在 Python 开发中,Requests 是一个非常受欢迎的 HTTP 请求库。遇到网络波动或其他问题时,请求可能会失败,这时我们通常会进行重试。
常见的写法一般是:
def login(): for a in range(3): try: return requests.get('https://www.baidu.com') except Exception as e: print(e) continue
复制代码
一种更高级的方式是编写一个装饰器,以便于重用
def retry_request(): def decorator(func): def wrapper(*args, **kwargs): for attempt in range(3): try: return func(*args, **kwargs) except Exception as e: if attempt == 2: # 最后一次重试 raise e return wrapper return decorator
@retry_request()def fetch_data(url): response = requests.get(url) response.raise_for_status() return response
复制代码
实际上,Requests 提供了自带的重试功能。
Requests 依赖了 urllib3 这个依赖库进行网络请求的发送,Requests 在 urllib3 的基础上做了一层封装,可以通过 HTTPAdapter 类实现自动重试。
import logging
import requestsfrom requests.adapters import HTTPAdapter
# 开启 urllib3 的日志,以便于查看重试过程logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')urllib3_logger = logging.getLogger('urllib3')urllib3_logger.setLevel(logging.DEBUG)
# 使用 session 发送请求session = requests.session()# 打印 adaptersprint(session.adapters)session.mount('https://', HTTPAdapter(max_retries=3))session.mount('http://', HTTPAdapter(max_retries=3))try: print(session.get('https://www.baidu.com', timeout=0.01).text[:100])except Exception as e: print(e) print(type(e))
复制代码
以上代码中,开启了 urllib3 的日志,方便我们后面查看重试的过程,并且在 session 中覆盖了默认的 adapters,添加了重试次数参数,为了方便复现,我将超时时间设置了很小的一个值,0.01,以确保一定会超时。
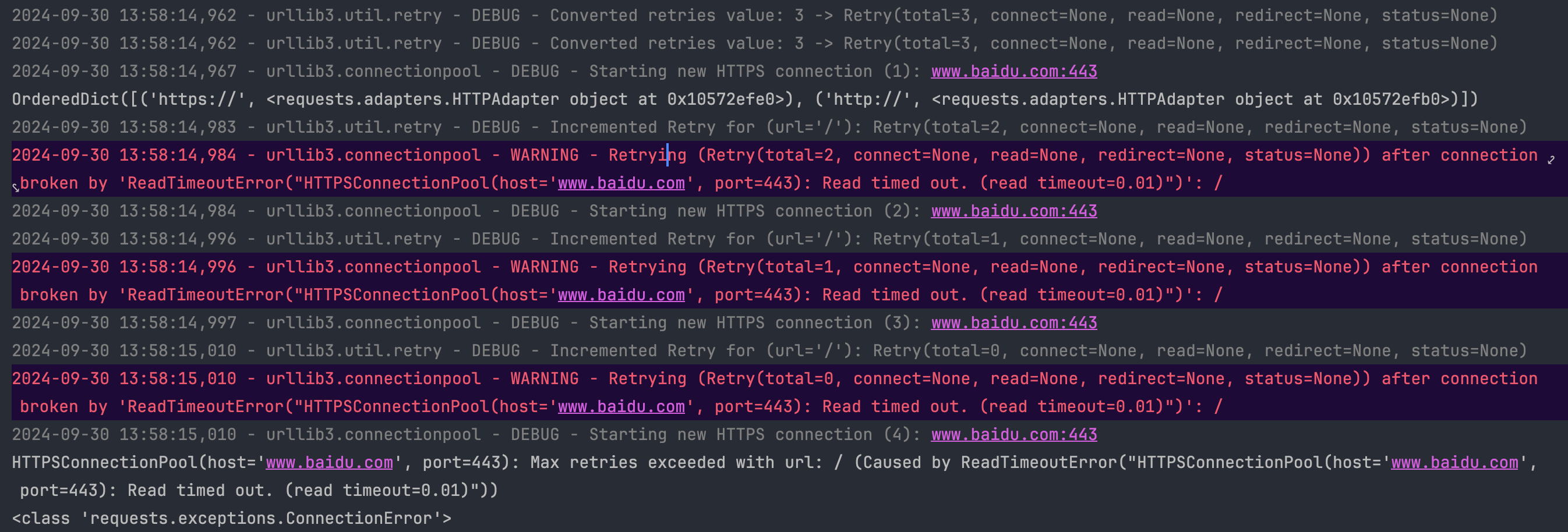
代码的运行结果为:
从上面的图片中可以看出,首先 urllib3 设置了两次重试参数(新建了两个 Retry 类),正好对应我们新建了两个 HTTPAdapter 类,然后向百度发送请求,在发生超时后,打印了日志并且设置重试次数为 2,然后继续重试。在 3 次重试后,打印了 URL 超过最大重试次数的错误,并且抛了一个 ConnectionError 异常。
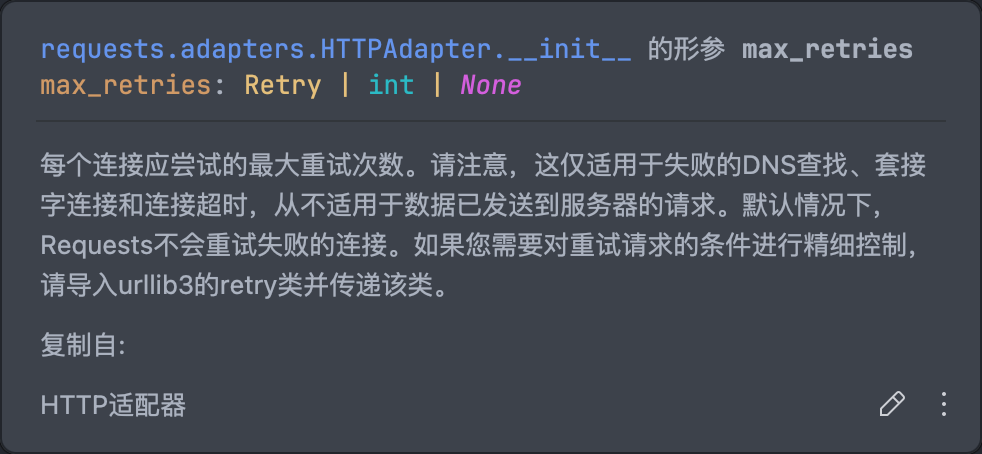
根据 max_retries 的文档说明,该参数仅适用于 DNS 查找、套接字连接和连接超时,而默认情况下并不会自动重试,需要手动设置。
也就是说它不会针对响应解析失败或者证书验证错误这些情况进行重试,这些情况需要我们手动处理。
其实,max_retries 参数最终会作为 Retry 类的一个参数来生效,通过 Retry 类可以更加精细的控制重试条件和重试流程,这个我们后面再说。
在以后的开发中,如果使用 Requests 需要对网络问题进行重试,可以直接使用以下代码,简单而有效!
session.mount('https://', HTTPAdapter(max_retries=3))session.mount('http://', HTTPAdapter(max_retries=3))
复制代码














评论