作者介绍
作者介绍:jennyerchen(陈再妮),PostgreSQL ACE 成员,TDSQL PG 开源版负责人,有多年分布式数据库内核研发经验,曾供职于百度数据库团队,加入腾讯后参与了 TDSQL PG 版异地多活、读写分离、Oracle 兼容等多个核心模块的研发,当前主要负责 CDW PG 的存算分离相关特性的研发工作。
背景简介
CDW PG 是腾讯自主研发的新一代分布式数据库,其具备业界领先的数据分析能力,在提供大型数据仓库处理能力的同时还能完整支持事务, 采用无共享的集群架构,适用于 PB 级海量 OLAP 场景。
OLAP 场景列存表的应用比较广泛,而且一般数据量都非常大,会占用很多的磁盘空间。列存高效存储表,因为数据是按列存储的,如果进行压缩的话可以具备很高的压缩比,大大节省磁盘空间。
压缩解压过程
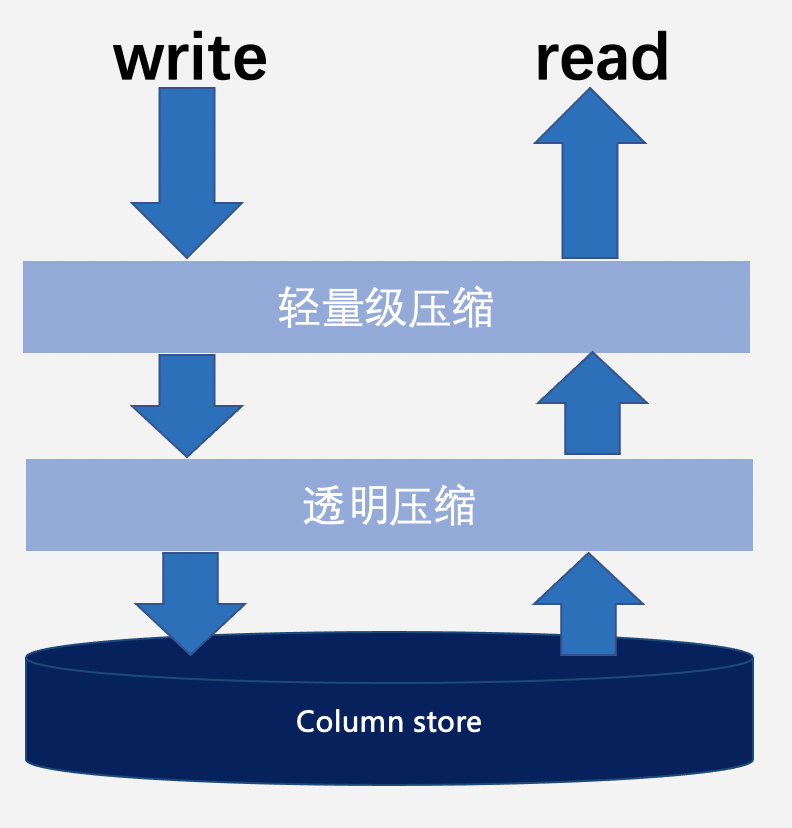
数据压缩解压过程如下图所示:
写入时进行压缩。
读取时进行解压。
压缩分为轻量级压缩和透明压缩 2 种,并且可叠加使用。数据写入时先经过轻量级压缩进行编码,然后编码结果可再进行透明压缩。数据读取时根据压缩时采用的算法先经过透明解压,然后再经过轻量级解码最后返回给用户。
针对压缩表的 xlog、用户数据的磁盘存储形态都是压缩的,而内存 buffer 中需要计算使用的数据是解压过的。
注:整个过程全自主实现,对用户完全透明,用户 0 感知。
压缩实现
对数据进行压缩能够有效地减少磁盘 IO 以及数据存储成本,但对数据的压缩和解压操作也会消耗额外的 CPU 资源、影响数据的访问与存储性能。所以压缩是一个用 CPU 换取磁盘 IO 的过程,需要根据业务需求,由用户来指定列存表创建时可以创建压缩表,也可以创建非压缩表(行存暂且不支持指定压缩)。
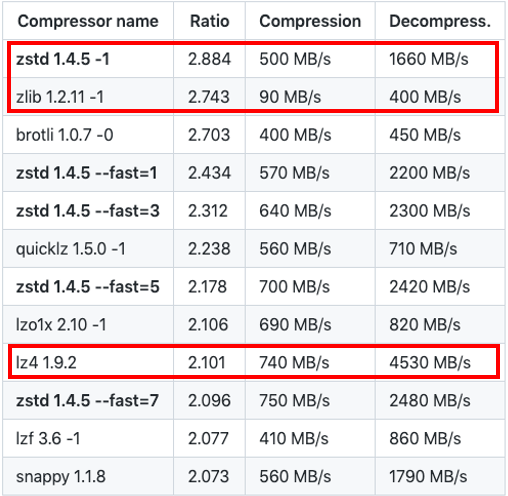
对比各种透明压缩算法的压缩解压性能和压缩比,zstd 是压缩比最高的,lz4 是压缩解压效率最好的,因此我们选择 zstd 和 lz4 这两种压缩算法分别用于不同的压缩级别:根据用户设定需要高压缩级别的采用 zstd,需要快速压缩解压而不追求压缩比的采用 lz4。
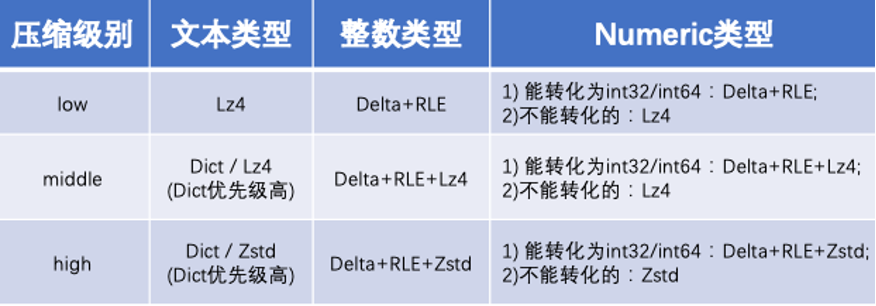
轻量级压缩算法主要是使用字符编码的方式,常用的有 RLE(当数据存在大量连续的相同值时,会把重复的数据存储为一个数据值和计数)、Delta(只存储数据间的差异 diff,适用于数据改变很小的场景)、Dict(先会检查数据的重复值,如果某一值出现的次数达到要求则将其加入字典。列中的值将会直接指向字典中与其重复的值)。根据其原理可知:数字类型的用 Delta 压缩后再对 diff 值用 RLE 可以达到很好的压缩比,文本类型的用 Dict 更适合。
因此如果指定了压缩表,则数据写入时进行压缩,并且内核会根据数据类型自适应选择较优的压缩算法:
文本类型
ow 模式只用 lz4;
middle 模式优先 dict 压缩,成功直接返回,dict 压缩不成功进入 lz4 压缩;
high 模式优先 dict 压缩,成功直接返回,dict 压缩不成功进入 zstd 压缩。
数字类型
low 模式在 delta 的压缩基础上再加上 RLE 压缩;
middle 模式在 delta 的压缩基础上再加上 RLE 压缩、lz4 压缩;
high 模式在 delta 的压缩基础上再加上 RLE 压缩、zstd 压缩。
numeric 类型
压缩级别为 low 时:numeric 能转成 int32 或者 int64 的,用 delta + RLE 压缩,不能转化的用 lz4;
压缩级别为 middle 时:numeric 能转成 int32 或者 int64 的,用 delta + RLE 压缩,不能转化的用 lz4;在前面的压缩基础上再加上 lz4;
压缩级别为 high 时:numeric 能转成 int32 或者 int64 的,用 delta + RLE 压缩,不能转化的用 lz4;在前面的压缩基础上再加上 zstd;
压缩过程中最终将使用的压缩方法存储在压缩页面头部中,供后续解压使用。数据读取时会进行解压,解压时优先读取头部信息,根据头部信息中记录的压缩算法,然后调用对应算法的解压函数,解压时的顺序与压缩时的顺序相逆,先使用透明压缩算法进行解压,再使用轻量级压缩算法进行解压。
使用实践
表级别压缩
表级别压缩的级别分为 high/middle/low/no,启用压缩可以降低磁盘存储大小,级别越高,磁盘占用空间越小,压缩也越耗时。
表级别压缩需要在创建表时指定压缩级别:WITH (orientation=column, compression = $压缩级别); 不指定压缩则默认是 low 压缩,可以通过 compression = no 显示指定不压缩。
1)创建一张不压缩表:
CREATE TABLE test1 (
id bigint NOT NULL,
name varchar(25) NOT NULL,
quantity numeric(15,2) NOT NULL,
commitdate date NOT NULL,
)WITH (orientation = column, compression = no);
复制代码
2)创建一张 low 级别压缩表:
CREATE TABLE test2 (
id bigint NOT NULL,
name varchar(25) NOT NULL,
quantity numeric(15,2) NOT NULL,
commitdate date NOT NULL,
)WITH (orientation = column);
复制代码
或者
CREATE TABLE test3 (
id bigint NOT NULL,
name varchar(25) NOT NULL,
quantity numeric(15,2) NOT NULL,
commitdate date NOT NULL,
)WITH (orientation = column, compression = low);
复制代码
3)创建一张 middle 级别压缩表:
CREATE TABLE test4 (
id bigint NOT NULL,
name varchar(25) NOT NULL,
quantity numeric(15,2) NOT NULL,
commitdate date NOT NULL,
)WITH (orientation = column, compression = middle);
复制代码
4)创建一张 high 级别压缩表:
CREATE TABLE test5(
id bigint NOT NULL,
name varchar(25) NOT NULL,
quantity numeric(15,2) NOT NULL,
commitdate date NOT NULL,
)WITH (orientation = column, compression = high);
复制代码
如果指定了压缩表,则数据写入时进行压缩存储,数据读取时会自动进行解压,整个过程完全透明,用户无感知。
注:表的压缩级别是创建表时就指定好的,不支持 DDL 变更。
列级别压缩设计
列存表建表时除了可以指定整个表级别的压缩级别外,还支持对某个列单独指定压缩级别,而不依赖整个表的压缩情况,列的压缩级别也分为 high/middle/low/no。
CREATE TABLE test6 (
id bigint NOT NULL,
name varchar(25) encoding(compression=high) NOT NULL,
quantity numeric(15,2) encoding(compression=middle) NOT NULL,
commitdate date encoding(compression=no) NOT NULL,
)WITH (orientation = column, compression = low);
复制代码
列级别压缩中不同字段可指定不同的压缩级别 high/middle/low/no,不用关心整个表的压缩级别,没有单独指定压缩字段的列采用表的压缩级别。
注:每个列的压缩级别是创建表时就确定好的,不支持 DDL 变更。
分区表压缩
因为分区表父表的列属性全部自动被子表继承,因此所有分区表子表的列压缩级别也继承自父表的列属性的压缩级别。而父表的列属性的压缩级别依赖于创建表时用户的指定。
创建父表:
create table order_range(
id int not null,
userid integer,
product text encoding(compression=high),
createdate date not null
) partition by range ( createdate ) with(orientation=column, compression = middle);
复制代码
创建子表:
create table order_range_201701 partition of order_range(id,userid,product, createdate) for values from ('2017-01-01') to ('2017-02-01') with(orientation=column);
create table order_range_201702 partition of order_range(id,userid,product, createdate) for values from ('2017-02-01') to ('2017-03-01') with(orientation=column);
create table order_range_default partition of order_range default with(orientation=column);
复制代码
子表 order_range_201701、order_range_201702、order_range_default 的情况都和父表的一样:所有列只有 product 列是 high 压缩级别,其他所有列都是 middle 压缩级别。
创建父表:
create table order_list(
id int not null,
userid integer encoding(compression=no),
product text encoding(compression=high),
area text encoding(compression=middle),
createdate date encoding(compression=low)
) partition by list( area ) with(orientation=column);
复制代码
创建子表:
create table order_list_gd partition of order_list(id,userid,product,area,createdate) for values in ('guangdong') with(orientation=column);
create table order_list_bj partition of order_list(id,userid,product,area,createdate) for values in ('beijing') with(orientation=column);
create table order_list_default partition of order_list default with(orientation=column);
复制代码
子表 order_list_gd、order_list_bj、order_list_default 的情况都和父表的一样:其中 id 列是 low 压缩级别,userid 列不压缩,product 是 high 压缩级别,area 是 middle 压缩级别,createdate 是 low 压缩级别。
因为父表没有指定 compression 参数,所以默认为 low,id 列没有额外指定,所以默认继承了表的 low 压缩级别。
创建父表:
CREATE TABLE orders_hash (
order_id bigint encoding(compression=no) not null,
cust_id bigint not null,
status text encoding(compression=middle)
) PARTITION BY HASH (order_id) with(orientation=column);
复制代码
创建子表:
CREATE TABLE orders_p1 PARTITION OF orders_hash FOR VALUES WITH (MODULUS 4, REMAINDER 0) with(orientation=column);
CREATE TABLE orders_p2 PARTITION OF orders_hash FOR VALUES WITH (MODULUS 4, REMAINDER 1) with(orientation=column);
CREATE TABLE orders_p3 PARTITION OF orders_hash FOR VALUES WITH (MODULUS 4, REMAINDER 2) with(orientation=column);
CREATE TABLE orders_p4 PARTITION OF orders_hash FOR VALUES WITH (MODULUS 4, REMAINDER 3) with(orientation=column);
复制代码
子表 orders_p1、orders_p2、orders_p3、orders_p4 的情况都和父表的一样:其中 order_id 列是不压缩,cust_id 是 low 压缩级别,status 是 middle 压缩级别。
因为父表没有指定 compression 参数,所以默认为 low,cust_id 列没有额外指定,所以默认继承了表的 low 压缩级别。
创建父表:
create table t_hash_partition(
f1 int,
f2 int encoding(compression=low)
) partition by hash(f2) with(orientation=column, compression = middle);
复制代码
创建子表:
create table t_hash_partition_1 partition of t_hash_partition FOR VALUES WITH(MODULUS 4, REMAINDER 0) with(orientation=column);
create table t_hash_partition_2 partition of t_hash_partition FOR VALUES WITH(MODULUS 4, REMAINDER 1);
create table t_hash_partition_3 partition of t_hash_partition FOR VALUES WITH(MODULUS 4, REMAINDER 2) with(orientation=column);
create table t_hash_partition_4 partition of t_hash_partition FOR VALUES WITH(MODULUS 4, REMAINDER 3)with(orientation='row');
复制代码
子表 t_hash_partition_1、t_hash_partition_3 为列存表,f1 列是继承自父表的 middle 压缩级别,f2 列是 low 压缩级别;
子表 t_hash_partition_2、t_hash_partition_4 为行存表,f1 f2 列不进行压缩(行存表不继承压缩属性);
因为建表时不指定 orientation 参数时,默认为行存格式,所以 t_hash_partition_2 为行存表。
创建父表:
CREATE TABLE orders_mix (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
复制代码
创建子表:
CREATE TABLE orders_mix_p1 PARTITION OF orders_mix FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_mix_p2 PARTITION OF orders_mix FOR VALUES WITH (MODULUS 4, REMAINDER 1) with(orientation=column);
CREATE TABLE orders_mix_p3 PARTITION OF orders_mix FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_mix_p4 PARTITION OF orders_mix FOR VALUES WITH (MODULUS 4, REMAINDER 3) with(orientation=column);
复制代码
子表 orders_mix_p1、orders_mix_p3 为行存表(因为建表时不指定 orientation 参数时,默认为行存格式);
子表 orders_mix_p2、orders_mix_p4 为列存表,因为父表为行表,没有压缩属性所以 orders_mix_p2、orders_mix_p4 表所有列都不会进行压缩。
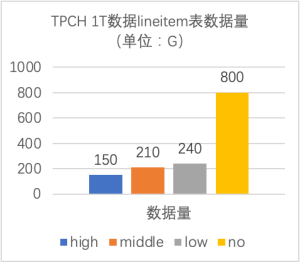
压缩结果测试
针对 TPCH 1T 数据量 lineitem 表在设置为不同压缩级别的测试情况如下:














评论