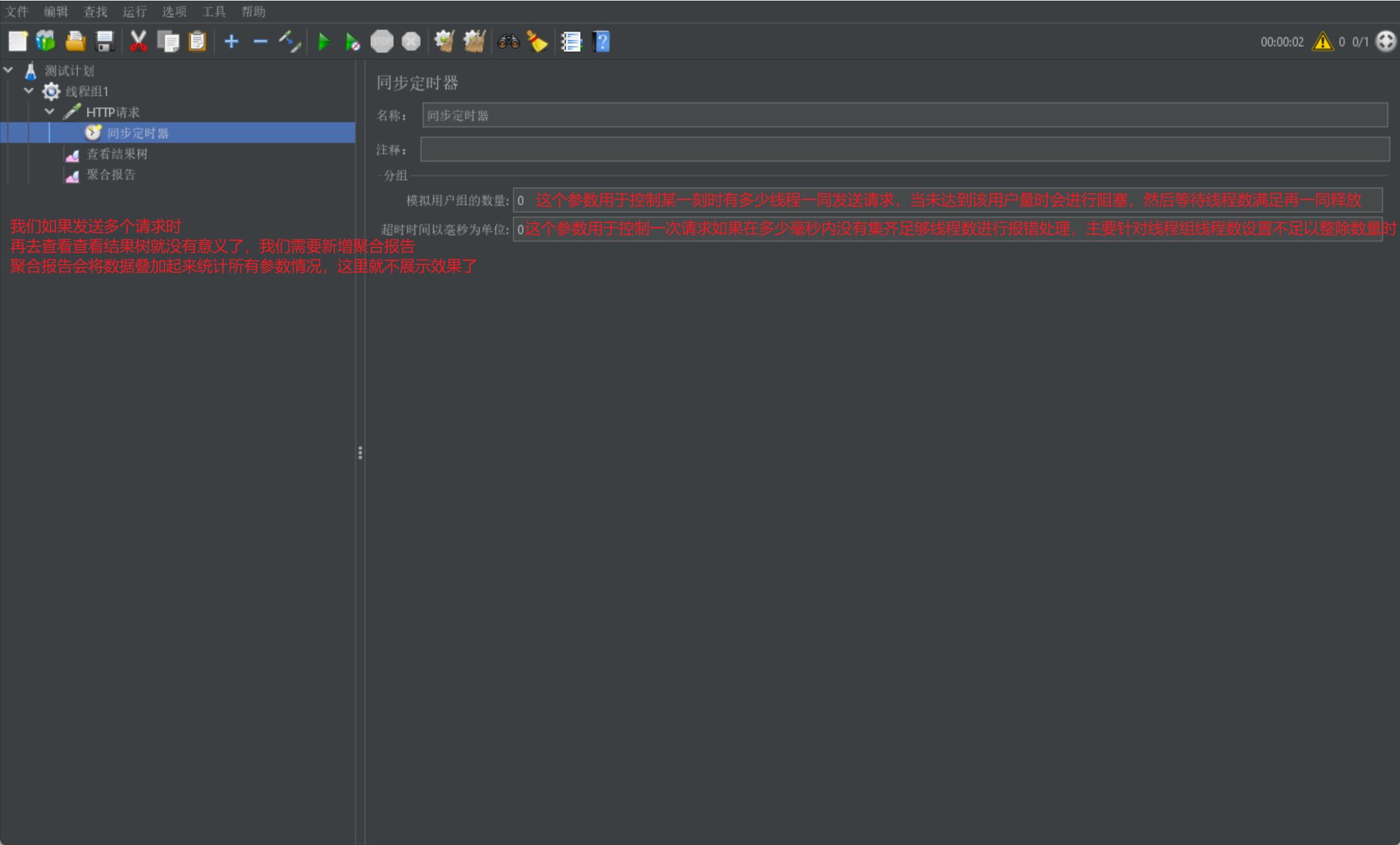
同步定时器
我们首先来介绍同步定时器:
阻塞线程,当在规定时间内达到一定线程数后,将这些线程一同释放,主要用于进行并发压力测试
我们直接介绍同步定时器的展示界面:
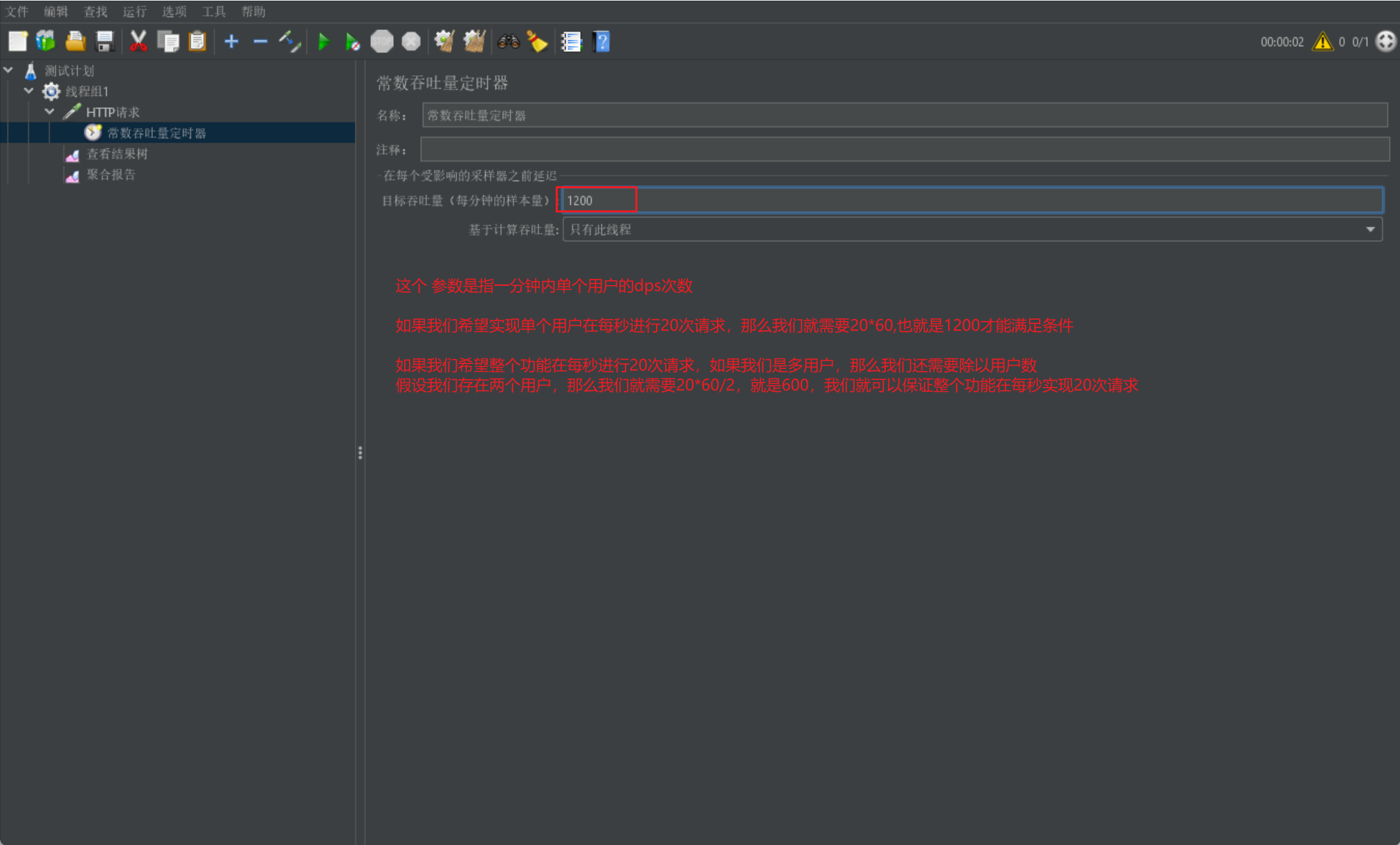
常数吞吐量定时器
下面我们来介绍常量吞吐量定时器:
用于控制单个用户的 dps 查询速度,常用于进行稳定测试或长时间压力测试
我们直接给出常数吞吐量定时器的展示界面:
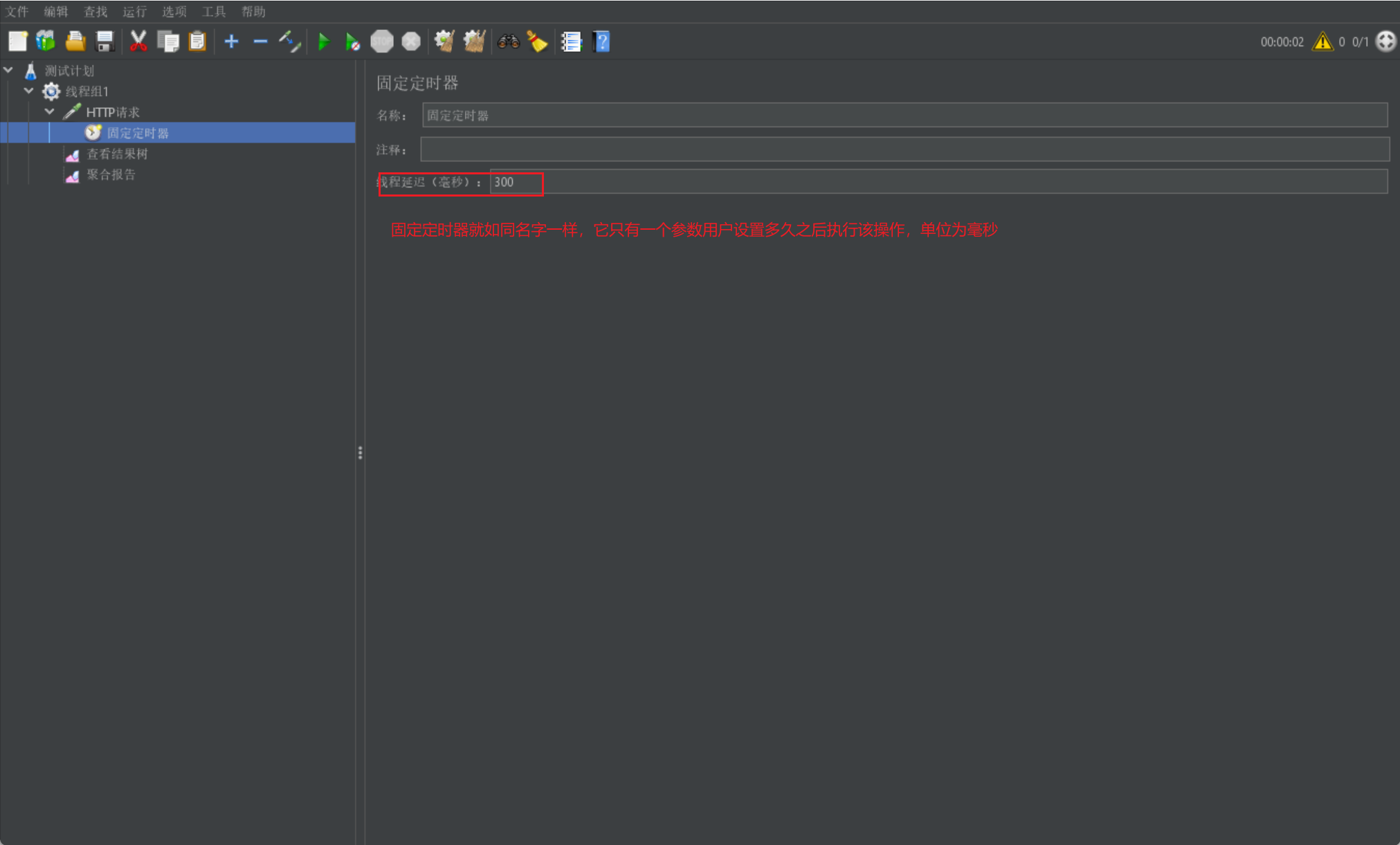
固定定时器
最后我们来介绍固定定时器:
用于控制该请求在多久之后进行执行,用于验证一些时间关系
我们直接给出固定定时器的展示界面:
结束语
这篇文章中详细介绍了性能测试以及性能测试工具 Jmeter 的详情使用,希望能为你带来帮助
文章转载自:秋落雨微凉
原文链接:https://www.cnblogs.com/qiuluoyuweiliang/p/17895887.html

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论