
Apache Paimon 在同程旅行的探索实践

摘要:本文主要介绍 Apache Paimon 在同程旅行的生产落地实践经验。在同程旅行的业务场景下,通过使用 Paimon 替换 Hudi,实现了读写性能的大幅提升(写入性能 3.3 倍,查询性能 7.7 倍),接下来将分为如下几个部分进行详细介绍:
湖仓场景现状和遇到的问题
遇见 Apache Paimon
Apache Paimon 的应用实践
问题发现和解决
未来规划
一、湖仓场景现状和遇到的问题
随着公司业务发展,实时性业务需求越来越多,2021 年开始逐步调研并引入湖仓架构,结合当时数据湖架构,最终我们选择 hudi 作为湖仓底座。通过内部自研数据集成能力能够一键将内部 base 层的 binglog 数据导入到湖仓内,逐步替代了基于 hive 实时同步,凌晨合并的方式;另外还结合湖上的流读能力,通过增量读的方式将增量结果合并到 DWD 层;以及结合 flink 窗口计算完成了大量实时报表的改造,极大提高了数据时效性,同时也节省了大量批处理合并计算资源。
但是随着任务和场景的增多,基于 hudi 的湖仓逐渐暴露出了一些问题,让我们不得不重新思考湖仓架构,以及后续演进方向。
1.1 湖仓应用现状
目前内部数据湖场景主要应用于以下几个场景:
数据库 base 层入湖,提升 ods 层时效性
利用湖增量能力,构建下游 dwd 层,节省计算资源
利用湖上局部更新能力,构建实时统计视图和报表
利用湖近实时更新能力,构建实时监控场景
整体架构如下:

利用湖仓的各项能力,我们将 ODS 后置批处理时间提前了近 1 小时,同时中间过程的计算存储成本也极大减少。不过同时也遇到了不少问题,在基于 Hudi 湖仓的实践过程中我们遇到的问题主要集中在写入性能,查询性能,资源消耗等方面。
1.2 湖仓写入性能问题
Apache Hudi 提供了两种写入模式 COW 和 MOR,COW 天然存在写入瓶颈,这里主要使用 MOR 类型,为了方便管理,同时开启任务异步 compact(5 个 commit/次)。
虽然 Hudi 使用类 LSM 模式进行数据写入与合并,不过有区别于 LSM 的 SSTable,合并过程全读全写,即使只变更了其中一条数据,也需要整个文件进行读取合并,这就造成 compact 过程需要比较大的内存。尤其当存在热点数据时,任务需要从一开始便保留足够的资源来应对突增的大流量数据,从而造成一定的内存资源浪费。以下是一个 Hudi 入湖任务的资源配比情况:
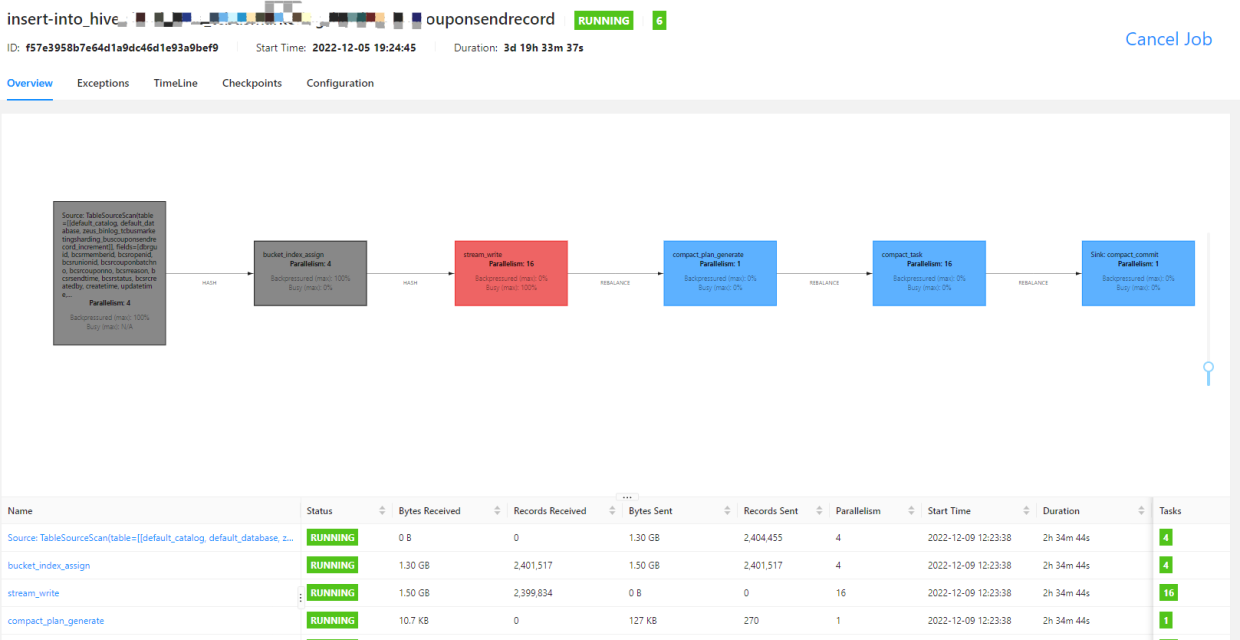
<center>(上图为运行容器数)</center>
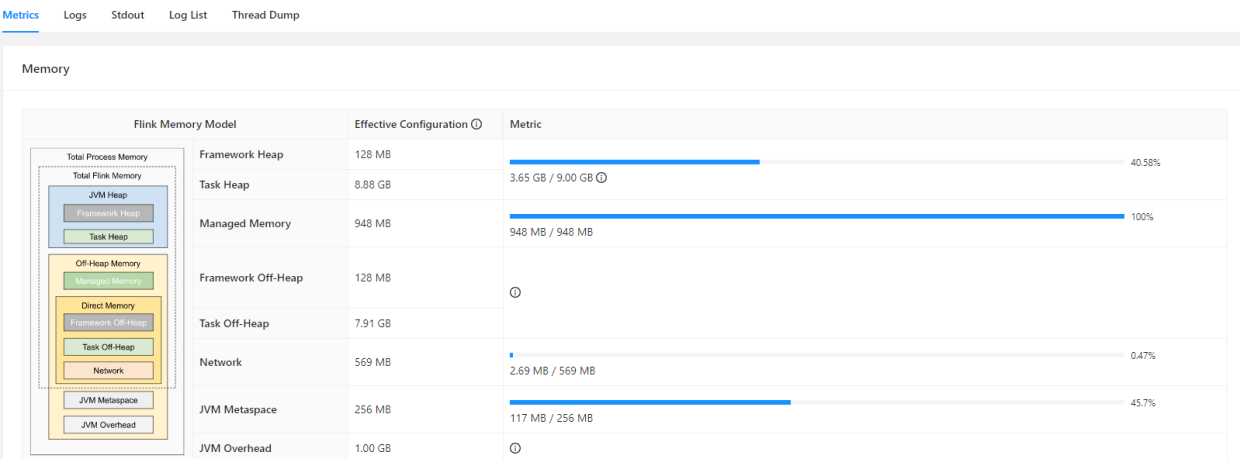
<center>(上图为容器资源配比)</center>
1.3 湖仓查询性能问题
我们主要利用基于表主键的 bucket 索引,因为湖仓做到了近实时,所以带来了更多的点查场景,Hudi 利用分区和主键下推到查询引擎后能够剪枝掉大量的分区和文件,不过单 bucket 内仍然需要 scan 整个文件来定位到具体的主键数据,点查性能略显吃力,结合 MOR 查询时的合并流程(如写入流程所描述)点查性能很难提升,以下是基于 Hudi 的点查,耗时 21s。
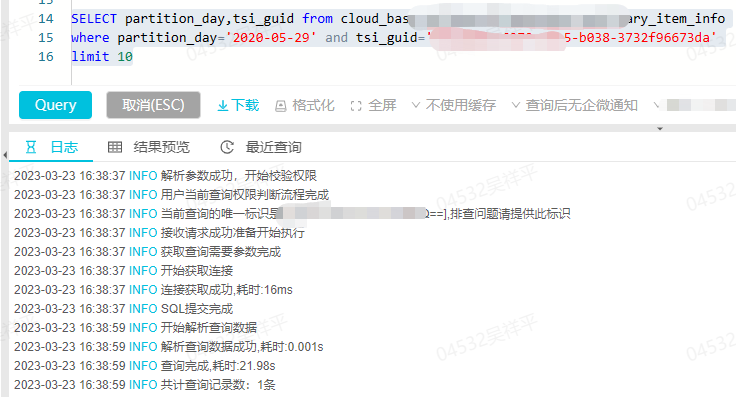
<p><center>(上图为基于 Hudi 的点查耗时情况)</center></p>
最后是写入资源压力,我们的湖仓主要架设在 HDFS 之上,大量上线湖仓任务之后 HDFS 的 IO 压力也逐步升高,这与 Hudi 写入原理有关。
1.4 成本相对较高
实时任务运行资源成本高,Hudi 有较多的调优参数,用户上手成本高,内部推广难,早期 Hudi 与 Spark 强绑定,后期解耦后,Flink 集成出现了不少问题,优化成本高。
综上所述,我们在湖仓场景下面临的问题总结如下:
MOR 类型表写入任务并行度和资源资源配置过高,造成资源浪费
点查性能难以优化,不能很好的满足需求
由于合并带来的存储 IO 压力变大
二、遇见 Apache Paimon
彼时还叫 Flink Table Store,如今成功晋升为 Apache 孵化项目 Apache Paimon,官网地址:Apache Paimon,首次接触在 FLIP-188: Introduce Built-in Dynamic Table Storage - Apache Flink - Apache Software Foundation 中,就被基于原生 LSM 的写入设计以及 universal compaction 深深吸引,便持续关注,在 0.2 版本发布后我们开始接入测试使用。
2.1 Apache Paimon 简介
Apache Paimon(incubating) is a streaming data lake platform that supports high-speed data ingestion, change data tracking and efficient real-time analytics
Apache Paimon 是一款支持高吞吐数据摄入,变更跟踪,高效分析的数据湖平台。以下是官网的架构图
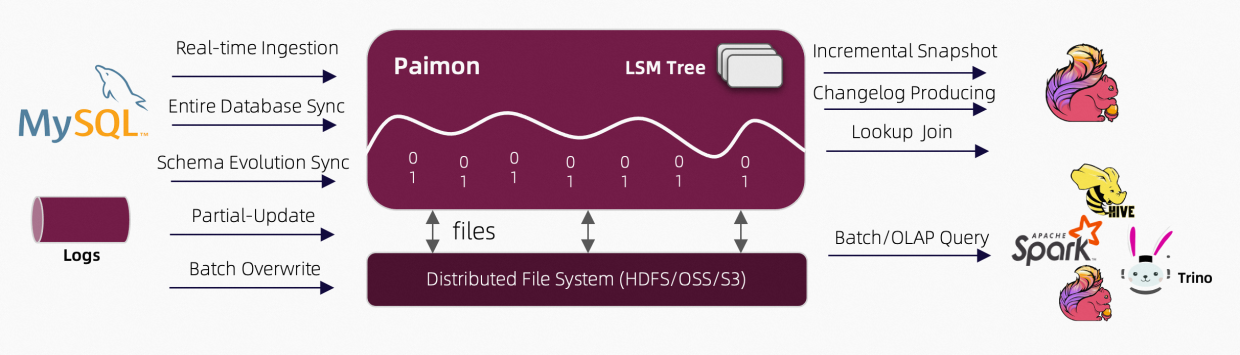
Apache Paimon 底层存储利用 LSM 结构,支持多分布式存储系统,且兼容当下所有主流的计算引擎(Flink,spark,hive,Trino),文件结构组织类似 Iceberg,相对 Hudi 来说更加简单和容易理解:
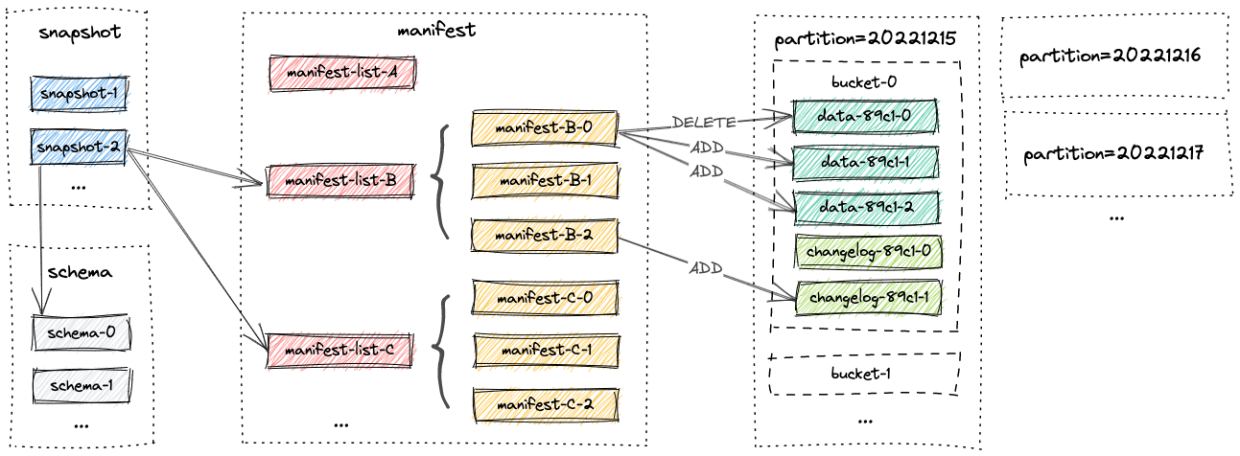
同时涵盖了湖技术目前我们特别关注的几大特性:
近实时高效更新
局部更新
增量流读
全增量混合流读
多云存储支持
多查询引擎支持
特别的 Lookup 能力
CDC 摄入(进行中)
结构演进(进行中)
2.2 基于 Apache Paimon 优化效果
写入性能和资源消耗方面,相同的表(均开启异步 Compact)基于 Apache Paimon 的资源使用情况如下:
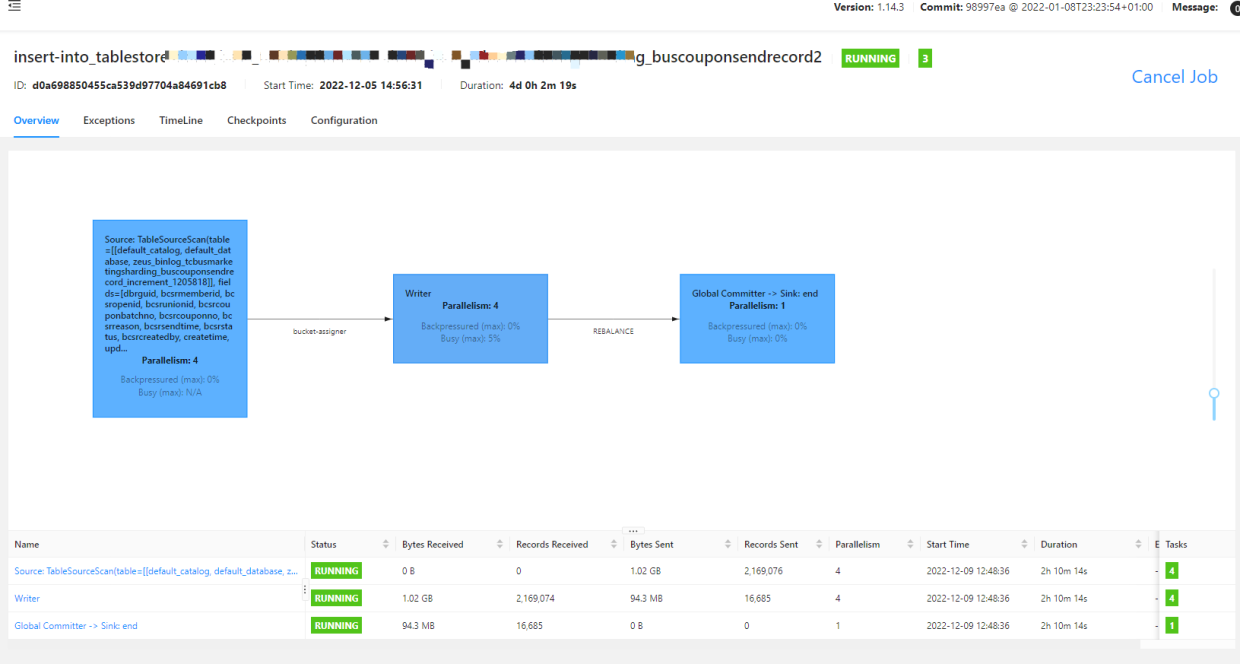
<p><center>(上图为 Apache Paimon 写入容器数)</center></p>
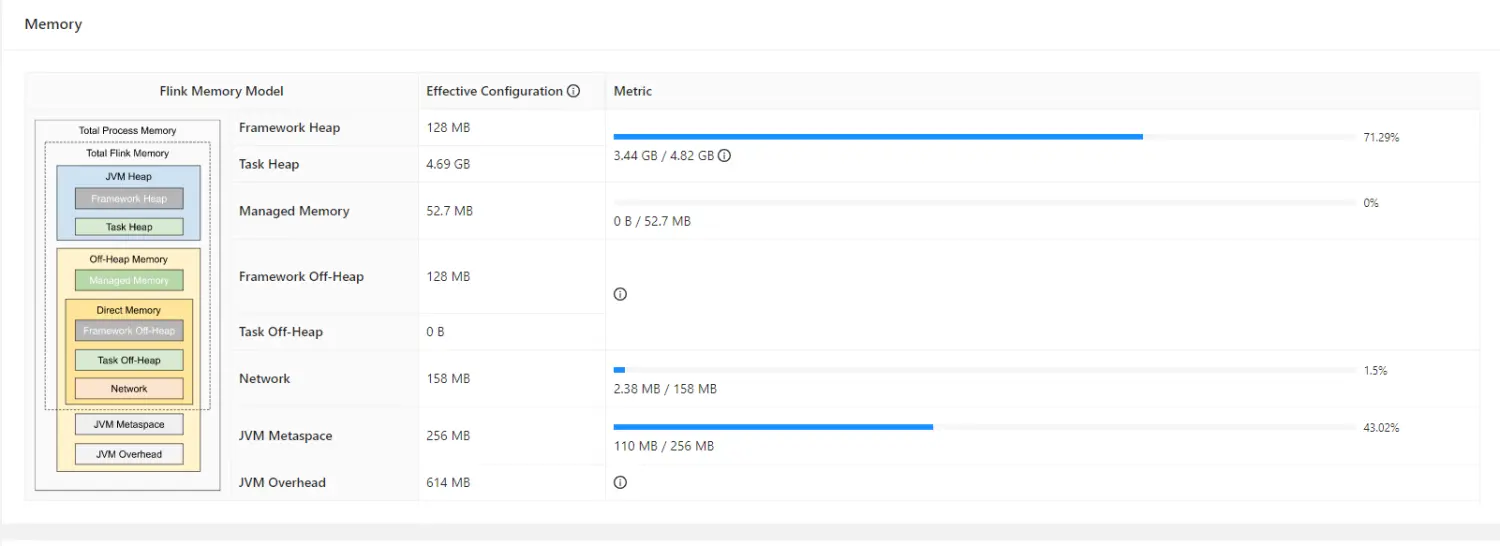
<p><center>(上图为 Apache Paimon 写入资源配比)</center></p>
在不降低写入性能的情况下 Apache Paimon 使用了更少的容器数和更低的资源配比。这得益于 SortRun 和 Universal-Compaction 策略的写优化能力,Upsert 效率相对 Hudi MOR 也有较大提升,如下 Flink 配置的情况下:
Upsert 4 亿数据,800 个分区(实际效果与集群性能相关与时间段相关,大概做个参考)的场景下, 使用 Apache Paimon 总共耗时 3 小时左右,而 Apache Hudi MOR 需要耗时 10 小时左右。
再来看下点查性能
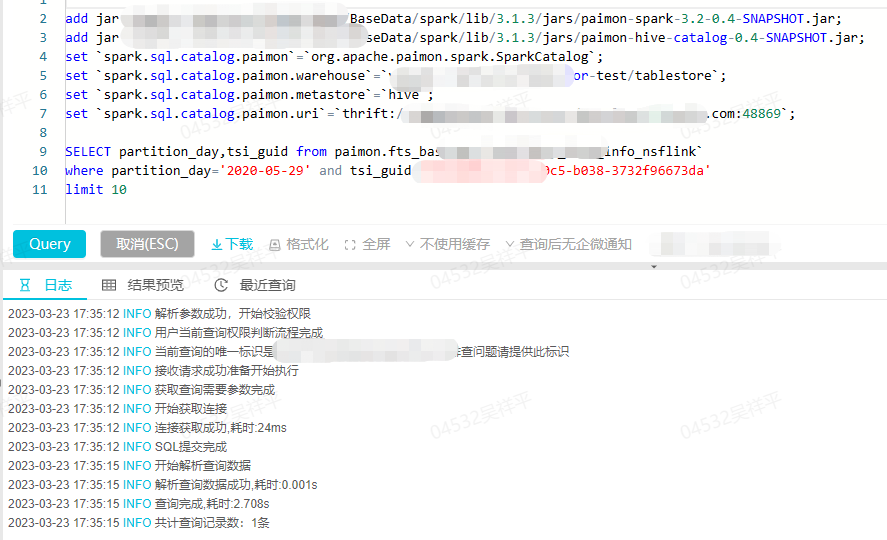
相同的条件下 Apache Paimon 只需要 2.7 秒,对比 Hudi 21 秒提升巨大。性能提升的主要原因在于有序的存储结构能够在数据检索时快速定位和减少 Scan 数量。
目前我们上线了部分场景的应用,大批量上线之后再观察 HDFS IO 压力情况。
三、Apache Paimon 的应用实践
目前我们在内部数据集成中加入了 Paimon 的支持,同时将多个场景切换到了 Paimon,主要包括 Binglog 集成,Partial Update 准实时宽表,以及 Append Only 场景。
3.1 Paimon 的自动化数据集成
我们通过集成平台屏蔽了用户对 binglog 的感知,通过一键的方式完成底层 Base 表全量+增量的同步功能,大致流程如下:
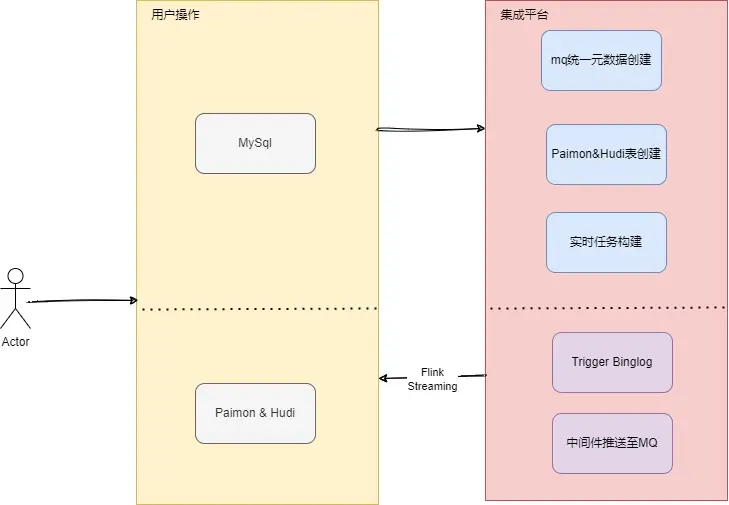
用户更加关注他们所熟悉的 Mysql 以及我们的最终湖仓表,大致集成界面如下:
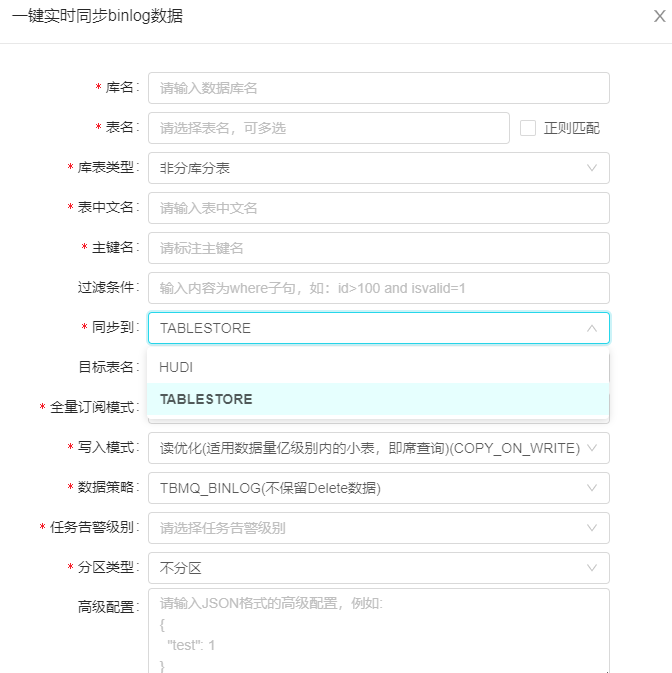
<center>注:Paimon 原名 Flink Table Store</center>
同时我们为了将 Hudi 表迁移到 Paimon 之中,小数据量的我们直接通过重做的方式,而大数据量会通过 Flink 批量导入方式进行初始化,经过测试,4 亿左右的表只需要不到 20 分钟即可导入完成,大致导入配置如下:
另外我们的集成环境和监控针对 Paimon 也进行了一系列优化:
根据表数据量来制定特定参数,使用户无感知
调整分区策略和资源,优化大量随机写情况
构建监控大盘,时刻关注任务运行情况,时刻维持任务正常运行和资源分配的一个平衡点
3.2 基于 Partial Update 的准实时宽表
准实时是介于离线和实时之间,其中准实时宽表是一个常见的案例,主要用来支持 Ad-Hoc Query。在准实时场景下,主要存在如下特点和挑战:
通过微批调度(分钟,小时)进行数据更新,但是延迟相对较高
通过流式引擎构建,则会存在保留大量状态造成资源严重浪费的情况
Paimon 提供了 Partial Update 的功能,可通过 Merge-Engine 参数来指定:
Partial Update 的特点:
结果表字段由多个数据源提供组成,可使用 Union All 的方式进行逻辑拼接
数据在存储层进行 Join 拼接,与计算引擎无关,不需要保留状态,节省资源
具体案例如下:
案例实践:数据写入
3.3 AppendOnly 应用
除了 Binlog 数据源,还有大量日志、埋点相关的 AppendOnly 数据源,这类数据基本都是数据量非常大的存在,一般来说,这类数据都是直接消费落在分布式文件系统上的。
当我们采用 Paimon 来构建 AppendOnly 表时,数据不仅可以实时写入,还可以实时读取,读写顺序一致,而且实时资源消耗也降低了不少完全可以替换部分消息队列的场景,达到解耦和降本增效的效果。SQL 如下:
写入效果如下:
四、问题发现和解决
4.1 Spark 跨 Warehouse 查询能力调整
当前 Hive Catalog 主要基于 Warehouse 路径组装 Paimon 表路径,在 Spark 环境内声明 Warehouse 之后不太容易跨 Warehouse 进行多 Paimon 表的查询。内部我们重载了 HiveCatalog 的 getDataTableLocation 方法,基于 Hive 表构建 Paimon 表路径
同时也增加了构建 Hive 外部表的能力,[FLINK-29922] Support create external table for hive catalog
4.2 大量分区 + Bucket 场景下 Flink 批读超过 Akka 消息限制优化
实践过程中如果发现类似以下错误,可以适当调大 Flink 中的akka.framesize参数,默认 10M。
最终通过加入分批次 Split 方式进行解决,[flink] Assign splits with fixed batch size in StaticFileStoreSplitEnumerator ,效果如下:

4.3 流读场景下,并行度分配不合理以及基于时间戳读取过期时间报错的问题
目前跟进中,[Feature] Some problems with stream reading
五、未来规划
完善 Paimon 平台分析等相关生态
基于 Paimon 的流式数仓构建
推广 Paimon 在集团内部的应用实践
替换部分消息队列的场景
Reference:
Apache Paimon 官网:https://paimon.apache.org/
Piamon Github:https://github.com/apache/incubator-paimon
基于 Apache Flink Table Store 的全增量一体实时入湖:https://www.jianshu.com/p/ac2ba73367fe
Flink Table Store 0.3 构建流式数仓最佳实践:https://juejin.cn/post/7207659644486959163
作者简介:
吴祥平:同程旅行大数据计算组负责人,Apache Hudi & Paimon Contributor,对流计算和数据湖技术充满热情
曾思杨:同程旅行公共 BI 数据开发,热爱流计算和数据湖技术及其实际应用
更多内容


活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:99 元试用 实时计算Flink版(包年包月、10CU)即有机会获得 Flink 独家定制卫衣;另包 3 个月及以上还有 85 折优惠!了解活动详情:https://www.aliyun.com/product/bigdata/sc

版权声明: 本文为 InfoQ 作者【Apache Flink】的原创文章。
原文链接:【http://xie.infoq.cn/article/8be6edf15d7ea5aa2dd98056f】。文章转载请联系作者。

Apache Flink 中文社区 2020-04-29 加入
官方微信号:Ververica2019 微信公众号:Apache Flink 微信视频号:ApacheFlink Apache Flink 学习网站:https://flink-learning.org.cn/ Apache Flink 官方帐号,Flink PMC 维护









评论