前言
某次金融系统迁移项目中,原计划 8 小时完成的用户数据同步迟迟未能完成。
24 小时后监控警报显示:由于全表扫描SELECT * FROM users导致源库 CPU 几乎熔毁,业务系统被迫停机 8 小时。
这让我深刻领悟到——10 亿条数据不能用蛮力搬运,得用巧劲儿递接!
今天这篇文章,跟大家一起聊聊 10 亿条数据,如何做迁移,希望对你会有所帮助。
一、分而治之
若把数据迁移比作吃蛋糕,没人能一口吞下整个十层蛋糕;
必须切成小块细嚼慢咽。
避坑案例:线程池滥用引发的血案
某团队用 100 个线程并发插入新库,结果目标库死锁频发。
最后发现是主键冲突导致——批处理必须兼顾顺序和扰动。
分页迁移模板代码:
long maxId = 0; int batchSize = 1000; while (true) { List<User> users = jdbcTemplate.query( "SELECT * FROM users WHERE id > ? ORDER BY id LIMIT ?", new BeanPropertyRowMapper<>(User.class), maxId, batchSize ); if (users.isEmpty()) { break; } // 批量插入新库(注意关闭自动提交) jdbcTemplate.batchUpdate( "INSERT INTO new_users VALUES (?,?,?)", users.stream().map(u -> new Object[]{u.id, u.name, u.email}).collect(Collectors.toList()) ); maxId = users.get(users.size()-1).getId(); }
复制代码
避坑指南:
二、双写
经典方案是停机迁移,但对 10 亿数据来说停机成本难以承受,双写方案才是王道。
双写的三种段位:
青铜级:先停写旧库→导数据→开新库 →风险:停机时间不可控
黄金级:同步双写+全量迁移→差异对比→切流 →优点:数据零丢失
王者级:逆向同步兜底(新库→旧库回写),应对切流后异常场景
当然双写分为:
同步双写实时性更好,但性能较差。
异步双写实时性差,但性能更好。
我们这里考虑使用异步双写。
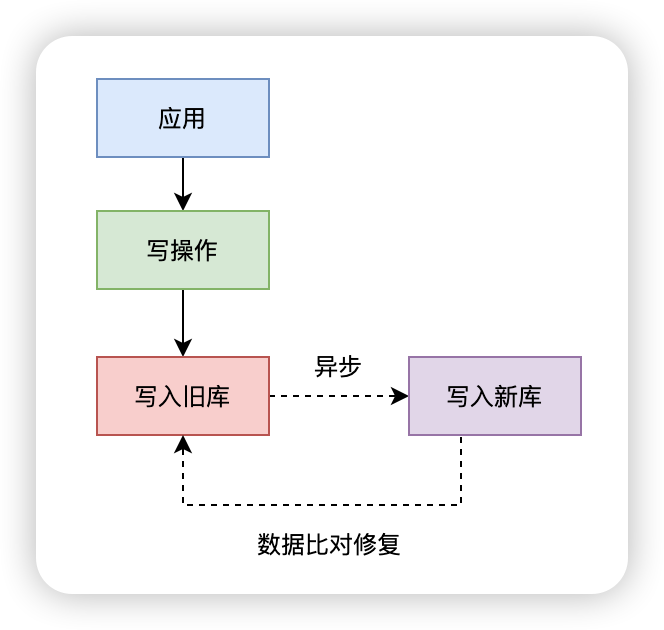
异步双写架构如图所示:
代码实现核心逻辑:
1、开启双写开关
@Transactional public void createUser(User user) { // 旧库主写 oldUserRepo.save(user); // 异步写新库(允许延迟) executor.submit(() -> { try { newUserRepo.save(user); } catch (Exception e) { log.error("新库写入失败:{}", user.getId()); retryQueue.add(user); } }); }
复制代码
2、差异定时校验
// 每天凌晨校验差异数据 @Scheduled(cron = "0 0 3 * * ?") public void checkDiff() { long maxOldId = oldUserRepo.findMaxId(); long maxNewId = newUserRepo.findMaxId(); if (maxOldId != maxNewId) { log.warn("数据主键最大不一致,旧库{} vs 新库{}", maxOldId, maxNewId); repairService.fixData(); } }
复制代码
三、用好工具
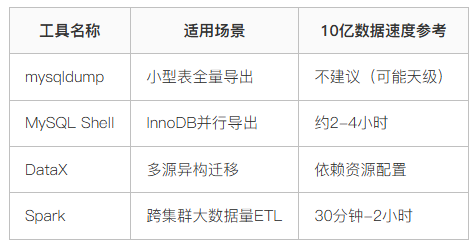
不同场景需匹配不同的工具链,好比搬家时家具用货车,细软用包裹。
工具选型对照表
Spark 迁移核心代码片段:
val jdbcDF = spark.read .format("jdbc") .option("url", "jdbc:mysql://source:3306/db") .option("dbtable", "users") .option("partitionColumn", "id") .option("numPartitions", 100) // 按主键切分100个区 .load()
jdbcDF.write .format("jdbc") .option("url", "jdbc:mysql://target:3306/db") .option("dbtable", "new_users") .mode(SaveMode.Append) .save()
复制代码
避坑经验:
四、影子测试
迁移后的数据一致性验证,好比宇航员出舱前的模拟训练。
影子库验证流程:
生产流量同时写入新 &旧双库(影子库)
对比新旧库数据一致性(抽样与全量结合)
验证新库查询性能指标(TP99/TP95 延迟)
自动化对比脚本示例:
def check_row_count(old_conn, new_conn): old_cnt = old_conn.execute("SELECT COUNT(*) FROM users").scalar() new_cnt = new_conn.execute("SELECT COUNT(*) FROM new_users").scalar() assert old_cnt == new_cnt, f"行数不一致: old={old_cnt}, new={new_cnt}"
def check_data_sample(old_conn, new_conn): sample_ids = old_conn.execute("SELECT id FROM users TABLESAMPLE BERNOULLI(0.1)").fetchall() for id in sample_ids: old_row = old_conn.execute(f"SELECT * FROM users WHERE id = {id}").fetchone() new_row = new_conn.execute(f"SELECT * FROM new_users WHERE id = {id}").fetchone() assert old_row == new_row, f"数据不一致, id={id}"
复制代码
五、回滚
即便做好万全准备,也要设想失败场景的回滚方案——迁移如跳伞,备份伞必须备好。
回滚预案关键点:
备份快照:迁移前全量快照(物理备份+ Binlog 点位)
流量回切:准备路由配置秒级切换旧库
数据标记:新库数据打标,便于清理脏数据
快速回滚脚本:
# 恢复旧库数据 mysql -h旧库 < backup.sql
# 应用Binlog增量 mysqlbinlog --start-position=154 ./binlog.000001 | mysql -h旧库
# 切换DNS解析 aws route53 change-resource-record-sets --cli-input-json file://switch_to_old.json
复制代码
总结
处理 10 亿数据的核心心法:
分而治之:拆解问题比解决问题更重要
逐步递进:通过灰度验证逐步放大流量
守牢底线:回滚方案必须真实演练过
记住——没有百分百成功的迁移,只有百分百准备的 Plan B!
搬运数据如同高空走钢丝,你的安全保障(备份、监控、熔断)就是那根救命绳。🪂
文章转载自:苏三说技术
原文链接:https://www.cnblogs.com/12lisu/p/18730055
体验地址:http://www.jnpfsoft.com/?from=001YH














评论