
基于数据驱动 U-Net 模型的大气污染物扩散快速预测,提升计算速度近 6000 倍

项目背景
当前,常见的大气污染预测模型大多是基于物理机理构建的,比如空气质量预测模型 Calpuff、AERMOD、CMAQ 等。然而,这些模型运算较为复杂,对于输入数据的要求非常高,运算耗时也比较长,适合用于常规固定区域的预报。当遇到突发污染事件时,就无法有效发挥作用。
针对以上问题,本项目以某城区 3km*3km 范围的固定模拟区域,根据污染物扩散模型,快速计算任意释放点源和任意风向的污染物扩散动图,并进行精度评估。仅利用城市局部污染物扩散云图作为输入,使用深度学习模型提取图像中污染物扩散的特征,纯数据驱动,无需建立物理模型,预测耗时短,适合作为突发污染扩散事件时的应急处置决策辅助。
项目需求
课题名称
基于数据驱动的污染物扩散深度学习模型案例
课题需求
外部单位提供数据集,总数据集详细描述:120 个动图数据(3 个风速*5 个释放源点位 * 8 个风向)。选取其中任意 1 个动图的数据,基于数据驱动类模型(模型不限制)提取数据特征,得到污染物扩散模型,可对污染物扩散进行预测。
项目地址
https://aistudio.baidu.com/aistudio/projectdetail/5663515
实现过程
数据集
我们选择了风速 15m/s,风向正北,Pos_0 作为污染源释放点的动图数据,数据来源于某城区 3km*3km 范围的固定区域内污染物扩散 CFD 模拟结果(南京欧帕提亚公司提供),共 745 秒 148 张污染物浓度云图,两张图片时间间隔 5 秒。
基于飞桨 2.4.0 的开发环境,在对动图解压之后,我们发现动图解压得到的 181 张静态图片中第 148 张之后的图片存在明显的图像抖动。我们采用了基于 Harris 角点检测的图像对齐算法进行处理,但是图像抖动没有得到完全消除。为了保证模型输入数据的质量,我们丢弃了第 148 张之后的静态图片。
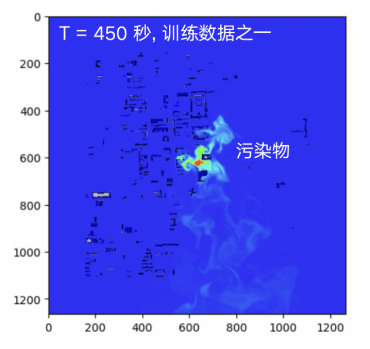
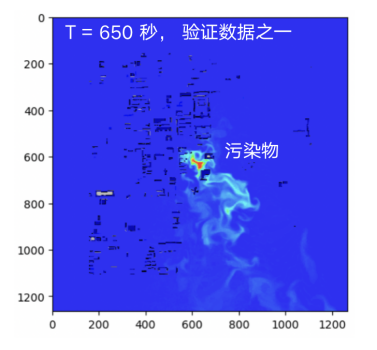
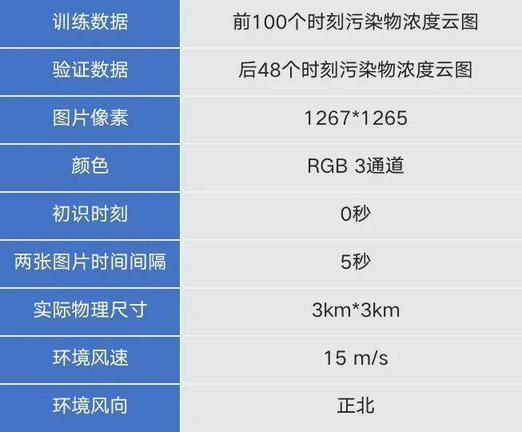

图 1 原始数据
U-Net 网络模型
网络模型如图 2 所示,其由 3 个 Encoder/Decoder、9 个卷积 Conv、9 个反卷积 Conv-T 组成,约 30 万个训练参数。之所以选择 U-Net,是因为该网络在图像分割和目标识别中应用广泛,污染物扩散模式学习可以看作是一种动态的目标识别任务,只不过目标的形态比较抽象;另一个原因是 U-Net 的代码实现较简单,短时间内可以完成网络的搭建。

图 2 U-Net 网络图
核心代码
训练
训练时输入数据为上一时刻的污染物云图,输出为预测的下一时刻的污染物云图。当前的训练 batch-size 为 1,即只预测下一时刻的污染物扩散情况。训练时,每 10 个 epoch 保存一次模型,防止训练意外中断时模型参数丢失。
预测
预测时,输入测试数据某时刻的污染物扩散云图,预测下一时刻的污染物扩散情况。测试函数中 supervise 这个 flag 为后续连续预测多个时刻的数据预置了接口。目前 supervise 置为 true,当模型预备连续预测多个时刻数据时,测试时将 supervise 置为 false。
项目成果
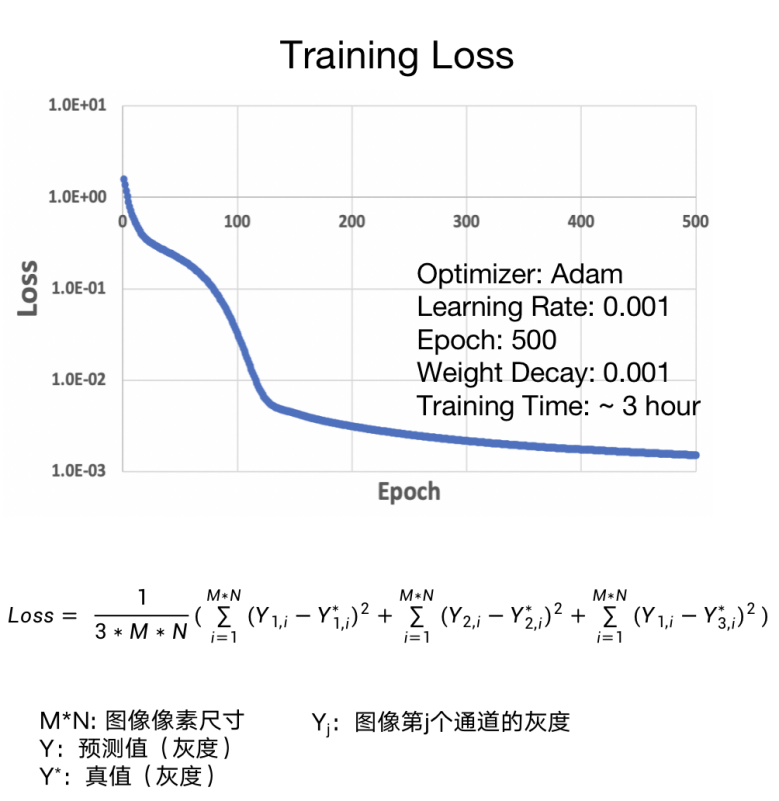
图 3 计算函数损失值
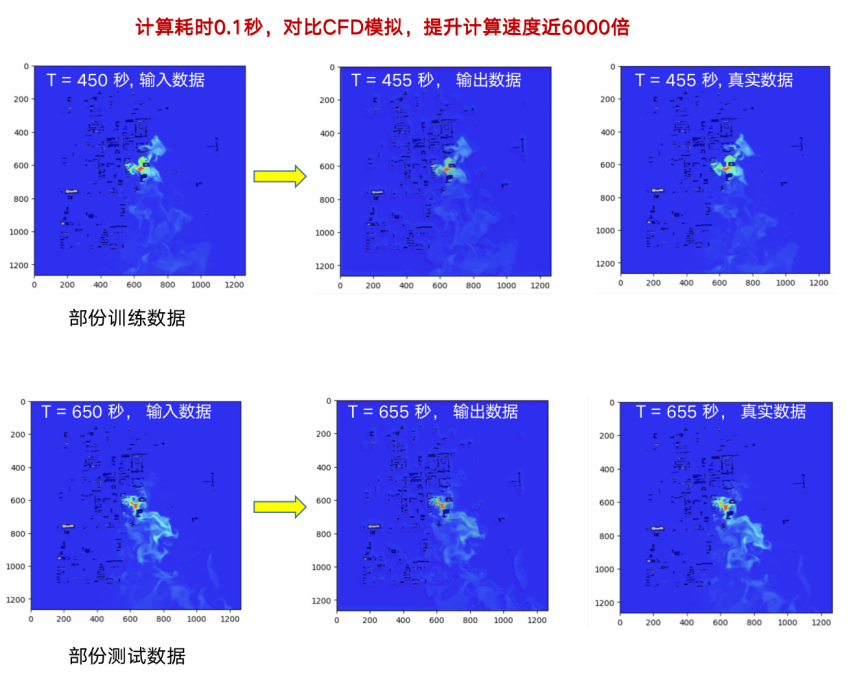
图 4 对比 CFD 模拟参数对比
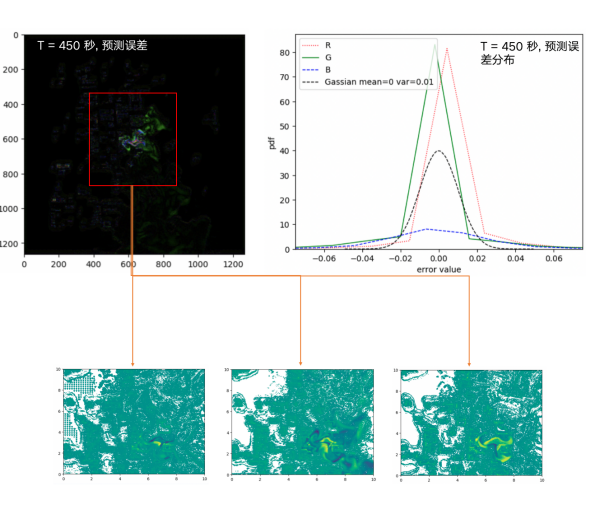
图 5 残差值对比
如图 5 所示,浓度误差主要集中在污染源附近(如图红色框),主要数值分布在-0.02~0.02 之间。不同颜色分别代表不同浓度区间误差,蓝色表示的低浓度相对误差较小,绿色红色表示的中高浓度误差平均误差较高,绿色区域表征的中等浓度区域,偏大的误差影响的面积较大。
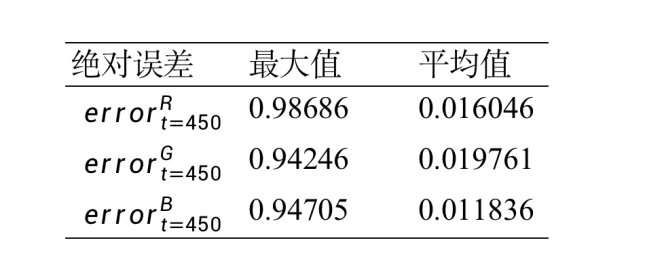
图 6 数值对比
未来发展方向
预测能力方面
基于前一时刻的污染物浓度云图,预测后十个时刻、二十个时刻,四十个时刻的污染物浓度云图;
尝试用多时刻预测多时刻。
网络方面
尝试引入更先进的网络架构,如 transformer;
对于网络层数和每层网络的神经元个数,尝试进行敏感性分析和误差分析;
尝试引入更多种类的激活函数如 tanh,silu 等;
尝试对 learning rate、batch size 等超参数进行调整实验。
物理原理方面
尝试引入物理先验知识,对建筑、边界位置施加 loss 软约束;
尝试利用流体 NS 方程对模型进行修正。
模型方面
尝试引入更多参数作为输入:如污染源位置、污染源初始浓度等提高模型的适应能力;
增加模型参数量级,探索大模型对复杂多态问题的处理能力;
尝试和传统流体求解方法进行融合。
项目意义与心得
本项目尝试用 U-Net 网络通过污染物扩散云图来学习污染物扩散的模型参数,对污染物扩散进行快速预测,是数据驱动计算场景拓展的一次探索。从项目结果来看,模型计算速度相比 CFD 模拟提升明显,但是模型预测的效果还有待提升,未来将通过探索以上几个方向,不断优化模型预测效果。项目实现过程中,我们花费了大量的时间处理背景存在抖动的图像,直到后来发现有一部分数据集的质量要远远好于另一部分,我们选择放弃质量不好的数据,从而加快了项目的进展。
数据处理过程中有以下几个方面的心得。
第一,对项目的数据应该第一时间进行全局探索,了解数据的全貌,对数据质量进行评估;
第二,与其花费大量的时间处理质量不好的数据,不如先使用质量较好的数据,优先做对模型取得进展更加关键的事情;
第三,相对于改变模型的结构,提高输入数据的质量对模型的训练结果起到更加积极的作用。一些开源模型的效果无法复现的原因在于训练数据的不公开,即便大家都用到同样结构的网络,但是训练数据不同,模型取得的效果就大不相同。从这个角度看,模型参数是训练数据在网络上留下的压缩信息,训练数据存在的瑕疵很难通过优化网络来解决。
飞桨 AI for Science 共创计划为本项目提供了强大的技术支持,打造活跃的前瞻性的 AI for Science 开源社区,通过飞桨 AI for Science 共创计划,学习到了如何在飞桨平台上使用科学计算的 AI 方法去解决 CFD 模拟预测的问题,并且大幅度提高了数据驱动计算的速度。相信未来会有越来越多的项目通过 AI for Science 共创计划建立产学研闭环,推动科研创新与产业赋能。
相关地址
飞桨 AI for Science 共创计划
https://www.paddlepaddle.org.cn/science
飞桨 PPSIG-Science 小组
https://www.paddlepaddle.org.cn/specialgroupdetail?id=9
飞桨 PaddleScience 工具组件
https://github.com/PaddlePaddle/PaddleScience

还未添加个人签名 2022-12-26 加入
还未添加个人简介









评论