
从 Purge 机制说起,详解 GaussDB(for MySQL) 的优化策略
在 MySQL 中,尤其是在使用 InnoDB 引擎时,Purge 机制至关重要。它可以回收 undo log【1】,清理过期数据,减少磁盘占用,维护数据库的整洁与高效。
Purge 机制
MySQL InnoDB 引擎使用 undo log 来保存事务修改记录的历史信息。事务提交后, update undo log(指在 delete 和 update 操作中产生的回滚日志)未被立即删除,而是会被记录到 undo history list【2】,等待 Purge 线程进行最后的删除。当 undo log 不再被任何事务依赖时,系统就会扫描这个 undo log,将过期的索引数据删除并清理 undo log 本身,这个整体的清理过程就是 MySQL InnoDB 引擎的 Purge 机制。
Purge 的操作可以分成三个主要步骤:
1.遍历已经提交的 update undo log
根据 undo log header 中的信息判断这些事务是否存在过期数据,如果判断存在过期数据,就要触发 Purge 机制进行清理,否则就不需要。
2.通过 undo log 进行数据的物理删除
其过程主要包括:扫描 undo 页面来获取 undo 记录,遍历 undo 记录以确认是否要进行清理,如果需要则删除索引中的过期数据。
3.回收 undo log
purge 的速度会影响已提交的 undo log 的清理回收,如果 purge 的清理速度赶不上事务生成 undo log 的速度,undo log 就会出现堆积。如果条件允许的话,对 undo tablespace 进行 truncate(截断)来实现 undo 空间的回收。
undo log 堆积主要会产生两方面的影响:
第一, 额外的存储占用
undo log 和索引都有历史版本数据,undo log 未及时清理会导致 undo log 自身以及 undo 关联的过期索引数据产生堆积,占用额外的存储空间,容易引起不必要的扩容和开销,对客户业务而言是不利的。
第二,性能下降
undo log 堆积会导致过期索引数据堆积,索引页面中会存在大量已经标记为 delete 的数据,这时候每个索引页面实际的有效数据占比就会很低,业务 SQL 执行中会出现获取少量数据却需要进行大量页面 IO 的情况,最终导致 SQL 执行性能劣化。
Purge 优化实现
当前 undo 堆积已经成为数据库运行的一个痛点问题,因此华为云 GaussDB(for MySQL)团队专门针对 Purge 机制存在的问题进行了如下优化。
优化点一:coordinator 与 worker 流水线化
Purge 任务是由 Purge 线程完成的,是 InnoDB 的常驻线程。其线程主要分成两个角色,分别是一个 purge coordinator 线程和若干个 purge worker 线程,以下简称为 coordinator 和 worker。
事务的修改可能会残留过期数据在索引中,而老数据的相关信息又存留在 undo 记录中,事务提交时的 undo log 会被记录在回滚段的 History List 中,coordinator 负责从 History List 中获取 undo log,读取其中的 undo 记录,并将可能残留过期数据的 undo 记录分发给 worker 来进行处理。所以,当前 purge 的流程可以简单划分成以下两个阶段:
阶段一:coordinator 读取 undo log 包含的 undo 页面,获取 undo 记录。
阶段二:coordinator 将读取到的 undo 记录批量分发给 worker 来进行处理,线程之间并发执行,且 coordinator 也会负责一部分 undo 记录的处理,待 coordinator 和所有 worker 都执行完毕后开启下一轮处理。
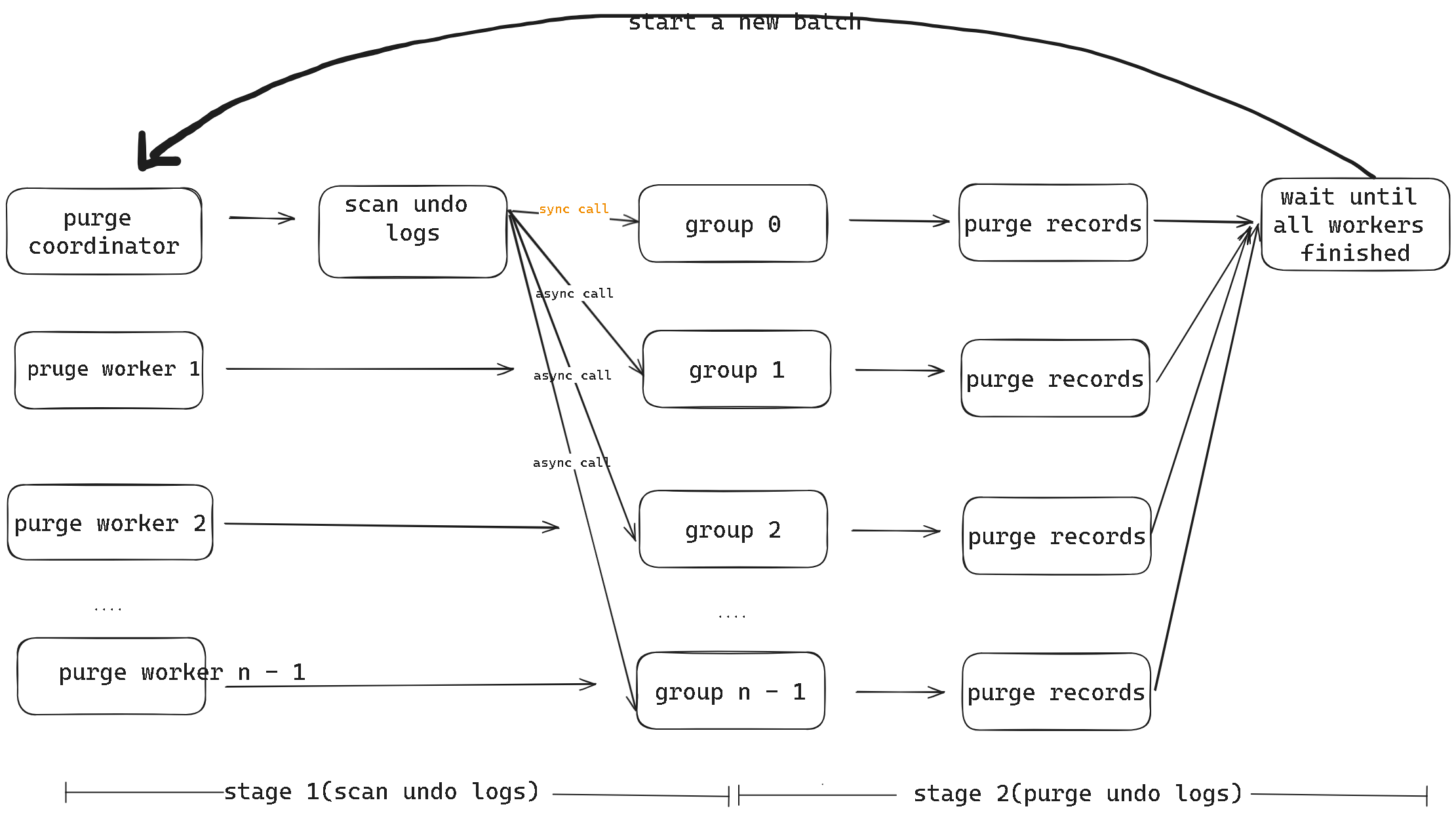
图 1 purge 原生流程
图 1 所示为原本的 Purge 流程,阶段一 coordinator 是单线程执行,阶段二 worker 是多线程并发,即并行执行,但整体两个阶段是串行执行,即阶段一执行完,阶段二才会继续执行。如果阶段一存在大量 undo 页面都需要进行 IO,串行执行就会严重影响整体的执行效率。不过,这种两阶段串行化执行的方式是可以优化的。
优化的整体思想即是:将 coordinator 和 worker 的执行流水线化。从图 1 可以看到,在原生 Purge 流程中,coordinator 除了负责扫描获取 undo 记录的任务,本身也会承担一部分 Purge 任务,且必须同步等待所有已分发的 Purge 任务完成之后,才能开始下一批次的 undo 记录扫描任务,这样就导致阶段一和阶段二是一个串行过程。
若令 coordinator 只单一地负责 undo 记录的扫描,不再兼职 Purge 清理任务,这样在 worker 执行的过程中,coordinator 就能直接继续去获取 undo 记录, 不再需要同步等待所有的 Purge 任务完成,这样就可以达到将原本串行的两阶段执行变成流水线执行的目的。
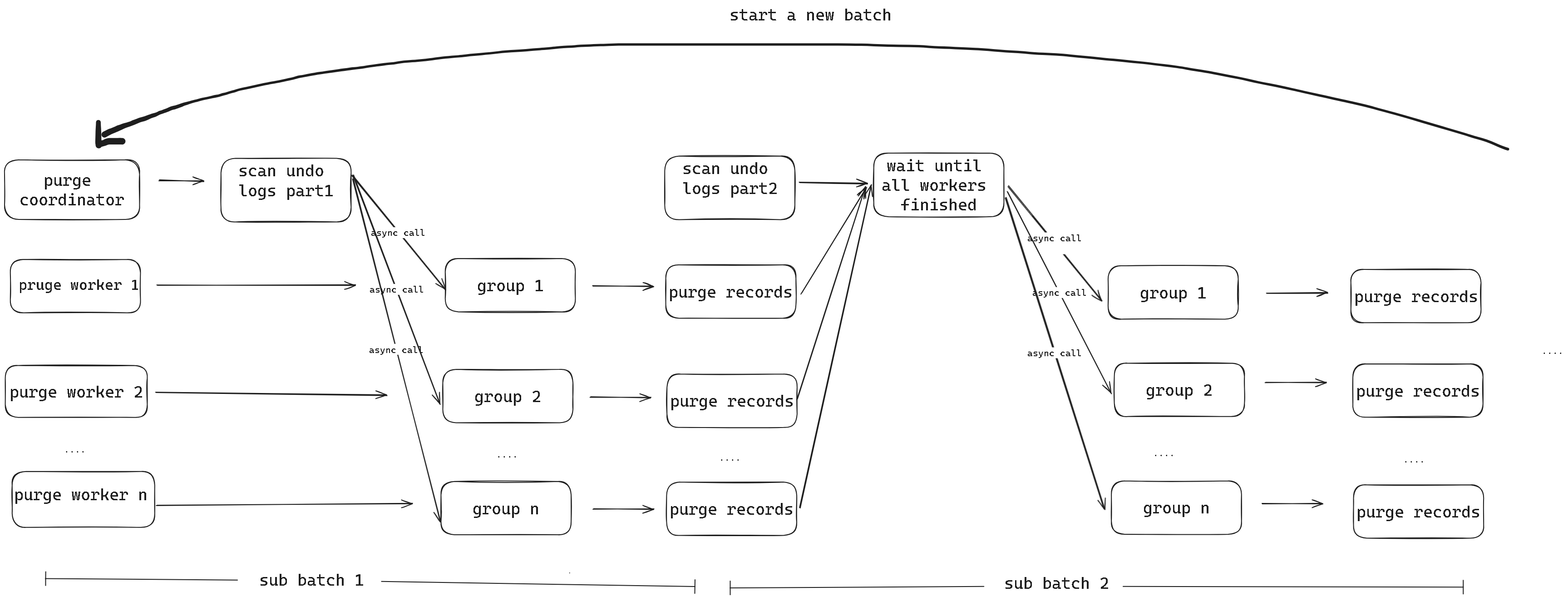
图 2 purge 优化流程
图 2 为优化后的 Purge 流程,Purge 优化会先将 innodb_purge_batch_size 指定的 undo 页面拆成若干个小的 batch, 拆分的批次数量由 innodb_rds_purge_subbatch_size 决定。coodinator 会先扫描第一个小 batch 的 undo 记录,然后分发给各个 worker 并行处理,在 worker 处理过程中,coordinator 可以去扫描第二个小 batch 的 undo 记录,等到所有 worker 执行完第一批 purge 任务后,coordinator 将立即分发第二批 undo 记录,worker 继续并行执行,而 coordinator 则立即开始并行地解析第三个小 batch 的 undo 记录,以此类推。
优化效果评估
当 coordinator 获取完第一个小 batch 之后,后续 coordinator 和 worker 都是同时运行的,每个 batch 运行的时间由 coordinator 和 worker 运行时间较长者决定,为了避免不必要的线程间等待,需要通过调整参数来令两个线程的耗时接近。
目前通过开启 innodb_monitor_enable 的 module_purge 监控,观察 coordinator 的耗时以及 worker 的耗时,再通过调整 innodb_purge_batch_size 和 innodb_rds_purge_subbatch_size 参数,将 coordinator 和 worker 的耗时调整到接近,让每个 batch 整体耗时降低。当前测试结果,innodb_purge_batch_size(600),innodb_rds_purge_subbatch_size(150)为最优配置,在此配置下 purge 速度有 1 倍提升。
优化点二:undo 记录二次分发
我们发现当前在 Purge 过程中,coordinator 分发 undo 记录给 worker 的策略是基于 InnoDB 层的 table id,即对于同一个表的 undo 记录都会分发给一个 worker。
这就会出现一种场景:当单个热点表被频繁执行 DML 时,会生成大量基于这个表的 undo 记录,此时无论 innodb_purge_threads 值设置多大,Purge 的任务都只会由一个线程承担,Purge 机制由原本设计上的并发执行回退成单线程执行,Purge 效率降低。
针对这个问题,我们在保持基于 table id 分发逻辑的基础上,增加一轮二次分发机制。
整体思路
01 根据 Purge 线程数将 undo 记录进行分组(如图 3),Purge 线程数量为 4,因此将 undo 记录划分为四个分组。
02 第一次分发(基于 table id 分发):将获取出来的 undo 记录根据 table id 进行分配,如果当前分组已存在该 table id 对应的 undo 记录,则继续分配至该分组;如果不存在包含该 table_id 的 undo 记录的分组,则寻找一个容量最小的分组,然后分配给小容量分组。
03 检测当前分配是否均衡,确认当前是否每个分组的记录数都小于 max_n= (m_total_rec + n_purge_threads - 1) / n_purge_threads。
如果是大于 max_n 则说明当前分组过载,否则就认为是均衡的。如图 3 中,max_n = (11+4 - 1) / 4 = 3,因此第二个、第四个分组均过载,需要进行二次分发。
04 第二次分发(基于分组负载分发):如果当前分组过载,则将过载部分数据转移至相邻下一个分组,然后校验下一个分组是否过载,循环校验,最多遍历 2 次所有分组。图 4 中,最终每个分组的记录数不超过 3 条,相同 table id 的 undo 记录也会分发到不同分组,例如 rec3 和 rec4 属于相同的 table,经过二次分发最终会分发到不同的分组,但是分发到不同分组对应最后的 Purge 结果并不影响。
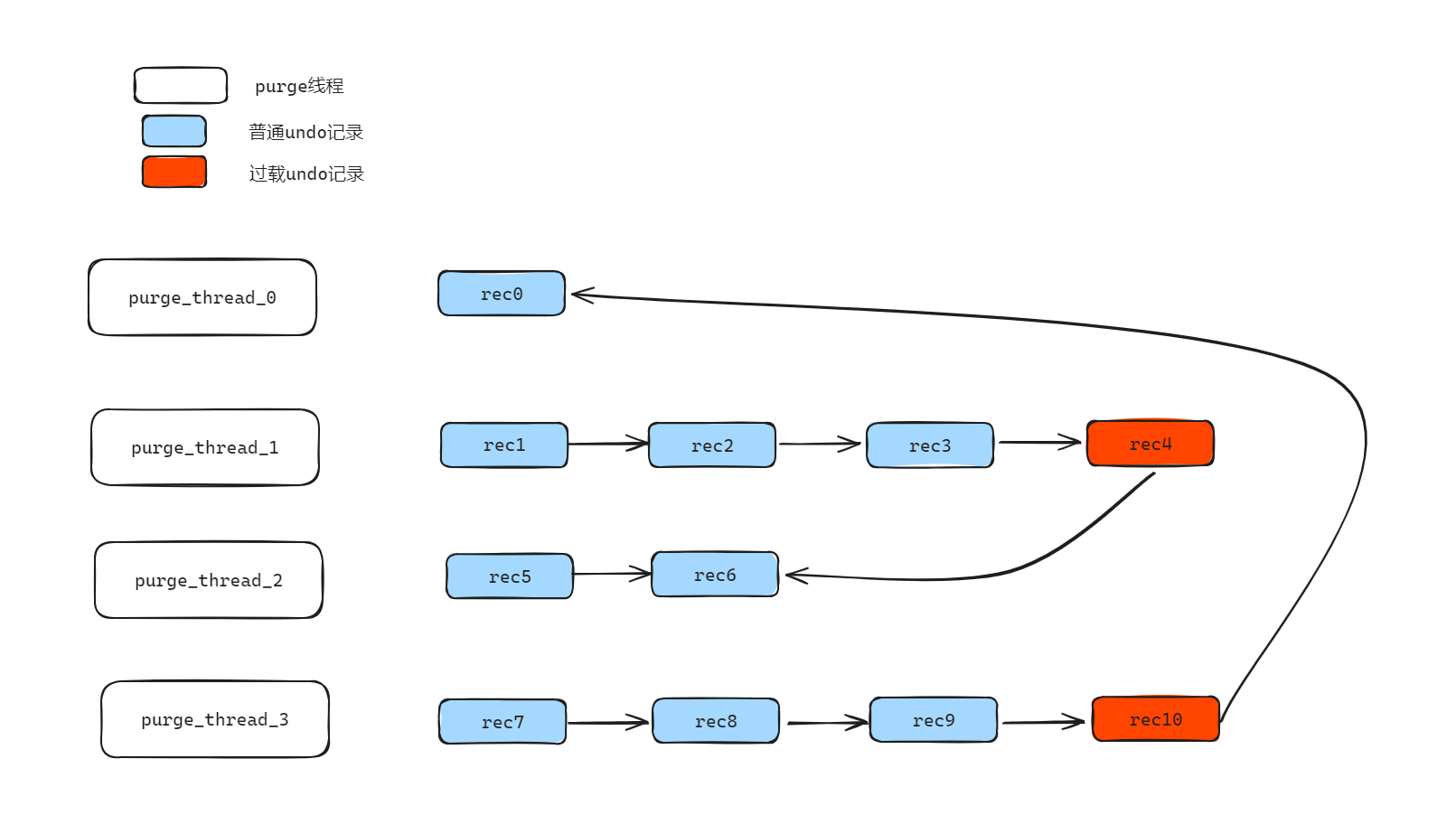
图 3 二次分发
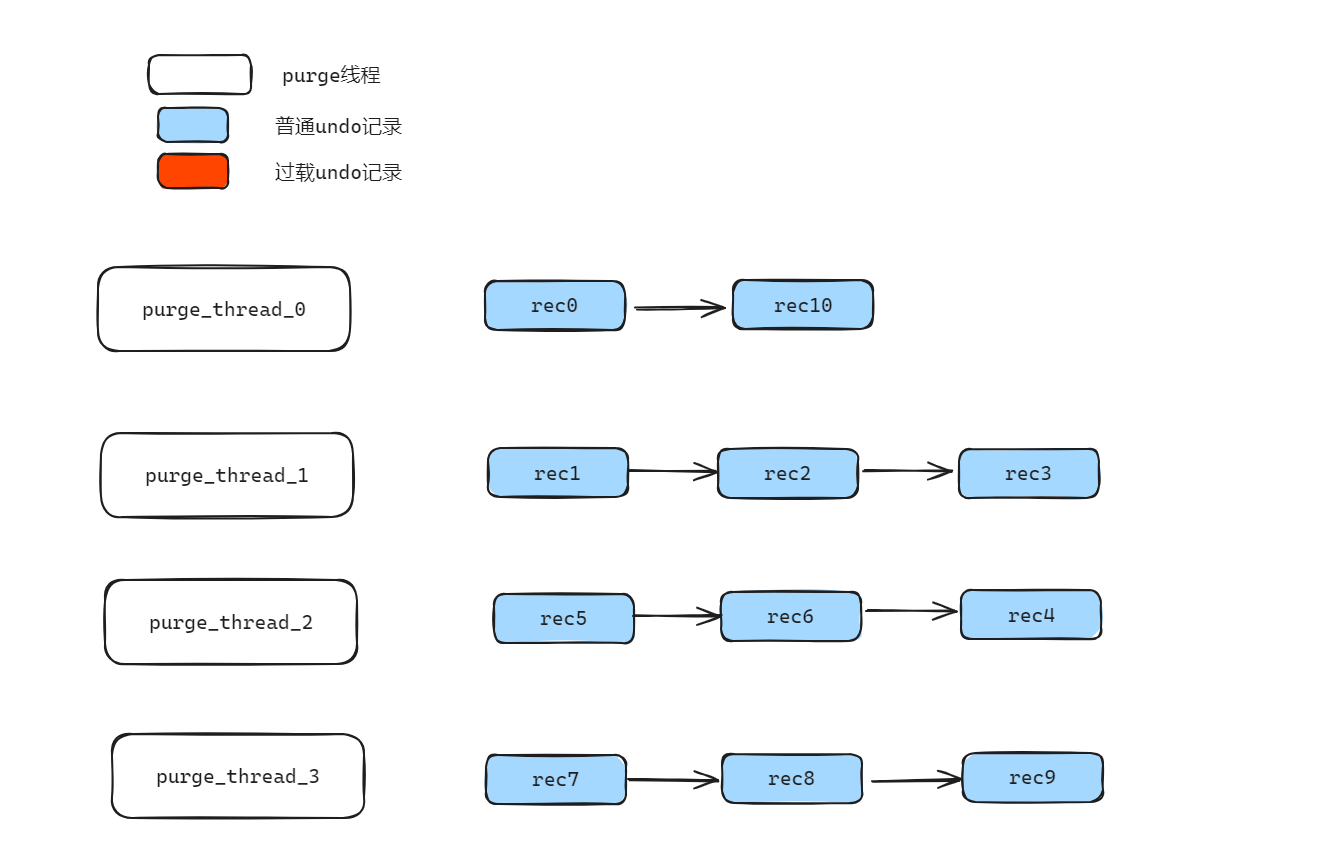
图 4 最终分发结果
优化点三:Purge 线程优先级调整
考虑到 Purge 相关的线程均为后台常驻线程,对于 GaussDB(for MySQL)而言,有较多后台线程,因此本身 Purge 相关线程的调度不处于高优先级,Purge 线程不会被系统频繁调度。所以,第三个优化点是调整 Purge 相关线程的优先级,GaussDB(for MySQL)将以高优先级启动 Purge 线程,确保 Purge 任务能够及时被调度。
测试验证
预备条件
innodb_rds_fast_purge_enabled: 以上三个优化开启的特性开关,开启后特性全部生效。
innodb_purge_batch_size :单个大 batch 处理的 undo 页面数,设置为 600,一个大 batch 会被划分成多个小 batch。
innodb_rds_purge_subbatch_size:单个小 batch 处理的 undo 页面数,设置为 150。
测试模型一:验证空载场景下 Purge 速度
实例规格:8U32G
数据库版本:GaussDB(for MySQL)-2.0.51.240300
操作系统:EulerOS 2.0(SPS)
数据量:64 张 sysbench 宽表,单表 1000 万行数据
并发数: 1/4/8/16/32/64/128/256/512 线程并发,读写模型
数据文件 :为了精确对比 purge 速度提升效果,我们对比空载场景即无业务负载。使用 history length 已经达到 5 亿的数据文件,在空载场景下对比开启优化和未开启优化的清理速度。
实际开启优化后,空载 Purge 清理速度大约有 1 倍提升,具体结果展示如下:
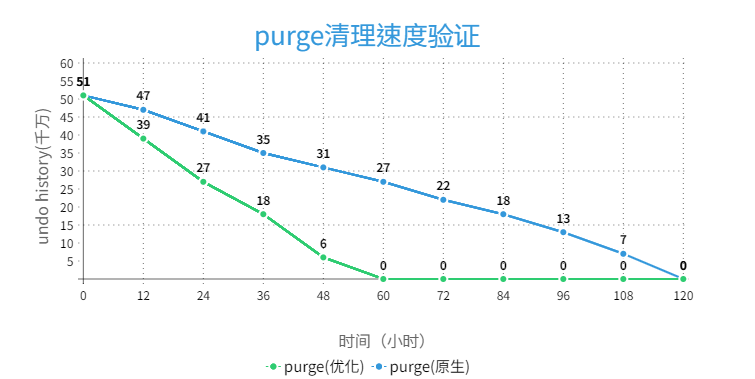
图 5 purge 速度对比
测试模型二:验证特性开启后对 SQL 执行性能的影响
实例规格:8U32G
数据库版本:GaussDB(for MySQL)-2.0.51.240300
操作系统:EulerOS 2.0(SPS)
数据量:64 张 sysbench 宽表,单表 1000 万行数据
并发数: 1/4/8/16/32/64/128/256/512 线程并发,读写模型
开启和关闭开关后,执行 sysbench 不同并发下的性能表现如下,开启关闭优化特性后,QPS 基本持平,说明优化特性对于业务性能基本可以忽略。
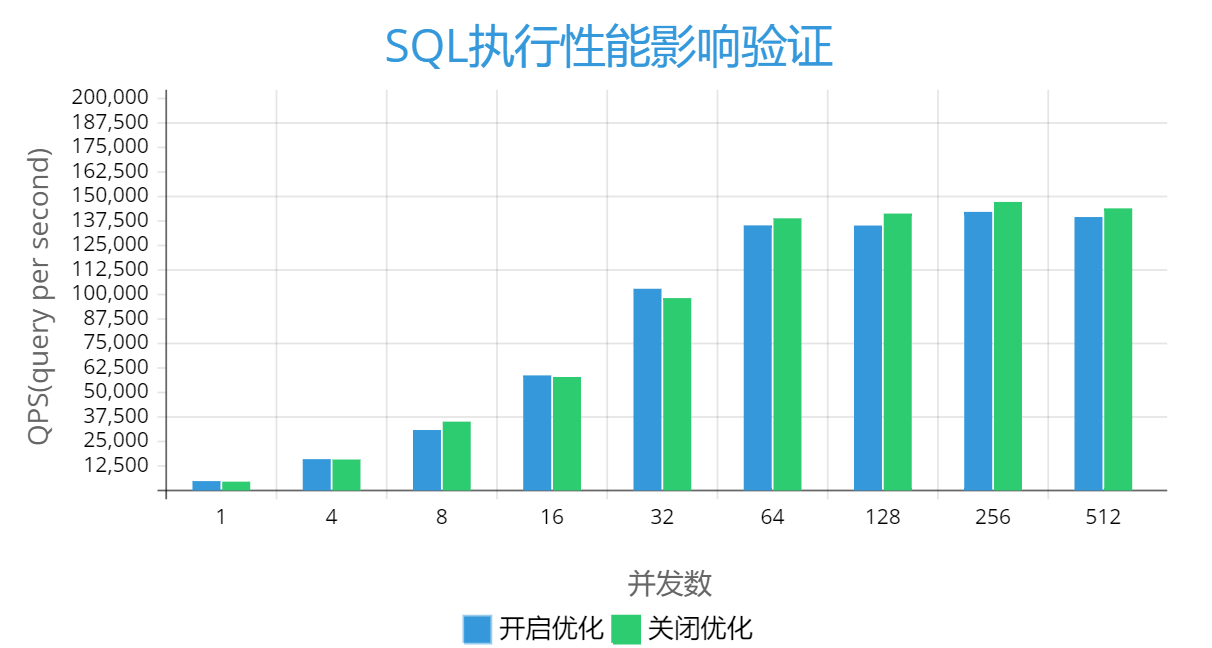
图 6 性能对比
总结
Purge 机制负责 GaussDB(for MySQL) InnoDB 过期数据的清理,对于数据库高性能平稳运行起到至关重要的作用。Purge 机制不及时不仅会导致过期数据的堆积,占用大量磁盘空间,还会影响 SQL 执行效率。当前 GaussDB(for MySQL)的 Purge 优化功能,通过任务流水线化、线程优先级调整、二次分发等手段,避免数据库 undo log 堆积,极大提升 Purge 的性能,大幅改善用户体验。
相关概念
【1】Undo Log:即回滚日志,保存了记录修改前的数据。在 InnoDB 存储引擎中,undo log 分为 insert undo log 和 update undo log。
insert undo log 是指在 insert 操作中产生的 undo log。由于 insert 操作的记录,只是对本事务可见,其它事务不可见,所以 undo log 可以在事务提交后直接删除,而不需要额外操作。
update undo log 是指在 delete 和 update 操作中产生的 undo log。该 undo log 可能要用于多版本并发控制的老版本数据获取,因此不能在提交的时候删除。
【2】Undo History List:即记录所有已提交事务的 undo log 的链表,可以通过该链表找到所有未被清理的已提交事务关联的 undo log。事务提交时,insert undo log 会被回收掉(reused 或者 free), update undo log 则会被移动到 Undo History List 链表。因此 Undo History List 的长度即 History Length 反应了未被处理和回收的 update undo log 的数量,我们一般通过 History Length 来评估 undo log 堆积的情况,可以通过 show engine innodb status 实时获取这个值。
文章转载自:华为云开发者联盟

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论