
6. Python 的高阶函数
Hi,大家好。 我是茶桁。
本节课,我们来学习一下 Python 中的「高阶函数」。
递归函数
让我们先来了解一下,什么是递归函数。
递归函数就是定义一个函数,然后在此函数内,自己调用自己。
既然是自己调用自己,那这个函数必须要有一个结束才行,否则会一直重复的调用下去,直到调用层数越来越多,最终会导致栈溢出。
让我们先写一个雏形:
最后,导致栈溢出,程序报错。
那么这个程序到底做了什么?
首先,我们定义了一个函数,然后执行,执行的时候给了一个参数3。
进入程序之后,先将3打印了一遍,然后在函数内部,又调用了一遍自己,参数为3-1,也就是传了一个参数2,在进入函数之后,打了了2, 继续自己调用自己,传参2-1,1-1, 0-1, ...就这样一直循环下去。
那么我们怎么样让这个程序停下来?就是在函数自己调用自己之前,加上一个限制条件:
我们给调用之前加了一个条件,如果num > 0才允许继续执行,这样,当程序传递了1-1之后,执行了最后一次打印,然后就不向下执行了。
不过不要以为程序到这里就结束了,我们多加一行代码试试看:
如果你不知道程序做了什么,我们稍微分析一下:
也就是,在递归函数中,程序是一层一层的进入,然后再一层一层的返回。
这就好像是, 我们在上学的时候,你坐在最后一排,但是你有个心仪的女孩坐在最前面。你想要对方电话,这个时候你传递一个纸条给前面的同学,前面的同学再往前传,一直往前传到女孩手里。女孩看完之后,写完回复再一次次的传回来。最后你满怀期待的打开一看:“滚。”
当然,我们的递归函数和这个不同的地方是最后不会多加那个“滚”字。
回调函数
什么是回调函数呢?
我们首先来思考一个问题:
在这个简单的函数中,我们已经学会了传值a给到func(),那么参数到底可以传一些什么进去?a可以是什么?能不能是一个函数呢?
这就引出了我们现在的内容:
可以看到,我们选择执行的是func函数,但是最后打印出了_self函数中语句。原因就是我们在执行func函数的时候,将_self函数作为参数传递给了func的形参obj, 我们在其中打印了obj以及obj的类型,并且最后执行了一下obj, 实际上也就是执行了一遍_self函数。
如果在一个函数中要求传递的参数是一个函数作为参数,并且在函数中使用了传递进来的函数,那么这个函数我们就可以称为是一个回调函数。
我们拿系统内部的一个现成的函数来重新封装一个新的函数来试试:
在日后使用这个函数的时候,就可以传入数值和要做什么计算的方法,就可以了。
当然,这个函数写的并不完善,比如,我们在执行func(2, 3, sum)的时候就会报错,原因是因为sum()函数内部是要进行迭代的的,然而int类型中没有魔法方法__iter__, 所以无法迭代。所以,要想这个函数具有通用性,还需要在内部完成很多工作。
闭包函数
之前我们在回调函数中将函数作为参数进行了传递,那么问题来了,既然函数能作为参数进行传递,那能不能作为参数被return呢?
我们可以看到,work函数被成功返回出来了。但是并未继续执行, 因为其内部的print()没起作用。
我们用一个变量来接收这个返回的函数:
说明res接收到返回的work()函数,并且最后执行成功了。
好了,让我们继续为这个函数做一点什么,看看有什么变化。
这个结合前几节所讲的内容就很好理解了对吧? nonlocal关键字拿到上一层函数定义的变量,然后在内层函数中进行使用,最后打印出来。
那我们继续执行会如何?让我们多执行几次:
你会不会认为会一直打印100? 让我们看看执行结果到底是怎样的:
怎么样,是不是完全没想到?这个就是闭包函数的特点。
在一个函数内返回了一个内函数,并且这个返回的内函数还使用了外函数中局部变量,这个就是闭包函数。其特点为:
在外函数中定义了局部变量,并且在内部函数中使用了这个局部变量
在外函数中返回了内函数,返回的内函数就是闭包函数
⚠️ 主要在于保护了外函数中的局部变量,既可以被使用,又不会被破坏。
检测一个函数是否为闭包函数,可以使用
func.__closure__,如果是闭包函数返回cell
匿名函数 -- lambda 表达式
首先,我们先弄清楚什么是匿名函数: 匿名函数的意思就是说可以不使用def来定义,并且这个函数也没有名字。
在 Python 中,我们可以使用lambda表达式来定义匿名函数。我们需要注意,lambda仅仅是一个表达式,并不是一个代码块,所以lambda又称为一行代码的函数。
在lambda表达式中,也有形参,并且不能够访问除了自己的形参之外的任何数据,包括全局变量。其语法如下:
让我们来尝试写写看,我们先来定义一个普通的加法运算的函数:
毫无疑问,执行结果为5。那么接下来,用lambda该怎么写呢?
结合闭包函数的讲解,这里就应该很容易看懂了吧?一样的地方就是,使用了一个变量res来接收这个返回的函数,然后执行res函数。
让我们再来一段:
只看结果的话,我们很清楚这段函数最后执行到了else语句内。但是是如何进入的呢?让我们将这段代码用普通函数的写法展开来看看:
这样是不是很清晰了?回过头来让我们看刚才那段lambda表达式,我们可以这样去看:
所以可以看出来,其实lambda十分的方便,并且并不难理解,当你习惯了lambda之后,会非常便捷。
迭代器
迭代器是一个很有意思的功能,可以说是 Python 中最具特色的功能之一,它是访问集合元素的一种方式。
迭代器是一个可以记住访问遍历的位置的对象。从集合的第一个元素开始访问,直到集合中的所有元素被访问完毕。
迭代器只能是从前往后一个一个的遍历,不能后退。
我们把之前一直使用的range()拿过来看:
表面上来看,似乎range()本身就是一个迭代器,可是我们来尝试做个实验:
当我们尝试调用next()函数的时候报错了,被告知range不是一个迭代器。
那么,range不是迭代器,究竟是什么呢?这里我们就要先深入研究下迭代器的特性:
严格来说,迭代器是指实现了迭代协议的对象,迭代协议是指实现了iter方法并返回一个实现了next方法的迭代器对象,并通过StopIterator一场标识迭代完成。
iter()
iter()能把迭代的对象,转为一个迭代器对象,其参数为可迭代的对象(str, list, tuple, dict), 返回值为迭代器对象。其中需要注意的一点是:迭代器一定是一个可以迭代的对象,但是可迭代的对象并不一定是迭代器。
我们在迭代器上使用iter会得到相同的对象:
基于此,我们可以这样实现:
next()
next()函数可以去调用迭代器,并返回迭代器中的下一个数据。
我们使用iter函数可以从任何可迭代对象中获取一个迭代器:
可以看到,我们使用iter函数可以从任何可迭代对象中获取一个迭代器。而且迭代器有个特点,即每次用完一个元素即消耗掉该元素,不会保留在迭代器中,也就是说,是一次性的。
可以看到,list里面已经空了。
我们用for来取值:
for直接将迭代内的元素全部取完了,所以最后打印下一个值的时候也显示空了。所以我们可以得到迭代器的取值方案:
迭代器的取值方案
next():调用一次获取一次,直到数据被取完。list():使用list函数直接取出迭代器中的所有数据。for:使用for循环遍历迭代器的数据
总结一下:
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:
iter()和next()。字符串,列表或元组对象都可用于创建迭代器:
那么,再回过头来看看range
range可以像任何其他可迭代对象一样循环使用,但是它并不具备迭代器中的一些特性,比如,我们之前实验过,range并不能使用next方法,而我们可以从range中得到一个迭代器:
我们在迭代器中使用元素就会消耗掉该元素,但是我们遍历一个range对象并不消耗它, 比如:

很明显我们可以重复使用。
来一个更直接的,我们之前用for获取了迭代里的值,我们对range()也来使用一下看看会不会有不同的结果:
一样的代码,对象不同。我们可以明显看到区别,range拿到最后里面的元素并没有减少。这也说明了,range并不是迭代器。
实际上,range的迭代是通过iter协议来实现的,只是一种类似迭代器的鸭子类型,并非真正的迭代器。
其实,有一种可以直接检测迭代器和可迭代对象的方法:
今天的知识点讲到这就结束了,接下来,让我们来做两个小练习。
练习题
递归查询斐波那契数列位数
还记得我们之前讲过的斐波那契数列吗?不记得没关系,我们来复习一下:
我们这次来实现一个函数,用于查询斐波那契数列中当前位置的数值是多少。
我为大家画了张图,来看看程序内部到底做了些什么:
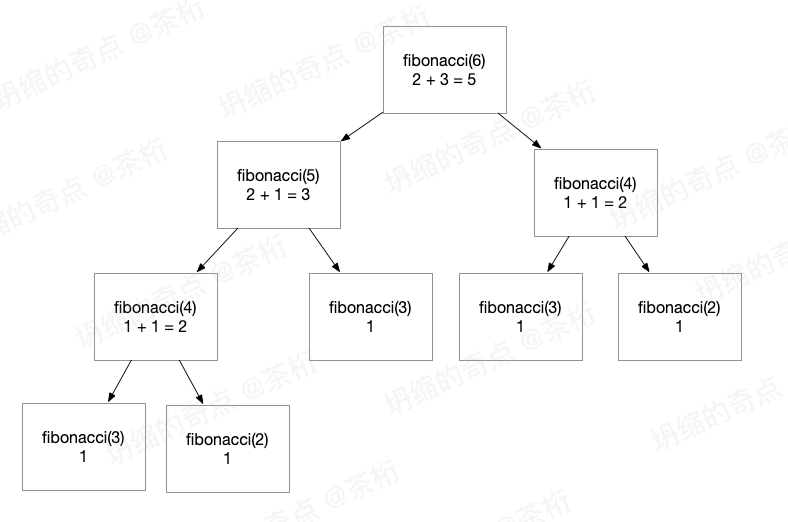
从这张图中,我们可以看到递归的步骤和返回的结果。
递归实现阶乘
什么是阶乘?比如我们实现 7 的阶乘,那么就是
让我们来试着实现一下:
验证一下看看:
看来结果没问题,那让我们来看看程序内发生了什么:
虽然实现了,最后还是不得不说几点注意事项:
递归函数的效率并不高,所以尽量能不用就不要用。
一个函数如果调用后没有结束,那么栈空间中就一直存在,直到这个函数运算结束才会销毁。
好了,今天的课程到此结束。大家课后记得多练习。下课!
版权声明: 本文为 InfoQ 作者【Hivan】的原创文章。
原文链接:【http://xie.infoq.cn/article/95e4822b0afe3e4c8a74e2901】。文章转载请联系作者。

还未添加个人签名 2020-10-20 加入
还未添加个人简介









评论