前言
分布式系统中,我们经常需要对数据、消息等进行唯一标识,这个唯一标识就是分布式 ID,那么我们如何设计它呢?本文将详细讲述分布式 ID 及其生成方案。
一、为什么需要分布式 ID
目前大部分的系统都已是分布式系统,所以在这种场景的业务开发中,经常会需要唯一 ID 对数据进行标识,比如用户身份标识、消息标识等等。
并且在数据量达到一定规模后,大部分的系统也需要进行分库分表,这种场景下单库的自增 ID 已达不到我们的预期。所以我们需要分布式 ID 来对各种场景的数据进行唯一标识。
二、分布式 ID 的特性
主要特性:
除此之外根据不同场景还有:
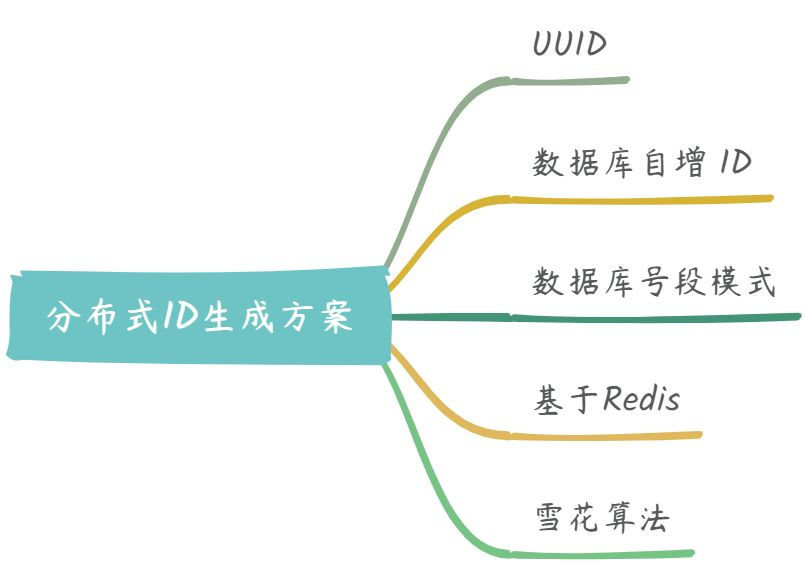
二、分布式 ID 常见生成方案
1. UUID
UUID(Universally Unique Identifier),即通用唯一识别码。UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息。
UUID 是由 128 位二进制数组成,通常表示为 32 个十六进制字符,形如:
550e8400-e29b-41d4-a716-446655440000
复制代码
这个字符串由五个部分组成,以连字符-分隔开,具体如下:
主要的 UUID 版本及其生成规则:
Java 中 UUID 对版本 4 进行了实现:
public static void main (String[] args) { // 默认版本 4 System.out.println(UUID.randomUUID()); // 版本 3,由命名空间和名字的MD5散列生成,相同命名空间结果相同 // 如下,"fuxing"返回的UUID一直为8b9b6bc3-90c8-37ef-bbef-0ed0c552718f System.out.println(UUID.nameUUIDFromBytes("fuxing".getBytes()));}
复制代码
优点: 本地生成,没有网络消耗,性能非常高。
缺点:
占用空间大,32 个字符串,128 位。
不安全:版本 1 可能会造成 mac 地址泄露。
无序,非自增。
机器时间不对,可能造成 UUID 重复。
2. 数据库自增 ID
实现简单,解释通过数据库表中的主键 ID 自增来生成唯一标识。如下,维护一个 MySQL 表来生成 ID。
CREATE TABLE `unique_id` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `value` char(10) NOT NULL DEFAULT '', PRIMARY KEY (`id`),) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
复制代码
当需要生成分布式 ID 时,向表中插入数据并返回主键 ID,这里 value 无含义,只是为了占位,方便插入数据。
优点: 实现简单,基本满足业务需求,且天然有序。
缺点:
数据库自身的单点故障和数据一致性问题。
不安全,比如可根据自增来判断订单量。
高并发场景可能会受限于数据库瓶颈。
那么有没有办法解决数据库自增 ID 的缺点呢?
通过水平拆分的方案,将表设置到不同的数据库中,设置不同的起始值和步长,这样可以有效的生成集群中的唯一 ID,也大大降低 ID 生成数据库操作的负载,示例如下。
unique_id_1配置:
set @@auto_increment_offset = 1; -- 起始值set @@auto_increment_increment = 2; -- 步长
复制代码
unique_id_2配置:
set @@auto_increment_offset = 2; -- 起始值set @@auto_increment_increment = 2; -- 步长
复制代码
这个还是需要根据自己的业务需求来,水平扩展的集群数量要符合自己的数据量,因为当设置的集群数量不足以满足高并发时,再次进行扩容集群会很麻烦。多台机器的起始值和步长都需要重新配置。
3. 数据库号段模式
号段模式是当下分布式 ID 生成器的主流实现方式之一,比如美团 Leaf-segment、滴滴 Tinyid、微信序列号等都使用的该方案,下面的大厂中间件中会展开说明。
号段模式也是基于数据库的自增 ID,数据库自增 ID 是一次性获取一个分布式 ID,号段模式可以理解成从数据库批量获取 ID,然后将 ID 缓存在本地,以此来提高业务获取 ID 的效率。
例如,每次从数据库获取 ID 时,获取一个号段,如(1,1000],这个范围表示 1000 个 ID,业务应用在请求获取 ID 时,只需要在本地从 1 开始自增并返回,而不用每次去请求数据库,一直到本地自增到 1000 时,才去数据库重新获取新的号段,后续流程循环往复。
表结构可进行如下设计:
CREATE TABLE `id_generator` ( `id` int(10) NOT NULL, `max_id` bigint(20) NOT NULL COMMENT '当前最大id', `step` int(10) NOT NULL COMMENT '号段的步长', `version` int(20) NOT NULL COMMENT '版本号', `biz_type` int(20) NOT NULL COMMENT '业务场景', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
复制代码
其中max_id和step用于获取批量的 ID,version是一个乐观锁,保证并发时数据的正确性。
比如,我们新增一条表数据如下。
然后我们可以使用该号段批量生成的 ID,当max_id = 1000,则执行 update 操作生成新的号段。新的号段的 SQL。
UPDATE id_generator SET max_id = #{max_id+ step}, version = version + 1 WHERE version = #{version} AND biz_type = 001;
复制代码
优点: ID 有序递增、存储消耗空间小。
缺点:
数据库自身的单点故障和数据一致性问题。
不安全,比如可根据自增来判断订单量。
高并发场景可能会受限于数据库瓶颈。
缺点同样可以通过集群的方式进行优化,也可以如 Tinyid 采用双缓存进行优化,下面的大厂中间件中会展开说明。
4. 基于 Redis
当使用数据库来生成 ID 性能不够的时候,可以尝试使用 Redis 来生成 ID。原理则是利用 Redis 的原子操作 INCR 和 INCRBY 来实现。
命令示例:
优点: 不依赖于数据库,使用灵活,支持高并发。
缺点:
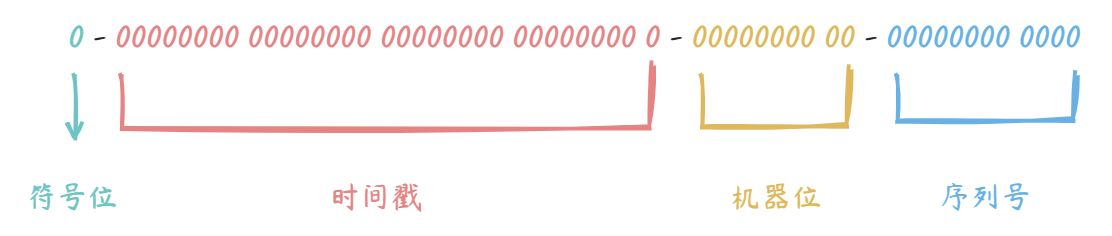
5. 雪花算法
雪花算法(Snowflake)是 twitter 公司内部分布式项目采用的 ID 生成算法。结果是一个 long 型的 ID。Snowflake 算法将 64bit 划分为多段,分开来标识机器、时间等信息,具体组成结构如下图所示:
结构说明:
优点:稳定性高,不依赖于数据库等第三方系统。使用灵活方便,可以根据业务需求的特性来调整算法中的 bit 位。单机上 ID 单调自增,毫秒数在高位,自增序列在低位,整体上按照时间自增排序。
缺点:
强依赖机器时钟,如果机器上时钟回拨,可能导致发号重复或者服务处于不可用状态。
ID 可能不是全局递增,虽然 ID 在单机上是递增的。
Redis 出现单点故障问题,可能会丢数据导致 ID 重复。
算法实现(Java):
package util; import java.util.Date; /** * @ClassName: SnowFlakeUtil * @Author: jiaoxian * @Date: 2022/4/24 16:34 * @Description: */public class SnowFlakeUtil { private static SnowFlakeUtil snowFlakeUtil; static { snowFlakeUtil = new SnowFlakeUtil(); } // 初始时间戳(纪年),可用雪花算法服务上线时间戳的值 // 1650789964886:2022-04-24 16:45:59 private static final long INIT_EPOCH = 1650789964886L; // 时间位取& private static final long TIME_BIT = 0b1111111111111111111111111111111111111111110000000000000000000000L; // 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断 private long lastTimeMillis = -1L; // dataCenterId占用的位数 private static final long DATA_CENTER_ID_BITS = 5L; // dataCenterId占用5个比特位,最大值31 // 0000000000000000000000000000000000000000000000000000000000011111 private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS); // dataCenterId private long dataCenterId; // workId占用的位数 private static final long WORKER_ID_BITS = 5L; // workId占用5个比特位,最大值31 // 0000000000000000000000000000000000000000000000000000000000011111 private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS); // workId private long workerId; // 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095 private static final long SEQUENCE_BITS = 12L; // 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095 // 0000000000000000000000000000000000000000000000000000111111111111 private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS); // 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095 private long sequence; // workId位需要左移的位数 12 private static final long WORK_ID_SHIFT = SEQUENCE_BITS; // dataCenterId位需要左移的位数 12+5 private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS; // 时间戳需要左移的位数 12+5+5 private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS; /** * 无参构造 */ public SnowFlakeUtil() { this(1, 1); } /** * 有参构造 * @param dataCenterId * @param workerId */ public SnowFlakeUtil(long dataCenterId, long workerId) { // 检查dataCenterId的合法值 if (dataCenterId < 0 || dataCenterId > MAX_DATA_CENTER_ID) { throw new IllegalArgumentException( String.format("dataCenterId 值必须大于 0 并且小于 %d", MAX_DATA_CENTER_ID)); } // 检查workId的合法值 if (workerId < 0 || workerId > MAX_WORKER_ID) { throw new IllegalArgumentException(String.format("workId 值必须大于 0 并且小于 %d", MAX_WORKER_ID)); } this.workerId = workerId; this.dataCenterId = dataCenterId; } /** * 获取唯一ID * @return */ public static Long getSnowFlakeId() { return snowFlakeUtil.nextId(); } /** * 通过雪花算法生成下一个id,注意这里使用synchronized同步 * @return 唯一id */ public synchronized long nextId() { long currentTimeMillis = System.currentTimeMillis(); System.out.println(currentTimeMillis); // 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题 if (currentTimeMillis < lastTimeMillis) { throw new RuntimeException( String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis, lastTimeMillis)); } if (currentTimeMillis == lastTimeMillis) { // 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095 // 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095 // 那么就使用新的时间戳 sequence = (sequence + 1) & SEQUENCE_MASK; if (sequence == 0) { currentTimeMillis = getNextMillis(lastTimeMillis); } } else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095 sequence = 0; } // 记录最后一次使用的毫秒时间戳 lastTimeMillis = currentTimeMillis; // 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行 // <<:左移运算符, 1 << 2 即将二进制的 1 扩大 2^2 倍 // |:位或运算符, 是把某两个数中, 只要其中一个的某一位为1, 则结果的该位就为1 // 优先级:<< > | return // 时间戳部分 ((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT) // 数据中心部分 | (dataCenterId << DATA_CENTER_ID_SHIFT) // 机器表示部分 | (workerId << WORK_ID_SHIFT) // 序列号部分 | sequence; } /** * 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒 * @param lastTimeMillis 指定毫秒时间戳 * @return 时间戳 */ private long getNextMillis(long lastTimeMillis) { long currentTimeMillis = System.currentTimeMillis(); while (currentTimeMillis <= lastTimeMillis) { currentTimeMillis = System.currentTimeMillis(); } return currentTimeMillis; } /** * 获取随机字符串,length=13 * @return */ public static String getRandomStr() { return Long.toString(getSnowFlakeId(), Character.MAX_RADIX); } /** * 从ID中获取时间 * @param id 由此类生成的ID * @return */ public static Date getTimeBySnowFlakeId(long id) { return new Date(((TIME_BIT & id) >> 22) + INIT_EPOCH); } public static void main(String[] args) { SnowFlakeUtil snowFlakeUtil = new SnowFlakeUtil(); long id = snowFlakeUtil.nextId(); System.out.println(id); Date date = SnowFlakeUtil.getTimeBySnowFlakeId(id); System.out.println(date); long time = date.getTime(); System.out.println(time); System.out.println(getRandomStr()); } }
复制代码
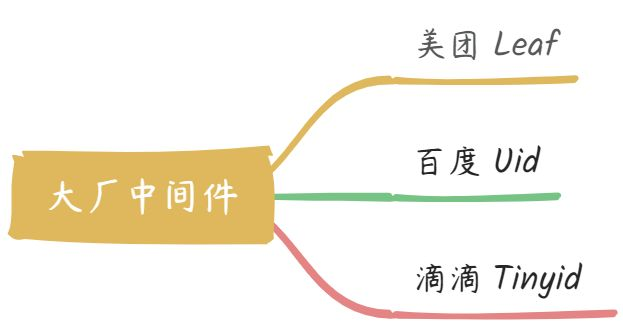
四、大厂中间件
1. 美团 Leaf
Leaf 的官方文档,简介和特性可访问了解,这里我将对 Leaf 的两种方案,Leaf segment 和 Leaf-snowflake 进行。
1.1. Leaf segment
基于数据库号段模式的 ID 生成方案,上面我们介绍到普通的号段模式有一些缺点:
数据库自身的单点故障和数据一致性问题。
不安全,比如可根据自增来判断订单量。
高并发场景可能会受限于数据库瓶颈。
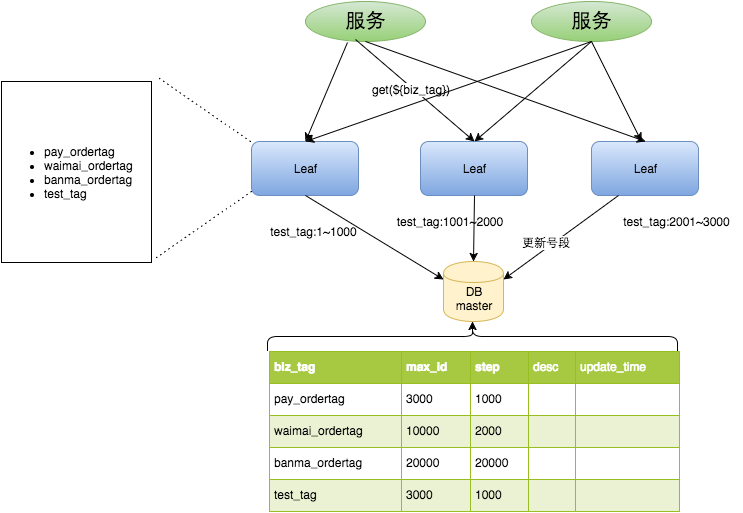
那么 Leaf 是如何做的呢?Leaf 采用了预分发的方式生成 ID,也就是在 DB 之上挂 n 个 Leaf Server,每个 Server 启动时,都会去 DB 拿固定长度的 ID List。
这样就做到了完全基于分布式的架构,同时因为 ID 是由内存分发,所以也可以做到很高效,处理流程图如下:
其中:
Leaf Server 1:从 DB 加载号段[1,1000]。
Leaf Server 2:从 DB 加载号段[1001,2000]。
Leaf Server 3:从 DB 加载号段[2001,3000]。
用户通过轮询的方式调用 Leaf Server 的各个服务,所以某一个 Client 获取到的 ID 序列可能是:1,1001,2001,2,1002,2002。当某个 Leaf Server 号段用完之后,下一次请求就会从 DB 中加载新的号段,这样保证了每次加载的号段是递增的。
为了解决在更新 DB 号段的时出现的耗时和阻塞服务的问题,Leaf 采用了异步更新的策略,同时通过双缓存的方式,保证无论何时 DB 出现问题,都能有一个 Buffer 的号段可以正常对外提供服务,只要 DB 在一个 Buffer 的下发的周期内恢复,就不会影响整个 Leaf 的可用性。
除此之外,Leaf 还通过动态调整步长,解决由于步长固定导致的缓存中的 ID 被过快消耗问题,以及步长设置过大导致的号段 ID 跨度过大问题,具体公式可去官方文档中了解。
对于数据一致性问题,Leaf 目前是通过中间件 Zebra 加 MHA 做的主从切换。
1.2. Leaf Snowflake
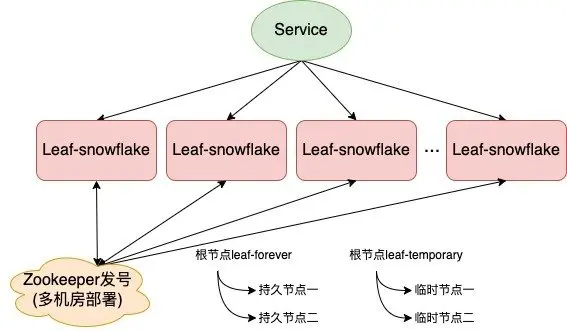
Leaf-snowflake 方案沿用 Snowflake 方案的 bit 位设计。
对于 workerID 的分配:当服务集群较小时,通过配置即可;服务集群较大时,基于 zookeeper 持久顺序节点的特性引入 zookeeper 组件配置 workerID。架构如下图所示:
2. 百度 UidGenerator
开源地址
UidGenerator 方案是基于 Snowflake 算法的 ID 生成器,其对雪花算法的 bit 位的分配做了微调。
结构说明(参数可在 Spring Bean 配置中进行配置):
UidGenerator 方案包含两种实现方式,DefaultUidGenerator 和 CachedUidGenerator ,性能要求高的情况下推荐 CachedUidGenerator。
3. 滴滴 Tinyid
Tinyid 官方文档
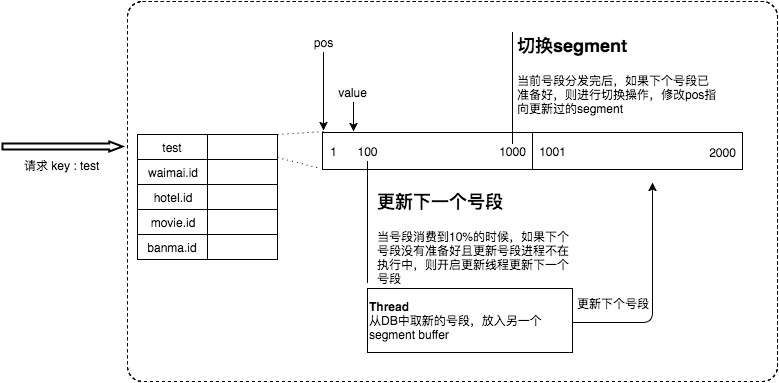
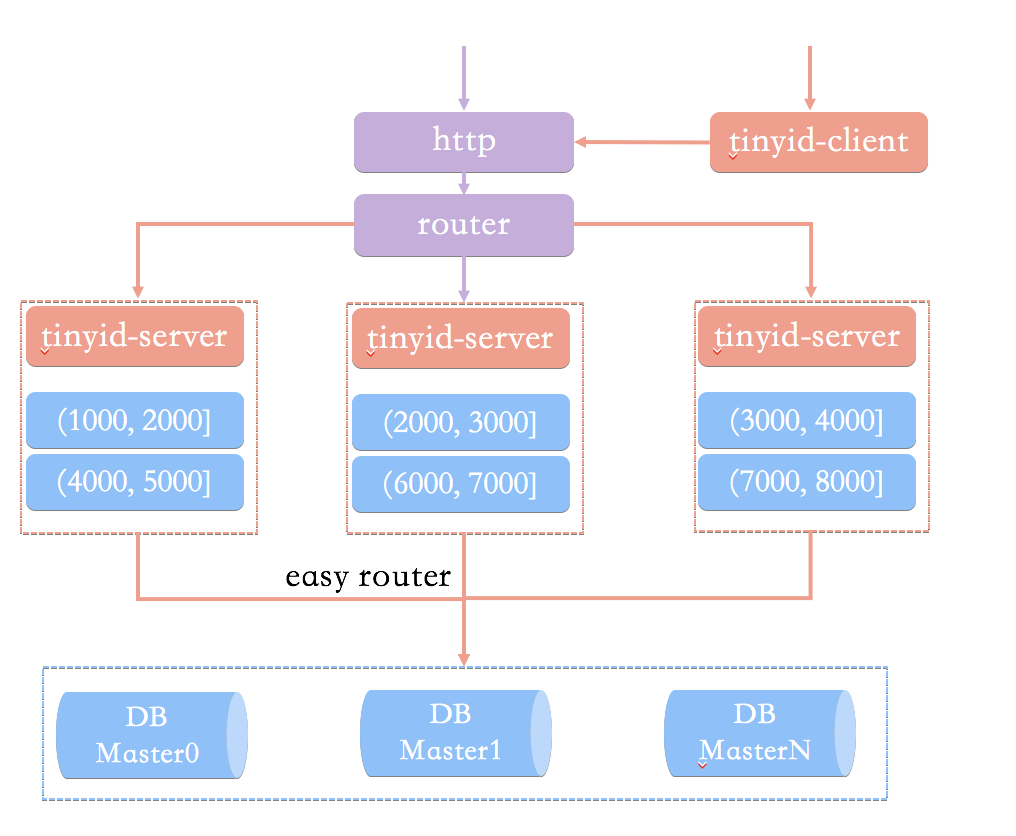
Tinyid 方案是在 Leaf-segment 的算法基础上升级而来,不仅支持了数据库多主节点模式,还提供了 tinyid-client 客户端的接入方式,使用起来更加方便。
Tinyid 也是采用了异步加双缓存策略,首先可用号段加载到内存中,并在内存中生成 ID,可用号段在首次获取 ID 时加载,号段用到一定程度的时候,就去异步加载下一个号段,保证内存中始终有可用号段,则可避免性能波动。
实现原理如下所示:
五、结语
本文对分布式 ID 以及其场景的生成方案做了介绍,还针对一下大厂的中间件进行简单分析,中间件的接入代码本文并没有做详细介绍,但是官方文档的链接都帖子了每个子标题下,其中都有详细介绍。
文中还针对每个生成方案的优缺点作出了说明,具体的使用可针对优缺点加上业务需求来进行选型。
文章转载自:fuxing.
原文链接:https://www.cnblogs.com/fuxing/p/18256122
体验地址:http://www.jnpfsoft.com/?from=infoq















评论