工具介绍
注意:该部分介绍摘抄自:https://www.aiwanyun.cn/archives/174
Prometheus、Grafana、Node Exporter 和 Alertmanager 是一组用于监控和可视化系统性能的开源工具。它们通常一起使用,形成一个强大的完整的监控和告警系统。 一般来说,这四个工具一起协作,形成了一个完整的监控和告警系统。Node Exporter 用于收集主机级别的指标(本文暂未使用),Prometheus 存储和查询这些指标,Grafana 提供可视化界面,而 Alertmanager 则负责管理和发送告警。整个系统的目标是帮助管理员和开发人员实时了解系统的状态、性能和健康状况,并在必要时采取措施。
Prometheus
Prometheus 是一种开源的系统监控和警报工具。它最初由 SoundCloud 开发,并成为 Cloud Native Computing Foundation(CNCF)的一部分。Prometheus 支持多维度的数据模型和强大的查询语言,使得用户可以轻松地收集和查询各种类型的监控数据。
Grafana
Grafana 是一个开源的数据可视化和监控平台。它提供了丰富的图表和仪表盘,可以将各种数据源的信息可视化展示。Grafana 支持多个数据源,包括 Prometheus、Graphite、InfluxDB 等,因此可以与各种监控系统集成,提供灵活且强大的可视化功能。
Alertmanager
Alertmanager 是 Prometheus 生态系统中的一个组件,负责处理和管理告警。当 Prometheus 检测到异常或达到某个预定的阈值时,它将生成告警并将其发送到 Alertmanager。Alertmanager 可以进行静默、分组、抑制和路由告警,并将它们发送到不同的接收端,如电子邮件、Slack 等
.NetCore 项目准备
基于我的一个示例项目进行改造,项目地址:https://gitee.com/AZRNG/my-example ,为了演示一个基本的监控效果,监控的数据也只是请求,具体生产环境需要监控什么业务,这个看具体情况了,这里需要在原来的项目基础上需要安装以下 nuget 包
<PackageReference Include="OpenTelemetry.Exporter.Prometheus.AspNetCore" Version="1.7.0-alpha.1" /><PackageReference Include="OpenTelemetry.Extensions.Hosting" Version="1.7.0" />
复制代码
然后就可以注入服务,这里只是举例操作
services.AddOpenTelemetry() .WithMetrics(builder => { builder.AddPrometheusExporter(); builder.AddMeter("Microsoft.AspNetCore.Hosting", "Microsoft.AspNetCore.Server.Kestrel"); });
复制代码
最后记得要使用服务
app.MapPrometheusScrapingEndpoint();
复制代码
启动项目后访问 ip+ metrics 访问页面
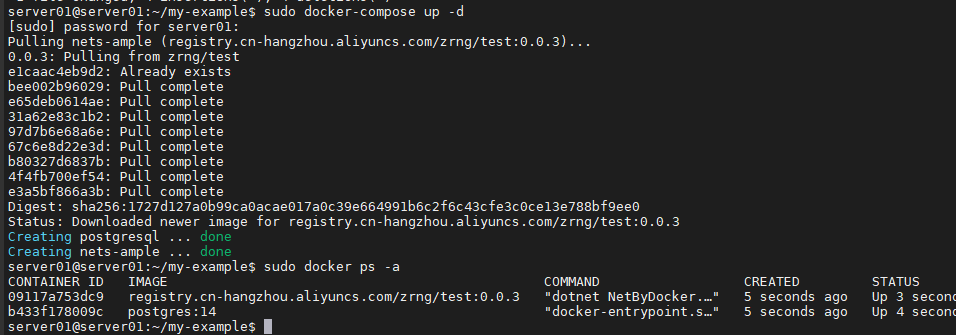
然后将该示例项目使用 docker 部署到服务器上 ,如果要使用该示例项目,记得切换分支到 develop,将项目拉取到服务器,然后进入项目目录,执行命令去生成容器
sudo docker-compose up -d
复制代码
部署成功截图如下
访问地址 http://192.168.82.163:8001/metrics
安装监控和可视化程序
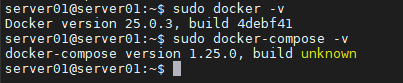
准备一个服务器,提前安装好了 docker 以及 docker-compose 程序,版本示例如下
关于 Prometheus 和 Grafana 可以通过 docker 进行安装到服务器中,可以参考仓库:https://gitee.com/AZRNG/common-docker-yaml
安装 Prometheus
因为这里我只是用于做 demo 演示效果,所以我并没有取考虑挂载的问题,生产环境使用记得挂载数据
version: '3'
services: prometheus: # 访问:http://localhost:9090/targets image: prom/prometheus:v2.37.6 container_name: prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--web.console.libraries=/usr/share/prometheus/console_libraries' - '--web.console.templates=/usr/share/prometheus/consoles' - '--web.external-url=http://localhost:9090/' - '--web.enable-lifecycle' - '--storage.tsdb.retention=15d' volumes: #- /etc/localtime:/etc/localtime:ro - ./config/prometheus/:/etc/prometheus/ #- ./data/prometheus:/prometheus ports: - 9090:9090 links: - alertmanager:alertmanager
alertmanager: # 告警服务 image: prom/alertmanager:v0.25.0 container_name: alertmanager ports: - 9093:9093 volumes: # - /etc/localtime:/etc/localtime:ro - ./config/prometheus/:/etc/alertmanager/ command: - '--config.file=/etc/alertmanager/alertmanager.yml' - '--storage.path=/alertmanager'
复制代码
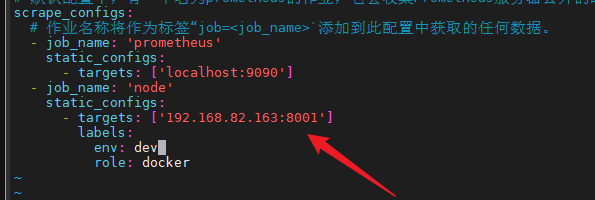
关于 prometheus.yml 内容如下
# 全局配置global: scrape_interval: 15s evaluation_interval: 15s # scrape_timeout is set to the global default (10s).# 告警配置alerting: alertmanagers: - static_configs: - targets: ['localhost:9093']# 加载一次规则,并根据全局“评估间隔”定期评估它们。rule_files: - "/config/rules.yml"# 控制Prometheus监视哪些资源# 默认配置中,有一个名为prometheus的作业,它会收集Prometheus服务器公开的时间序列数据。scrape_configs: # 作业名称将作为标签“job=<job_name>`添加到此配置中获取的任何数据。 - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' # .NetCore服务地址 static_configs: - targets: ['localhost:9100'] labels: env: dev role: docker
复制代码
alertmanager.yml 文件,我并没有做配置,暂时搞了一个默认的
global: resolve_timeout: 5m smtp_smarthost: 'xxx@xxx:587' smtp_from: 'zhaoysz@xxx' smtp_auth_username: 'xxx@xxx' smtp_auth_password: 'xxxx' smtp_require_tls: trueroute: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'test-mails'receivers:- name: 'test-mails' email_configs: - to: 'scottcho@qq.com'
复制代码
rule.yml 文件内容如下
groups:- name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 1m labels: serverity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
复制代码
然后就可以运行 docker-compose 命令去生成容器,示例如下
然后访问 Ip 地址加端口访问页面,比如http://192.168.81.139:9090/
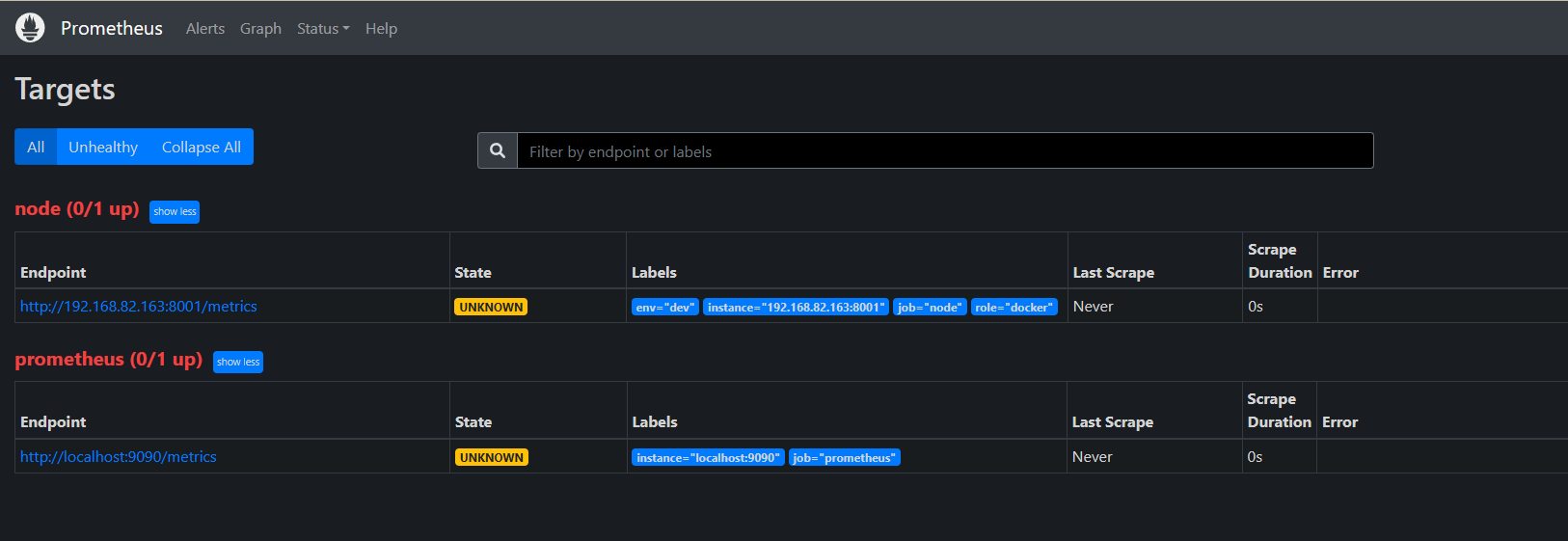
打开这个界面就说明安装好了,这个时候我们看下 http://192.168.81.139:9090/targets?search= 页面
这个 node 报错是因为这个地址是无效了,那么修改为真是.NetCore 的服务地址,修改配置文件然后重新启动
重启后界面显示如下
安装 Granfana
这里直接使用 docker 来安装 grafana
sudo docker run --name grafana -d -p 8000:3000 grafana/grafana
复制代码
然后访问地址 ip+ 8000,默认账号密码为 admin/admin
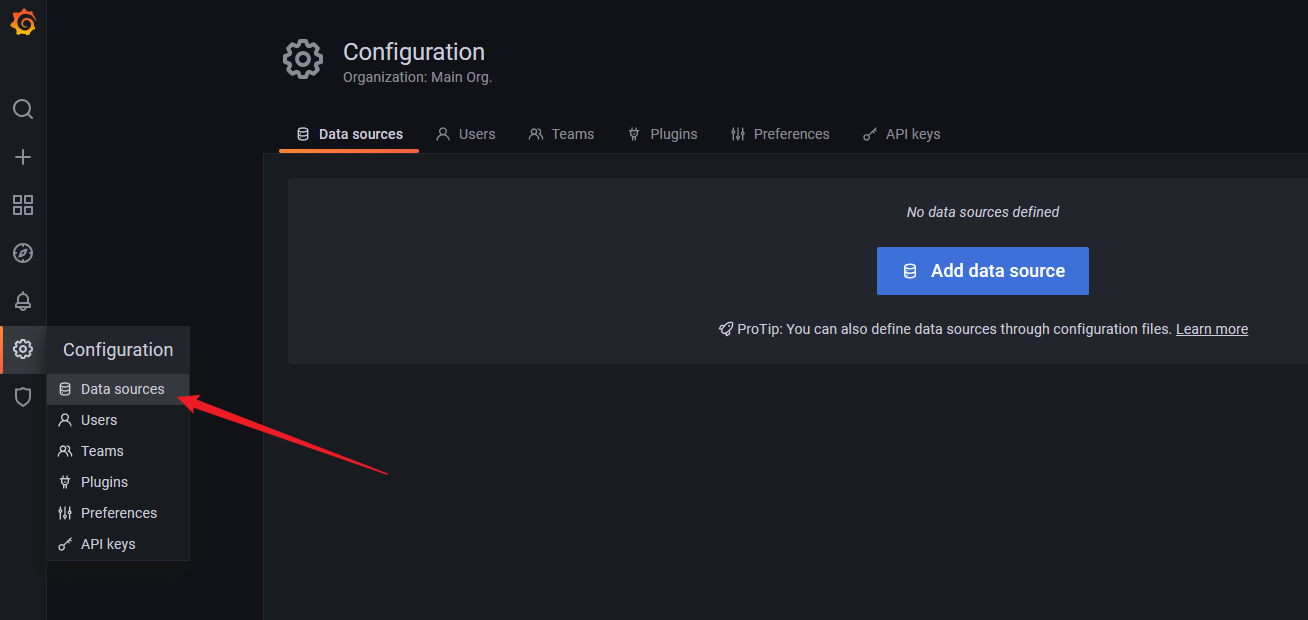
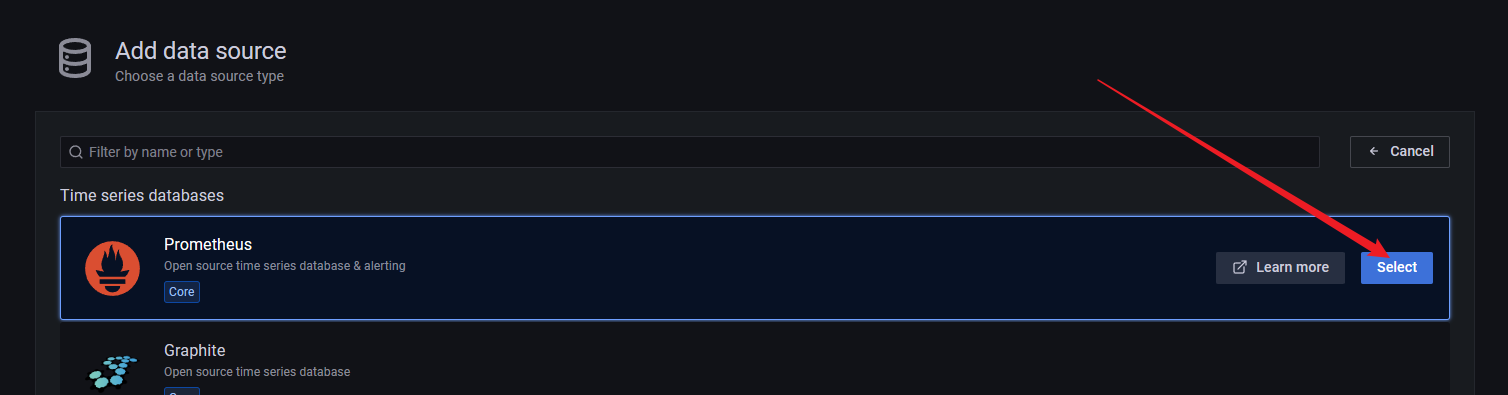
添加数据源
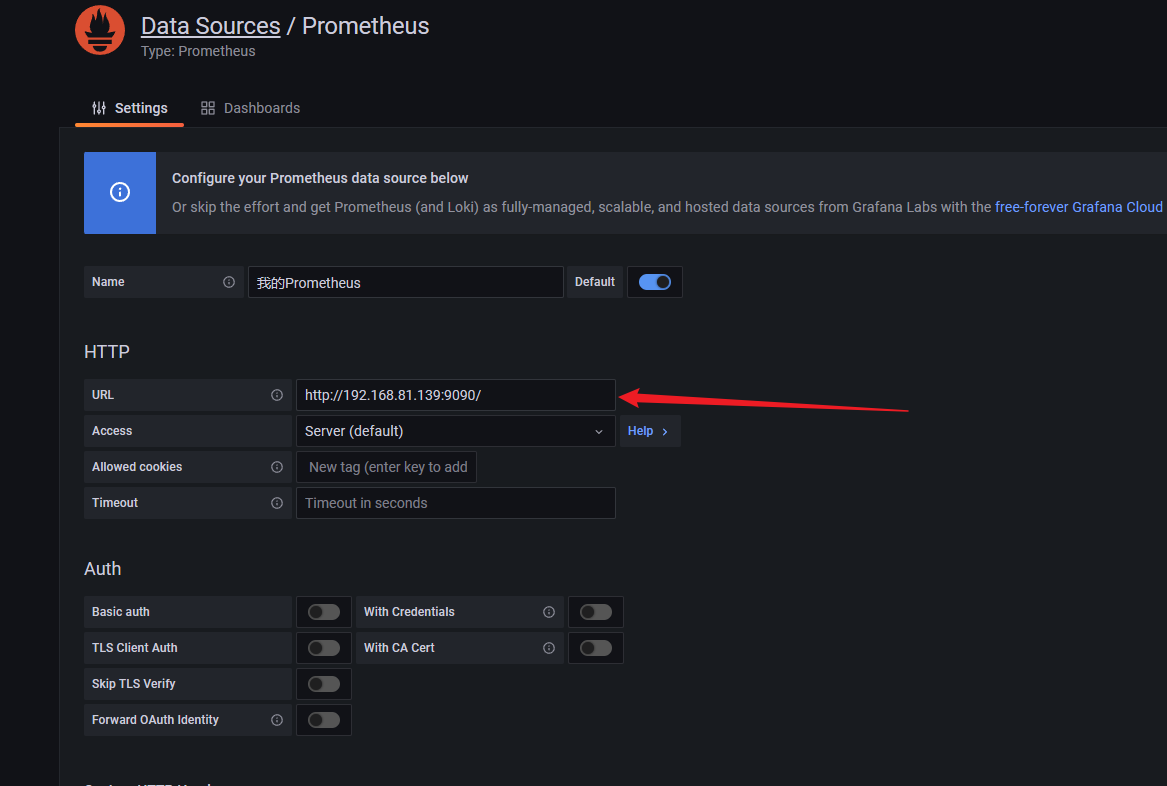
填写 prometheus 地址
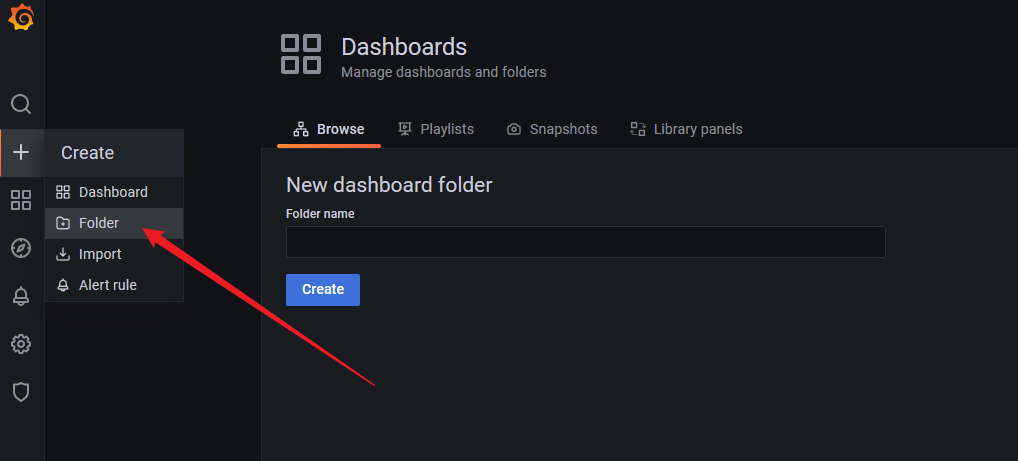
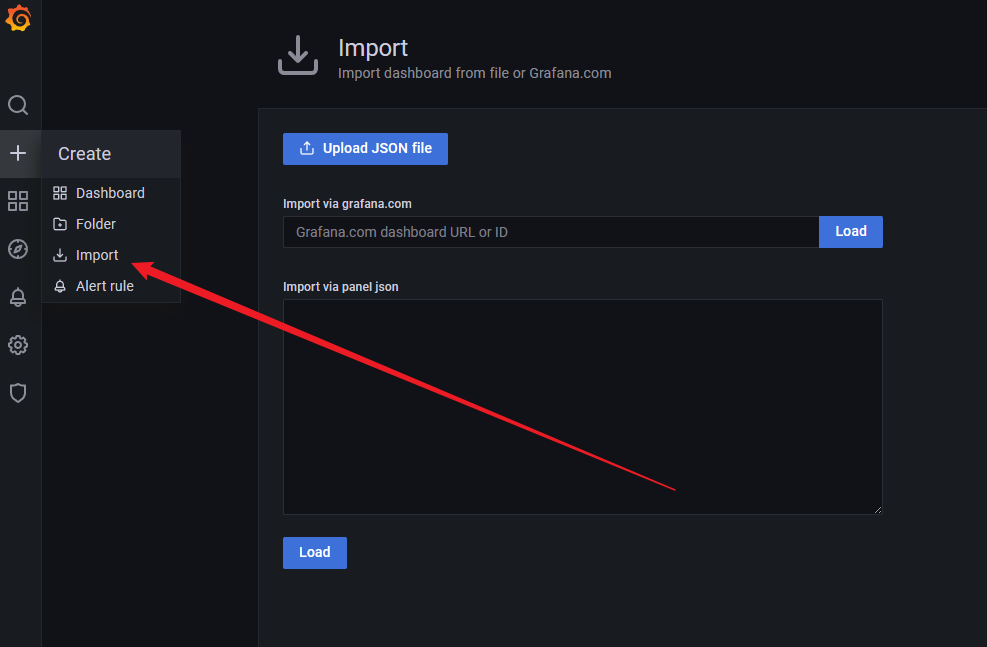
导入仪表盘
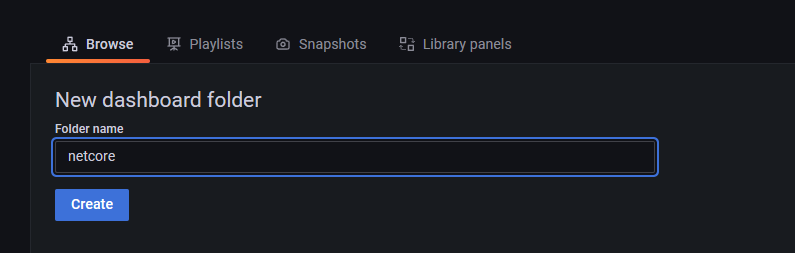
创建文件夹用来存放我们本地的要导入的文件
想要在 Grafana 中进行数据的展示,需要导入 dashborards 模板,本文的模板我是从微软仓库找到的,地址为:https://github.com/dotnet/aspire/tree/main/src/Grafana
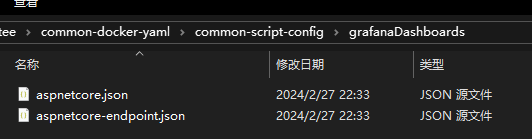
分别点进去下载这两个仪表盘对应的的 json 文件即可,也可以去我 common-docker-yaml 仓库中下载
然后导入 json 文件
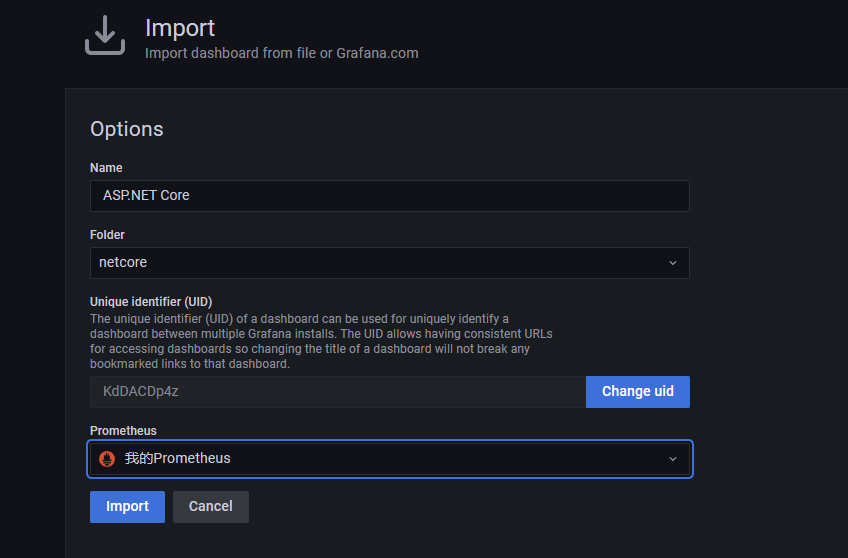
导入 aspnetcore.json 文件,并选择我们的 netcore 文件夹以及选择刚刚我们创建的 Prometheus 数据源
导入 aspnetcore-endpoint.json 文件
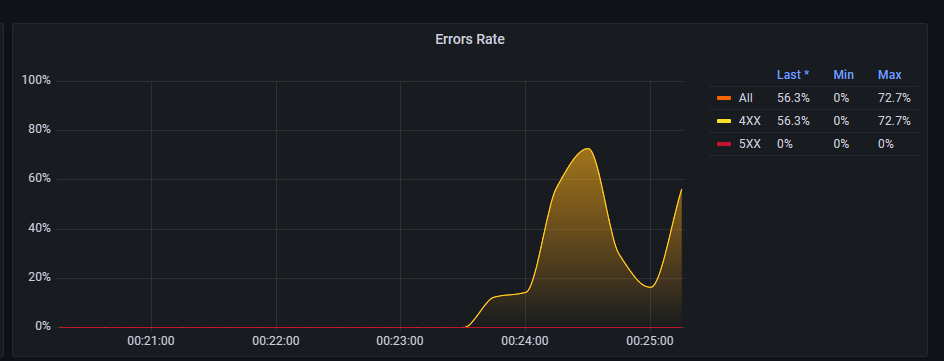
这个时候我们就看到了好看的仪表盘
当我点击接口让其报错,那么就显示到界面上
如果需要监控其他内容,也可以模仿着进行修改。
文章转载自:AZRNG
原文链接:https://www.cnblogs.com/azrng/p/18048851
体验地址:http://www.jnpfsoft.com/?from=001













评论