一、垂直分库场景
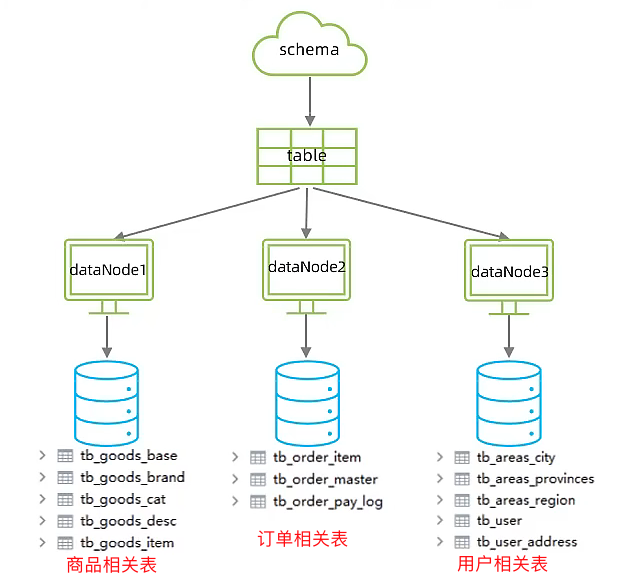
场景:在业务系统中,涉及一下表结构,但是由于用户与订单每天都会产生大量的数据,单台服务器的数据存储以及处理能力是有限的,可以对数据库表进行拆分,原有数据库如下
说明 1:整个业务系统中的表,大致分为四个,商品信息类的表,订单相关的表,用户相关表及省市区相关的表,这里暂时将省市区的表和用户相关的表放在一个数据节点上。
说明 2:因为商品,订单和用户相关的数据,每天都会产生海量的数据,所以我们采取的分库策略是将不同业务类型数据,放在不同数据库中,即垂直分库。
二、准备工作
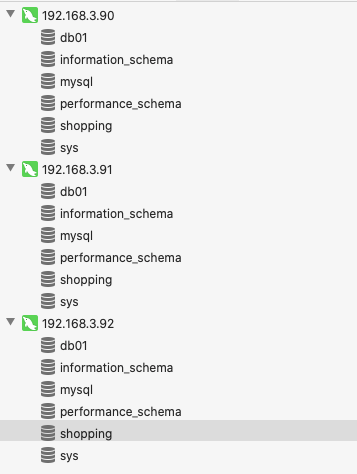
在 192.168.3.90,192.168.3.91,192.168.3.92 三台服务器上创建 shopping 数据库
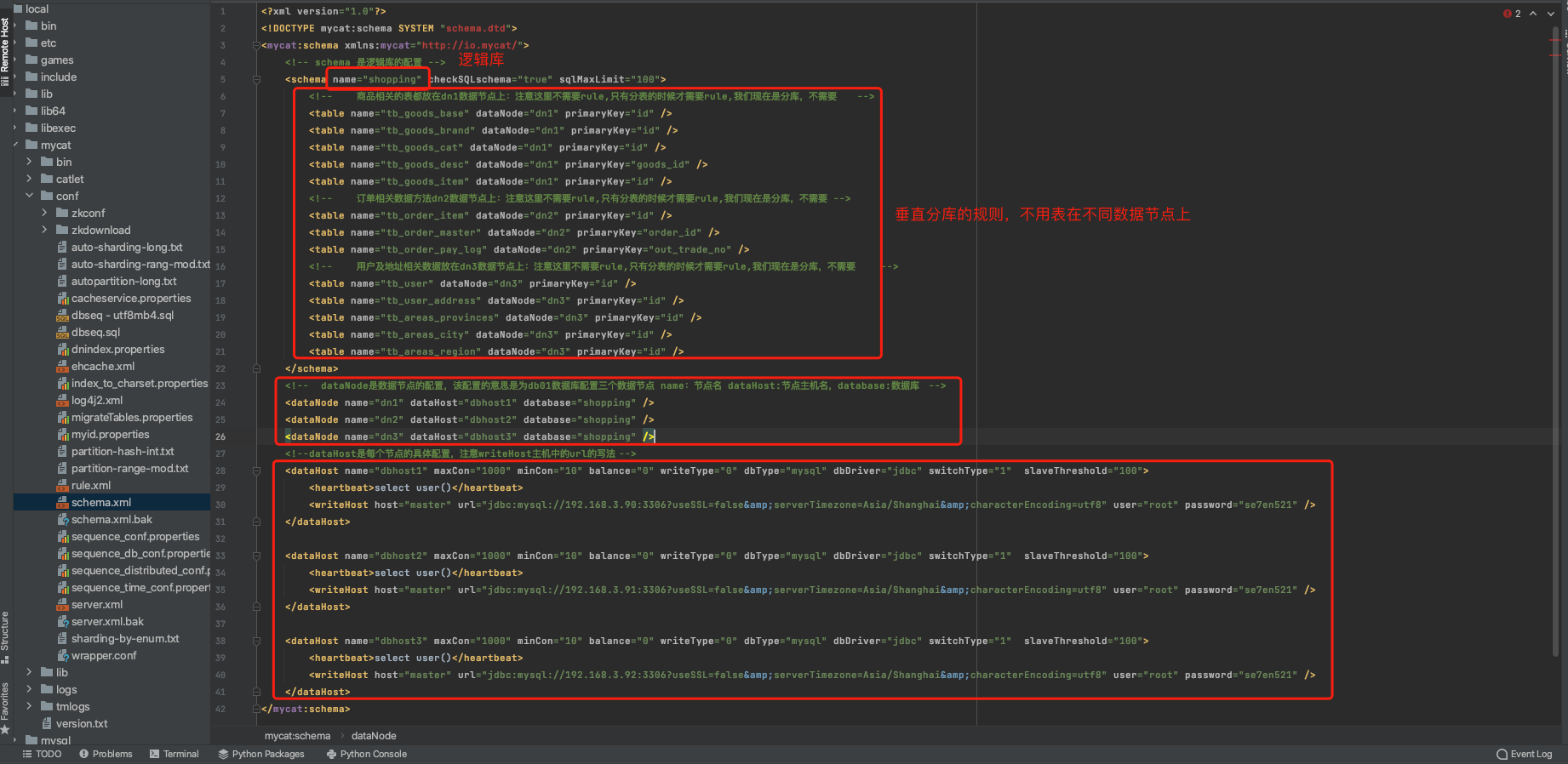
三、配置 schema.xml
说明 1:在 schema 标签里面的 table 标签不需要 rule 属性的,只有在分表时才需要 rule,我们现在是分库操作,不需要 rule 属性
说明 2:在 table 标签中,商品相关的表都放在 dn1 数据节点上,和订单相关的表都放在 dn2 数据节点上,和用户和地址相关的都放在 dn3 数据节点上
四、配置 server.xml
说明 1:修改 schemas 标签中的数据库名称为 shopping
五、Mycat 分库测试
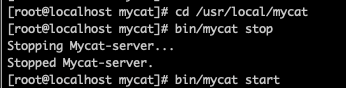
首先因为修改 Mycat 的配置文件,所以需要重启一下 Mycat,保证新的配置起作用。
重启之后,在 192.168.3.91 服务器上连接 Mycat
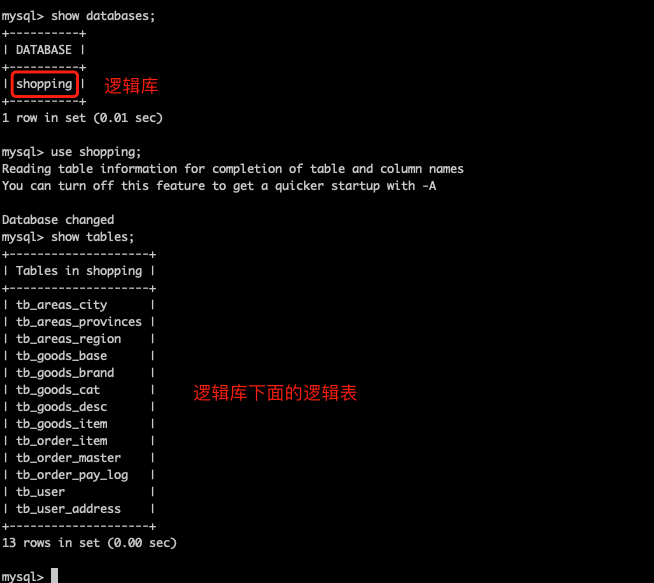
查看逻辑库和逻辑表
说明 1:目前这些表都还只是逻辑表,在 mycat 中存在,但是在 MySQL 的数据库中都没不存在,所以还需要把这些表创建出来。
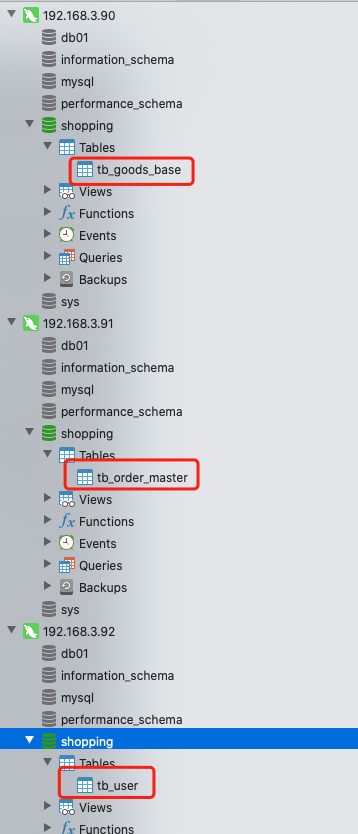
说明 2:这里我们创建三个表作为代表,其他暂时用不到的表就先不创建了,每个数据节点上创建一个表,然后这些表就会自动的出现在配置好的数据节点上。
create table tb_goods_base(id int auto_increment primary key, goods_name varchar(20), category varchar(20), price int);create table tb_order_master(order_id int auto_increment primary key, money int, goods_id int, receiver_province varchar(6), receiver_city varchar(6), receiver varchar(20));create table tb_user(id int auto_increment primary key, name varchar(20), age int, gender varchar(1));
复制代码
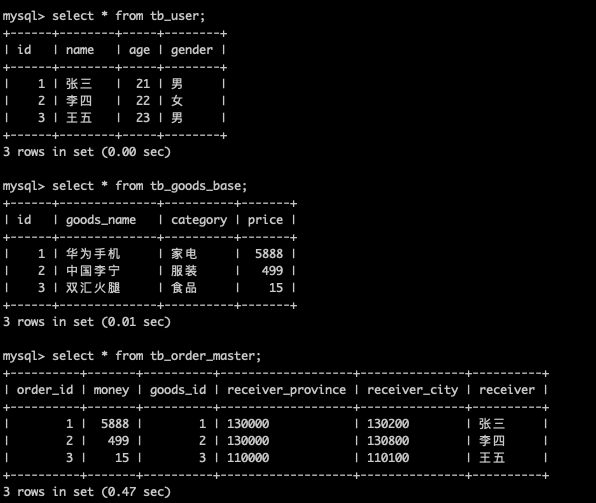
在往每个表中插入一些测试数据
insert into tb_user (name, age, gender) values ("张三", 21, "男");insert into tb_user (name, age, gender) values ("李四", 22, "女");insert into tb_user (name, age, gender) values ("王五", 23, "男");insert into tb_goods_base (goods_name, category, price) values ("华为手机","家电", 5888);insert into tb_goods_base (goods_name, category, price) values ("中国李宁","服装", 499);insert into tb_goods_base (goods_name, category, price) values ("双汇火腿","食品", 15);
insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (5888, 1, "130000", "130200", "张三");insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (499, 2, "130000", "130800", "李四");insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (15, 3, "110000", 110100, "王五");
复制代码
以上是对 Mycat 数据垂直分库的创建表,插入数据和查询数据的测试。
六、Mycat 多表查询测试
情况一:同一数据节点上的多表查询
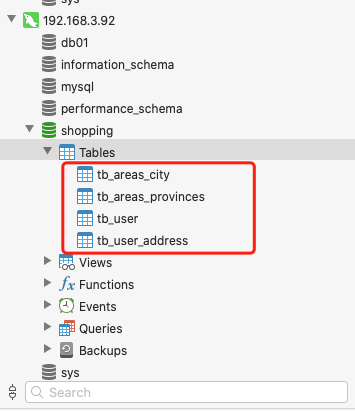
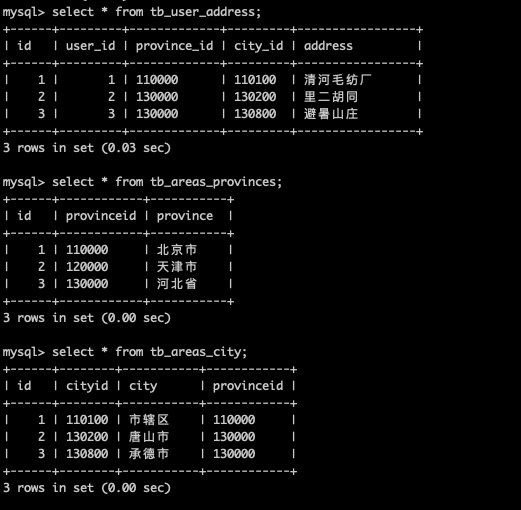
首先创建一个三个的表用于测试,同一数据节点内的多表查询,tb_areas_provinces, tb_areas_city, tb_user_address 三个表都是在 dn3 数据节点上的。
create table tb_areas_provinces (id int auto_increment primary key, provinceid varchar(6), province varchar(20));create table tb_areas_city (id int auto_increment primary key, cityid varchar(6), city varchar(20), provinceid varchar(6));create table tb_user_address (id int auto_increment primary key, user_id int, province_id varchar(6), city_id varchar(6), address varchar(20));
复制代码
说明 1:根据分库策略,创建的这三个测试表,都是属于用户和地址相关的数据,都在 dn3 数据节点上。
添加一些测试数据
insert into tb_areas_provinces (provinceid, province) values ("110000", "北京市");insert into tb_areas_provinces (provinceid, province) values ("120000", "天津市");insert into tb_areas_provinces (provinceid, province) values ("130000", "河北省");
insert into tb_areas_city (cityid, city, provinceid) values ("110100", "市辖区", "110000");insert into tb_areas_city (cityid, city, provinceid) values ("130200", "唐山市", "130000");insert into tb_areas_city (cityid, city, provinceid) values ("130800", "承德市", "130000");
insert into tb_user_address (user_id, province_id, city_id, address) values (1, "110000", "110100", "清河毛纺厂");insert into tb_user_address (user_id, province_id, city_id, address) values (2, "130000", "130200", "里二胡同");insert into tb_user_address (user_id, province_id, city_id, address) values (3, "130000", "130800", "避暑山庄");
复制代码
现多表查询需求是:根据 tb_user, tb_user_address 表,tb_areas_provinces 表和 tb_areas_city 表查出用户的名字已经所在的省,市,已经详细的地址:使用 Mycat 查询
select u.name, p.province, c.city, ua.address from tb_user as u, tb_user_address as ua, tb_areas_provinces as p, tb_areas_city as c where u.id = ua.user_id and ua.province_id = p.provinceid and ua.city_id = c.cityid;
复制代码
说明:同一数据节点内的多表联合查询在 mycat 中可以正确查出结果。
情况二:不在同一数据节点上的多表查询
需求:查询每一笔订单的收件地址信息(包含省、市信息),其中要用到 tb_order_master 在 dn2 数据节点上,tb_areas_provinces 和 tb_areas_city 在 dn3 数据节点上
select o.order_id, o.receiver,p.province, c.city from tb_order_master as o, tb_areas_provinces as p, tb_areas_city as c where o.receive_province=p.provinceid and o.receiver_city=c.cityid;
复制代码
这个时候就报错了, 报错的原因是:夸数据节点的多表查询,在执行 sql 的时候,Mycat 并不知道,将这条 sql 给哪一个数据节点处理。
解决方式:将一些数据量少,并且一旦确定了就很少改变的表,设置为全局表,全局表可以在每个数据节点上都能访问。而本案例中的省/市表就符合这个特性,中国每个城市的编码一旦确定,几乎就不会变化,这样的数据表,我们就可以设置为全局表。全局表会存在每一个数据节点上。
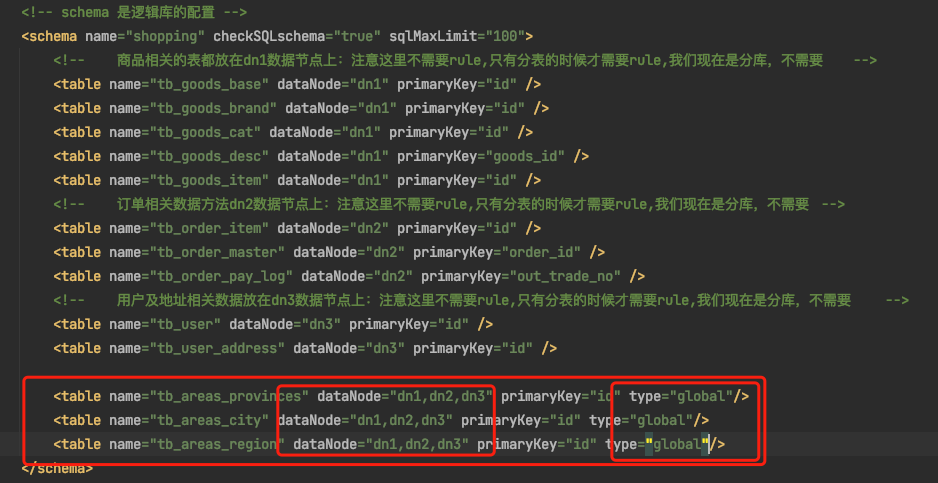
如果要设置全局表,只需要在 schema.xml 设置逻辑表的时候加上 type="global"参数即可
说明 1: 因为省市相关的数据表需要在 dn1,dn2,dn3 三个数据节点上,所以 dataNode 这里要设置 dn1,dn2,dn3 三个节点
说明 2:在 table 标签内添加 type="global"属性
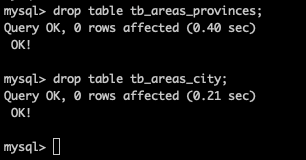
说明 3:因为之前的 areas 的表,都要变成全局表,所以需要数据清空在重新添加测试数据
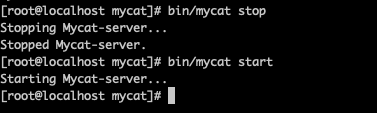
说明 4:因为修改了 Mycat 配置,所以需要重新启动 Mycat
重新创建 tb_areas_provinces 和 tb_areas_city 两个表
create table tb_areas_provinces (id int auto_increment primary key, provinceid varchar(6), province varchar(20));create table tb_areas_city (id int auto_increment primary key, cityid varchar(6), city varchar(20), provinceid varchar(6));
复制代码
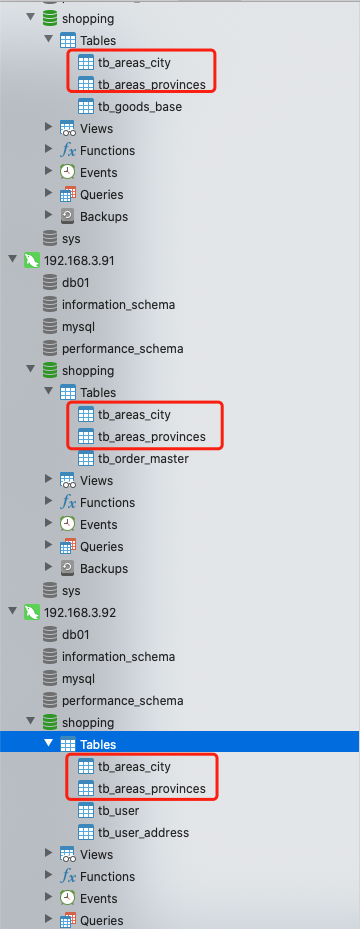
说明 5:这时候就会发现 tb_areas_procinces 和 tb_areas_city 出现在了三个数据节点上
再次插入数据进行多表查询测试:
insert into tb_areas_provinces (provinceid, province) values ("110000", "北京市");insert into tb_areas_provinces (provinceid, province) values ("120000", "天津市");insert into tb_areas_provinces (provinceid, province) values ("130000", "河北省");
insert into tb_areas_city (cityid, city, provinceid) values ("110100", "市辖区", "110000");insert into tb_areas_city (cityid, city, provinceid) values ("130200", "唐山市", "130000");insert into tb_areas_city (cityid, city, provinceid) values ("130800", "承德市", "130000");
复制代码
会发现插入的这些测试数据,会在 dn1,dn2,dn3 的每个数据节点的表中都添加成功。
现在就可以顺利的进行多表查询了。
说明 6:当全局表中的数据发生改变的时候,每个数据节点下的表,也都会发生数据改变。
文章转载自:Se7eN_HOU
原文链接:https://www.cnblogs.com/Se7eN-HOU/p/17908887.html
体验地址:http://www.jnpfsoft.com/?from=001


















评论