
转角遇到爱,资源中心系统和图数据库

01 前言
无论你信不信,图数据库就是资源管理系统写在基因里的真爱。虽然图计算最初是为了解决复杂社交网络、海量关联数据而兴起的新技术,但却非常契合通讯网络的业务逻辑和组网结构,它们是“歪打正着的天作之合”。
通讯网络与图计算的底层原理基本上是一致的,两者都是点线为基,由点线组合成端到端链路或网状的结构,实现单点、两点、多点的网络通讯。现实中资源管理以网络设备为点,光纤光缆为线,组成覆盖到千家万户的复杂组网。
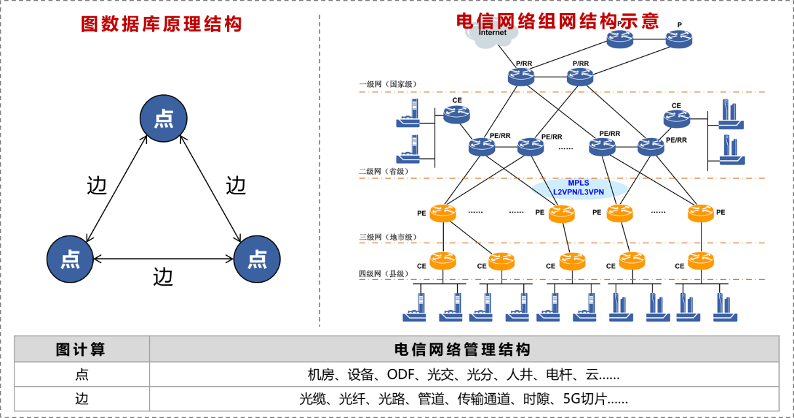
图计算与网络资源管理映射示意
02 难点
只从承载层的光缆网看,基础链接设施全国在千万级别,各省在百万级别,到地市也一般也有十万级别。组网中的关联关系是非常复杂的,传统的关系型数据库已经很难处理类似复杂关系的计算。在资源管理领域,目前有如下难点:

接入能力确认难:在地图上任意位置,确认网络覆盖的能力,比较依赖做好的数据,不能实时快速计算。
端到端路由配置难:组网的底层逻辑是打通亮点之间的通道,但随着距离越远,中间的节点越多,计算也就越难。需要大量人力投入,实时性跟不上。
建立资源知识图谱难:建立以资源为切入点,关联客户、业务、位置、告警、性能、运维、规划、设计等多源关系的知识图谱。
03 PK
从数据库检索逻辑层面,可以简单的归纳:传统关系型数据库是乘法,有几张表就是几个表查询消耗相乘。图数据库采用的逻辑是加法,随着深度进行消耗的累加。所以前者对算力的消耗是指数曲线,而后者是线性增长。从两者的检索逻辑看,图数据库更擅长深度关系型数据的查询。
以下举一个例子说明两者的逻辑的不同:
查询某机房下所有的设备端口,表结构:

多级关系模型示意
关系型数据库算法:消耗 D = |R|×|E|×|C|×|P|,消耗量级达到百亿,所以当查询深度超过 5 以后,可能查询就会挂起。(注:||示意查询消耗)
图数据库算法:消耗 D = |R|+|E|+|C|+|P|,消耗量级十万左右。相比较传统关系型数据库,消耗非常低。
当然传统关系型数据库为了解决深度的问题,会在端口表里面冗余存储机房的字段,以方便类似的查询逻辑,以及增加索引以减少消耗等,这里不做深入探讨。
04 实战
技术选型
图数据库选型:鉴于从主流使用频率和国产化呼声两方面的原因考虑,我们选择两款图数据库进行资源应用的数据实战验证:
Neo4j:头部图数据库产品老牌稳定,支持百亿顶点和边,有最大的市场份额。缺点是集群需要收费,对商业支持要求过高。
Nebula:国产化图数据库自研图存储,支持千亿顶点万亿边,没有在集群功能上设置收费门槛,可以更好的开放尝试。
国产化和开源免费是避不开的话题,前者关乎祖国的强大,后者关于口袋的经费,所以浩鲸科技孜孜不倦的在这方面投入研究。
环境准备
为了充分验证图数据库的性能,此次实战准备了点数据 830 万设备,边数据 560 万物理连,配套 3 台 8C16G 的 X86 服务器,验证在集群和非集群下的使用情况。
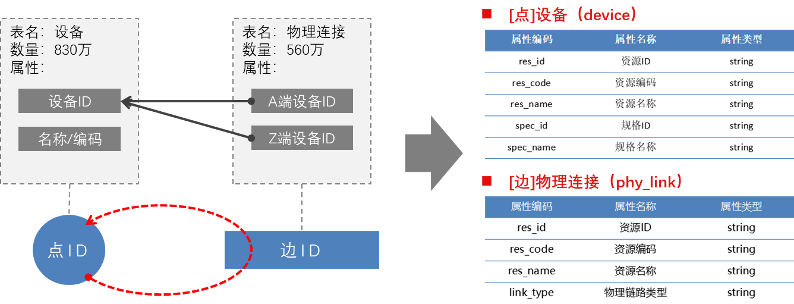
验证模型设定示意
实战 1:已知 AZ 两端搜索最短通路
场景:某银行需要从 A 地点的营业厅到 Z 地点的总部大楼实现稳定的网络通讯,即 AZ 两个位置拉通一条光纤光路。具体业务逻辑,根据客户指定的地址,找到关联覆盖的光分纤箱设备,然后根据物理连接表中的 AZ 端设备关系,级联查询到对端总部大楼的 ODF 设备。
要求:因为光衰与光纤长度,级联的光设施数量正比,所以路径越短约好,级联设备越少约好。
现状情况:
1、实时性差:通过任务提前计算好宏观路由表,包括起始设备,终止设备,空闲纤芯数。全量任务只能定时执行,每天一次。
2、查询效率低:百万数据下 3 跳以下 10 秒左右,超过 5 跳大概率挂死。
验证情况:
对于 5 跳左右的查询,图数据库的搜索时长控制在非常低的毫秒级,基本上达到实时的互动,虽然两款图数据库表现有细微的差距,但不影响使用感知。而关系型数据库 PG 在此场景下,直接挂起无法给出查询结果。


实战 1 验证结果
实战 2:已知 A 端搜索到指定规格 Z 端最短通路
场景:相比场景 1,此业务只明确了 A 端的设备 ID,并不知道 Z 端具体要到哪个设备,只知道要连接到此地址下的规格为 ODF 的设备。
要求:为了光衰最小,要求两端的最短路径。
现状情况:
1、通过全量计算生成路由表,耗时大约 40 分钟。
2、每天监听增量数据,对增量数据进行重新计算并更新路由表。
全量计算对数据库消耗很大,且计算很慢,增量计算性能也很差,且经常出现计算失败的情况,实效性和准确性都无法保障。
图数据实战:
在集群加持下 Nebula 数据库表现特别良好,而且随着跳数的增多,性能没有出现劣变,维持稳定的水平,难度最大的 5 跳只耗时 35 毫秒。Neo4j 非集群下表现较好,但随着跳数的增多,查询消耗的时长有较大的增幅。关系型 PG 库由于百万级多级关联,也出现无法实时查询结果。

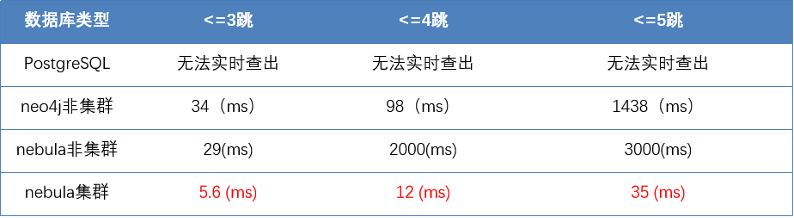
实战 2 验证结果
不足
当然图数据库并不是万能的,以上的实战只是在深度查询场景下证明图计算有巨大优势,并不能完全替代关系型数据库,主要原因如下:
图不擅长复杂的 OLTP 计算,而关系型数据库更擅长记账类应用;
图数据库不适合并发非常高的项目:图数据库天然是做海量关系数据的计算处理,所以计算复杂度比较高,并发性能不如关系型数据库;
查询语言尚未统一:不同图模型、产品使用的查询语言不一样,需要考虑使用友好及未来的转换成本;
生态还在不断完善:图数据库诞生及发展年限比较短,还需要未来一定时间的积累和沉淀。
结论
图数据库的算法基因决定深度关系查询的速度要比关系型数据库快,而且深度越大,比对效果越明显,提升百倍以上的效率。
图数据库与关系型数据库擅长不同的场景,所以他们是互补的关系,两者结合产生 1+1 大于 2 的效果。

两种数据库互补模式
05 展望
浩鲸科技致力于在网络自智、数字孪生、算力网络等方向和场景上叠加图数据的深度检索能力。当前在国内超过 20 多省资源中心项目为孵化平台,预研图数据库在客户资源树、云网资源树、资源知识图谱方面的创新,逐步构建完善的图数据库应用体系,赋能更好的使用体验,为客户创造更多的生产价值。
版权声明: 本文为 InfoQ 作者【鲸品堂】的原创文章。
原文链接:【http://xie.infoq.cn/article/9f053616a97a504d039e3b004】。文章转载请联系作者。

全球领先的数字化转型专家 2021-03-16 加入
鲸品堂专栏,一方面将浩鲸精品产品背后的领先技术,进行总结沉淀,内外传播,用产品和技术助力通信行业的发展;另一方面发表浩鲸专家观点,品读行业、品读市场、品读趋势,脑力激荡,用远见和创新推动通信行业变革。









评论