
大前端 CPU 优化技术 --SIMD 技术

近几年随着边缘计算(Edge Computing)、端算力、端智能、异构运算等技术的运用井喷式涌现出来,越来越多的人更重视端上的计算处理能力。端上的 AI 识别能力,图像处理,视频处理等都需要大量的计算才能带来更好的效果,各个大厂作为行业引领者也在相关优化技术上不断的进行探索,硬件厂商也不断的对硬件本身的算力做突破。
端运算相比云计算能带来更优的实时性,更好的安全性,更全的个性化服务。但是端上本身受限于芯片的面积、功耗、散热等因素,移动端上的处理器的性能远低于服务器端处理器的性能,几年前看到过一些基础的数据测试结果,差距不是一般的大,除了本身处理器自身能力的原因,集成化也是个很大的问题,手机多以 soc 形式存在,并行处理、协作等都是有损耗的。当然不仅只是处理器的问题,在端上还有内存、存储空间、网络带宽等诸多限制。
目前在移动市场大部分的手机 CPU 架构都是基于ARM架构的,当在ARM的处理器上做图像处理,音视频转换,游戏渲染等涉及大量数据计算的时候,常常会出现因为计算量太大造成算力瓶颈的困境。所需要选择一种更加简单快捷的计算方式以获得处理速度上的提升,ARM NEON就是一个不错的选择,今天的主角登场了。
SIMD 技术及最新发展
要介绍 NEON 之前不得不先提下 SIMD 技术,Single Instruction Multiple Data (SIMD)顾名思义就是“一条指令处理多个数据(一般是以 2 为底的指数数量)”的并行处理技术,相比于“一条指令处理几个数据”,运算速度将会大大提高。它是 Michael J. Flynn 在 1966 年定义的四种计算机架构之一(根据指令数与数据流的关系定义,其余还有 SISD、MISD、MIMD)。
SIMD 一般应用在数据量较大的场合,比如在视频、图形、图像处理中的 8-bit 像素数据,音频编码中的 16-bit 采样数据等。在诸如上述的情形中,很可能充斥着大量简单而重复的运算,且少有控制代码的出现。因此 SIMD 就擅长为这类程序提供更高的性能,其使用一条指令,加载多个同样 type 和 size 的数据,并对数据进行并行处理。
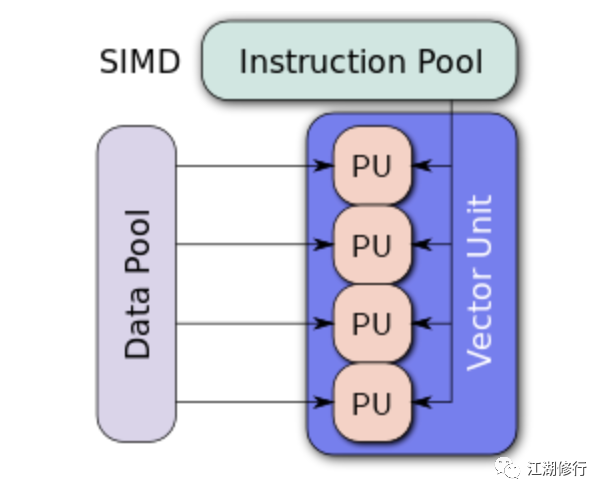
SIMD 采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每个数据分别执行相同操作,从而实现并行技术,简单来说就是一个指令能够同时处理多个数据。SIMD 结构如下:
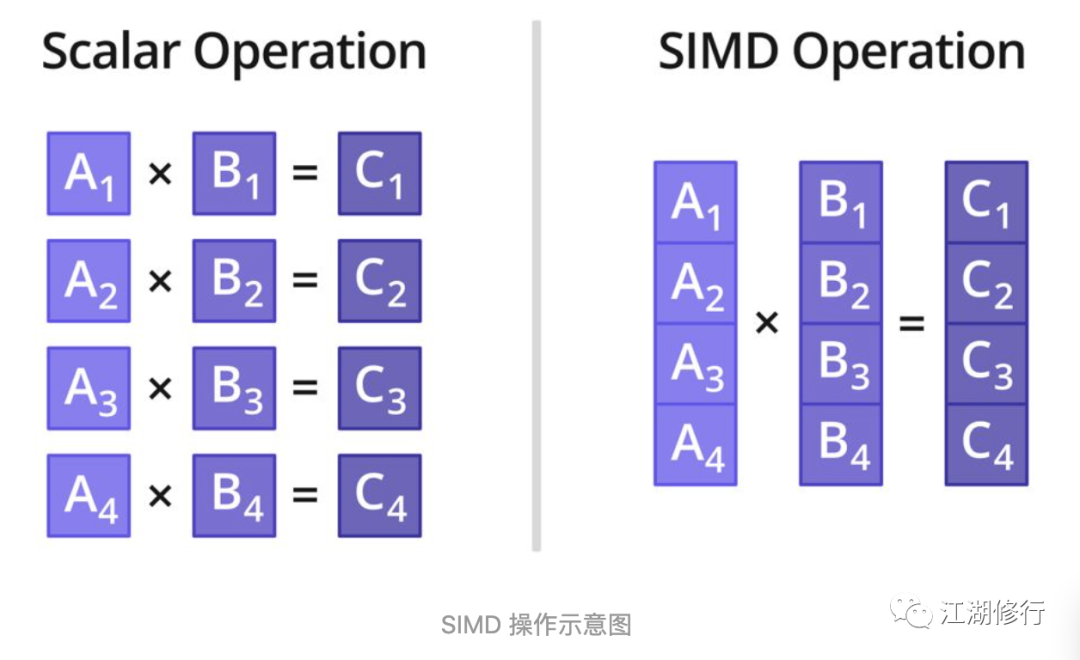
SIMD 操作如下:
指令数与数据流
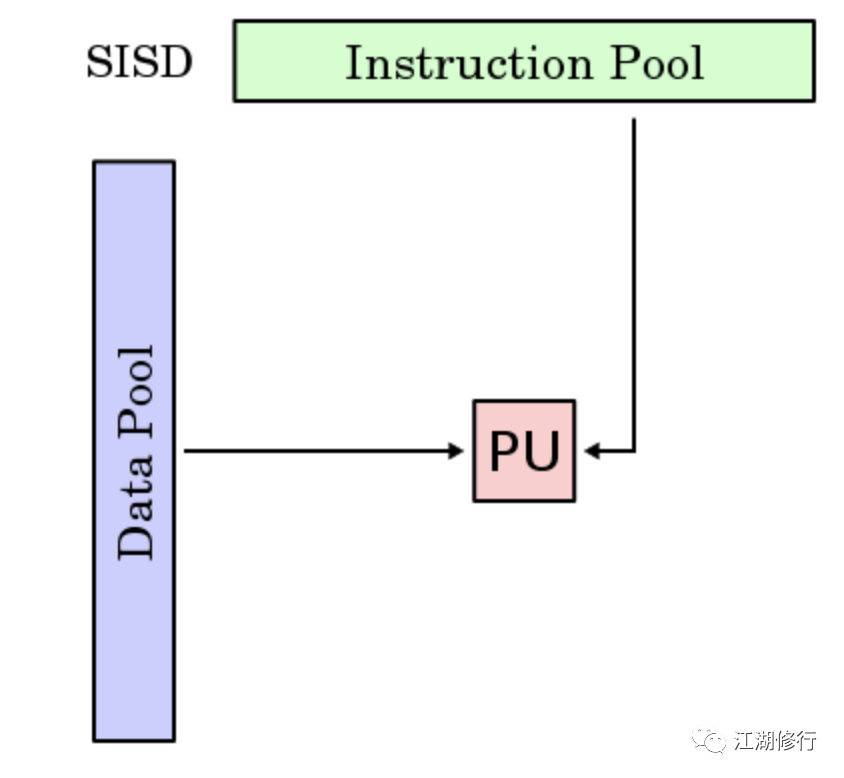
SISD(Single Instruction Single Data)
SISD 机器是一种传统的串行计算机,它的硬件不支持任何形式的并行计算,所有的指令都是串行执行。并且在某个时钟周期内,CPU 只能处理一个数据流。早期的计算机都是 SISD 机器,如冯诺.依曼架构,如 IBM PC 机,早期的巨型机和许多 8 位的家用机等。
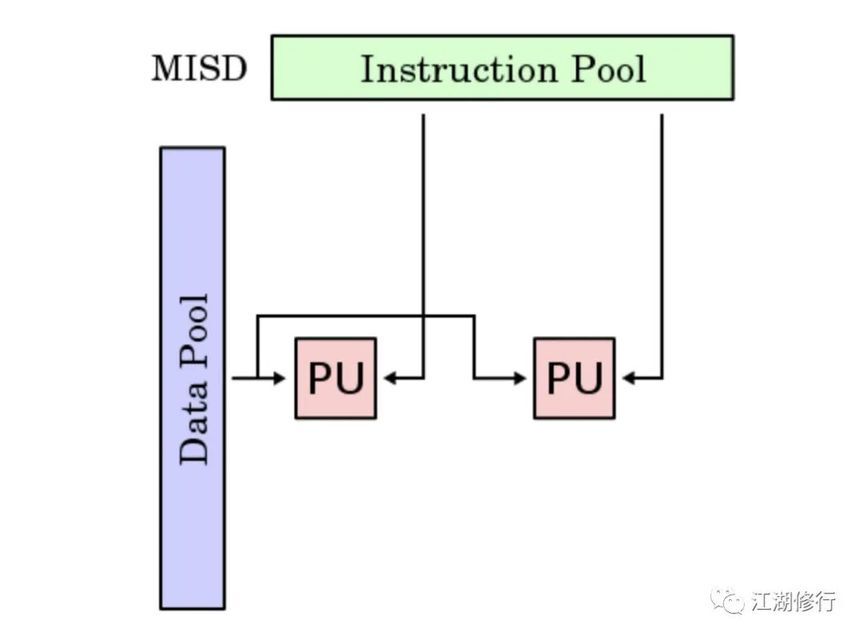
MISD(Multiple Instruction Single Data)
是采用多个指令流来处理单个数据流。由于实际情况中,采用多指令流处理多数据流才是更有效的方法,因此 MISD 只是作为理论模型出现,没有投入到实际应用之中。
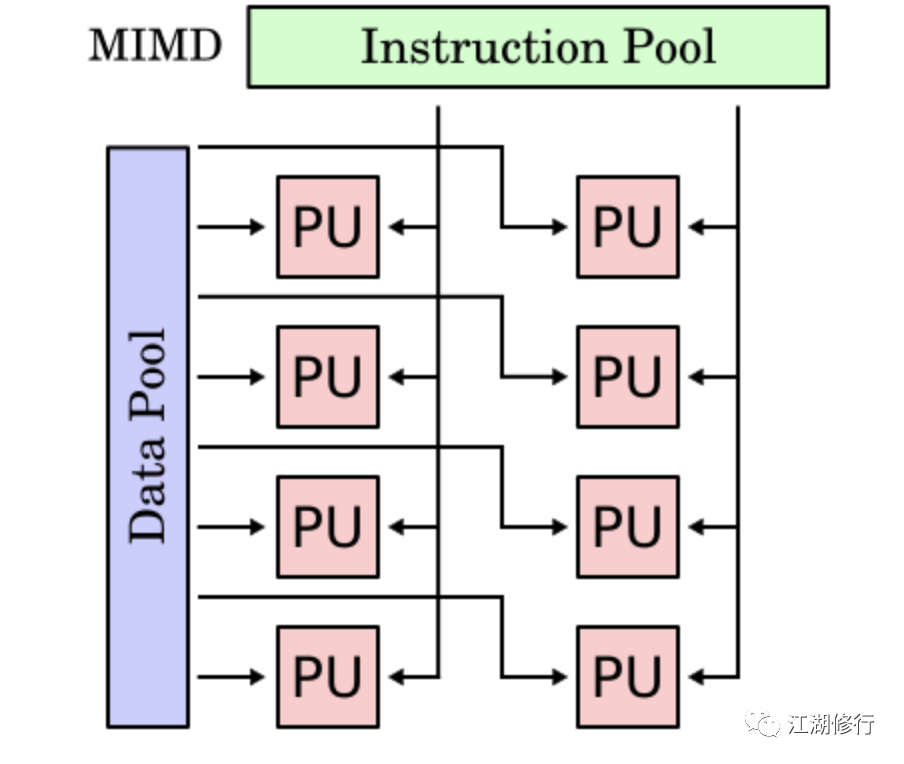
MIMD(Mutiple Instruction Mutiple Data)
MIMD 机器可以同时执行多个指令流,这些指令流分别对不同数据流进行操作。在任何时钟周期内,不同的处理器可以在不同的数据片段上执行不同的指令,也即是同时执行多个指令流,而这些指令流分别对不同数据流进行操作。最新的多核计算平台就属于 MIMD 的范畴,例如 Intel 和 AMD 的双核处理器等。
SIMD 最新发展
最新的 ARM 架构的下一代 SIMD 指令集被称作 SVE(Scalable Vector Extension,可扩展矢量指令),其是针对高性能计算(HPC)和机器学习等领域开发的一套全新的矢量指令集。
SVE 指令集中有很多概念与 NEON 指令集类似,例如矢量、通道、数据元素等。
SVE 指令集也提出了一个全新的概念:可变矢量长度编程模型。
传统的 SIMD 指令集采用固定大小的向量寄存器,例如 NEON 指令集采用固定的 64/128 位长度的矢量寄存器。
而支持 VLA 编程模型的 SVE 指令集则支持可变长度的矢量寄存器,使其能够在现在或将来的多应用场景下实现伸缩,允许 CPU 设计者自由选择向量的长度来满足 PPA 目标,甚至在可能的情况下通过提高编译器自动矢量化技术来降低软件开发成本。
SVE 允许矢量寄存器长度可以在 128 到 2048 之间选择实现。它支持与矢量长度无关的编程模型,允许代码在所有矢量长度上自动运行和缩放,而无需重新编译。它还引入了几个创新性的特性,这些特性可以克服一些传统的自动矢量化障碍。不同的应用场景对向量长度有不同的需求,所以没有哪一个单一的长度是最佳的。出于这个原因,SVE 的向量长度是可选择的(从 128 到 2048,以 128 递增)。更重要的是,编程模型可以动态调整到合适的向量长度,而不需要重新编译高级语言或者重写手工编码的 SVE 组件或编译器。更长的矢量只是 SVE 解决方案的一部分,要实现显著的加速也需要高水平的矢量利用率,所以 SVE 特性具有以下特点:
可伸缩的向量长度:通过选择合适的长度来提高并行度
丰富的寻址方式.实现非线性数据访问
单通道 predication:允许包含复杂控制流的循环矢量化
Predicate-driven 的循环控制和管理:降低了将标量代码的矢量化开销
丰富的并行化操作:适用于更多类型的可分解 loop-carried 依赖关系
向量分区和软件管理的推测:支持将数据依赖的 loop 矢量化
可伸缩的向量内子循环允许对具有更复杂 loop-carried 依赖关系的循环进行矢量化
ARM 在 2019 年便推出了 SVE2,以最新的 Armv9 为基础,扩充了更多的运算类型以全面替代 NEON,同时增加了矩阵相关运算的支持。
版权声明: 本文为 InfoQ 作者【江湖修行】的原创文章。
原文链接:【http://xie.infoq.cn/article/83e22578e32bd9f80c676118a】。文章转载请联系作者。

还未添加个人签名 2021-12-05 加入
还未添加个人简介









评论