
深入分析与解决方案:缓存与数据库双写不一致问题
key 重建优化
开发人员通常使用“缓存+过期时间”的策略,以便既能加速数据读写,又能确保数据的定期更新。这种模式基本上能够满足绝大部分需求。然而,当以下两个问题同时出现时,可能会对应用系统造成严重的影响:
热点 key 的出现:当前的 key 是一个热点 key,例如一条热门的娱乐新闻,导致并发请求量非常大。这种情况会使得缓存的读取请求集中在这个热点 key 上,造成缓存的压力显著增加。
缓存重建的复杂性:当缓存失效后,重建缓存的过程不能在短时间内完成。重建缓存可能涉及复杂的计算任务,例如执行复杂的 SQL 查询、多次 I/O 操作、以及处理多个数据依赖等。这种复杂的重建过程可能会导致系统性能下降,进而影响用户体验。
在缓存失效的瞬间,如果大量线程同时启动缓存重建操作,会导致后端负载急剧增加,甚至可能使应用系统崩溃。这种情况会显著影响系统的稳定性和性能。为了解决这一问题,关键在于避免大量线程同时进行缓存重建。
一个有效的解决方案是使用互斥锁机制,该方法确保在任何给定时刻只有一个线程被允许执行缓存重建操作。其他线程则需要等待重建线程完成缓存重建后,才能从缓存中重新获取数据。这种策略不仅能减轻后端系统的压力,还能避免因并发重建引起的性能瓶颈,显著提升系统的稳定性和响应速度。
示例伪代码:
缓存与数据库双写不一致
在高并发场景下,同时进行数据库与缓存的操作可能会引发数据不一致性的问题。具体来说,当多个线程或进程同时尝试更新缓存和数据库时,可能会导致缓存与数据库之间的数据不匹配。
双写不一致情况
当多个线程或进程同时进行缓存和数据库的更新时,可能出现以下问题:
缓存与数据库的数据不一致:例如,两个线程同时更新数据库,但只一个线程更新了缓存,这会导致缓存中的数据和数据库中的数据不一致。
延迟问题:即使在更新缓存和数据库时都执行了操作,也可能由于网络延迟或其他因素,导致缓存和数据库之间的状态不同步。
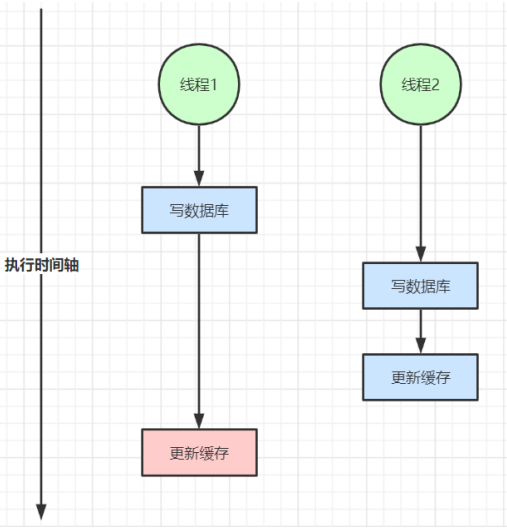
读写并发不一致
读写并发不一致是指在并发场景下,多个线程或进程对同一数据进行读写操作时,可能导致数据的不一致或错误。
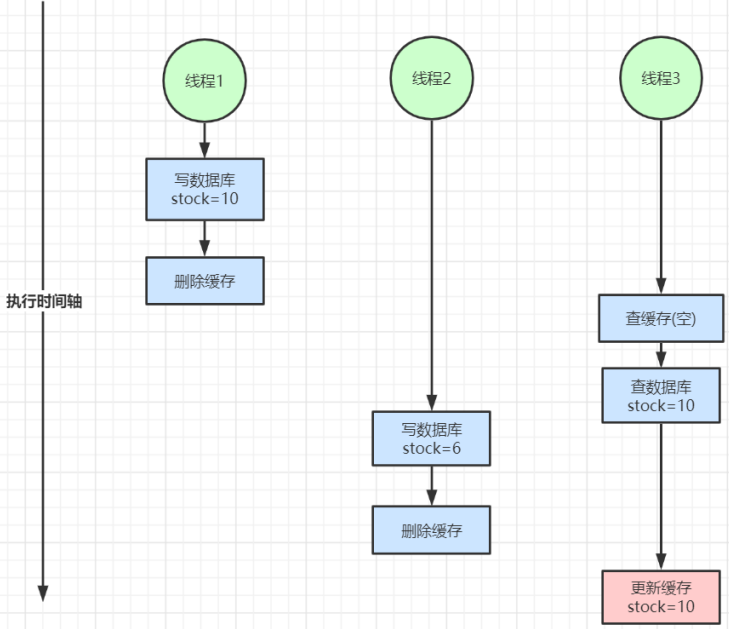
以下是一些常见的读写并发不一致的解决方法:
1、针对并发几率较小的数据:
对于个人维度的订单数据、用户数据等,并发操作较少且对数据一致性的要求相对宽松。对于这类数据,可以通过设置缓存的过期时间来解决缓存与数据库之间的数据不一致问题。具体做法是,在缓存中设置合理的过期时间,缓存数据会在过期后自动失效。每当缓存失效时,系统将自动从数据库中读取最新的数据,并更新缓存。这种策略简单有效,可以大大减少缓存不一致的发生几率。
2、在并发较高的场景下的缓存数据一致性:
即使在业务场景下并发较高,但如果可以容忍短时间的缓存数据不一致(例如商品名称、商品分类菜单等),则仍然可以通过设置缓存的过期时间来满足大部分业务需求。通过合理设置过期时间,虽然缓存数据可能会在短时间内出现不一致,但这种不一致通常不会对业务造成严重影响。因此,缓存过期策略仍然是一种有效的解决方案。
3、对于不能容忍缓存数据不一致的场景:
如果业务对缓存数据的一致性有严格要求,可以使用分布式读写锁来保证并发读写操作的顺序性。具体做法是,在进行写操作时,通过分布式锁机制来确保只有一个操作能够执行,从而避免写写冲突。而对于读操作,通常可以在不加锁的情况下进行,以提高性能。分布式锁能够有效地控制并发写操作,确保数据的一致性,尽管可能会对系统性能产生一定影响。
4、引入中间件以维护数据一致性:
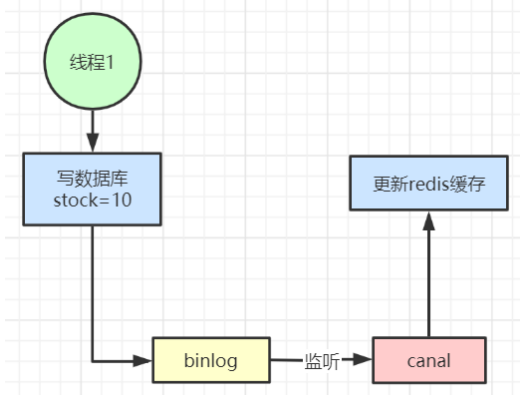
可以使用阿里开源的 Canal 工具,通过监听数据库的 binlog 日志来及时更新缓存。这种方法可以在数据发生变化时自动更新缓存,从而减少缓存和数据库之间的一致性问题。然而,引入 Canal 或类似的中间件会增加系统的复杂度,因此需要权衡其带来的额外复杂性和对系统一致性的增强。使用这种方案时,应考虑中间件的维护、配置和潜在的性能影响,以确保系统的稳定性和可靠性。
总结
上述解决方案主要针对的是读多写少的场景,通过引入缓存来提升性能。然而,对于写多读多且不能容忍缓存数据不一致的情况,我们需要重新考虑缓存的使用策略。以下是针对这种情况的优化建议:
1、避免使用缓存:
在写操作频繁且读操作也较多的场景中,如果业务对数据一致性的要求非常高,使用缓存可能并不是最佳选择。此时,直接操作数据库可以避免缓存数据与数据库数据之间的不一致问题,因为所有的数据操作都直接在数据库中进行,从而确保数据的一致性和准确性。
2、数据库作为主存储:
如果数据库面临着高负载的压力,但仍然需要处理大量的读写操作,可以考虑将缓存作为数据的主存储,而将数据库作为备份。具体做法是:所有的读写操作都先写入缓存,缓存会异步地将数据同步到数据库中。这样,缓存可以在高并发读写操作中提供快速的响应,而数据库则用于长期的数据存储和备份。这种策略可以提高系统的读写性能,同时保持数据库的数据完整性。
3、缓存适用的数据类型:
将缓存用于对实时性和一致性要求不是特别高的数据。例如,商品分类信息、系统配置等数据可以缓存,因为这些数据变化频率较低,对一致性要求不是很高。缓存能显著提升访问速度,但在数据不一致的情况下,对业务影响较小。避免将缓存用于对一致性要求极高的关键业务数据,以减少因缓存引发的复杂性和风险。
4、避免过度设计:
在设计缓存系统时,要避免为了保证绝对一致性而进行过度设计和复杂控制。这种过度设计不仅会增加系统的复杂性,还可能影响系统的性能。应当根据实际业务需求,合理选择缓存策略,平衡性能和一致性要求,避免不必要的复杂性和资源浪费。
总之,在选择是否使用缓存及其设计时,需要根据业务场景和数据一致性要求进行权衡。缓存应主要用于提升读操作性能,而对于写多读多且对一致性要求高的场景,可能需要依赖数据库本身的能力或采用其他策略来处理数据的一致性问题。
文章转载自:努力的小雨

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论