
基于容器和 Kubernetes 的应用无限扩容
基于应用负载动态管理 CPU、内存等资源的使用是云原生架构的最佳实践之一,Kubernetes 通过资源请求和限制以及 HPA/VPA 等机制,为云原生应用资源管理提供了很好的支持。原文: Infinite Scaling with Containers and Kubernetes
如果没有足够资源让容器完成工作,那么即使把世界上最好的代码容器化也没有任何意义。
我在写关于容器状态探测的文章时产生了这篇文章的想法,很明显,对kubelet查询返回准确响应只是解决方案的第一部分。
第二部分是本文的主题: 为容器分配资源。我们需要探索资源分配的所有领域,从 Kubernetes pod 中的单个容器直到云上近乎无限的容量。
过去几年基于容器的工作负载发展迅速,使得对系统设计中资源容量的关注成为了过去时。
Kubernetes 资源管理: 概述
"如何确保容器始终拥有所需资源?"
本节只是为刚开始使用 Kubernetes 管理资源的人简单介绍一下资源管理,关于命名空间限制范围和Kubernetes容器资源管理的官方文档仍然是必读资料,如果你对这一主题比较熟悉,可以跳到下一部分。
Kubernetes 资源管理主要包括 CPU、内存和本地临时存储,容器规范可以为每种资源类型定义资源请求和资源限制。
资源请求(resource request) 是容器运行时所需的最小资源量,节点调度器只有在节点满足 pod 中所有容器的最小资源请求时,才会将 pod 调度到该节点上。
资源限制(resource limit) 是 kubelet 在其生命周期内应该分配给容器的最大资源量。当容器设置了资源限制但没有资源请求时,相当于将资源请求设置为与资源限制相同的值。
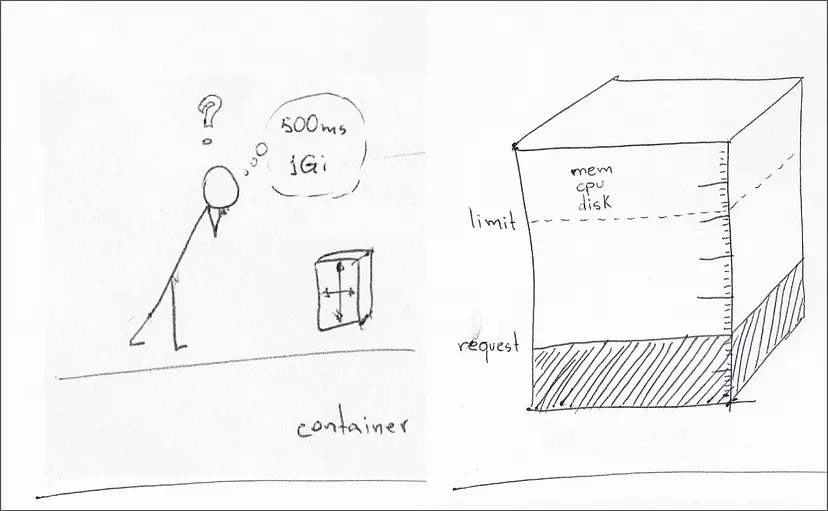
Kubernetes 允许软件开发人员和系统管理员协作设置 CPU、内存和临时存储等资源预留的最小量和最大限制。
容器可以设置资源请求和限制的任意组合,CPU 和内存预留的不同组合定义了父 pod 的服务质量,如下所示:
pod 中每个容器都有资源请求和限制,并且每个容器的请求和限制具有相同的值: Guaranteed。
pod 中至少有一个容器没有设置资源请求或限制: BestEfford。
不属于前两种的 pod: Burstable。
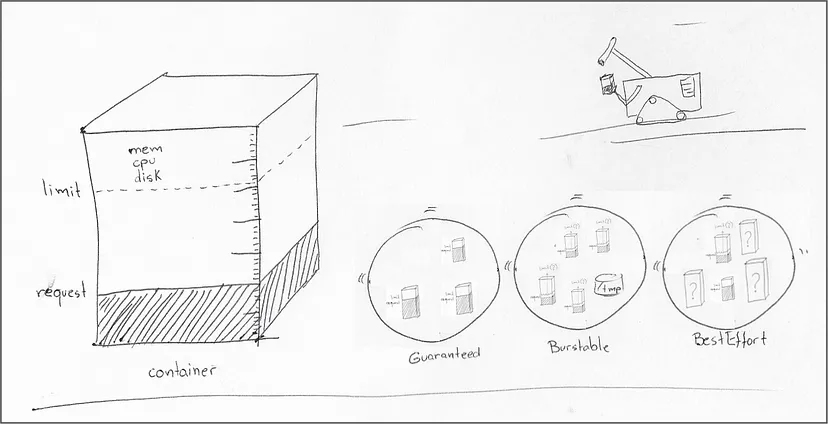
"Guaranteed"工作负载要求所有容器中的 CPU 和内存的限制和请求具有相同的值。如果集群满足所有"Guaranteed"工作负载的需求,则确保请求得到执行。高于"requests"和低于"limits"的任何 pod 是否被调度取决于集群是否有空闲资源。如果集群资源耗尽,"BestEfford"容器将被首先驱逐。
当kube-scheduler决定在工作节点上调度某个 pod 时,了解这些类别的含义会很有帮助:
"Guaranteed"意味着调度程序只将 pod 分配给具有足够资源的工作节点,以满足 pod 中所有容器的请求。
"Burstable"意味着调度程序会寻找具有足够内存的工作节点来满足 pod 中所有容器的资源请求,调度器并不关心工作节点是否能够满足 pod 中容器的资源限制或资源请求之上的任何限制。
"BestEffort"是指调度程序在调度"BestEffort" pod 之前,将首先满足"Guaranteed"或"Burstable" pod 的资源请求。调度器会不断重新评估,如果"Guaranteed"或"Burstable" pod 需要资源,可能会标记"BestEffort" pod 以便驱逐。
决策时间:谁来定义容器资源?
首先需要理解,资源请求是用来保护容器的,而资源限制是用来保护集群的。
做出决策的主要参与方是产品开发人员和系统管理员,由于决策会随着时间的推移而改变,因此他们之间的"谈判"充满挑战:
产品开发人员将大部分时间用于建立与部署与生产环境隔离的资源边界。
系统管理员通常在处理Kubernetes工作负载规范时缺乏足够的文档说明资源请求和限制的变化会如何影响工作负载。
产品开发人员可以更好的了解工作负载的需求及其在不同资源分配下的行为,一般来说,应该能够在发布前确定以下阈值:
绝对最小(Absolute minimum)资源请求。这个值是加载运行时所需的资源,并且能够轻松响应来自 kubelet 的探测请求。
最大可用(Maximum usable)资源限制。这个值是容器的性能开始遇到外部限制的点,比如磁盘 I/O 或调用第三方服务的瓶颈。
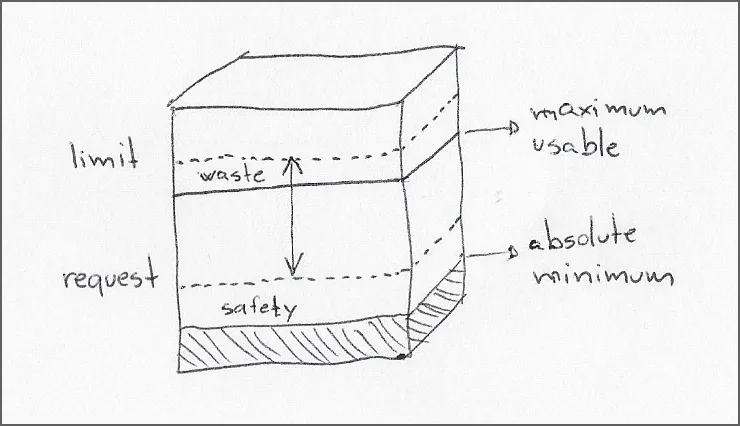
开发人员必须定义资源范围,然后在选择资源请求和限制时平衡运行时安全和资源浪费。
理想情况下,产品开发人员还应该建立并记录容器性能在边界内的变化情况,这些信息可以帮助系统架构师在部署之前规划初始容量,并使系统管理员能够调整生产环境中的资源请求。
配额、范围和公地悲剧
系统管理员可以查看集群容量及可用容量。作为偶尔兼顾 SRE 的人,我比较欣赏"Guaranteed"工作负载。对于组织来说,在 pod 中所有容器上设置固定的资源边界并信任 pod 可以在边界内可靠工作需要特殊的信心(以及大量测试)。
"Burstable"工作负载在信任范围内的排名略低。当我做 SRE 时,最大的希望是在 burstable pod 中的所有容器都设置了上一节提到的"绝对最小"资源请求。
关于 burstable 工作负载的资源限制,我的观点来自资源限制背后的开发理念:
(好的理念) 在工作负载内进行自动伸缩(例如,启动具有最小和最大内存限制的 Java 虚拟机)。这种安排(资源限制设置高于资源请求)意味着开发团队花时间确定了工作负载的可用操作范围,并能很好的控制和管理资源。
(不好的理念) 防止最终错误。这种设计理念让我想起了"公地悲剧",即每个人都预期资源最终将被耗尽,因此需要占有更多共享资源,从而加速了共享资源的耗尽。当开发团队低估了资源需求时,这种理念尤其具有灾难性,在这种情况下,工作负载持续在其资源开销的突发区域内运行,使其容易受到 CPU 节流、内存耗尽和工作节点 kubelet 终止的影响。
最后留下来的是"BestEffort"工作负载,它们不受约束的耗尽集群资源的能力,以及面对其他请求相同资源的 pod 时脆弱的调度状态,让我们时刻担心集群的运行。
在处理这些类型的工作负载时,系统管理员必须花时间考虑以下选项:
用限制范围(limit ranges)为命名空间中的容器和 pod 设置默认资源请求和限制。我认为,对跨命名空间的工作负载分配相同的资源限制,再加上缺乏产品开发人员的投入,让这一主张并不现实。
用资源配额(resource quotas)限制命名空间中所有 pod 的组合资源。这种方法是更有前途的解决方案,减少了最终容器对该命名空间失控的"爆炸半径",优点是避免了资源安全缓冲区叠加命名空间中 pod 数量所造成的浪费。
深吸一口气,我们有望从下一节中介绍的 pod 自动缩放技术中解脱出来。
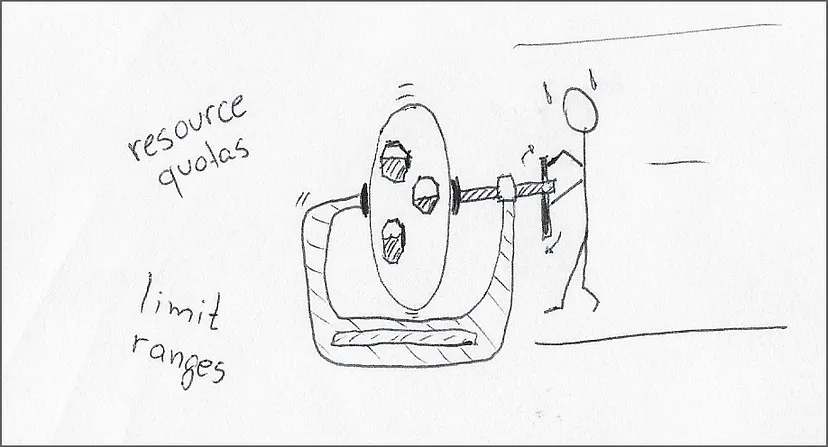
系统管理员可以用资源配额和限制范围来防止工作负载受到干扰,但通常缺乏协调运行时安全和浪费的足够信息。
Pod 自动缩放: 超越静态大小
许多读者可能已经准备好提出处理难以控制的工作负载的常用方法:
这两种流行的自动扩容技术可以根据资源指标在集群内动态分配容量。HPA 可以更改部署 pod 副本的数量,而 VPA 可以更改 pod 的资源请求和限制。注意,在Kubernetes增强建议添加到 Kubernetes 之前,VPA 对 pod 的更改会导致 pod 重启。
虽然能够自动扩展容量,但这些组件并不能在缺乏对工作负载的操作范围的精确定义。例如,如果 pod 中的容器没有对该度量的资源请求,HPA 将不会对该度量采取行动。HPA 也不适合部署依赖于集群中 pod 的特定数量的副本的场景。
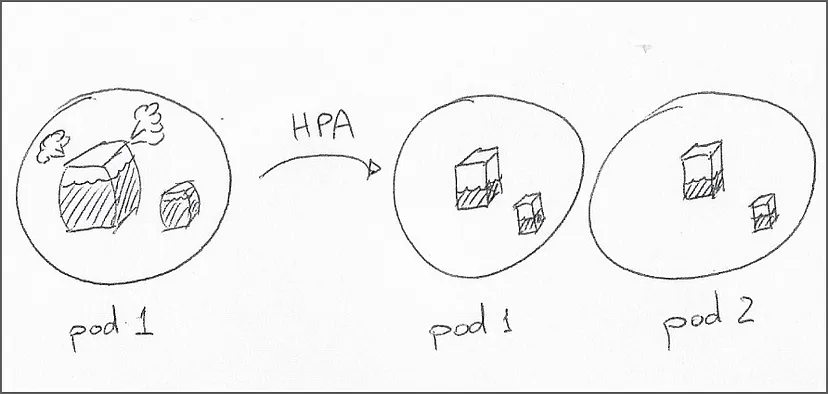
当资源利用率偏离预期,HPA 通过增加或减少 pod 副本的数量来平衡部署容量。
对于需要固定数量副本的工作负载或没有预设限制的工作负载,使用 VPA 效果更好。不过会有一个相对较长的限制列表。此外,如果设置限制范围,则需要考虑的因素可能会非常复杂。
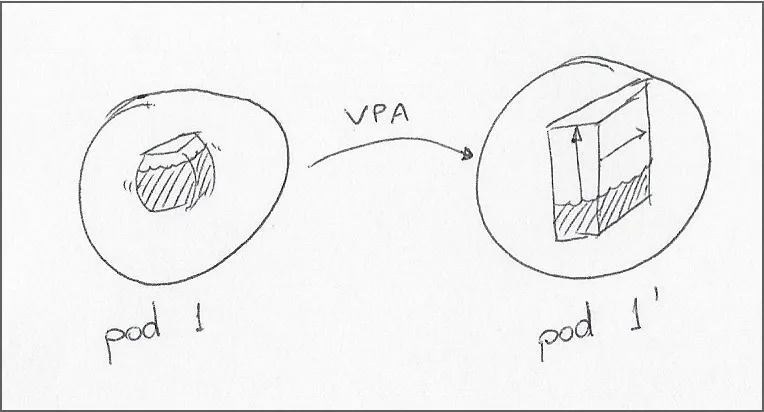
VPA 通过观察 pod 内的资源利用率来平衡部署容量,并重新创建具有更多资源请求和限制的 pod(在不重新启动的情况下调整 pod 大小目前还在实验阶段)。
这些工具在自动伸缩工作负载方面最终是否有效取决于开发期间经过充分研究的资源请求和限制的分析工作。在这方面我必须给予 VPA 额外的信任,因为它能够"学习"部署的资源范围。
自动化运维 operator: 即开即用的 SRE?
Kubernetes operator引入了自定义资源的概念来管理应用程序和工作负载。从概念上讲,operator 持续监控自定义资源并将其内容映射到工作负载资源。
Operator成熟度模型定义了五个不同级别的自动化,最高是 5 级,即"自动驾驶(Auto Pilot)"。处于该成熟度阶段的 operator 应该对其管理的工作负载自动应用包括水平或垂直扩展在内的自主行为。
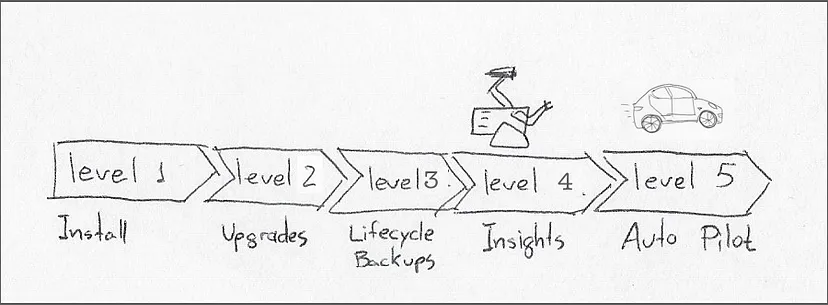
operator 成熟度模型要求能够自调优和自动扩展工作负载的"5 级"operator。
开发 operator 自然会有额外成本,包括设计和记录自定义资源定义,operator pod 还存在额外的运行时成本。这就是为什么我认为 operator 的价值只有在第 4 级或"深度洞察(Deep Insights)"时才能开始抵消成本,这一级别需要生成指标、发出警报、完成工作负载分析等。
在 4 级以下,operator 对于帮助缓解产品开发人员对未来的预测以及帮助系统管理员将这些预测变为现实几乎没有任何帮助。
Knative: 零浪费的弹性容量
据其网站介绍,Knative"是一个开源企业级解决方案,用于构建无服务器和事件驱动应用程序。"
从本文角度来看,我们感兴趣的是 Knative 的服务模块。该模块包含 Knative Pod Autoscaler (KPA),它模仿 HPA 改变 Pod 副本数量以满足需求的能力,具有两个关键区别:
根据外部请求的数量来缩放副本
当没有外部请求时,将副本缩小到零
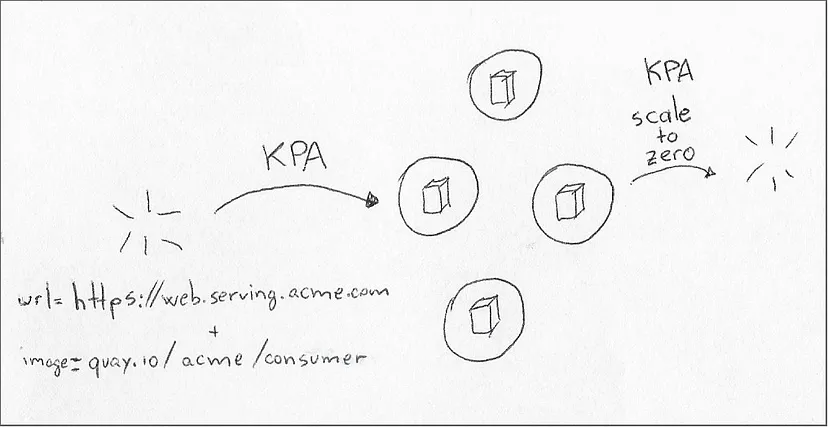
Knative Pod Autoscaler 监视对 URL 的请求,并决定需要多少 Pod 来处理等待的请求队列。通过正确的配置,在没有未处理请求的情况下,KPA 将删除 pod 的所有副本,以最大限度节省资源。
与 HPA 不同的地方在于,HPA 在超过预设边界时对资源利用率做出反应,KPA 根据并发性和[每秒请求数](https://knative.dev/docs/serving/autoscaling/rps-target "Knative Configuring the requests per second (RPS "每秒请求数") target")目标做出决策。
根据经验,HPA 更适合资源需求不会突然改变的、长时间运行的、启动缓慢的进程。相反,KPA 更适合能够快速启动以满足即时需求的瞬时进程。
最后,无论是否考虑"无服务器",KPA 都要使用容器,因此资源限制仍然很重要。
集群自动伸缩: 突破极限
一旦对工作负载资源和 pod autoscaler 进行了适当的调优,就可以深入了解工具箱并使用Kubernetes集群autoscaler了。
集群自动缩放器可以根据资源需求添加(或删除)工作节点,自动缩放器尊重可配置的下限和上限,以保证 pod 的最小容量以及一定程度的成本控制,避免难以控制的工作负载使集群过度扩容。
缓慢扩容(Slow stretching) 。记住,与 pod 自动缩放器相比,集群自动缩放器的响应时间明显较慢,工作节点需要几分钟才能对 kube-scheduler 可用。
假设需要集群自动缩放器来处理峰值需求,在这种情况下,必须部署一个牺牲缓冲区的"暂停舱(pause pod)"(在集群自动缩放器文档中有描述)。当新工作负载需要这些资源时,kube-scheduler 会立即退出 pause pod 以释放资源,然后集群扩展节点数量以重新分配被驱逐的 pod。
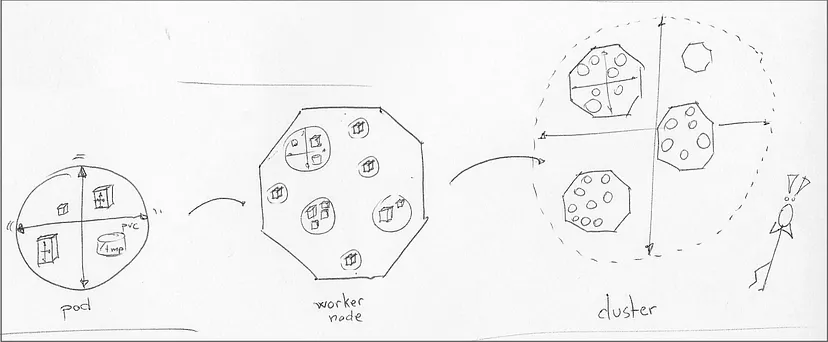
一旦 pod 自动缩放器无法在集群工作节点上找到足够的空间,集群自动缩放就会开始工作。
请注意,Kubernetes 的污点(taints)和容忍(tolerations)也在自动缩放器的工作中发挥作用,如果没有对污点的容忍,则设有污点的工作节点将被禁止放置 pod。
无服务器: 无限容量……但有限制
对于最终级别的自动扩展,是时候放弃集群的边界了(即使 Kubernetes 也有限制),并在云服务商级别考虑无服务器功能。
主要的云服务商可以根据多个事件(如 web 请求、数据库操作和计时器)按需启动容器镜像。与单个集群相比,云服务商的资源容量实际上是无限的,与在集群中运行相同的工作负载相比,只在容器中运行一会儿的成本几乎可以忽略不计。
具有讽刺意味的是,尽管每次调用的成本极低,但无服务器方法使我们从担心资源限制转向担心成本超支:
容器限制仍然很重要: 云服务商要求为每个容器调用指明 cpu 和内存数量。
预算限制: 如果测试套件中的错误可能耗尽集群容量,那么在无服务器部署中,相同的错误可能会在一夜之间耗尽整个部门的预算。
无服务器产品还有几种变体,例如将一个小功能交给云引擎,而不是整个容器镜像,或者让云服务商使用托管集群来运行容器(以规模化换取安全性)。
为方便起见,这些产品都可以从包含 Dockerfile 的 Git 存储库开始,在调度该镜像的工作负载之前,用存储库构建和缓存容器镜像。
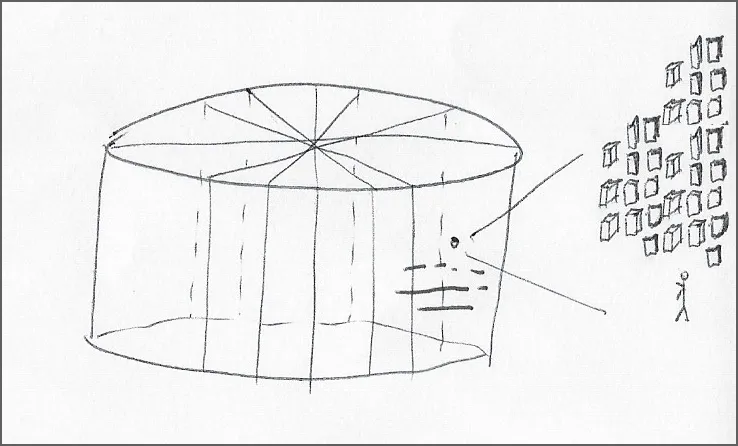
在云服务商的无服务器分配中,无需担心集群容量。但系统管理员仍然需要担心单个容器是否有足够资源运行,还要避免对资源近乎无限的使用。
结论
我们涵盖了工作负载的整个资源分配范围,从调优单个容器到 Kubernetes 之外的超大规模工作负载。
本文首先概述了 Kubernetes 资源管理及其资源请求和限制的核心概念,然后在这些静态限制的基础上构建 pod 自动缩放器: HPA、VPA 和 KPA。
从 pod 自动缩放器有效利用集群最大容量的能力开始,继续使用集群自动缩放来增加容量。最后以跨云服务商的无服务器产品形式,用几乎无限的资源(和成本)完成了整个视角的闭环。
除了 VPA,其他技术仍然建立在开发时确定容器资源消耗的努力之上。例如,HPA 不会根据没有指定限制的资源采取行动,而云服务商会直接请求分配给每个容器运行的 CPU 和内存资源。
参考文献
Practical Kubernetes — Top Ten Challenges — Part 6: Sizing and Footprint Optimization, by Andre Tost
You can’t have both high utilization and high reliability, by Nathan Yellin
Vertical Pod Autoscaler deep dive, limitations and real-world examples
IBM Code Engine (Managed Knative)
你好,我是俞凡,在 Motorola 做过研发,现在在 Mavenir 做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI 等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。微信公众号:DeepNoMind
版权声明: 本文为 InfoQ 作者【俞凡】的原创文章。
原文链接:【http://xie.infoq.cn/article/80f5240876c93fbe67bc5bf7a】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。
公众号:DeepNoMind 2017-10-18 加入
俞凡,Mavenir Systems研发总监,关注高可用架构、高性能服务、5G、人工智能、区块链、DevOps、Agile等。公众号:DeepNoMind









评论