
详解 GaussDB(DWS) 中的行执行引擎
1.前言
GaussDB(DWS)包含三大引擎,一是 SQL 执行引擎,用来解析用户输入的 SQL 语句,生成执行计划,供执行引擎来执行;二是执行引擎,其中包含了行执行引擎和列执行引擎,执行引擎即查询的执行者,位于优化器和存储引擎之间,负责将数据从存储引擎中读取出来,并根据计划将数据处理加工后返回给客户端,执行引擎的目标是为了更好地利用计算资源,更快地完成计算。三是存储引擎,决定了数据库数据的存取方式,直接影响了数据库的读写性能。
其中行执行引擎应用于行存表中,传统的 OLTP(OnLine Transaction Processsing 联机事务处理)场景与功能、业务强相关,数据需要进行频繁的增删改查,这时比较适合使用行存储式。行存储的优势主要有两个方面:首先是点查性能好,在点查场景下可以直接索引到某行数据的元组位置;其次就是更新效率高,行存储在实时并发入库,并发更新方面依然有着比较大的优势。行执行引擎的关键就是:一次处理一行数据,即一 tuple,适合数据频繁更新,增删改操作多,且查询结果涉及表的多列的场景。
2.行执行引擎组成
2.1 行执行框架
行执行引擎的执行基本单位是算子,查询计划是以树的形式存在的,算子是执行树上的每个节点。每个算子需要经历初始化,执行,清理的生命周期,执行时包括递归遍历计划树的各个节点,从计划树根节点开始,递归到叶节点来获取一个 tuple,经过逐层节点算子的处理,返回一个结果 tuple,直到再无 tuple。整体算子的执行采用 Piepline 模式,一次一 tuple,控制流从上到下,数据流由下到上,图示实线为控制流,虚线为数据流,使用上层来驱动下层。
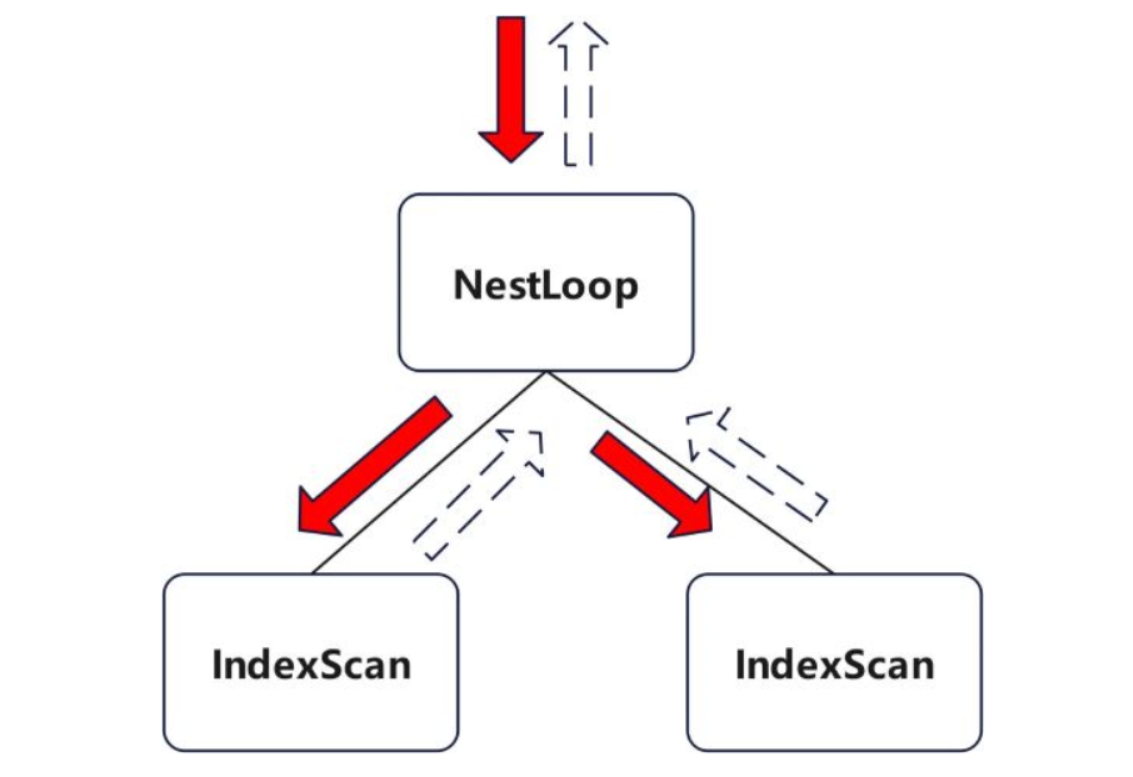
2.2 行执行引擎算子
算子总共分为四类,扫描算子,控制算子,物化算子,连接算子等。对于分布式系统而言,还包括着 stream 算子等。
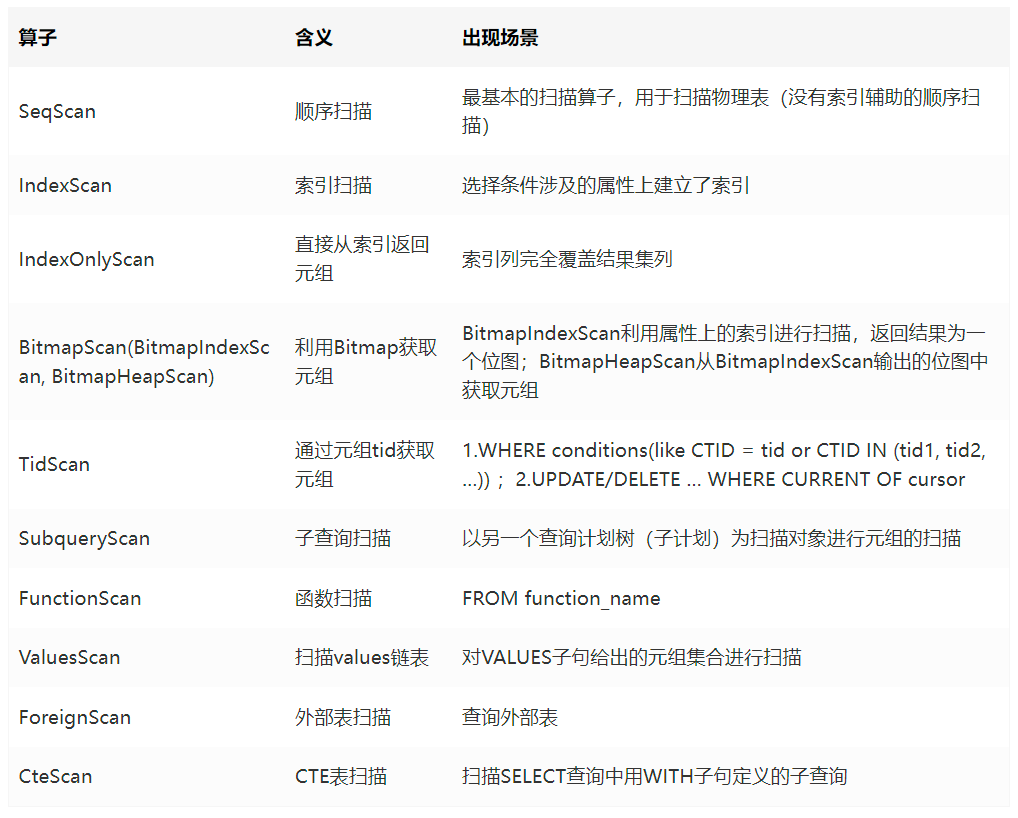
2.2.1 扫描算子
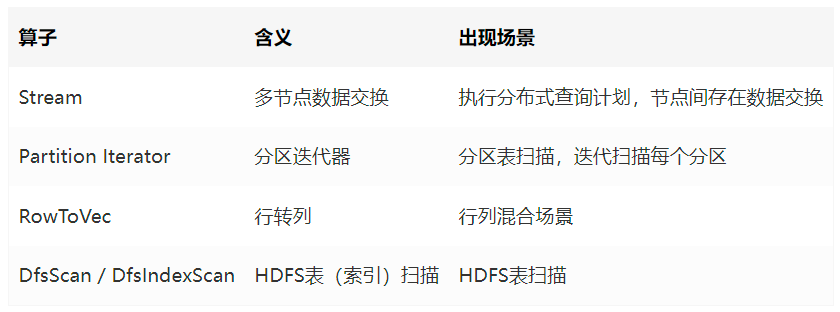
扫描算子用来扫描表中的数据,每次获取一条元组作为上层节点的输入, 存在于查询计划树的叶子节点,它不仅可以扫描表,还可以扫描函数的结果集、链表结构、子查询结果集。一些比较常见的扫描算子如表所示。
2.2.2 连接算子
连接算子对应了关系代数中的连接操作,以表 t1 join t2 为例,主要的集中连接类型如下:inner join、left join、right join、full join、semi join、 anti join,其实现方式包括 Nestloop、HashJoin、MergeJoin;

三类连接算子的实现方式特点:

2.2.3 物化算子
物化算子是一类可缓存元组的节点。在执行过程中,很多扩展的物理操作符需要首先获取所有的元组才能进行操作(例如聚集函数操作、没有索引辅助的排序等),这是要用物化算子将元组缓存起来;

2.2.4 控制算子
控制算子是一类用于处理特殊情况的节点,用于实现特殊的执行流程。
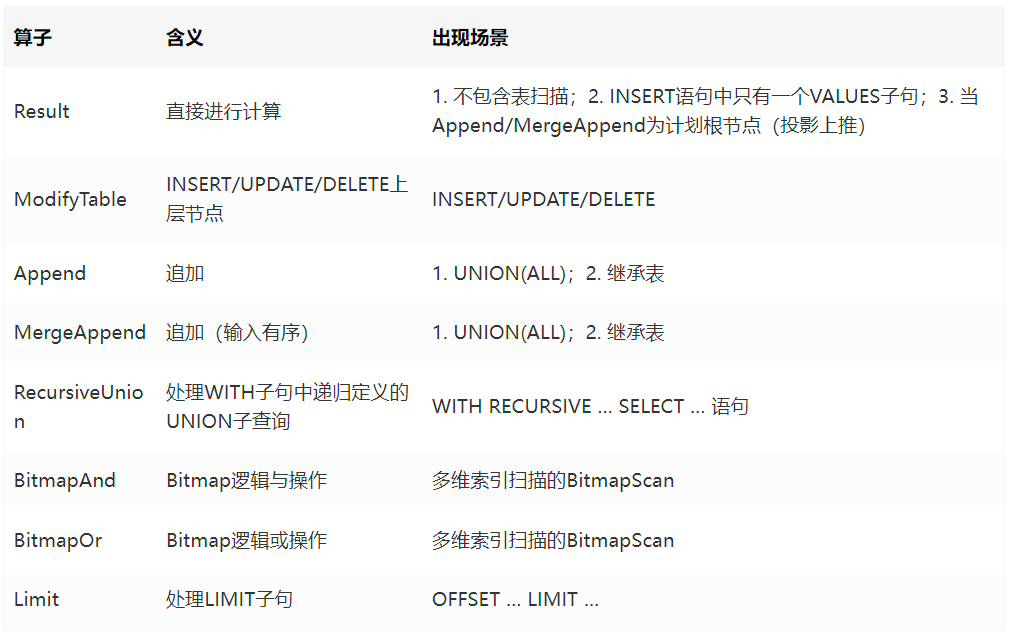
2.2.5 其他算子
其他算子包括 Stream 算子,以及 RemoteQuery 等算子
Stream 算子主要有三种类型:Gather stream、Broadcast stream、Redistribute stream
Gather 算子: 每个源结点都将其数据发送给目标结点进行汇聚
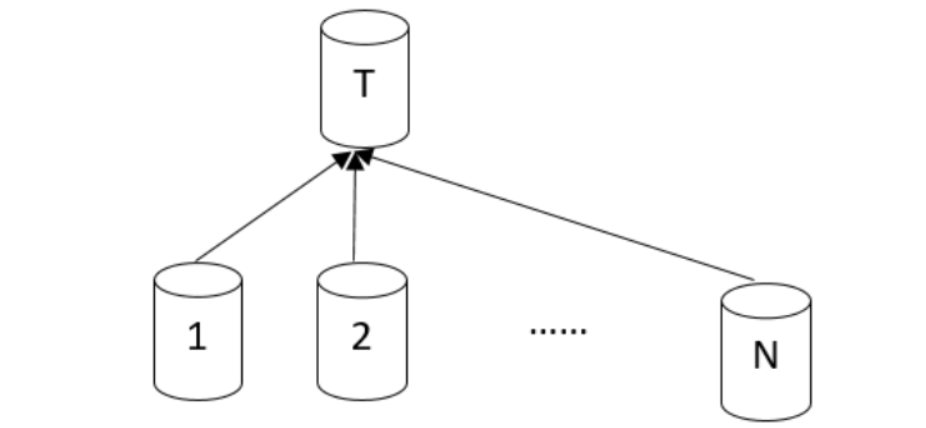
Broadcast stream: 由一个源节点将其数据发给 N 个目标节点进行运算
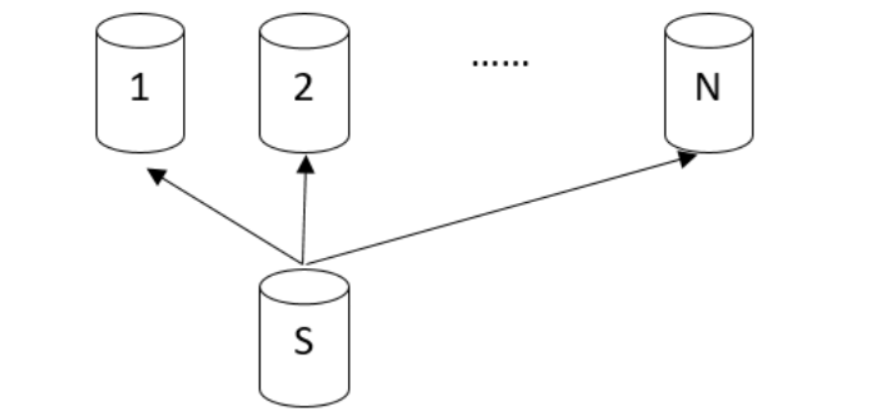
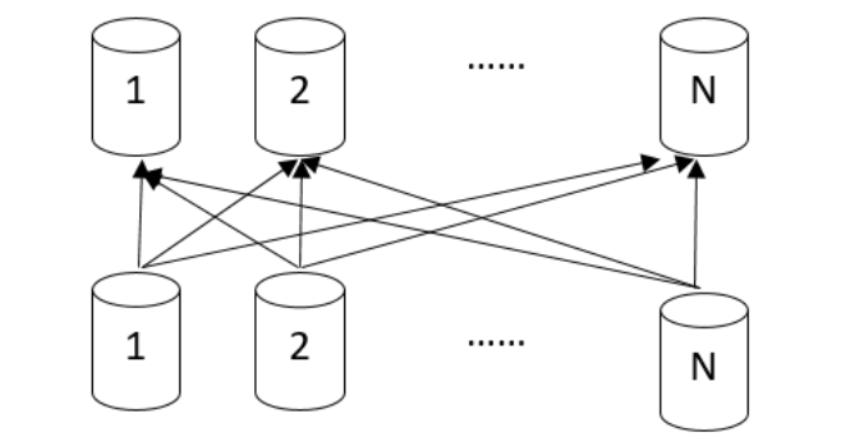
Redistrubute stream: 每个源节点将其数据根据连接条件计算 Hash 值,根据重新计算的 Hash 值进行分布,发给对应的目标节点
3. 执行框架总结
本文主要讲解了如下几个方面:
大致介绍了 GaussDB(DWS)行执行引擎在整个数据库系统中的位置;
介绍了行执行引擎的框架;
最后介绍了一些常见和常用的行执行引擎相关的算子。
文章转载自:华为云开发者联盟

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论