
飞书深诺电商广告素材搜索实战
背景介绍
飞书深诺集团是专注海外数字营销解决方案的专业服务提供商,为有全球化营销需求的企业提供标准 &定制相结合的全链路服务产品,满足游戏、APP、电商、品牌等典型出海场景需求。电商是我们的一个典型服务场景,在该场景里,我们的创意部门需要为客户制作素材,如:广告图、宣传视频、宣传文案等。而如何将公司沉淀的海量素材数据方便快捷的提供给创意人员,提升其工作效率和质量,是我们亟待需要解决的一个问题;比较直观的方式是通过图搜图, 视频搜视频,文本搜文本的方式,同时在搜索的过程中结合其他的一些相关条件(如:热度,效果值等)作为辅助搜索的条件,帮助创意人员选择合适的素材。
例如,在制作广告图的过程中,创意人员需要寻找与目标产品最相似的图片,以便提高广告效果,我们可以将目标产品图片转化为特征向量,并在现有的海量素材图片(也转化成特征向量保存)中进行匹配,寻找最接近的图片,作为搜索结果返回;而由于创意工作中涉及到的图片、视频、文本等属于非结构化数据,传统检索技术显得有些力不从心。同时,作为创意辅助类工具,对于检索结果的相似性上,有一定的模糊空间。而向量化搜索工具就可以对海量、非结构化数据,进行精确或近似的检索,较好的解决该场景的问题。
技术选型
非结构化数据的向量化
在素材领域,其数据基本都是非结构化的,所以首先需要考虑的是如何将这些非结构化的数据转换为检索系统可以识别的信息。传统的检索技术一般是在结构化的数据库的字段上做检索,比如:字符串、整数、浮点数等。对于非结构化数据来说,首先要提取其特征向量,简单的说就是对其转化成连续值。通过一定的距离计算,才能检索到相近的数据。由于图片、视频、文本(这里特指带有丰富语义的长文本)包含的信息较多,其转化的结果一般是个高维的向量。那么如何获得这些向量呢?
对于图片来说,早期人们直接将图片的每个像素点值(0~255)拉平,成一长串向量,作为其表征,但是这样得到的向量会有很多冗余,如果图片分辨率很大,得到的向量又会非常长,不方便计算;后来人们又使用传统的图形学、光学处理算法,处理图片和视频的像素点,从而获取压缩过的特征向量。
视频则通过切帧操作,把每一帧看成一张图像,通过图像的方式来获取向量,再将其按照一定的加权计算规则,得到一个类似图片的向量(通常比图片要长)。
文字则采用词典 one-hot 编码等方式,简单说来就是,将文本进行分词操作,通过一个固定的词典来判断,文本是否包含某个词,如果包含,该词的位置上就置为 1,否则置为 0。
进入深度学习时代之后,基于模型的 embedding 向量获取技术迅速成为主流。向量 embedding 是指通过神经网络模型,把图片/文本/视频作为训练集输入,执行一项训练任务(一般是分类任务)。训练完成之后,将神经网络中的某一层的输出数值,作为该图片/视频/文本 的表征向量。Embedding 方式具有通用,且表征信息丰富等优势,通过神经网络大量参数,捕捉素材中的细节信息。
(注:图中仅仅是一种示意, 不要理解成一个区块就对应一段向量)
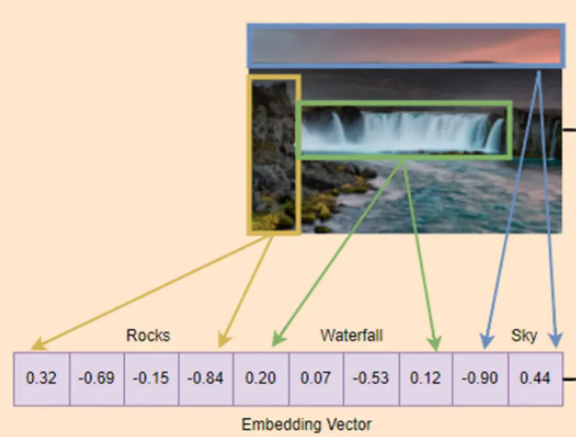
(特征向量提取的参考资料 见文末)
距离度量
图文视频等素材转化成向量之后,我们就需要有度量它们接近 or 不接近的办法,才能实现检索的目的。那么对于向量的距离度量,在数学上有两种常见的方式:余弦距离和欧拉距离
余弦相似度(向量表示),余弦距离 = 1 - similarity

欧式距离(向量表示)
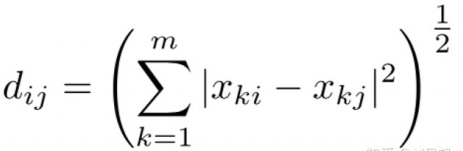
在实践中,我们往往更关心素材的内容,比如说一张图片,常常忽略它的亮度、分辨率、旋转形变等,而关心其描绘了什么。因此,选用余弦距离是比较好的,余弦距离的结果(0~1 的浮点数)表示两个向量的夹角,而不考虑长度,夹角越小,向量方向越接近,素材就越相似。同时,在数学上也可以证明余弦距离和欧拉距离在归一化的情况下是等价的,余弦距离在计算上更加的高效。
通过对素材转化成特征向量,再通过检索技术,就能实现素材(图像、视频、文字、语音)的近似或精确匹配的需求。
向量检索工具的选型
向量检索工具在市面上并不少见,我们从向量索引的支持程度、开发/部署的成本,以及易用性等多个方面,对比了传统检索工具(ElasticSearch)、轻量级的向量检索库(FAISS),以及 Milvus 向量检索平台的优劣势(如下所示)。
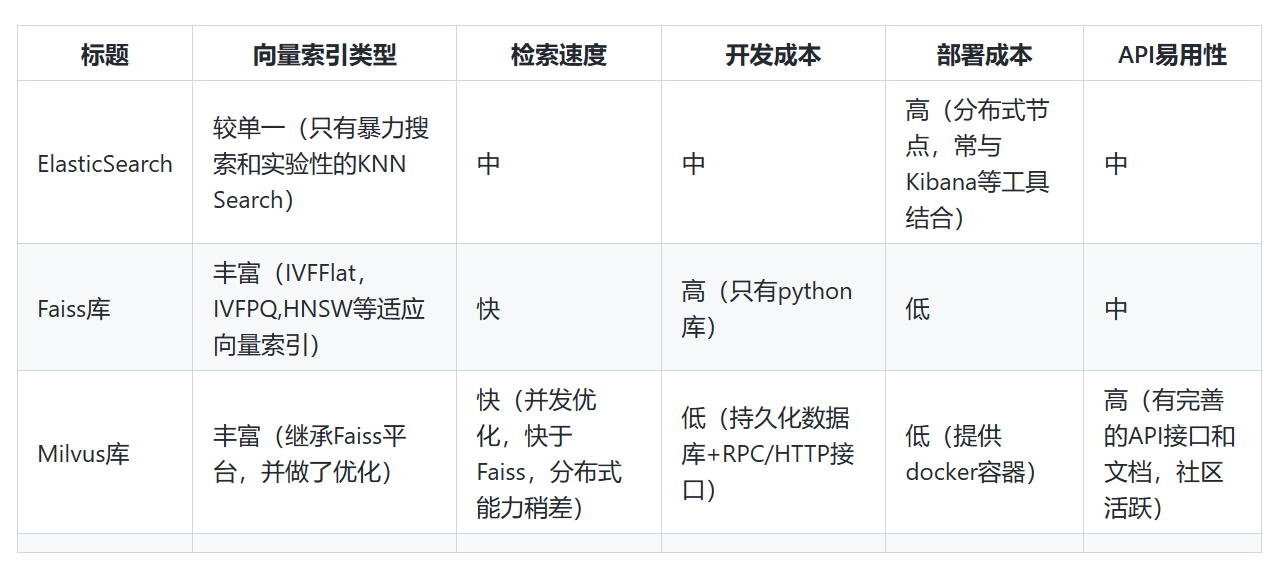
考虑到主要是针对图片和视频的特征向量检索需求,同时业务需要实时接口,还需要承受一定程度的并发负载。因此,综合上述要求,我们认为 Milvus 是比较合适的向量检索工具。它对 FAISS, ANN 等工具进行了封装, 建立自己的存储文件结构、持久化数据库,同时提供了方便的接口, 可以算的上开箱即用了。
根据前文所述,非结构化创意素材的检索,往往需要的是近似匹配,而非精确匹配。在实际应用中,近似匹配已经足够满足大多数用户的需求,并且具有更高的效率。这也是 Milvus 的一项优势,它可以通过参数设置,对向量检索的准确性、近似程度、资源占用、速度 做不同程度的 trade-off,比较适合在实际工程中使用。
我们在返回相似向量的同时, 还需要图片/视频的一些对应信息, 我们通过 kv 的形式放在 redis 缓存里,加快获取的速度。在 web 接口封装方面,考虑到团队里 python 程序员占主流,我们选用了 nginx + flask + gunicorn + supervisor 的 web 经典套餐。
使用到的各工具和框架:
Milvus (向量相似检索)
Redis (业务缓存)
Nginx(负载均衡)
Flask+Gunicorn (Web 框架+并发服务)
Supervisor (服务的进程启动与异常自动重启)
Docker (容器隔离部署)
(向量检索的参考资料 见文末)
应用方案介绍
广告内的图片和视频往往是相对重要的部分,这些素材能够吸引用户的眼球,起到促进点击、转化的作用。因此选择与爆款或优质素材相类似的素材,并加以改造利用,是电商广告投放中常见的操作。同时,也有很多相近的素材,有着将其归类,去重的需要。因此,我们的素材检索系统主要是以图片和视频作为主要的功能实现。以下大致介绍了如何通过向量检索系统,寻找相似的素材的过程。
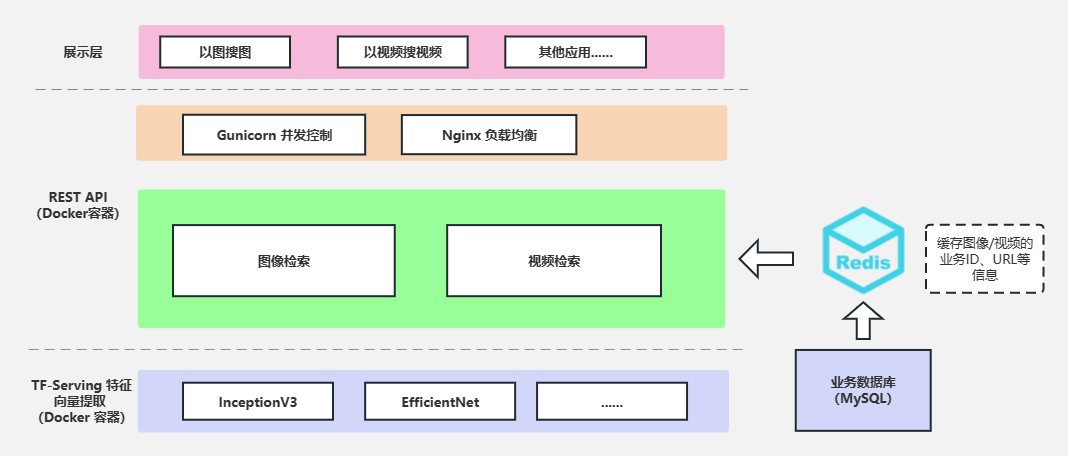
系统架构示意
素材搜索系统是一个多层的架构,其中涉及到提供特征向量提取的模型层、由 Milvus 向量引擎组成的检索层,以及做参数包装业务层。整体架构如下所示:
特征向量获取
在我们的项目中,图片和视频使用谷歌的 InceptionV3 图像预训练模型来提取特征向量;视频通过提取关键帧之后,再将每一帧图片进行向量提取,之后综合加权得到一个视频的 embedding 向量。预训练的图像模型已经是开源的,其工程实现是由 TF-Serving(Google 的深度学习推理框架)来完成的。从外部看起来,就是一个 docker 封装的接口。
向量的存储与检索
在我们的关系型数据库中,每个图片和视频都有一个唯一的业务 ID。这些素材转化成向量之后,业务 ID 与 向量也是一一对应的。我们将转化好的向量,以及其业务 ID、素材类型(视频 or 图片)、素材 URL 等信息 也一并保存至数据库中。然后,使用 Milvus 提供的 API 接口,将向量存入;Milvus 支持对存入的向量设置一个整型的 ID,我们就用业务 ID 来代替。在检索到相似的素材时,我们通过返回的业务 ID 来获得原始的图片/ 视频。
选择合适的索引
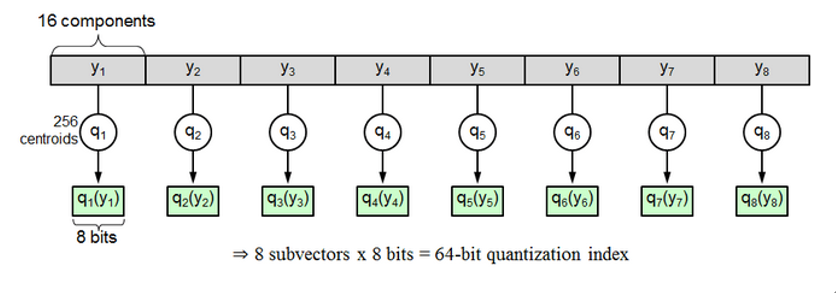
图片/视频 向量在检索出来之后, 上层调用还要做一些业务操作, 留给我们的接口的时间就不能太多, 要求做到 1s 内返回。由于对速度的要求比较高, 同时服务部署的机器内存又有一定的限制, 我们选用了 IVF_PQ 作为向量索引。这是一种有损压缩的向量索引, Milvus 内置了这种类型的索引。它将所有向量分解成 m 段, 每一小段分别进行聚类,每小段由所属的聚类中心来表示,称为索引值。
如:一个 D=128 维的原始向量,它被切分成了 M=8 个 d=16 维的短向量,同时每个 16 维短向量都对应一个量化的索引值,索引值即该短向量距离最近的聚类中心的编号,每一个原始向量就可以压缩成 8 个索引值构成的压缩向量,即每个向量都用这 8 个索引值来表示,相对于原始值有一定的误差。
在实际使用的时候,预先计算好的各个聚类中心间的距离(codebook 码表),通过查找表得出两个向量索引值之间的距离,来近似替代两个向量的真实距离,加快了计算速度;在使用中可以通过参数 m 的设置, 使得向量压缩成很小的比例, 也大量减少了内存占用(约为向量原始空间大小的 5%~10%)。
根据 milvus 官方提供的公式:

我们计算得出合适的索引参数是 nlist=1024, m=8
使用分区提高速度
分区是 Milvus 向量库提供的一种非常实用的功能,其通过一些属性字段,将整个向量库分区分片存放,为了达到每次检索减少搜索量,提高效率的目的。目前素材中,图片接近 4kw, 视频 1kw, 为了提高检索速度, 分区变得十分必要。我们通过一些业务属性, 根据属性值做笛卡尔积操作来建立分区:
例如,我们向量对应的 Item 有两个属性:
属性 A,取值 1, 2, 3, 4
属性 B,取值 1, 2, 3
那么建立分区 A1_B1, A1_B2, A1_B3, A2_B1, A2_B2, A2_B3, ...... A4_B3, 一共 12 个。通过分区操作,我们将每个分区的向量规模控制在 500w 以下, 进一步提高了检索速度。
需要注意的是, 用来建立分区的属性应该是不会变动的基本属性, 因为如果发生变动, 重新建立分区, 导入数据, 建立索引是非常漫长的过程, 所以分区确定下来, 轻易不要改变。另外分区及属性值不能太多, 否则各个属性值相乘(笛卡儿积)会让数量变得非常庞大, 使程序变得过于复杂. 更多的属性检索或筛选, 我们在 milvus 向量搜索的结果上另外封装一层业务接口来实现。
工程化包装
向量检索应用是以 REST API 对外表现的。主要开发框架及其作用如下:
Flask: REST API 主要代码结构
Redis: 素材业务 ID 与 其他信息的 key-value 缓存
Gunicorn: 并发控制
Supervisor: 进程监控保活
Docker: 整体应用封装成镜像
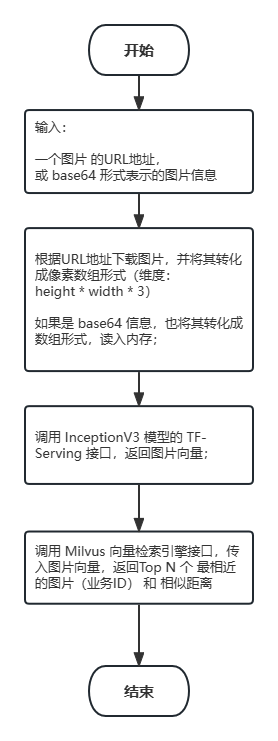
以下以图片类接口为例,简要描述了接口的输入、输出 和 执行步骤:
系统效果
界面展现
向量检索服务以 REST 接口的形式对外提供,前端团队调用接口,将结果展示在界面上。UI 示意如图(部分业务信息模糊处理),类似谷歌的以图搜图,百度的以影搜影等…
呈现效果图 1(上传素材、输入参数)

呈现效果图 2(展示搜索结果)

性能指标
目前我们的图片总量大约在 3kw+,向量维数是 2048 维;视频总量大约在 1kw,向量维数也是 2048 维。
经过性能测试指标可以看出,图片检索耗时平均在 0.5-1.5s 左右;视频检索耗时在 3-3.5s 左右,需要注意的是,这里均包含了图片和视频本身转换为 embedding 的时间,实际图片向量检索的时间平均在 200ms,视频向量检索的平均时间在 100ms 左右;

总结与改进
随着电商广告对于素材的要求趋于多样化,各式各样的非结构化素材检索的需求逐渐浮出水面,其对应的技术方案也进入人们视野。通过 深度学习模型 和 Milvus 向量检索引擎,我们构造了一个实用的素材检索系统,为图片和视频的相似检索、唯一匹配等需求提供了支持。 Milvus 集成各种常见向量索引, 能满足工程中大部分的需求,存储操作和检索速度都达到了工业级的水准,并且提供服务化的接口, 基本上做到了开箱即用,是个很方便上手的向量检索引擎。
通过素材检索系统的实施,我们实现了对相近素材的搜索,为业务人员提供了创意帮助,以及相同素材归类、去重的功能。同时,在实践过程中,我们也发现了一些有待改进的点。比如,向量索引是有损的方式,为了追求检索的高速度,是以牺牲计算精度为代价的。其召回相似素材的准确程度是低于 全量暴力搜索+排序 的形式的。直观的体现就是会有 某些素材并不太相似,但是被召回了,或者 应该被归类的素材没有被归类。这些问题涉及到 对向量库和检索时的参数设置进一步的调优,同时也需要对比、选择更合适的深度学习模型来提取素材特征向量,达到准确度和速度更好的 trade-off 平衡。这些将在后续的工作中逐渐调试和完善。
参考资料
图片/视频/文本 如何获取特征向量
相关资料:向量检索介绍
乘积量化原理 (论文)
https://inria.hal.science/file/index/docid/514462/filename/paper_hal.pdf
作者介绍

张聪 (高级算法工程师)
毕业于芬兰坦佩雷大学, 目前就职于飞书深诺数据研究院,过去几年工作主要是机器学习算法的研究和应用开发,业务领域包括电商、广告、信息流推荐等。
版权声明: 本文为 InfoQ 作者【飞书深诺】的原创文章。
原文链接:【http://xie.infoq.cn/article/98afacaf08f3baac660f410ae】。文章转载请联系作者。

还未添加个人签名 2020-05-21 加入
还未添加个人简介









评论