
如何通过观测云的 RUM 找到前端加载的瓶颈 -- 可观测性入门篇
声明与保证
本文写作于 2023 年 6 月,性能优化的评价标准和优化方式仅适用于当前观测云控制台,当然随着产品迭代及技术更新,本文也会应要求适当更新。
1.网站性能评价的发展史(近 20 年)
讲到网站性能优化,离不开网站技术发展史,更离不开网站性能的评价标准的发展。优化既离不开不断演进发展的技术,也离不开前人对技术优化的方法论和具体实践。近 20 年来,网站性能评价的标准有三次比较值得关注的关键节点,这三次关键节点分别能看出性能优化的视角与方法。
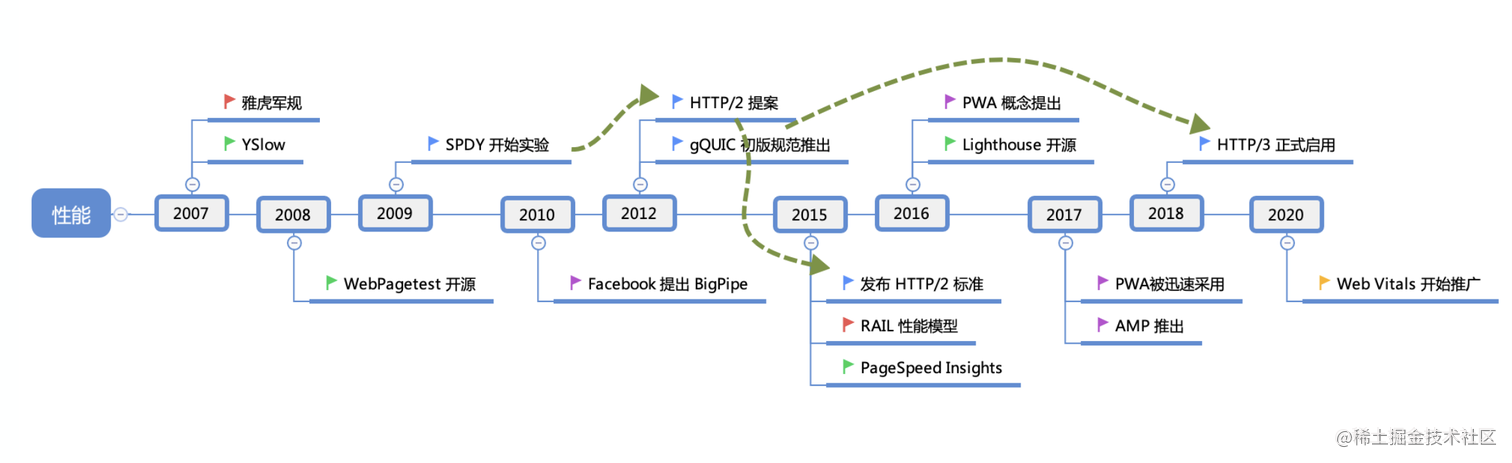
性能优化技术和评价标准的发展历史图
1.1 Yahoo 军规打下夯实的基础:有定性无定量的坑
最初,在只有纯文本阅读的时代,几乎或者很少会像现在一样考虑性能(产品)上的优化。随着互联网时代的到来以及信息化发展,图片、音视频等多媒体时代降临,开始有了在网站性能优化的第一次启蒙。雅虎作为第一梯队,率先推出了网站优化的军规,很快被广大开发者所接受,这些军规即使现在看,依旧有很大的借鉴和指导意义。其中基本包含了以下内容,因篇幅有限,故未完全展开讲述:
减少 http 请求
使用内容发布网络
添加 Expires 头
压缩组件
将样式表放在顶部
将脚本放在底部
避免 css 表达式
使用外部 javascript 和 css
减少 DNS 查找
精简 Javascript
避免重定向
删除重复脚本
配置 ETag
使用 Ajax 可缓存
内容来源:《高性能网站建设指南》
注:此处不建议完全照搬雅虎军规进行以上设置,尤其是在没有构建全面的网站指标体系和性能模型前,单独照搬不仅可能抓不住痛点甚至还有可能有反作用;
1.2.RAIL 性能模型首次提出:以用户体验为中心的可量化标准
搜索引擎时代谷歌对于网站评价标准的影响非常大,在谷歌的不断探索中,首先提出了以用户为中心的性能模型,因为谷歌的巨大影响力,这个评价模型也开始在开发人员中传播开来,性能评价的视角也逐渐转向了用户体验,非常可喜的是对于这四项用户体验的维度,每个维度都有量化的指标。
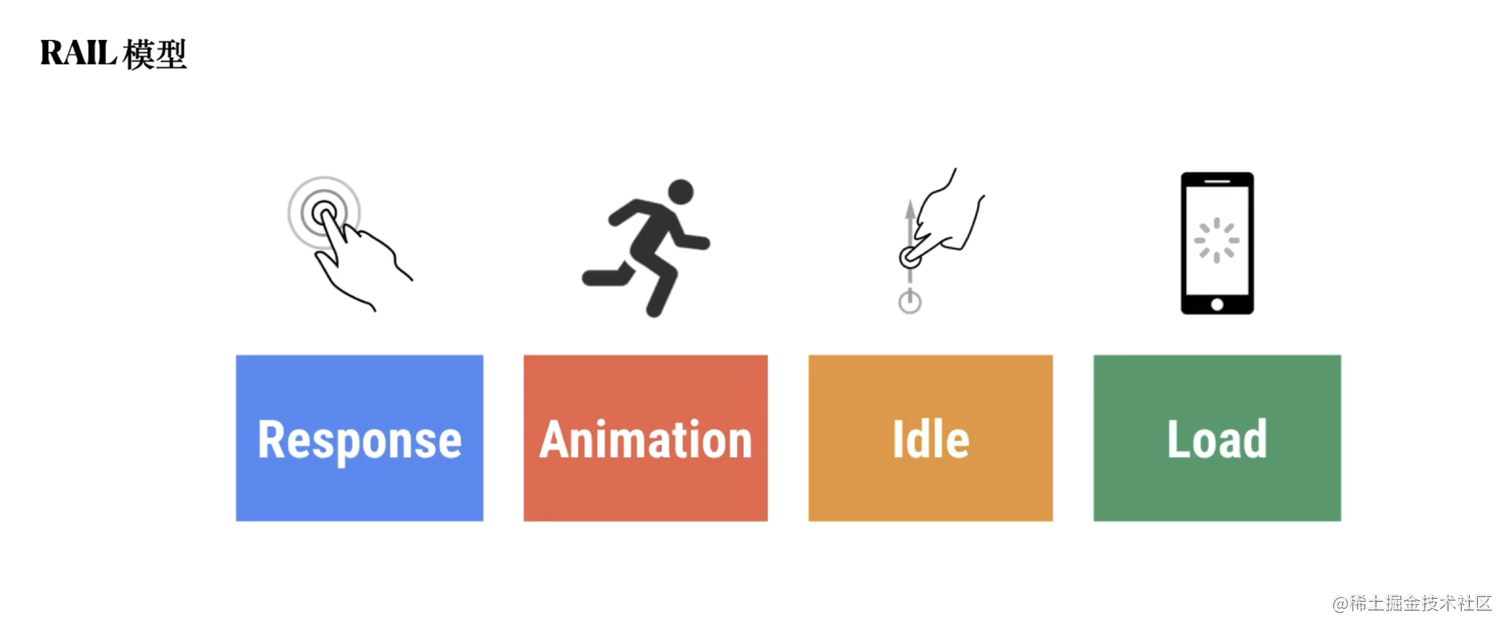
RAIL 模型图
来源:web.dev/rail
如下介绍一下用户如何感知性能延迟的关键指标:

数据来源:web.dev/rail
总结一下,该模型非常强调对于性能的延迟,特别强调:
响应 :100ms 内响应
动作:50 毫秒内处理事件
动画:10 毫秒内生成一帧
加载:在 5s 内交付内容并交互
1.3. 网站核心指标几乎统一了性能的评价标准:从三个维度可量化
然而直到 2020 年的十年左右的时间,RAIL 并没有像搜索引擎一样被大众完全使用,在这期间谷歌陆续推出了开源框架 lighthouse,并在 chrome devtools 中开始使用 web vitals。谷歌也有很多开发开始了在 web vitals 的布道。web vitals 很快被广大开发者所接受,并快速被 APM 厂商作为衡量网站性能的方法。
web vitals 是一种思想,该思想吸收囊括了性能发展过程中的几个关键指标,分别从加载速度、交互情况、视觉稳定性这三个方面入手,每部分包括 1 个或者多个指标。web vitals 也在不断调整其指标内容,目前广为接受的分别是 LCP、FID 和 CLS。
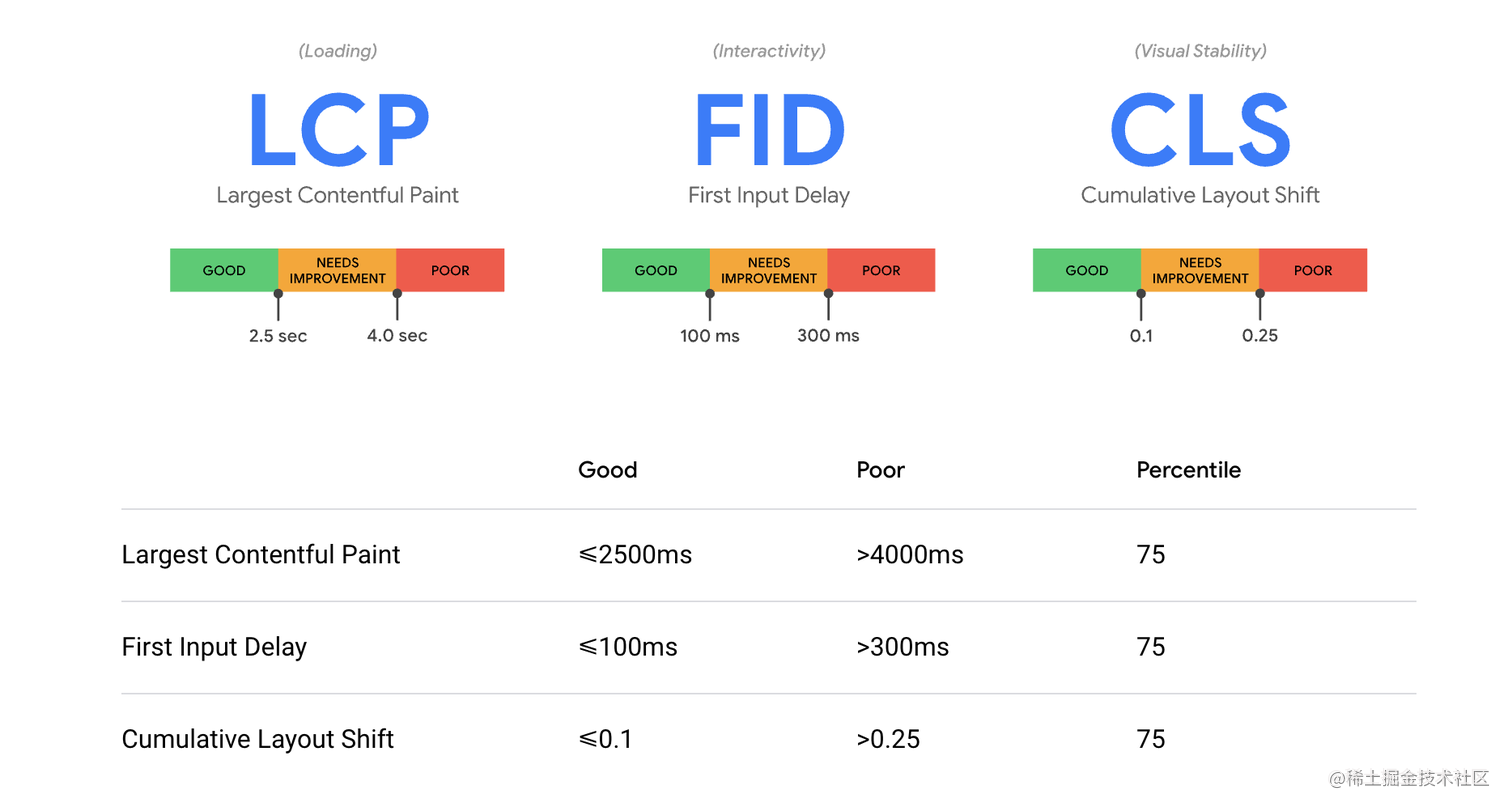
网站核心指标图
数据来源:web.dev/defining-co…
LCP :最大内容绘制 (LCP) 是测量感知加载速度的一个以用户为中心的重要指标,因为该项指标会在页面的主要内容基本加载完成时,在页面加载时间轴中标记出相应的点,迅捷的 LCP 有助于让用户确信页面是有效的。
FID:首次输入延迟 (FID) 是测量加载响应度的一个以用户为中心的重要指标,因为该项指标将用户尝试与无响应页面进行交互时的体验进行了量化,低 FID 有助于让用户确信页面是有效的。
CLS:累积布局偏移 (CLS) 是测量视觉稳定性的一个以用户为中心的重要指标,因为该项指标有助于量化用户经历意外布局偏移的频率,较低的 CLS 有助于确保一个页面是令人愉悦的。
需注意:web vitals 标准也在不断变化中,目前一个比较新颖的指标就包括即将替代 FID 的 INP,这不是本篇最佳实践的重点,但必须要认识到,web vitals 是目前接受度最为广泛的标准,也是观测云的网站性能体系中的重要组成部分。
2.观测云用户体验方案
言归正传,网站核心指标给出了比较规范易接受的性能评价体系。在观测云的用户体验的最佳实践中,首先推荐用户的,便是使用观测云用户体验监测功能。
随着产品支持的用户和平台越来越多,虽然基础设施和服务都健康运行,但没有客户端的可观测性,也只是伪全面,因为很有可能报错出现在客户端,或者用户体验差已经流失了。
观测云的用户体验监测(rum)既包含了 RAIL 的精华,也囊括了网站核心指标。作为基于浏览器的性能指标收集性能和用户体验的方式(这部分会在后续实践的文章详细介绍),远比实验室或者开发者本地性能测试有好处,正是因为基于真实的物理设备和网络情况,以及真实的用户行为,所提供的指标和数据也更有意义和价值,比如可以
今天作为入门篇,我将简单介绍一下基础功能
2.1 用户访问监测介绍
观测云用户体验方案推荐用户接入用户访问监测,收集真实的用户行为数据和性能数据,分析用户行为和性能数据,做出对研发和业务做出最佳的决策。
需注意:不同网站有不同的性能需求,观测云推荐用户根据业务场景收集访问和性能数据,不代表推荐用户收集 100%的用户访问数据,用户需根据实际情况选用接入方式和接入情况,观测云允许用户对用户数据进行采样。
2.1.1 有关观测云 SDK 的接入和数据的分析
网站接入观测云 SDK 后,用户的访问数据(包含用户旅程)和性能数据就有了进一步分析的可能。在登录观测云后不仅可以看到这部分的数据,包括有会话、页面、动作、错误、卡顿这几个维度,更重要的是可以以此创建基于业务的数据分析,以下将先介绍基础的面板以满足日常访问和性能数据的查看。
a.数据查看
在性能方面,首先观测云推荐用户关注性能仪表盘中的网站核心指标,为方便用户查看,在观测云用户监测中有专门的性能看板,不仅能够满足对网站核心指标的查看,还包含了卡顿、xhr、资源等分析情况。
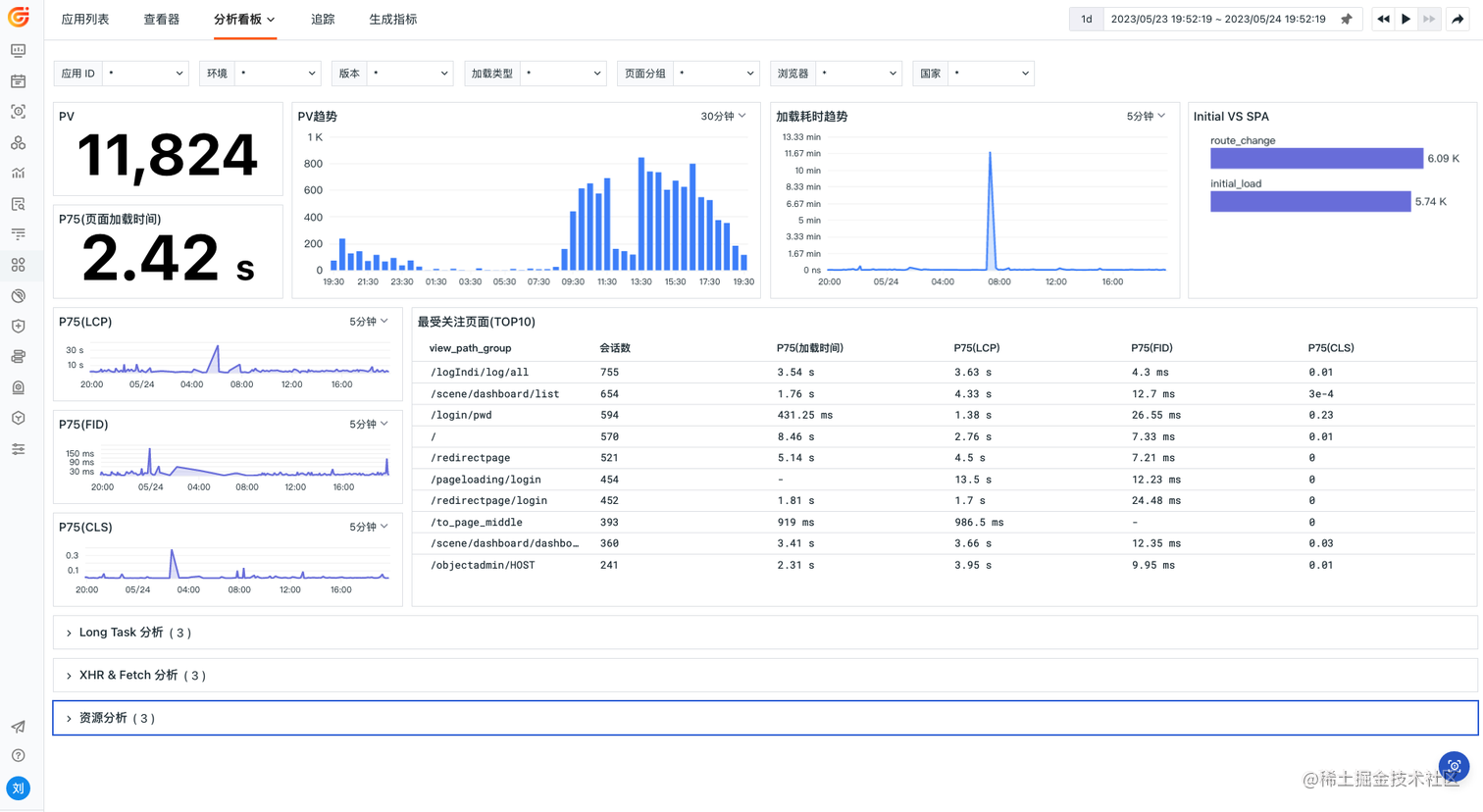
观测云用户访问数据的分析看板
其次,由于卡顿和报错越来越成为制约性能和用户体验的两大因素,观测云推荐从会话和页面的维度,关注以下 4 个和性能关键的指标:
session_long_task_count,会话卡顿次数
session_error_count,会话错误次数
view_long_task_count,页面卡顿次数
view_error_count,页面错误次数
注意:页面级别的网站核心指标依然非常重要,核心指标对于 good/needs improvement 和 poor 的评价标准是一般指标,e.g. 让用户等 2.5s(LCP 在 2.5s 内)才看到页面这显然又太宽泛,在没有更适用的定量标准前,以产品使用场景设定一个 benchmark 非常有意义。
b.数据分析前的小知识点补充
性能数据分析
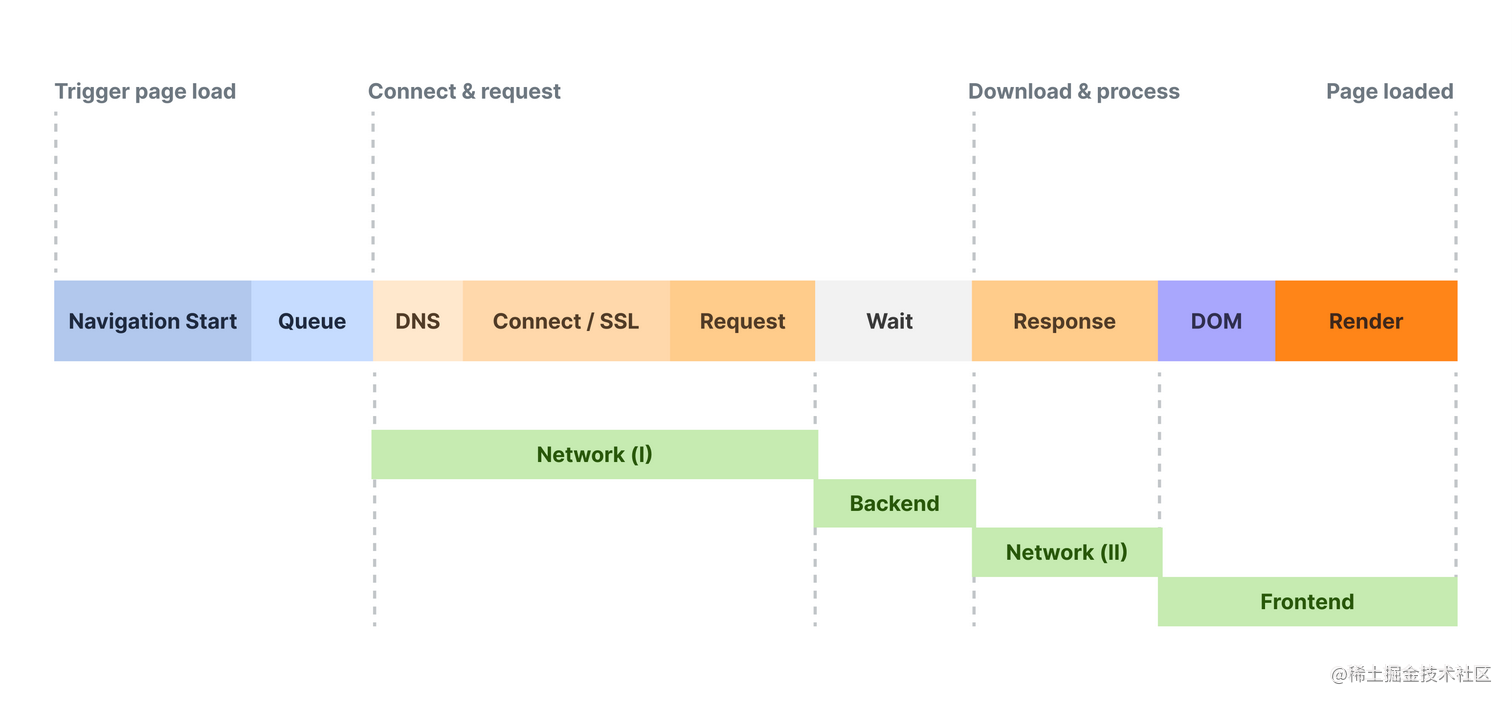
说到性能瓶颈分析,多基于浏览器的性能指标,这个过程通常划分为以下十几个阶段:
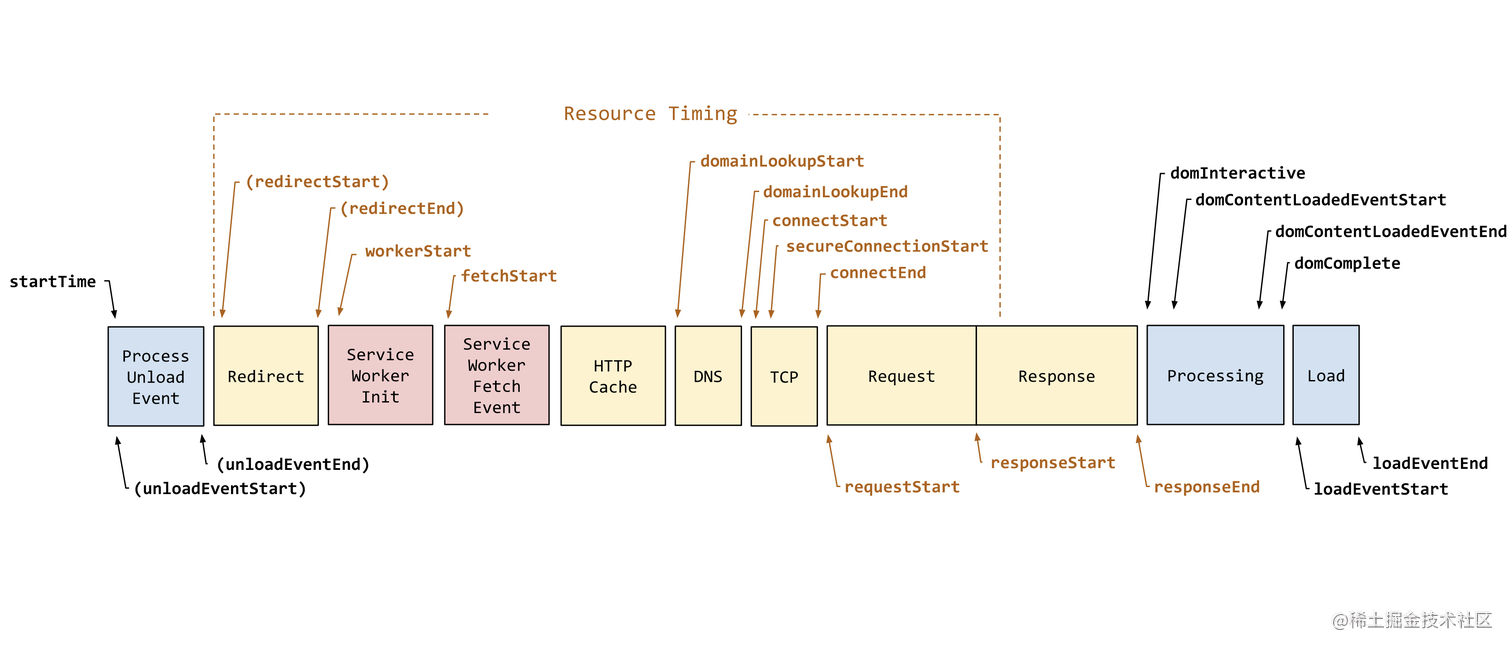
Navigation Api 时间图
数据来源:developer.mozila
看上图的内容,具体指标的计算逻辑如下表所示,若感到枯燥,可以直接调到表格后的下一个部分看精简内容,不过如果想成为网站性能专家,这部分算是基础入门内容。
是不是看着眼睛都晕了?其实单纯只看一下这部分其实也可以:
2.2 有关网站核心指标的数据分析初步展示与标准
在之前有关网站核心指标的叙述中,已经能够看到对于几个指标的 benchmark。
需注意:网站核心指标最早针对 MPA 架构,现在也支持 SPA 架构的网站,但必须注意到,SPA 目前没有统一的标准和路由规范,谷歌也在不断提高对 SPA 的适配,观测云也不断更新和补充用户体验的指标和相关功能,不断满足用户需求。
观测云内置的时序数据仪表盘,能够清晰地观测到真实的网站核心指标的数据情况,对于异常的性能数据指标,方便下钻进行分析。
3.优化实践参考
观测云性能指标列表
这部分内容更多的是赋能、启迪与实践,所以不再列出具体的指标列表,详情参考以下链接。
这里我特意列出在会话级别的几个指标,这些可能是数据分析、网站性能、 用户行为分析、用户增长与运营需要格外关注的:
3.1 需要关注的指标
控制性和可观测性需要专家构建评价系统给出关键指标及其相关性指标构建模型,给出大一统的数据模型可能很难,但落地到具体产品场景可能会有一些方法,这需要有一定经验的人对已有指标进行数据分析,在这点上观测云又给用户设置了特定的入口,供小白、中高级开发、专家乃至是产品同学进行场景建设。网站性能可以构建的模型可以从以下几方面来搭建场景:
-网站加载性能的现场指标收集,包括前面描述的各种指标
-网站加载性能的可视化和评价标准体系,这部分可以参考观测云默认的性能模板
-网站加载性能的相关性分析,这部分正好是一系列文章的第一篇。
下面我们便以观测云为例进行探索:
3.2 性能探索与实践
a.观测云控制台
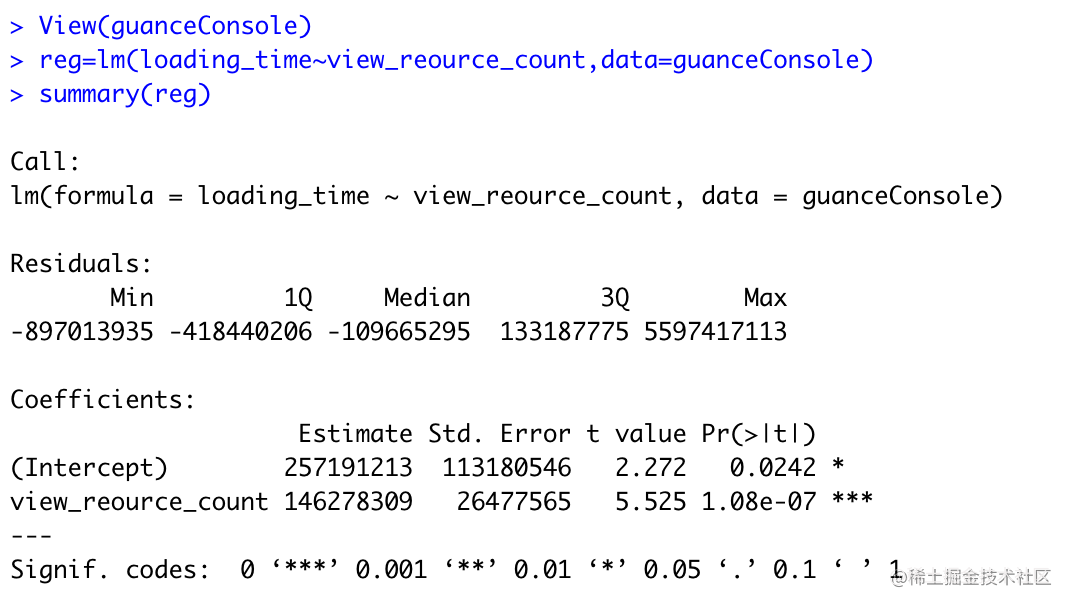
第一个分析的例子,观测云推荐用户使用场景仪表板中的散点图工具,来探查性能和不同指标之间的关系散点图能直观看出 x 和 y 的相关性,这里可以把 y 为加载时间,根据经验推荐用户分别以页面为维度,将 X 轴可以设置为资源加载数量。
资源加载数量和页面加载时间的数据可视化图


图注:其中 X 轴代表页面资源加载的数量;Y 轴代表页面加载时间(单位:s)
肉眼就能看出 x 在 0-30 间存在比较明显的正相关,导出该数据分析,发现数值远小于 0.05,也就是从统计分析上也能看出较强的相关性。
我们打开控制台的 network 选项,进行查看,发现在该页面有 169 个请求:
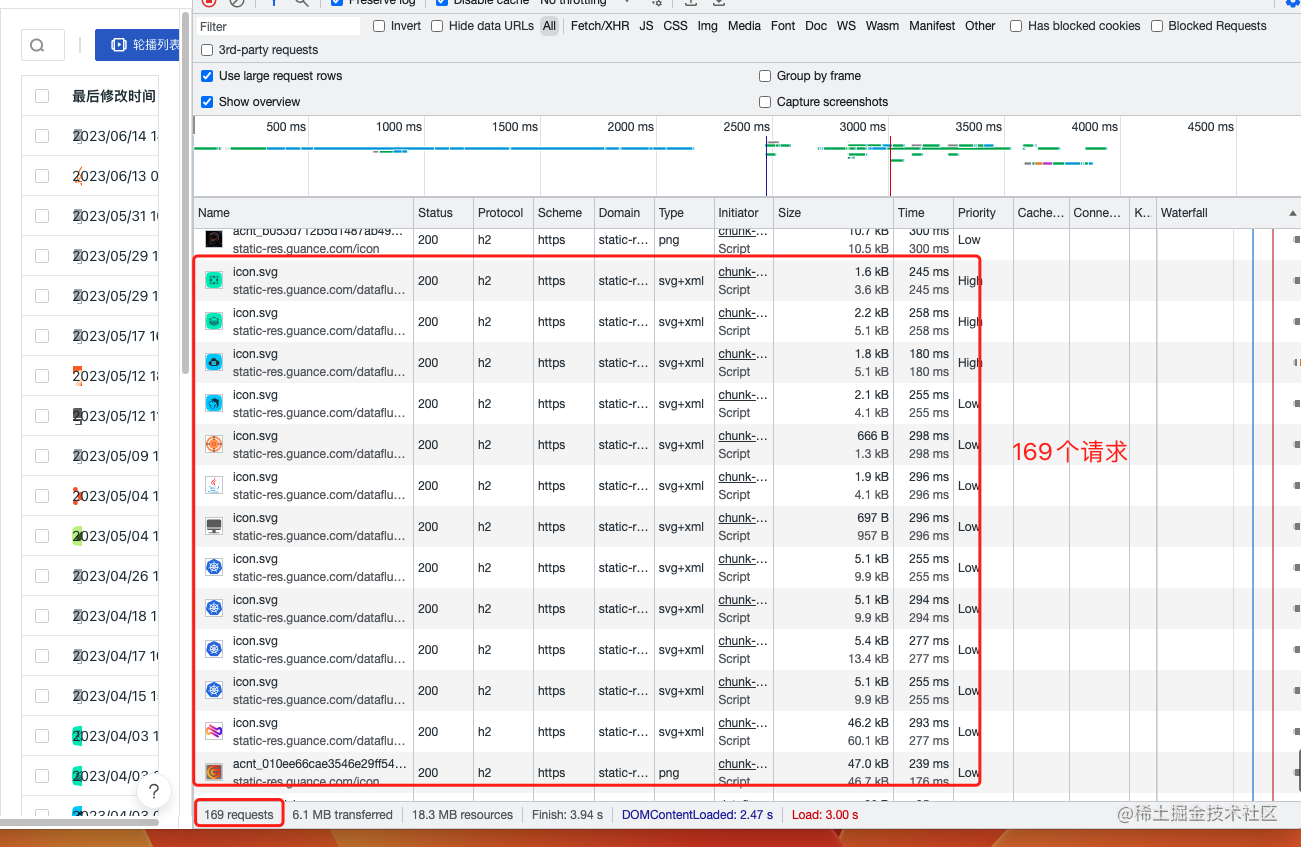
这么多资源看起来很不方便,我们使用观测云的场景仪表板继续探索,使用饼图对当前的资源类型进行分类,发现 js、css、image 三者的数量合占比 60%。
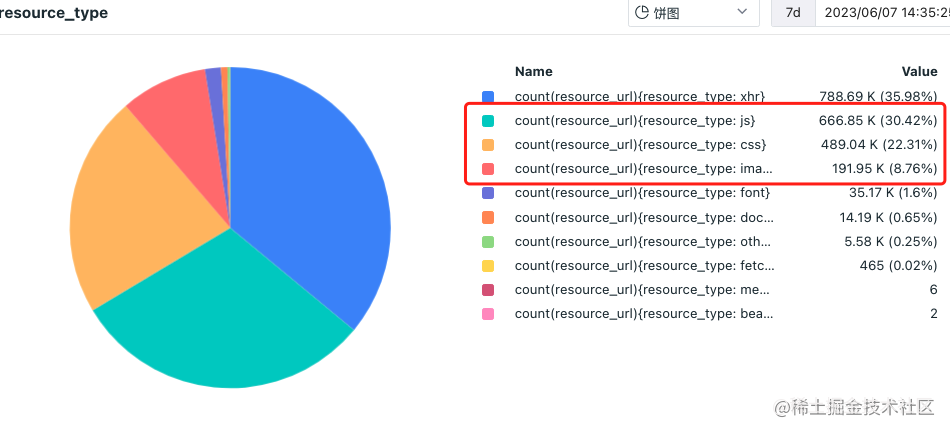
对这些静态资源我们可以做一个耗时比的统计,一般我们可以取 avg、min、max、p99、p90,这里我们采用 max 的 duration 来看,主要是想知道哪种类型耗时时间最长。

上图可以看出,image 类型耗时非常长,到底都是哪些内容呢,我们对 image 的类型继续做探索:

我们加载耗时最长的图片进行排序,看下图发现大多是 icon 类型:

因为上面讲到的样式资源加载的数量,所以按照请求加载的数量进行排行:
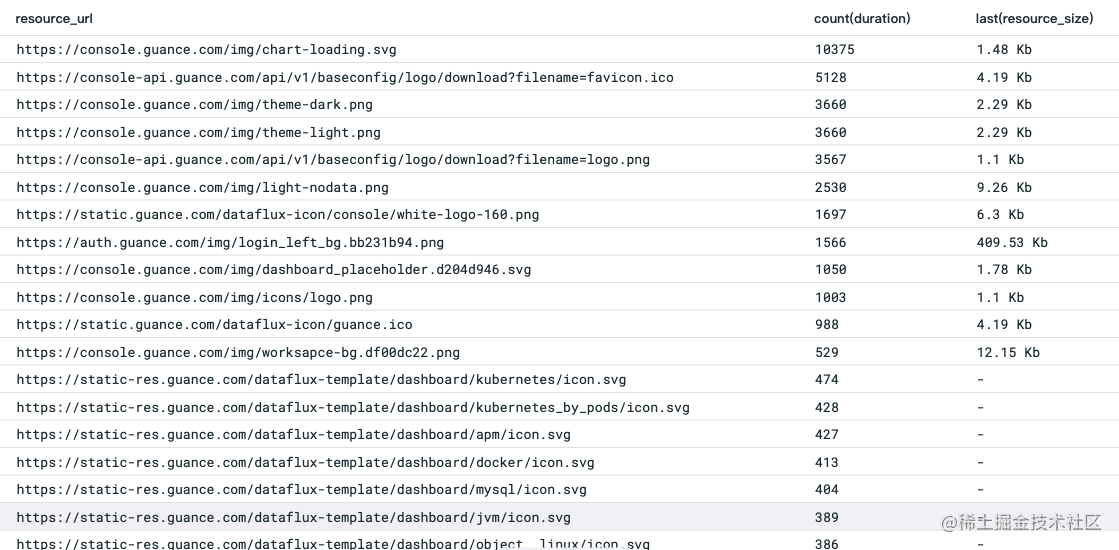
能够看到 chart-loading 等 icon 文件加载次数占比最多,但大小基本都在 5kb 以下,我们看到这些图片的文件名都是非增量更新的,也就是不会经常变动的静态资源,我们把这几个文件打开查看一下分别是:




看到这里,优化的角度也就非常清晰了,这 100 多个 icon 需要设计整理到一个文件就可以了。
我们看到 loading 这个文件加载的次数比任何都要多,这个文件是做什么的?我们还可以进一步对这个 loading 的文件进行探究,可以以页面功能或者 viewid 来进一步探索,这里以矩形树图为例:
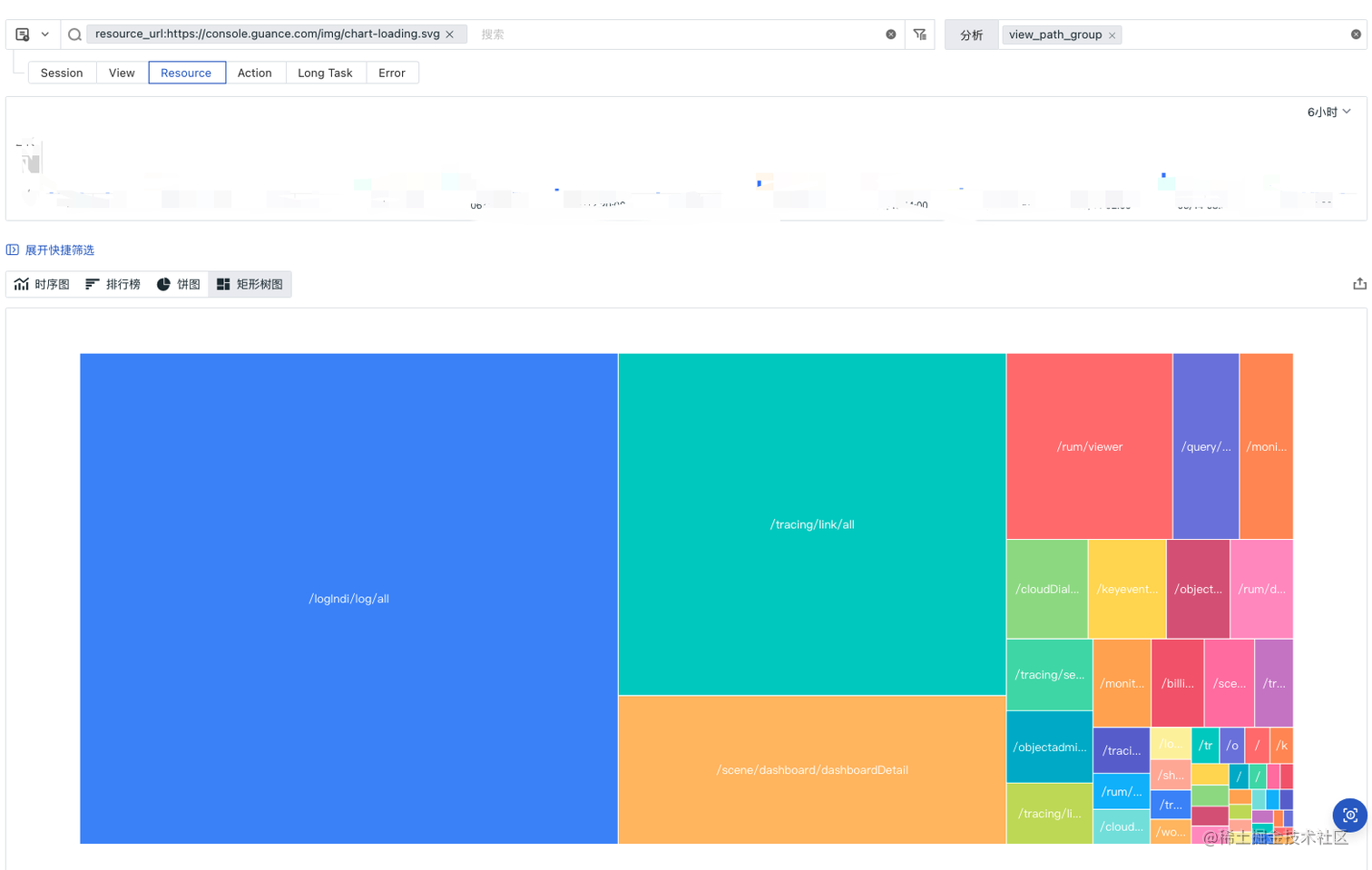
看着是以 login 加载次数最多,其他几乎所有页面都有加载,看来这个文件还是挺重要的,我们看看这个文件的缓存情况,我们来按照 resource_status 来进行查看:

我们发现 95%左右的状态码是 200,我们看一下它的传输时间来判断是否使用了本地缓存,在这个时候可以使用 resource_trans 这个来判断:
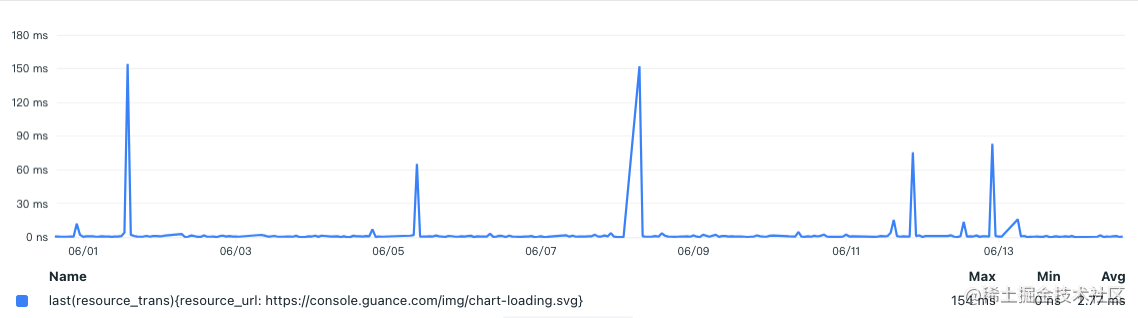
这里从上图也基本能推测该资源比较好的使用了缓存,大概在几天左右,max 基本可以理解成缓存失效后消耗的时间(>100ms),min 可以理解成加载本地缓存的时间(几乎为 0ms),所以这块可以如果适当做调整的话,可能得一个方向便是要从文件的大小入手,同理我们把其他类似的图片传输耗时进行分析:

看 avg 都不大,但 max 较大,说明文件大小还是需要调整(也可能是文件格式),我们按照 max 进行排序:

看到这些文件不仅 max 时间长,avg 也很长,要减少大小,可能还要考虑调整格式等手段了。
这里我再深入一点举个例子以 login_left_bg 这个图片为例子,其 resource_status 的饼形图如下所示:
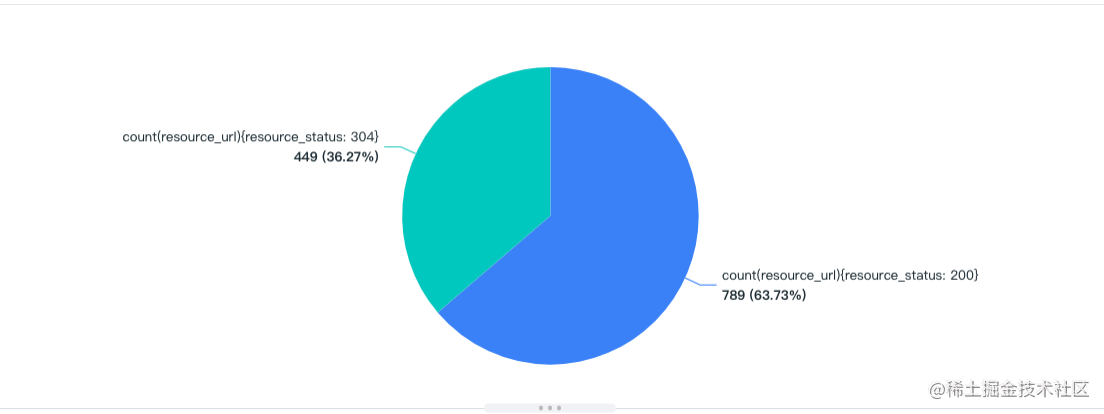
上图所示,说明该文件几乎都要经常去服务器查看文件是否有最新,这块就需要考虑这个文件是否是需要将缓存时间设置长一些了。
综上,使用了 resource 的很多指标字段进行了基本的数据分析,发现基本可以利用场景仪表板把揭示非常多的内容,不论是从 loading_time 和其他指标相关性的探索,还是对该指标的优化,我们都能看出当前网站的指标体系是非常复杂的,影响因素众多,需要深入探索,这块也是观测云不断投入力量研发的。
b.观测云官网
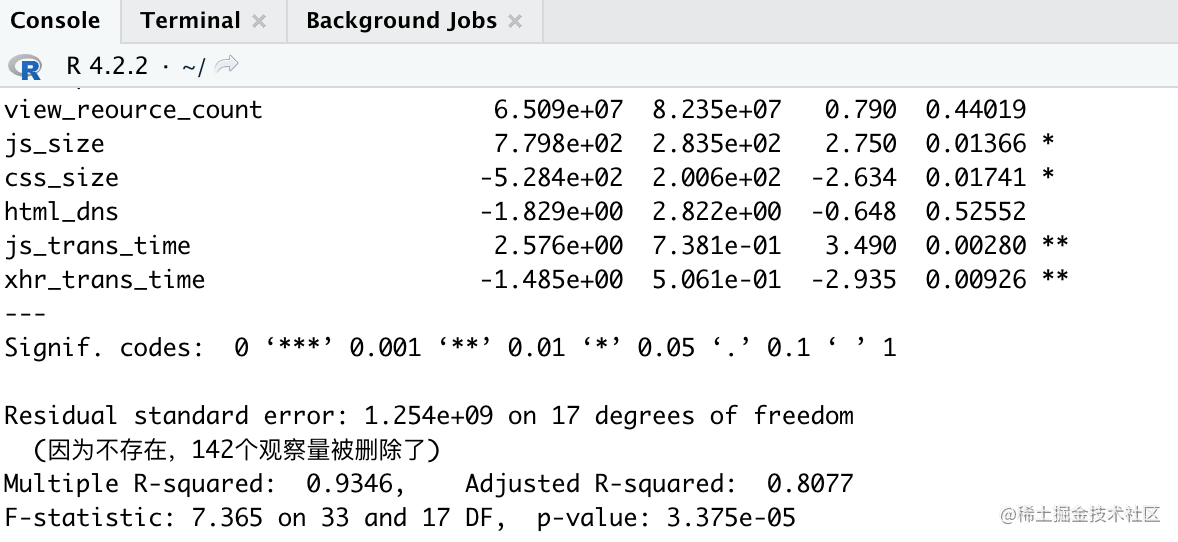
同理对官网进行相关性分析,看到 view_resource_count 则没有显著性,但 js_size、css_size 的相关性较高.
我们打开官网进行查看,发现 js 和 css 较大存在 blank_line 和 white_space,webpack 有对应的 compress 插件可以去掉 white_space 和 blank_line,这部分比较简单就不展开了。
现在使用观测云对 resource 进行分析,首先先以 resource_status 筛选 resource_trans 的情况,
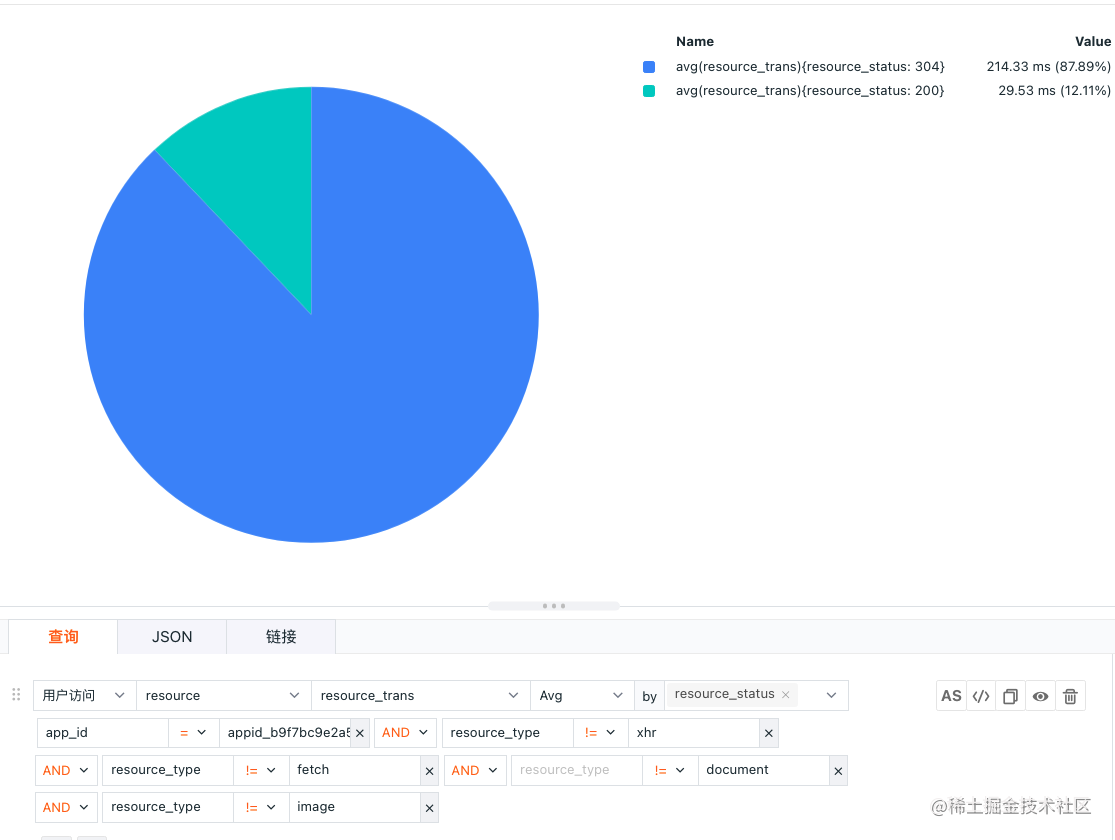
上图得知,304 的资源平均传输时间比 200 的传输时间要长很多,也就是去服务器查看没有更新的文件,发现没有更新的内容,依旧使用了缓存内容,这里也能明显看出使用了合理设置缓存时间的好处,但这里有点问题,下面以时序图来推测缓存时间:
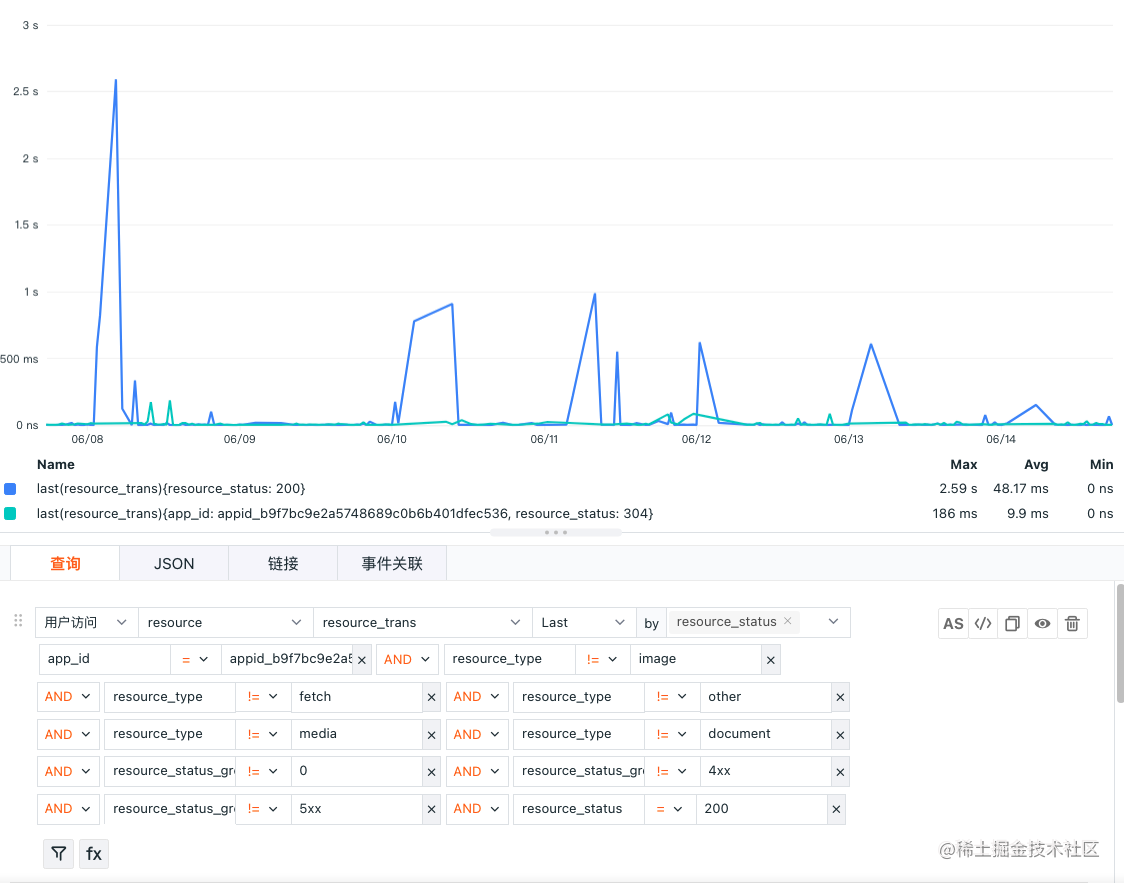
这时候 我们还可以直接将 200、304 时序图拉出来,这里选择加入 resouce_type 做筛选一并做可视化:

上图看出 css 的耗时 max 和 avg 明显大于 js 的耗时,我们看看 css 这部分的内容:
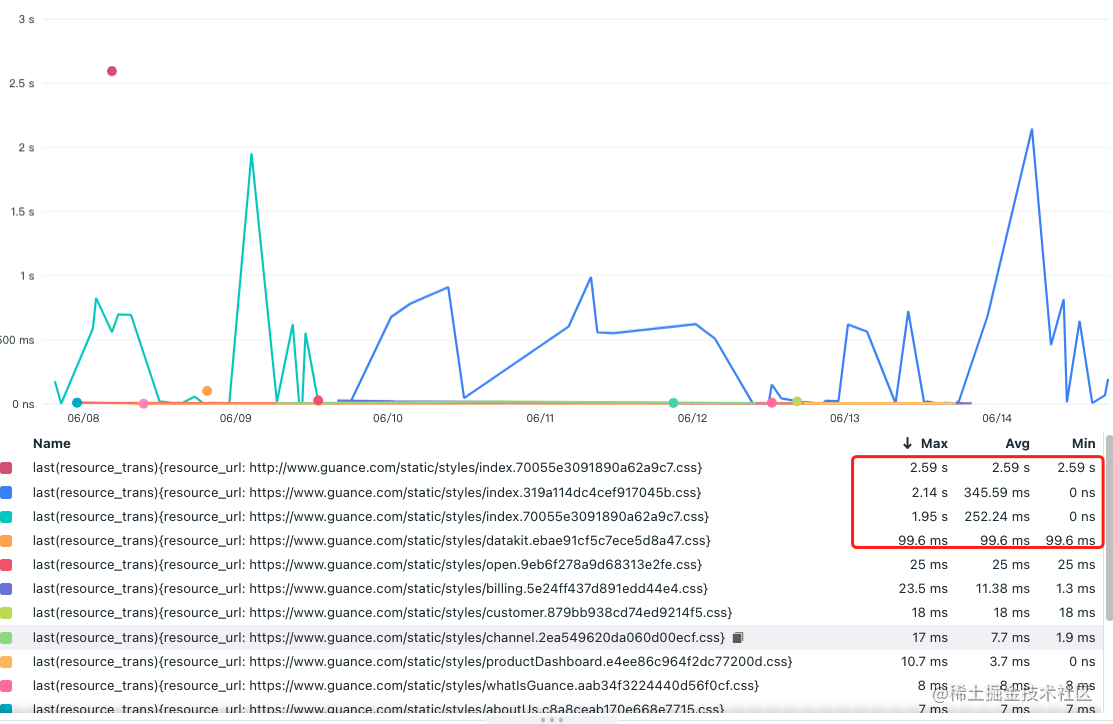
我们打开其中的文件进行查看:
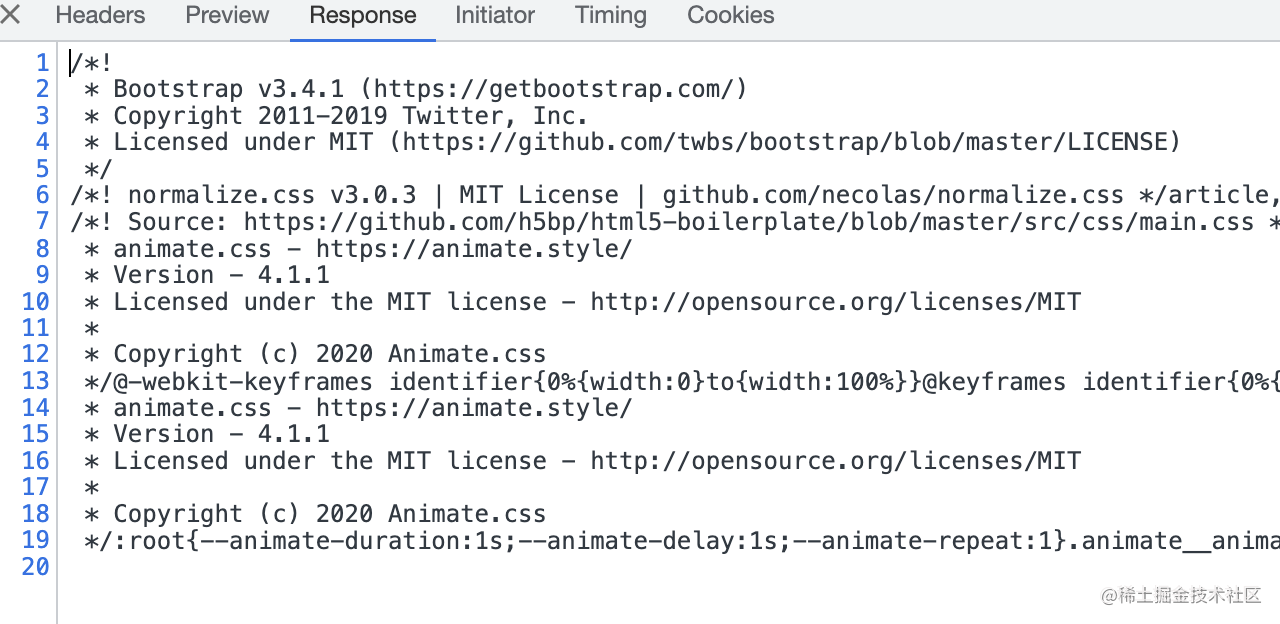
这部分是第三方库,可以摘出来放 CDN 可能效果会好很多。
下面针对 js 进行查看

限于篇幅,此处就不再做具体分析,相信小伙伴已经能够看出性能调优的基本思路和方法。这里最后补充一张资源加载首包时间和页面架子时间的可视化图,感兴趣的小伙伴可以继续探索。
资源加载首包时间和页面加载时间的数据可视化图

图注:其中 X 轴代表资源加载首包时间;Y 轴代表页面加载时间(单位:s)
注意:观测云推荐用户根据使用场景来洞察性能,需要明确的是,除了资源加载数量、资源加载首包时间,还有很多影响网站性能的因素,如 TCP、DNS 等网络情况。
总结
综上所述,随着技术与评价标准的发展,观测云既能给用户提供完整的指标体系,提供了指标洞察的方法,让网站系统的性能能够被观测和提升,限于篇幅内容,有关网站加载性能提升的第一篇内容到这里就先结束了,之后会对网站核心指标中有关加载性能的 LCP 以及提升的四大方法做分享。
后续补充:
仪表板配置 json
python 或者 r 的代码随附:
本文使用观测云-中国区 1(杭州)站点,商业版账号。
直接开通商业版可获得 500 元无限制代金券,实现本文观测场景每天消费仅需几分钱,可以用几十年了。
或可以选择开通体验版,每天有 2000 的免费额度,,可参考:
完成观测云账号注册后,会登录到观测云工作空间控制台,之后的数据可视化都会在这里展现。
作者:卡曼在观测
链接:https://juejin.cn/post/7267797785088573480
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
版权声明: 本文为 InfoQ 作者【Yestodorrow】的原创文章。
原文链接:【http://xie.infoq.cn/article/7ebf317eb4c69af5a695c0178】。文章转载请联系作者。

还未添加个人签名 2017-10-19 加入
还未添加个人简介









评论