
【MindStudio 训练营第一季】MindStudio Profiling 随笔
MindStudio Profiler 简介
Ascend AI 处理器是一款面向 AI 业务应用的高性能集成芯片,包含 AI CPU、A Core、AI Vector Core 等计算单元来提升 AI 任务的运算性能。基于 Ascend AI 处理器,Mindstudio 在算子开发、模型训练及推理应用等不同环节,提供了端到端的Profiler工具。该工具可以帮助用户看到模型从应用层到芯片层的接口和算子耗时,从而准确定位系统的软、硬件性能瓶颈,提高性能分析的效率。
调优主要分为三步:
性能数据采集、解析、分析
性能问题定位,发现性能瓶颈点
采取性能优化措施
性能分析简要介绍

通过命令行采集性能数据
数据采集方式
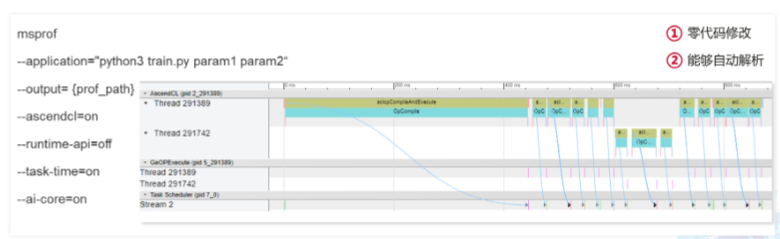
数据采集方式——离线推理
acl.json 配置文件方式
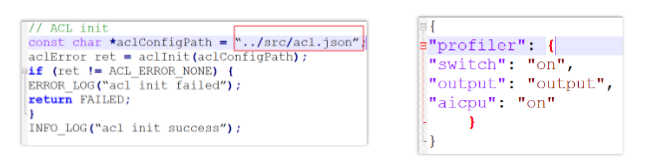
打开工程文件,查看调用的 aclInit0 函数,获取 acl.json 文件路径
修改 acl.json 文件,添加 Profiling 相关配置
AI 任务相关性能数据采集方式 - API 接口
API 接口类型
aclprofinit: 设置落盘路径
aclprofCreateConfig: 设置采集参数
aclprofStart: 开始采集
aclmdlExecute: 执行模型
aclprofStop: 结束采集
aclprofDestroyConfig: 释放配置资源
aclprofFinalize:释放 profiling 组件资源
API 接口规范
ACL API(C 接口)
pyACL API (Python 接口)

数据采集方式——在线推理与训练
MindSpore

TensorFlow
环境变量配置:
训练脚本配置 Estimator 模式下,通过 NPURunConfig 中的 profiling_config 开启 Profiling 数据采集。
sess.run 模式下,通过 session 配置项 profiling_mode.profiling_options 开启 Profiling 数据采集。

Pytorch 框架侧数据的采集方法

Pytorch CANN 侧数据的采集方法

同时采集 PyTorch 框架侧和 CANN 数据
msprof.bin

对比不同迭代的耗时

仅采集需要的迭代

Profiling 数据说明
(1) Step trace timeline 数据: step trace 数据查看选代耗时情况,识别较长选代进行分析。


(2) 对应迭代的 msprof timeline 数据: 通过打开导出的 msprof 数据查看送代内耗时情况,存在较长耗时算子时,可以进一步找算子详细信息辅助定位;存在通信耗时或调度间隙较长时,分析调用过程中接口耗时。

(3)HCCL timeline 数据:通过多卡进行训练时,卡间通信算子也可能导致性能瓶颈。

(4)打开组件接口耗时统计表:可以查看迭代内 AscendCL API 和 Runtime APl 的接口耗时情况,辅助分析接口调用对性能的影响。

(5)打开对应的算子统计表:可以查看送代内每个 AI CORE 和 AI CPU 算子的耗时及详细信息,进一步定位分析算子的 metrics 指标数据,分析算子数据搬运、执行流水的占比情况,识别算子瓶颈点。

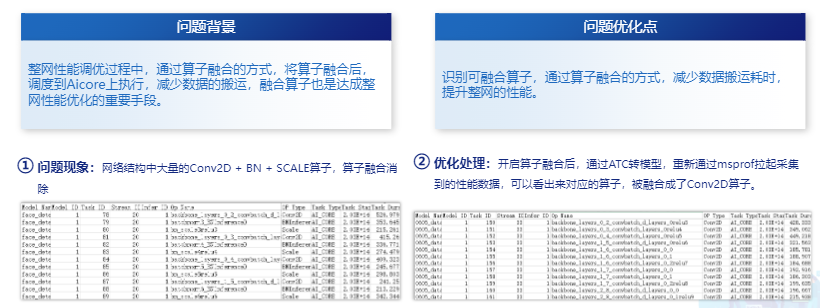
优化案例——算子融合

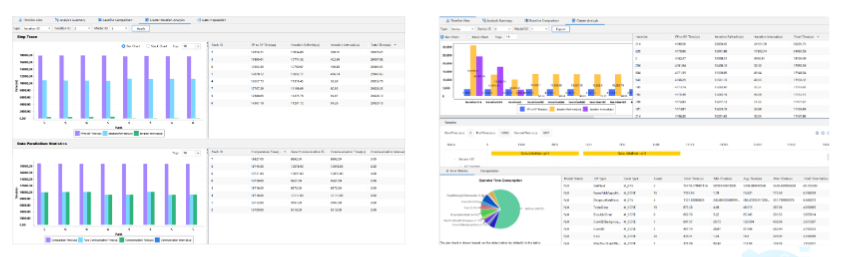
通过 MindStudio IDE 分析性能
IDE 模式
集群调优

版权声明: 本文为 InfoQ 作者【Angel Wings】的原创文章。
原文链接:【http://xie.infoq.cn/article/8f8c34a378379d2ed9f8e3dd1】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2020-03-18 加入
还未添加个人简介








评论