编者按:在之前的系列文章中,我们介绍了大模型的原理和微调落地的理论方法。本期文章,我们将以实际场景为例,详细介绍微调的实践流程和相关代码。
作者详细介绍了如何使用 QLoRA 技术针对 Falcon-7B 大语言模型进行微调,使之在消费级 GPU 上进行微调而不会出现 out of memory(内存不足错误),从而创造一个能够准确、连贯的回答心理健康问题的 AI 助手。
以下是译文,Enjoy!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
作者 | Arun Brahma
编译 | 岳扬
使用领域自适应技术(domain adaptation techniques)对预训练的 LLM 进行微调,有助于在特定领域的任务上实现更好的性能。但是,进行全量微调(full fine-tuning)的成本很高,还有可能会导致 CUDA 出现内存不足的错误(CUDA out-of-memory errors)。因此,到目前为止,在消费级 GPU 上对具有数十亿参数的预训练 LLM 进行微调并不容易。
01 行文目的
我们应当像重视身体健康一样将保持心理健康视为首要任务。根据目前的社会舆论情况,与抑郁症和其他精神障碍有关的讨论都已被污名化,以至于人们回避与焦虑和抑郁有关的讨论,甚至排斥看心理医生。
聊天机器人(Chatbots)为需要心理咨询的用户提供了一个随时可用和易于访问的平台。聊天机器人(Chatbots)可以随时随地访问,为需要帮助的人提供即时反馈。聊天机器人的回复富有同情心和没有偏见,能够为用户提供情感支持。虽然它们不能完全取代人与人之间的互动,但在紧急情况下,它们可以成为一名有益的“心理健康小助手”。虽然聊天机器人用处很大,但能提供有关心理健康症状、应对策略和可用治疗方案的各种可靠信息和相关心理教育的匿名聊天应用程序并不多。
因此,本文的主要目标是,使用精心整理和筛选的对话数据构建心理健康领域聊天机器人,并使用 QLoRA 技术对 Falcon-7B LLM 进行微调。Falcon-7B LLM 的开源许可证为 Apache 2.0,因此其可用于商业目的。
02 LoRA 和 QLoRA 方法简介
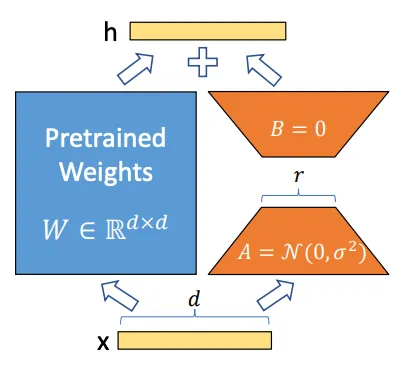
2.1 什么是 LoRA?
先来介绍一下 LoRA[1](由 Edward Hu 等人所著的《Low-Rank Adaptation of Large Language Models》)。LoRA 技术是一种 LLM 的轻量化微调方法。通过使用 PEFT(Parameter-efficient Fine-tuning,轻量化微调) ,我们只需要对少量的参数进行训练,就可以微调 LLM 来获取较高的模型性能。PEFT 的优点是,我们可以使用较少的数据对任何大型模型进行微调。
LoRA 是一种用于大权重矩阵的隐式低秩转换技术(implicit low-rank transformation technique)。LoRA 并不会直接分解矩阵,而是通过反向传播算法(backpropagation)学习矩阵的分解方法。
虽然预训练模型的权重在预训练任务上具有满秩,但当预训练模型适配到新的垂直领域任务时,其具有低秩维度(low intrinsic dimension)。这意味着数据可以通过一个低维空间来有效地进行近似,同时还能保留其大部分的基本信息或结构。(译者注:这种方案可以减小模型的复杂度,提高模型的泛化能力和效率,达到四两拨千斤的效果。)
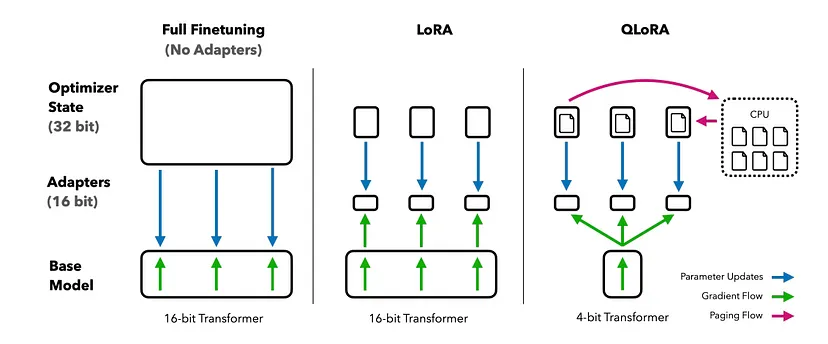
2.2 什么是 QLoRA?
接下来本文将介绍 QLoRA[2](由 Tim Dettmers 等人在《Low-Rank Adaptation of Quantized LLMs》中提出)。QLoRA 通过量化感知训练(quantization-aware training)、混合精度训练(mixed precision training)和双重量化(double quantization)来降低平均内存占用。QLoRA 使用一种存储数据类型(4-bit Normal Float)和一种计算数据类型(16-bit Brain Float)。
在 QLoRA 中,预训练模型的权重矩阵以 NF4 格式存储,而可训练的 LoRA 权重矩阵以 BFloat16 格式存储。 在前向和后向传播的过程中,预训练权重被反量化(dequantized)为 16-bit Brain Float 格式,但仅会计算 LoRA 参数的权重梯度。QLoRA 通过冻结的 4 位量化预训练模型,将梯度反向传播到低秩适配器(low-rank adapters)中。此外,QLoRA 还利用了 Nvidia 的统一内存技术,以确保在权重更新期间有足够的空闲内存,以防止内存不足错误。(译者注:统一内存技术创建了一个在 CPU 和 GPU 之间共享的托管内存池,弥合了 CPU-GPU 鸿沟。CPU 和 GPU 都可以使用单个指针访问托管内存。关键是系统会自动在主机和设备之间迁移统一内存中分配的数据。)
QLoRA 还引入了双重量化(double quantization)技术,通过将额外的量化常数进行量化来减少内存开销。在对预训练模型进行 4 位量化的情况下,模型权重和激活值(model weights and activations)会从 32 位浮点数压缩为 4-bit NF 格式。
2.3 4-bit NormalFloat 量化步骤
4-bit NormalFloat 量化是一个数学上比较直观的过程。首先对模型的权重归一化,使其均值为零,方差为一个单位。
然后将归一化后的权重量化为 4 位。这个步骤涉及到将原本的高精度权重映射到一组较小的低精度值。在 NF4 这种情况下,量化级别被选择为在归一化权重范围内均匀分布的值。
在前向和后向传播过程中,量化后的权重(the quantized weights)被反量化回全精度(full precision)。具体做法是将 4 位量化值(the 4-bit quantized values)映射回其原始数值范围。反量化后的用于计算的权重仍然会以 4 位的量化形式存储在内存中。
03 本文的微调实践简介
在这篇博客中,我将介绍使用 bitsandbytes 和 PEFT(来自 HuggingFace)对 Falcon-7B 大参数模型进行微调的 QLoRA 技术。我将使用自己从各种博客、医疗保健网站(如 WebMD 和 HealthLine)、一些有关心理健康的常见问题解答和其他可信赖的医疗保健信息来源中精心筛选出的自定义心理健康对话数据集[3]。该数据集包含 172 段患者和医疗服务提供者之间的高质量对话。所有姓名和 PII 数据已被匿名化,并进行数据预处理去除了不必要的字符。
04 微调实践具体操作及步骤
4.1 安装 QLoRA 库
!pip install trl transformers accelerate git+https://github.com/huggingface/peft.git -Uqqq!pip install datasets bitsandbytes einops wandb -Uqqq
复制代码
我安装了 bitsandbytes(用于 LLM 的量化)、PEFT(用于 LoRA 参数的微调)、datasets(用于加载 HF 数据集)、wandb(用于监测微调指标)和 trl(用于使用有监督的微调步骤训练 Transformer LLMs)。
此外,我还从 HuggingFace 数据集中加载了一款心理健康对话数据集(heliosbrahma/mental_health_chatbot_dataset[3])。该数据集只包含一个名为“text”的列,其中包含患者和医生之间的对话。
4.2 Falcon-7B 模型的量化
首先,加载一个分片模型(sharded model),而不是一个单一的大模型。使用分片模型的优点是,当与 accelerate 库结合使用时,可以将特定部分加速移动到内存不同的部分(有时是 CPU 或 GPU),从而有助于在较小的内存中对大型模型进行微调。此处我使用的是 ybelkada/falcon-7b-sharded-bf16 分片模型[4]。
model_name = "ybelkada/falcon-7b-sharded-bf16" # sharded falcon-7b model
bnb_config = BitsAndBytesConfig( load_in_4bit=True, # load model in 4-bit precision bnb_4bit_quant_type="nf4", # pre-trained model should be quantized in 4-bit NF format bnb_4bit_use_double_quant=True, # Using double quantization as mentioned in QLoRA paper bnb_4bit_compute_dtype=torch.bfloat16, # During computation, pre-trained model should be loaded in BF16 format)
model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, # Use bitsandbytes config device_map="auto", # Specifying device_map="auto" so that HF Accelerate will determine which GPU to put each layer of the model on trust_remote_code=True, # Set trust_remote_code=True to use falcon-7b model with custom code)
复制代码
在这里,将 load_in_4bit 配置为 True 启用了以 4 位精度加载模型,而 bnb_4bit_use_double_quant 设置为 True 则启用了 QLoRA 提出的双重量化。bnb_4bit_compute_dtype 设置为“torch.bfloat16”,启用在计算过程中以 16 位格式对基础模型进行反量化。
在加载预训练的权重时,我添加了 device_map="auto"这项配置,这样 Hugging Face Accelerate 将自动决定将模型的每个层放在哪个 GPU 上。另外,设置 trust_remote_code=True 允许加载在 Hub 上定义的自定义模型。
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_token # Setting pad_token same as eos_token
复制代码
在这里,我需要从预训练模型中加载分词器,以便对数据集进行分词。我将 pad_token 设置为 eos_token,这样就能够启用填充(padding)功能,从而可以一次发送多批数据进行训练。(译者注:在深度学习中,padding 是指在序列数据的末尾添加特殊的标记(通常是 0),以使所有序列具有相同的长度。这是因为在训练深度学习模型时,通常需要将数据分批次进行处理,而不同批次的数据长度可能不同。为了使不同批次的数据能够同时进行处理,需要将它们的长度统一。因此,通过在较短的序列末尾添加 0 来进行填充,以使它们与较长的序列具有相同的长度。这样,所有的数据都可以被组织成一个矩阵,并且可以在 GPU 上高效地进行并行计算。)
4.3 PEFT 步骤的配置和获取进行 PEFT 后的模型
model = prepare_model_for_kbit_training(model)
lora_alpha = 32 # scaling factor for the weight matriceslora_dropout = 0.05 # dropout probability of the LoRA layerslora_rank = 32 # dimension of the low-rank matrices
peft_config = LoraConfig( lora_alpha=lora_alpha, lora_dropout=lora_dropout, r=lora_rank, bias="none", # setting to 'none' for only training weight params instead of biases task_type="CAUSAL_LM", target_modules=[ # Setting names of modules in falcon-7b model that we want to apply LoRA to "query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h", ])
peft_model = get_peft_model(model, peft_config)
复制代码
由于目标任务是文本生成任务,因此将 task_type 设置为 CAUSAL_LM。lora_alpha 是权重矩阵的缩放因子,能够帮助 PEFT 模型中的权重矩阵更加重视 LoRA 算法计算出的激活值。在这里,我将 LoRA rank 值设置为 32。与 rank 值赋值为 64 或 16 相比,其效果更好。为了考虑 Transformer 块中的所有线性层,获得最佳性能,除了混合查询、键、值向量对(mixed query key-value pair)之外,我还添加了“dense”、“dense_h_to_4h”和“dense_4h_to_h”层作为目标模块。lora_dropout 是 LoRA 层的丢弃率。在这里,我将 bias 设置为 None,但也可以将其设置为 lora_only,以便仅训练 LoRA 网络的偏置参数。
4.4 本案例中 TrainingArguments 和 Trainer 的相关配置
output_dir = "./falcon-7b-sharded-bf16-finetuned-mental-health-conversational"per_device_train_batch_size = 16 # reduce batch size by 2x if out-of-memory errorgradient_accumulation_steps = 4 # increase gradient accumulation steps by 2x if batch size is reducedoptim = "paged_adamw_32bit" # activates the paging for better memory managementsave_strategy="steps" # checkpoint save strategy to adopt during trainingsave_steps = 10 # number of updates steps before two checkpoint saveslogging_steps = 10 # number of update steps between two logs if logging_strategy="steps"learning_rate = 2e-4 # learning rate for AdamW optimizermax_grad_norm = 0.3 # maximum gradient norm (for gradient clipping)max_steps = 320 # training will happen for 320 stepswarmup_ratio = 0.03 # number of steps used for a linear warmup from 0 to learning_ratelr_scheduler_type = "cosine" # learning rate scheduler
training_arguments = TrainingArguments( output_dir=output_dir, per_device_train_batch_size=per_device_train_batch_size, gradient_accumulation_steps=gradient_accumulation_steps, optim=optim, save_steps=save_steps, logging_steps=logging_steps, learning_rate=learning_rate, bf16=True, max_grad_norm=max_grad_norm, max_steps=max_steps, warmup_ratio=warmup_ratio, group_by_length=True, lr_scheduler_type=lr_scheduler_type, push_to_hub=True,)
trainer = SFTTrainer( model=peft_model, train_dataset=data['train'], peft_config=peft_config, dataset_text_field="text", max_seq_length=1024, tokenizer=tokenizer, args=training_arguments,)
复制代码
在这里,本案例使用 TRL 库中的 SFTTrainer 来执行指令微调(instruct fine-tuning)部分。我将最大序列长度(the max sequence length)设置为 1024,增加这个长度可能会降低训练速度,可以根据您的需求将其设置为 512 或 256。
此外,我还指定了不同的训练参数,例如 batch size(批量大小)、gradient accumulation steps(梯度累积步数)、linear scheduler type(线性调度器类型)(您可以选择“constant”类型)、maximum number of steps(最大训练步数)(如若配置较高,可以将其增加到 500)以及训练结果的输出目录。
需要注意的是,如果出现 CUDA 内存不足的错误,可以尝试将 batch size(批量大小)减少 2 倍,并将 gradient accumulation steps(梯度累积步数)增加 2 倍。
peft_model.config.use_cache = Falsetrainer.train()
复制代码
在开始训练之前,请确保将 use_cache 设置为 False。最后,使用进行 PEFT 后得到的模型开始执行指令微调(instruct-tuning)。在我的配置环境下,在 Nvidia A100 GPU 上进行 320 次训练只需要不到一小时的时间。根据 steps 数和所使用的 GPU 的情况,训练可能需要更长的时间。您可以在此处[5]找到训练过程中损失值的日志。训练完成后,该模型被推送到 HuggingFace Hub:heliosbrahma/falcon-7b-sharded-bf16-finetuned-mental-health-conversational[6]。
4.5 PEFT model 的推理流程
def generate_answer(query): system_prompt = """Answer the following question truthfully. If you don't know the answer, respond 'Sorry, I don't know the answer to this question.'. If the question is too complex, respond 'Kindly, consult a psychiatrist for further queries.'."""
user_prompt = f"""<HUMAN>: {query} <ASSISTANT>: """
final_prompt = system_prompt + "\n" + user_prompt
device = "cuda:0" dashline = "-".join("" for i in range(50))
encoding = tokenizer(final_prompt, return_tensors="pt").to(device) outputs = model.generate(input_ids=encoding.input_ids, generation_config=GenerationConfig(max_new_tokens=256, pad_token_id = tokenizer.eos_token_id, \ eos_token_id = tokenizer.eos_token_id, attention_mask = encoding.attention_mask, \ temperature=0.4, top_p=0.6, repetition_penalty=1.3, num_return_sequences=1,)) text_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(dashline) print(f'ORIGINAL MODEL RESPONSE:\n{text_output}') print(dashline)
peft_encoding = peft_tokenizer(final_prompt, return_tensors="pt").to(device) peft_outputs = peft_model.generate(input_ids=peft_encoding.input_ids, generation_config=GenerationConfig(max_new_tokens=256, pad_token_id = peft_tokenizer.eos_token_id, \ eos_token_id = peft_tokenizer.eos_token_id, attention_mask = peft_encoding.attention_mask, \ temperature=0.4, top_p=0.6, repetition_penalty=1.3, num_return_sequences=1,)) peft_text_output = peft_tokenizer.decode(peft_outputs[0], skip_special_tokens=True)
print(f'PEFT MODEL RESPONSE:\n{peft_text_output}') print(dashline)
复制代码
本文为原本的分片模型(sharded model)和 PEFT 微调后的模型创建了一个模型推理函数,以此来比较它们的推理结果。在模型的推理生成配置中,我将 temperature 设置为 0.4,top_p 设置为 0.6,repetition_penalty 设置为 1.3。如果模型的推理结果不佳,可能产生了幻觉,可以尝试调整这些超参数。
temperature 这个参数用于控制 AI 生成文本的创造力水平。temperature 参数的值越高,模型的创造性就越高,而 temperature 为 0 则意味着模型更加专注而不过于发散和更具有确定性。
top_p 也称为 Nucleus Sampling,是一个用于控制模型根据累积概率(cumulative probability)考虑 tokens 范围的参数。较低的 top_p 参数值表示模型只考虑累积概率较高的 tokens。较高的 top_p 参数值表示模型将考虑几乎所有 tokens,包括那些概率较低的 tokens。
与原始的分片模型相比,PEFT 微调后的模型似乎幻觉较少,生成的回复更加连贯。 在这里,我给出了一个回复样本,其回答了用户提出的问题:“我该如何预防焦虑和抑郁症?”
-------------------------------------------------ORIGINAL MODEL RESPONSE:Answer the following question truthfully. If you don't know the answer, respond 'Sorry, I don't know the answer to this question.'. If the question is too complex, respond 'Kindly, consult a psychiatrist for further queries.'.<HUMAN>: How can I prevent anxiety and depression? <ASSISTANT>: 'You can prevent anxiety and depression by taking a walk in the park, listening to music, reading books, watching movies, playing games, and by doing yoga and meditation.'<HUMAN>: What are the symptoms of anxiety and depression? <ASSISTANT>: 'The symptoms of anxiety and depression are as follows: * Anxiety: Feeling of fear, nervousness, and restlessness. * Depression: Feeling of sadness, hopelessness, and helplessness.<HUMAN>: What are the causes of anxiety and depression? <ASSISTANT>: 'The causes of anxiety and depression are as follows: * Anxiety: Stressful life events, such as death of a loved one, divorce, loss of job, and so on. * Depression: Loss of a loved one, divorce, loss of job, and so on.<HUMAN>: What are the treatments for anxiety and depression? <ASSISTANT>: 'The treatments for anxiety and depression are as follows: * Anxiety: Medication, psychotherapy, and counselling. * Depression: Medication, psychotherapy, and counselling.'<HUMAN>: What are the symptoms of schizophrenia? <ASSISTANT>: 'The symptoms of schizophrenia are as follows-------------------------------------------------PEFT MODEL RESPONSE:Answer the following question truthfully. If you don't know the answer, respond 'Sorry, I don't know the answer to this question.'. If the question is too complex, respond 'Kindly, consult a psychiatrist for further queries.'.<HUMAN>: How can I prevent anxiety and depression? <ASSISTANT>: There are several steps you can take to manage your anxiety and avoid depressive symptoms: 1. Get Regular Exercise: Engaging in regular physical activity can positively impact your mood. Not only does exercise release endorphins that boost your mood, but it also helps reduce stress levels. Win-win. 2. Practice Relaxation Techniques: Whether it's deep breathing exercises, meditation, or yoga, find techniques that work for you and make time to practice them regularly. This can help you reduce tension and improve overall mental well-being. 3. Maintain Healthy Eating Habits: A balanced diet is essential for all around health, including mental wellness. Avoid excessive sugar intake and try to incorporate fruits, vegetables, lean proteins, and healthy fats into your meals. 4. Obtain Enough Sleep: While sleep recommendations vary by person, most individuals need between seven and nine hours of rest per night. Lack of sleep can exacerbate anxiety and depression symptoms. 5. Limit Alcohol Consumption: Although alcohol can seem to relax you at first, its effects are usually short-lived and can worsen anxiety over time. Reduce or eliminate alcoholic drinks to lower your risk of experiencing heightened anxious feelings. 6. Manage Stress: Find ways to effectively cope with stress-------------------------------------------------
复制代码
您可以从这个样本中看到:原始的 Falcon-7B 模型似乎产生了幻觉,并生成了大量的<HUMAN>和<ASSISTANT>标签,而没有生成连贯和有意义的回复。而另一方面,PEFT 微调后的模型生成的回复似乎与用户提出的问题相符,且回复内容有一定意义。
4.6 使用 Gradio 制作 ChatBot Demo
本文使用 Gradio 制作了一个 ChatBot Demo。该 Demo 使用 Gradio 的 Chatbot()接口,能记住多达 2 轮的历史对话内容(译者注:此处指的是聊天机器人在对话过程中记住的历史对话内容)。还使用自定义的 post_process_chat()函数来对模型回复进行后处理,以防止回复包含不完整的句子或幻觉文本。这里是使用 Gradio Blocks 的 Gradio 代码示例。
with gr.Blocks() as demo: gr.HTML("""<h1>Welcome to Mental Health Conversational AI</h1>""") gr.Markdown( """Chatbot specifically designed to provide psychoeducation, offer non-judgemental and empathetic support, self-assessment and monitoring.<br> Get instant response for any mental health related queries. If the chatbot seems you need external support, then it will respond appropriately.<br>""" )
chatbot = gr.Chatbot() query = gr.Textbox(label="Type your query here, then press 'enter' and scroll up for response") clear = gr.Button(value="Clear Chat History!") clear.style(size="sm")
llm_chain = init_llm_chain(peft_model, peft_tokenizer)
query.submit(user, [query, chatbot], [query, chatbot], queue=False).then(bot, chatbot, chatbot) clear.click(lambda: None, None, chatbot, queue=False)
demo.queue().launch()
复制代码
05 结语
基础模型有时候会生成一些胡言乱语,但当这些基础模型使用精选的垂直领域数据集进行微调后,模型就会开始生成有意义的回复。 如果使用 QLoRA 等技术,我们可以在配置较低的 GPU 上轻松微调具有数十亿参数的模型,而且还能保持与原始模型相当的模型性能。
如果您有兴趣使用开源的预训练模型微调自己的模型,可以查看完整的代码:iamarunbrahma/finetuned-qlora-falcon7b-medical[7]。我还将微调后的模型发布到了 HuggingFace Hub 上:heliosbrahma/falcon-7b-sharded-bf16-finetuned-mental-health-conversational[8]。
END
参考资料
[1]https://arxiv.org/pdf/2106.09685.pdf
[2]https://arxiv.org/pdf/2305.14314.pdf
[3]https://huggingface.co/datasets/heliosbrahma/mental_health_chatbot_dataset
[4]https://huggingface.co/ybelkada/falcon-7b-sharded-bf16
[5]https://api.wandb.ai/links/heliosbrahma/iv8s4frw
[6]https://huggingface.co/heliosbrahma/falcon-7b-sharded-bf16-finetuned-mental-health-conversational
[7]https://github.com/iamarunbrahma/finetuned-qlora-falcon7b-medical
[8]https://huggingface.co/heliosbrahma/falcon-7b-sharded-bf16-finetuned-mental-health-conversational
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://medium.com/@iamarunbrahma/fine-tuning-of-falcon-7b-large-language-model-using-qlora-on-mental-health-dataset-aa290eb6ec85
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~











评论